
什麼是數據挖掘中的決策樹? 類型、真實世界的示例和應用
已發表: 2021-06-15目錄
數據挖掘簡介
數據通常以原始數據的形式出現,需要對其進行有效處理才能將其轉換為有用的信息。 結果的預測通常依賴於在數據中發現模式、異常或相關性的過程。 該過程被稱為“數據庫中的知識發現”。
直到 1990 年代才創造了“數據挖掘”一詞。 數據挖掘建立在三個學科之上:統計學、人工智能和機器學習。 自動化數據挖掘已將分析過程從繁瑣的方法轉變為更快的方法。 數據挖掘允許用戶
- 刪除所有嘈雜和混亂的數據
- 了解相關數據並將其用於預測有用信息。
- 預測明智決策的過程加快了。
數據挖掘也可以稱為識別需要分類的隱藏信息模式的過程。 只有這樣,數據才能轉化為有用的數據。 有用的數據可以輸入數據倉庫、數據挖掘算法、數據分析以進行決策。
數據挖掘中的決策樹
一種數據挖掘技術,數據挖掘中的決策樹為數據的分類建立模型。 模型以樹形結構的形式構建,因此屬於有監督的學習形式。 除了分類模型之外,決策樹還用於構建回歸模型,以預測類標籤或有助於決策過程的值。 決策樹可以使用數字和分類數據,如性別、年齡等。
決策樹的結構
決策樹的結構由根節點、分支和葉節點組成。 分支節點是樹的結果,內部節點表示對屬性的測試。 葉節點代表一個類標籤。
決策樹的工作
1. 決策樹在離散變量和連續變量的監督學習方法下工作。 根據數據集最重要的屬性將數據集拆分為子集。 屬性的識別和分割是通過算法完成的。
2.決策樹的結構由根節點組成,它是重要的預測節點。 分裂過程從決策節點開始,決策節點是樹的子節點。 沒有進一步分裂的節點稱為葉節點或終端節點。
3. 按照自上而下的方法將數據集劃分為同質區域和非重疊區域。 頂層在一個地方提供觀察,然後分裂成分支。 該過程被稱為“貪婪方法”,因為它只關注當前節點而不是未來節點。
4. 除非達到停止標準,否則決策樹將繼續運行。
5. 隨著決策樹的建立,會產生大量的噪聲和異常值。 為了去除這些異常值和噪聲數據,應用了“樹修剪”的方法。 因此,模型的準確性會提高。
6. 在由測試元組和類標籤組成的測試集上檢查模型的準確性。 一個準確的模型是根據模型的分類測試集元組和類的百分比來定義的。
圖 1 :未修剪和修剪樹的示例
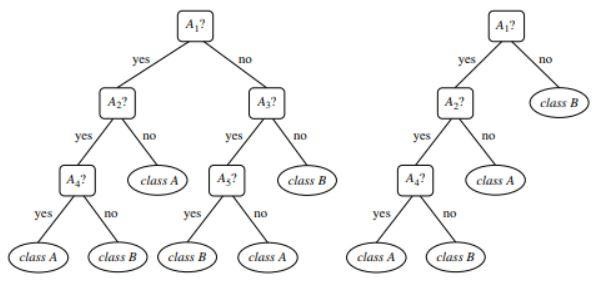
資源
決策樹的類型
決策樹導致基於樹狀結構的分類和回歸模型的發展。 數據被分解成更小的子集。 決策樹的結果是具有決策節點和葉節點的樹。 下面解釋兩種類型的決策樹:
一、分類
分類包括建立描述重要類別標籤的模型。 它們應用於機器學習和模式識別領域。 機器學習中的決策樹通過分類模型導致欺詐檢測、醫療診斷等。分類模型的兩個步驟過程包括:
- 學習:建立基於訓練數據的分類模型。
- 分類:檢查模型的準確性,然後用於新數據的分類。 類標籤採用離散值的形式,如“是”或“否”等。
圖 2 :分類模型示例。
資源
2.回歸
回歸模型用於數據的回歸分析,即數值屬性的預測。 這些也稱為連續值。 因此,回歸模型不是預測類別標籤,而是預測連續值。
使用的算法列表
1980 年,機器研究員 J. Ross Quinlan 開發了一種稱為“ID3”的決策樹算法。 該算法被他開發的C4.5等其他算法所繼承。 兩種算法都應用了貪心方法。 算法 C4.5 不使用回溯,並且樹以自上而下的遞歸分而治之的方式構建。 該算法使用帶有類標籤的訓練數據集,隨著樹的構建,這些標籤被分成更小的子集。
- 最初選擇三個參數——屬性列表、屬性選擇方法和數據分區。 訓練集的屬性在屬性列表中描述。
- 屬性選擇方法包括選擇用於區分元組的最佳屬性的方法。
- 樹結構取決於屬性選擇方法。
- 樹的構建從單個節點開始。
- 當一個元組中表示不同的類標籤時,就會發生元組的拆分。 這將導致樹的分支形成。
- 拆分方法決定了應該為數據分區選擇哪個屬性。 基於這種方法,分支是根據測試結果從一個節點生長出來的。
- 遞歸地執行拆分和分區的方法,最終得到訓練數據集元組的決策樹。
- 樹的形成過程一直持續到並且除非剩下的元組不能被進一步分割。
- 算法的複雜度表示為
n * |D| * 日誌 |D|
其中,n 是訓練數據集 D 中的屬性數,|D| 是元組的數量。
資源
圖 3:離散值拆分
決策樹中使用的算法列表是:
ID3
在形成決策樹時,將整個數據集 S 視為根節點。 然後對每個屬性進行迭代並將數據拆分為片段。 該算法檢查並獲取那些在迭代之前未獲取的屬性。 在 ID3 算法中拆分數據非常耗時,並且不是理想的算法,因為它會過度擬合數據。
C4.5
它是一種高級形式的算法,因為數據被分類為樣本。 與 ID3 不同,可以有效處理連續值和離散值。 存在修剪方法,可去除不需要的分支。
大車
該算法可以執行分類和回歸任務。 與 ID3 和 C4.5 不同,決策點是通過考慮基尼指數來創建的。 一種貪心算法被應用於旨在降低成本函數的分裂方法。 在分類任務中,使用基尼指數作為代價函數來表示葉子節點的純度。 在回歸任務中,使用平方和誤差作為成本函數來找到最佳預測。
柴德
顧名思義,它代表卡方自動交互檢測器,一個處理任何類型變量的過程。 它們可能是名義變量、有序變量或連續變量。 回歸樹使用 F 檢驗,而分類模型中使用卡方檢驗。
火星
它代表多元自適應回歸樣條。 該算法專門在回歸任務中實現,其中數據大多是非線性的。
貪婪遞歸二進制拆分
發生二進制拆分方法會導致兩個分支。 元組的拆分是通過拆分成本函數的計算來執行的。 選擇成本最低的拆分並遞歸執行該過程以計算其他元組的成本函數。
具有真實世界示例的決策樹
根據給定數據預測貸款資格流程。
Step1:加載數據
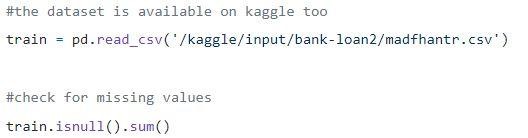

空值可以刪除或填充一些值。 原始數據集的形狀為(614,13),刪除空值後的新數據集為(480,13)。
Step2:查看數據集。

Step3:將數據拆分為訓練集和測試集。
第 4 步:構建模型並擬合訓練集

在可視化之前,需要進行一些計算。
計算1:計算整個數據集的熵。

計算 2:求每一列的熵和增益。
- 性別欄
- 條件 1:包含所有男性的數據集,然後,
p = 278,n=116,p+n=489
熵(G=男性)= 0.87
- 條件 2:包含所有女性的數據集,然後,
p = 54 , n = 32 , p+n = 86
熵(G=女性)= 0.95
- 性別欄中的平均信息

- 已婚專欄
- 條件 1:已婚 = 是(1)
在此拆分整個數據集與已婚狀態是
p = 227 , n = 84 , p+n = 311
E(已婚=是)= 0.84
- 條件 2:已婚 = 否(0)
在此拆分整個數據集,已婚狀態為 no
p = 105 , n = 64 , p+n = 169
E(已婚 = 否)= 0.957
- 已婚列中的平均信息為
- 教育專欄
- 條件一:學歷=研究生(1)
p = 271 , n = 112 , p+n = 383
E(教育=研究生)= 0.87
- 條件 2:教育 = 未畢業(0)
p = 61 , n = 36 , p+n = 97
E(教育=未畢業)= 0.95
- 教育欄的平均信息= 0.886
增益 = 0.01
4) 自僱專欄
- 條件 1:自僱 = 是(1)
p = 43 , n = 23 , p+n = 66
E(自僱=是)= 0.93
- 條件 2:自僱 = 否(0)
p = 289 , n = 125 , p+n = 414
E(自僱=否)= 0.88
- 自僱教育欄的平均信息 = 0.886
增益 = 0.01
- Credit Score 列:該列有 0 和 1 值。
- 條件 1:信用評分 = 1
p = 325 , n = 85 , p+n = 410
E(信用評分= 1)= 0.73
- 條件 2:信用評分 = 0
p = 63 , n = 7 , p+n = 70
E(信用分數 = 0) = 0.46
- 信用評分列中的平均信息 = 0.69
增益 = 0.2
比較所有增益值

信用評分的收益最高。 因此,它將被用作根節點。
第 5 步:可視化決策樹

圖 5:具有標準 Gini 的決策樹
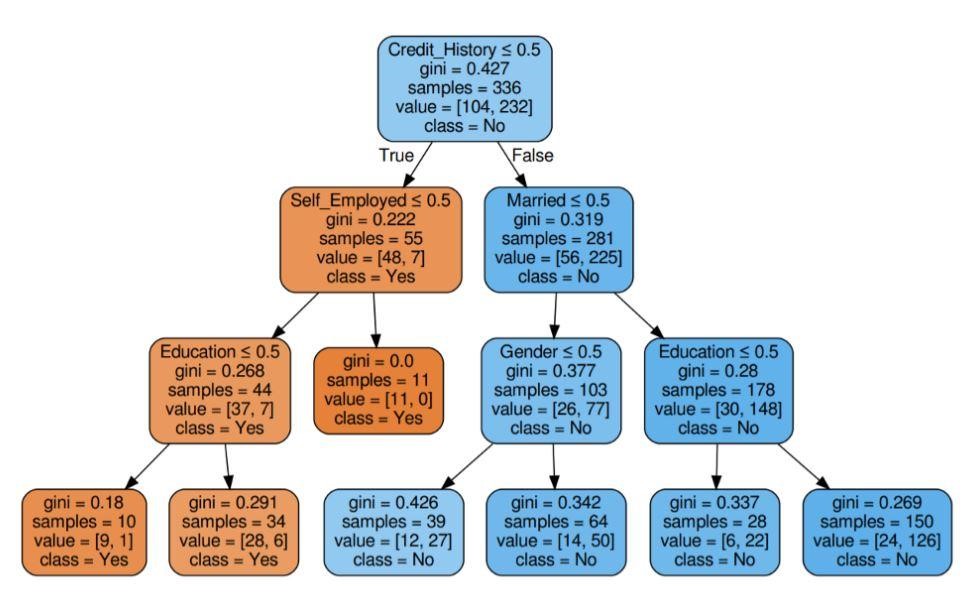 資源
資源
圖 6:具有標準熵的決策樹
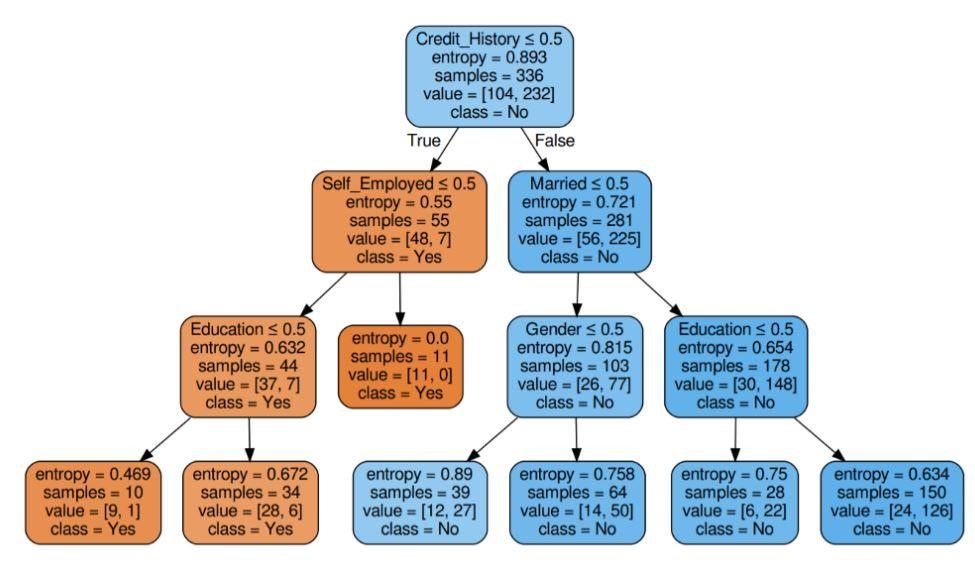
資源
第6步:檢查模型的分數
幾乎 80% 的準確率得分。
應用程序列表
決策樹主要由信息專家用於進行分析調查。 它們可能被廣泛用於商業目的,以分析或預測困難。 決策樹的靈活性允許它們用於不同的領域:
1. 醫療保健
決策樹允許預測患者是否患有具有年齡、體重、性別等條件的特定疾病。其他預測包括考慮成分、製造時間等因素來確定藥物的效果。
2. 銀行業
決策樹有助於根據一個人的財務狀況、工資、家庭成員等來預測一個人是否有資格獲得貸款。它還可以識別信用卡欺詐、貸款違約等。
3. 教育部門
可以在決策樹的幫助下根據學生的成績、出勤率等來確定學生的入圍名單。
優勢一覽
- 決策模型的可解釋結果可以呈現給高級管理層和利益相關者。
- 在構建決策樹模型時,不需要對數據進行預處理,即標準化、縮放等。
- 數據類型和分類數據都可以由決策樹處理,該決策樹顯示出比其他算法更高的使用效率。
- 數據中的缺失值不會影響決策樹的過程,從而使其成為一種靈活的算法。
接下來是什麼?
如果您有興趣獲得數據挖掘方面的實踐經驗並接受專家的培訓,您可以查看 upGrad 的數據科學執行 PG 計劃。 該課程面向 21-45 歲之間的任何年齡組,最低資格標準為 50% 或同等畢業及格分數。 任何工作的專業人士都可以加入這個由 IIIT 班加羅爾認證的執行 PG 計劃。
數據挖掘中的決策樹能夠處理非常複雜的數據。 所有的決策樹都有三個重要的節點或部分。 讓我們在下面討論它們中的每一個。 現在我們已經了解了決策樹的工作原理,讓我們嘗試看看在數據挖掘中使用決策樹的一些優點什麼是數據挖掘中的決策樹?
決策樹是在數據挖掘中構建模型的一種方式。 可以理解為倒置二叉樹。 它包括一個根節點、一些分支和最後的葉節點。
決策樹中的每個內部節點都表示對屬性的研究。 每個部分都表示該特定研究或考試的結果。 最後,每個葉節點代表一個類標籤。
構建決策樹的主要目標是通過對先前數據使用判斷程序來創建一個可用於預測特定類別的理想。
我們從根節點開始,與根變量建立一些關係,並進行符合這些值的劃分。 基於基本選擇,我們跳轉到後續節點。 決策樹中使用了哪些重要節點?
當我們連接所有這些節點時,我們就會得到分裂。 我們可以無限次地使用這些節點和劃分來形成具有各種困難的樹。 使用決策樹有什麼好處?
1.當我們將它們與其他方法進行比較時,決策樹在預處理期間不需要太多的計算來訓練數據。
2. 決策樹不涉及信息的穩定化。
3. 此外,它們甚至不需要擴展信息。
4. 即使數據集中省略了一些值,也不會影響樹的構建。
5. 這些模型是相同的本能。 它們的描述也沒有壓力。