
什麼是 Java 機器學習? 如何實施?
已發表: 2021-03-10目錄
什麼是機器學習?
機器學習是人工智能的一個部門,它從可用數據、示例和經驗中學習,以模仿人類的行為和智能。 使用機器學習創建的程序可以自行構建邏輯,而無需人工手動編寫代碼。
這一切都始於 1950 年代初的圖靈測試,當時艾倫·特寧得出結論,計算機要想擁有真正的智能,就需要操縱或說服人類它也是人類。 機器學習是一個相對古老的概念,但直到今天這個新興領域才得以實現,因為計算機現在可以處理複雜的算法。 機器學習算法在過去十年中已經發展到包括複雜的計算技能,這反過來又增強了它們的模仿能力。
機器學習應用也以驚人的速度增長。 從醫療保健、金融、分析和教育,到製造、營銷和政府運營,在實施機器學習技術後,每個行業的質量和效率都得到了顯著提升。 世界各地都出現了廣泛的質量改進,因此推動了對機器學習專業人員的需求。
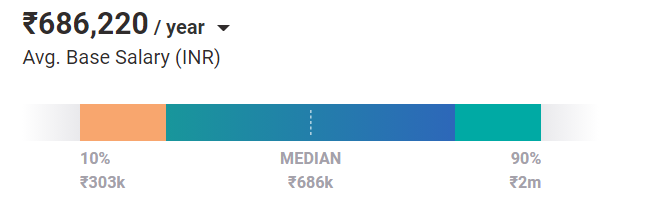
平均而言,機器學習工程師今天的薪水為 686,220 盧比/年。 這就是入門級職位的情況。 憑藉經驗和技能,他們可以在印度賺取高達 200 萬盧比/年的收入。
機器學習算法的類型
機器學習算法分為三種類型:
1. 監督學習:在這種類型的學習中,訓練數據集指導算法做出準確的預測或分析決策。 它利用從過去的訓練數據集中學習來處理新數據。 以下是監督學習機器學習模型的一些示例:

- 線性回歸
- 邏輯回歸
- 決策樹
2. 無監督學習:在這種類型的學習中,機器學習模型從未標記的信息中學習。 它通過對對象進行分組或理解它們之間的關係,或利用它們的統計特性來進行分析,從而採用數據聚類。 無監督學習算法的例子有:
- K-means 聚類
- 層次聚類
3.強化學習:這個過程是基於hit and trial。 它是通過與空間或環境互動來學習的。 RL 算法通過與環境交互並確定最佳行動方案來從過去的經驗中學習。
如何用 Java 實現機器學習?
Java 是用於實現機器學習算法的頂級編程語言之一。 它的大部分庫都是開源的,提供廣泛的文檔支持、易於維護、適銷性和易讀性。
根據受歡迎程度,以下是用於在 Java 中實現機器學習的前 10 個機器學習庫。
1.亞當斯
高級數據挖掘和機器學習系統或 ADAMS 關注構建新穎靈活的工作流系統並管理複雜的現實世界流程。 ADAMS 採用樹狀架構來管理數據流,而不是進行手動輸入輸出連接。
它消除了對顯式連接的任何需要。 它基於“少即是多”的原則,執行檢索、可視化和數據驅動的可視化。 ADAMS 擅長數據處理、數據流、管理數據庫、腳本和文檔。
2.JavaML
JavaML 提供了多種為 Java 編寫的 ML 和數據挖掘算法,以支持軟件工程師、程序員、數據科學家和研究人員。 每個算法都有一個易於使用的通用界面,並且即使沒有 GUI,也有廣泛的文檔支持。
與其他聚類算法相比,它的實現相當簡單直接。 其核心功能包括數據操作、文檔編制、數據庫管理、數據分類、聚類、特徵選擇等。
加入來自世界頂級大學的在線機器學習課程——碩士、高管研究生課程和 ML 和 AI 高級證書課程,以加快您的職業生涯。
3.威卡
Weka 也是一個為 Java 編寫的支持深度學習的開源機器學習庫。 它提供了一套機器學習算法,並在數據挖掘、數據準備、數據聚類、數據可視化和回歸等數據操作中得到廣泛應用。
示例:我們將使用一個小型糖尿病數據集來演示這一點。
第 1 步:使用 Weka 加載數據
| 導入 weka.core.Instances; 導入 weka.core.converters.ConverterUtils.DataSource; 公共類主要{ 公共靜態 void main(String[] args) 拋出異常 { // 指定數據源 數據源 dataSource = new DataSource(“data.arff”); // 加載數據集 實例 dataInstances = dataSource.getDataSet(); // 顯示實例數 log.info(“加載的實例數為:” + dataInstances.numInstances()); log.info(“數據:” + dataInstances.toString()); } } |
第 2 步:數據集有 768 個實例。 我們需要訪問屬性的數量,即 9。
| log.info(“數據集中的屬性(特徵)個數:” + dataInstances.numAttributes()); |
第三步:我們需要在建立模型之前確定目標列並找到類的數量。
| // 識別標籤索引 dataInstances.setClassIndex(dataInstances.numAttributes() - 1); // 獲取數量 log.info(“類數:” + dataInstances.numClasses()); |
第 4 步:我們現在將使用簡單的樹分類器 J48 構建模型。
| // 創建決策樹分類器 J48 treeClassifier = new J48(); treeClassifier.setOptions(new String[] { “-U” }); treeClassifier.buildClassifier(dataInstances); |
上面的代碼重點介紹瞭如何創建由模型訓練所需的數據實例組成的未修剪樹。 在模型訓練後打印樹結構後,我們可以確定規則是如何在內部構建的。
| 等離子 <= 127 | 質量 <= 26.4 | | preg <= 7:tested_negative (117.0/1.0) | | 懷孕 > 7 | | | 質量 <= 0:tested_positive (2.0) | | | 質量 > 0:tested_negative (13.0) | 質量 > 26.4 | | 年齡 <= 28:tested_negative (180.0/22.0) | | 年齡 > 28 | | | plas <= 99:tested_negative (55.0/10.0) | | | 塑料 > 99 | | | | pedi <= 0.56:tested_negative (84.0/34.0) | | | | 足底 > 0.56 | | | | | 懷孕 <= 6 | | | | | | 年齡 <= 30:tested_positive (4.0) | | | | | | 年齡 > 30 | | | | | | | 年齡 <= 34:test_negative (7.0/1.0) | | | | | | | 年齡 > 34 | | | | | | | | 質量 <= 33.1:tested_positive (6.0) | | | | | | | | 質量 > 33.1:tested_negative (4.0/1.0) | | | | | preg > 6:tested_positive (13.0) 塑料 > 127 | 質量 <= 29.9 | | plas <= 145:tested_negative (41.0/6.0) | | 塑料 > 145 | | | 年齡 <= 25:test_negative (4.0) | | | 年齡 > 25 | | | | 年齡 <= 61 | | | | | 質量 <= 27.1:tested_positive (12.0/1.0) | | | | | 質量 > 27.1  | | | | | | 壓力 <= 82 | | | | | | | pedi <= 0.396:tested_positive (8.0/1.0) | | | | | | | pedi > 0.396:test_negative (3.0) | | | | | | 壓力 > 82: 測試陰性 (4.0) | | | | 年齡 > 61:test_negative (4.0) | 質量 > 29.9 | | 等離子 <= 157 | | | pres <= 61:tested_positive (15.0/1.0) | | | 壓力 > 61 | | | | 年齡 <= 30:tested_negative (40.0/13.0) | | | | 年齡 > 30:test_positive (60.0/17.0) | | plas > 157:tested_positive (92.0/12.0) 葉數:22 樹的大小:43 |
4. 阿帕奇馬豪
Mahaut 是一組算法,可幫助使用 Java 實現機器學習。 它是一個可擴展的線性代數框架,開發人員可以使用它進行數學、統計學家分析。 數據科學家、研究工程師和分析專業人員通常使用它來構建企業級應用程序。 它的可擴展性和靈活性允許用戶快速輕鬆地實施數據集群、推薦系統和創建高性能機器學習應用程序。
5. 深度學習4j
Deeplearning4j 是一個用 Java 編寫的編程庫,為深度學習提供廣泛的支持。 它是一個開源框架,結合了深度神經網絡和深度強化學習來服務於業務運營。 兼容Scala、Kotlin、Apache Spark、Hadoop等JVM語言和大數據計算框架。
它通常用於檢測語音、語音和書面文本中的模式和情緒。 它作為一個 DIY 工具,可以發現交易中的差異,並處理多項任務。 它是一個商業級的分佈式庫,由於其開源特性,它具有詳細的 API 文檔。
這是一個如何使用 Deeplearning4j 實現機器學習的示例。
示例:使用 Deeplearning4j,我們將構建卷積神經網絡 (CNN) 模型,借助 MNIST 庫對手寫數字進行分類。
第 1 步:加載數據集以顯示其大小。
| DataSetIterator MNISTTrain = new MnistDataSetIterator(batchSize,true,seed); DataSetIterator MNISTTest = new MnistDataSetIterator(batchSize,false,seed); |
第 2 步:確保數據集為我們提供了十個唯一標籤。
| log.info(“在訓練數據集中找到的總標籤數” + MNISTTrain.totalOutcomes()); log.info(“在測試數據集中找到的標籤總數” + MNISTTest.totalOutcomes()); |
第 3 步:現在,我們將使用兩個卷積層和一個展平層來配置模型架構以顯示輸出。
Deeplearning4j 中有一些選項允許您初始化權重方案。
| // 構建 CNN 模型 MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder() .seed(seed) // 隨機種子 .l2(0.0005) // 正則化 .weightInit(WeightInit.XAVIER) // 初始化權重方案 .updater(new Adam(1e-3)) // 設置優化算法 。列表() .layer(new ConvolutionLayer.Builder(5, 5) //設置步幅、內核大小和激活函數。 .nIn(nChannels) .stride(1,1) .nOut(20) .activation(激活.IDENTITY) 。建造()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // 下採樣捲積 .kernelSize(2,2) .stride(2,2) 。建造()) .layer(new ConvolutionLayer.Builder(5, 5) // 設置步幅、內核大小和激活函數。 .stride(1,1) .nOut(50) .activation(激活.IDENTITY) 。建造()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // 下採樣捲積 .kernelSize(2,2) .stride(2,2) 。建造()) .layer(new DenseLayer.Builder().activation(Activation.RELU) .nOut(500).build()) .layer(new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD) .nOut(輸出編號) .activation(激活.SOFTMAX) 。建造()) // 最終輸出層為 28×28,深度為 1。 .setInputType(InputType.convolutionalFlat(28,28,1)) 。建造(); |
第 4 步:在我們配置好架構後,我們將初始化模式和訓練數據集,並開始模型訓練。
| 多層網絡模型 = 新多層網絡(conf); // 初始化模型權重。 模型.init(); log.info(“第二步:開始訓練模型”); //每 10 次迭代設置一個監聽器,並在每個 epoch 上評估測試集 model.setListeners(new ScoreIterationListener(10), new EvaluativeListener(MNISTTest, 1, InvocationType.EPOCH_END)); // 訓練模型 model.fit(MNISTTrain, nEpochs); |
隨著模型訓練的開始,您將獲得分類準確度的混淆矩陣。
這是十個訓練週期後模型的準確度:
| ==========================混淆矩陣======================= == 0 1 2 3 4 5 6 7 8 9 —————————————————— 977 0 0 0 0 0 1 1 1 0 | 0 = 0 0 1131 0 1 0 1 2 0 0 0 | 1 = 1 1 2 1019 3 0 0 0 3 4 0 | 2 = 2 0 0 1 1004 0 1 0 1 3 0 | 3 = 3 0 0 0 0 977 0 2 0 1 2 | 4 = 4 1 0 0 9 0 879 1 0 1 1 | 5 = 5 4 2 0 0 1 1 949 0 1 0 | 6 = 6 0 4 2 1 1 0 0 1018 1 1 | 7 = 7 2 0 3 1 0 1 1 2 962 2 | 8 = 8 0 2 0 2 11 2 0 3 2 987 | 9 = 9 |
6. 埃爾基
由索引結構或 ELKI 支持的開發 KDD 應用程序的環境是用於數據挖掘的內置算法和程序的集合。 它是用 Java 編寫的,是一個開源庫,包含算法中高度可配置的參數。 它通常被研究科學家和學生用來深入了解數據集。 顧名思義,它為使用索引結構開發複雜的數據挖掘程序和數據庫提供了環境。
7.日本SAT
Java Statistical Analysis Tool 或 JSAT 是一個 GPL3 庫,它使用面向對象的框架來幫助用戶使用 Java 實現機器學習。 它通常用於學生和開發人員的自我教育目的。 與其他 AI 實現庫相比,JSAT 擁有最多的 ML 算法,並且是所有框架中最快的。 由於零外部依賴,它具有高度的靈活性和高效性,並提供高性能。
8. Encog 機器學習框架
Encog 是用 Java 和 C# 編寫的,包含幫助實現機器學習算法的庫。 它用於構建遺傳算法、貝葉斯網絡、隱馬爾可夫模型等統計模型等。
9. 木槌
語言工具包或槌的機器學習用於自然語言處理 (NLP)。 與大多數其他 ML 實現框架一樣,Mallet 也提供對數據建模、數據聚類、文檔處理、文檔分類等的支持。
10. Spark MLlib
企業使用 Spark MLlib 來提高工作流管理的效率和可擴展性。 它處理大量數據並支持重負載的 ML 算法。
結帳:機器學習項目的想法
結論
這將我們帶到了文章的結尾。 有關機器學習概念的更多信息,請通過 upGrad 的機器學習和 AI 理學碩士課程與班加羅爾 IIIT 和利物浦約翰摩爾斯大學的頂尖教師取得聯繫。
為什麼我們應該將 Java 與機器學習一起使用?
如果機器學習專業人士選擇 Java 作為其項目的編程語言,他們會發現與當前代碼存儲庫交互更容易。 由於易於使用、打包服務、更好的用戶交互、快速調試和數據圖形說明等特性,它是首選的機器學習語言。 Java 使機器學習開發人員可以輕鬆擴展他們的系統,使其成為從頭開始構建大型、複雜的機器學習應用程序的絕佳選擇。 Java 虛擬機 (JVM) 支持許多集成開發環境 (IDE),允許機器學習者快速設計新工具。
學習Java容易嗎?
由於 Java 是一種高級語言,因此很容易掌握。 作為一名學習者,您不必深入了解細節,因為它是一種結構良好、面向對象的語言,對於新手來說足夠簡單。 因為有許多程序可以自動運行,您可以快速掌握它們。 您不必詳細了解那裡的事情是如何運作的。 Java 是一種獨立於平台的編程語言。 它使程序員能夠創建可在任何設備上使用的移動應用程序。 它是物聯網的首選語言,也是開發企業級應用程序的最佳工具。
什麼是 ADAMS,它對機器學習有何幫助?
高級數據挖掘和機器學習系統 (ADAMS) 是一個 GPLv3 許可的工作流引擎,用於快速創建和管理數據驅動的反應式工作流,這些工作流可以很容易地併入業務流程。 遵循少即是多原則的工作流引擎是 ADAMS 的核心。 ADAMS 採用樹狀結構,而不是允許用戶在畫布上安排操作員(或 ADAMS 行話中的演員),然後手動鏈接輸入和輸出。 不需要顯式連接,因為這種結構和控制參與者決定了數據在流程中的流動方式。 運算符處理程序中的內部對象表示和子運算符嵌套導致樹狀結構。 ADAMS 為數據檢索、處理、挖掘和顯示提供了一組多樣化的代理。