
為 Google Assistant 和 Amazon Alexa 創建語音技能
已發表: 2022-03-10在過去的十年中,對話界面發生了翻天覆地的變化。 隨著人們達到“峰值屏幕”,甚至開始縮減他們的設備使用量,大多數操作系統中都包含了數字健康功能。
為了對抗屏幕疲勞,語音助手已經進入市場,成為快速檢索信息的首選。 一個重複的統計數據表明,到 2020 年,50% 的搜索將通過語音完成。此外,隨著採用率的提高,開發人員可以在他們的工具帶中添加“對話界面”和“語音助手”。
設計隱形
對於許多人來說,開始語音 UI (VUI) 項目可能有點像進入未知領域。 詳細了解 William Merrill 在語音設計中的經驗教訓。 閱讀相關文章 →
什麼是會話界面?
會話界面(有時縮寫為 CUI,是人類語言的任何界面。它被認為是比前端開發人員習慣構建的圖形用戶界面 GUI 更自然的界面。GUI 需要人類了解其特定的界面語法(想想按鈕、滑塊和下拉菜單)。
使用人類語言的這一關鍵區別使 CUI 對人們來說更加自然; 它需要的知識很少,並且將理解的負擔放在了設備上。
通常 CUI 有兩種形式:聊天機器人和語音助手。 由於自然語言處理 (NLP) 的進步,在過去十年中,兩者都出現了大幅增長。
了解語音術語

| 關鍵詞 | 意義 |
|---|---|
| 技能/動作 | 一個語音應用,可以實現一系列意圖 |
| 意圖 | 技能實現的預期操作,用戶希望技能做什麼以響應他們所說的內容。 |
| 發聲 | 用戶說或說出的句子。 |
| 喚醒詞 | 用於啟動語音助手收聽的單詞或短語,例如“Hey google”、“Alexa”或“Hey Siri” |
| 語境 | 話語中有助於技能實現意圖的上下文信息片段,例如“今天”、“現在”、“當我到家時”。 |
什麼是語音助手?
語音助手是一款能夠進行 NLP(自然語言處理)的軟件。 它接收語音命令並以音頻格式返回答案。 近年來,與助手互動的範圍正在擴大和發展,但技術的關鍵是自然語言輸入、大量計算、自然語言輸出。
對於那些尋找更多細節的人:
- 該軟件接收來自用戶的音頻請求,將聲音處理成音素,即語言的組成部分。
- 通過 AI(特別是 Speech-To-Text)的魔力,這些音素被轉換為近似請求的字符串,保存在 JSON 文件中,該文件還包含有關用戶、請求和會話的額外信息。
- 然後處理 JSON(通常在雲中)以計算出請求的上下文和意圖。
- 根據意圖,再次在更大的 JSON 響應中返迴響應,以字符串或 SSML 的形式(稍後會詳細介紹)
- 使用 AI(自然是反向 - Text-To-Speech)處理響應,然後將其返回給用戶。
那裡發生了很多事情,其中大部分都不需要再三考慮。 但是每個平台都以不同的方式執行此操作,並且需要更多了解的是平台的細微差別。

支持語音的設備
設備能夠內置語音助手的要求非常低。 它們需要麥克風、互聯網連接和揚聲器。 Nest Mini 和 Echo Dot 等智能揚聲器提供了這種低保真語音控制。
排在第二位的是語音+屏幕,這被稱為“多模式”設備(稍後會詳細介紹),並且是 Nest Hub 和 Echo Show 等設備。 由於智能手機具有此功能,因此它們也可以被視為一種支持多模式語音的設備。
語音技巧
首先,每個平台的“語音技能”都有不同的名稱,亞馬遜使用技能,我將堅持作為一個普遍理解的術語。 谷歌選擇“行動”,三星選擇“膠囊”。
每個平台都有自己的內置技能,比如詢問時間、天氣和體育比賽。 開發人員製造的(第三方)技能可以使用特定的短語來調用,或者,如果平台喜歡它,可以隱式調用,而無需關鍵短語。
顯式調用:“Hey Google,與 <app name> 交談。”
明確說明了要求的技能:
隱式調用:“嘿 Google,今天天氣怎麼樣?”
請求的上下文暗示了用戶想要什麼服務。
有哪些語音助手?
在西方市場,語音助手更像是一場三馬賽跑。 蘋果、谷歌和亞馬遜對他們的助手有非常不同的方法,因此吸引了不同類型的開發者和客戶。
蘋果的 Siri
設備名稱:“Siri”
喚醒短語:“嘿 Siri”
Siri 擁有超過 3.75 億活躍用戶,但為了簡潔起見,我不會對 Siri 進行太多詳細介紹。 雖然它可能在全球範圍內得到很好的採用,並融入了大多數 Apple 設備,但它要求開發人員已經在 Apple 的一個平台上擁有一個應用程序,並且是用 swift 編寫的(而其他的可以用每個人都喜歡的:Javascript 編寫)。 除非您是想要擴展其應用程序產品的應用程序開發人員,否則您目前可以跳過蘋果,直到他們打開他們的平台。
谷歌助理
設備名稱:“Google Home、Nest”
喚醒短語:“嘿谷歌”
谷歌擁有三巨頭中最多的設備,全球超過 10 億台,這主要是由於大量 Android 設備內置了谷歌助手,就其專用的智能揚聲器而言,數量略小一些。 谷歌助手的總體使命是取悅用戶,他們一直非常擅長提供輕巧直觀的界面。
他們在平台上的主要目標是利用時間——希望成為客戶日常生活的一部分。 因此,他們主要關注實用性、家庭樂趣和令人愉快的體驗。
為 Google 打造的技能在參與作品和遊戲時是最好的,主要關注家庭友好的樂趣。 他們最近為遊戲添加的畫布就是這種方法的證明。 谷歌平台對技能的提交要嚴格得多,因此他們的目錄要小得多。
亞馬遜亞歷克斯
設備名稱:“Amazon Fire、Amazon Echo”
喚醒短語:“Alexa”
亞馬遜在 2019 年的設備數量已超過 1 億台,這主要來自其智能揚聲器和智能顯示器的銷售,以及他們的“火”系列或平板電腦和流媒體設備。
為亞馬遜打造的技能往往針對技能購買。 如果您正在尋找一個平台來擴展您的電子商務/服務或提供訂閱服務,那麼亞馬遜就是您的不二之選。 話雖這麼說,ISP 不是 Alexa Skills 的要求,它們支持各種用途,並且對提交更加開放。
其他
還有更多的語音助手,例如三星的 Bixby、微軟的 Cortana 和流行的開源語音助手 Mycroft。 這三者都有合理的追隨者,但與亞馬遜、谷歌和蘋果這三巨頭相比,仍然是少數。
建立在亞馬遜 Alexa 上
亞馬遜語音生態系統已經發展到允許開發人員在 Alexa 控制台內構建他們的所有技能,所以作為一個簡單的例子,我將使用它的內置功能。
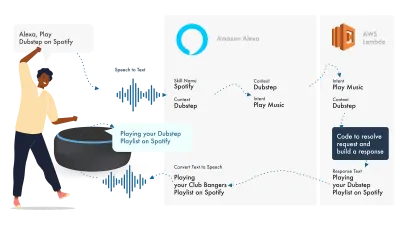
Alexa 處理自然語言處理,然後找到合適的 Intent,將其傳遞給我們的 Lambda 函數來處理邏輯。 這會將一些對話位(SSML、文本、卡片等)返回給 Alexa,Alexa 會將這些位轉換為音頻和視頻以顯示在設備上。
在亞馬遜上工作相對簡單,因為它們允許您在 Alexa 開發人員控制台中創建您的所有技能部分。 使用 AWS 或 HTTPS 端點具有靈活性,但對於簡單的技能,在開發控制台中運行所有內容就足夠了。
讓我們建立一個簡單的 Alexa 技能
前往 Amazon Alexa 控制台,如果您沒有帳戶,請創建一個帳戶,然後登錄,
點擊Create Skill然後給它一個名字,
選擇custom作為您的模型,
並為您的後端資源選擇Alexa-Hosted (Node.js) 。
完成配置後,您將擁有基本的 Alexa 技能,它將為您構建您的意圖,以及一些幫助您入門的後端代碼。
如果您單擊 Intents 中的HelloWorldIntent ,您將看到一些已經為您設置的示例話語,讓我們在頂部添加一個新示例。 我們的技能稱為 hello world,因此添加 Hello World 作為示例話語。 這個想法是捕捉用戶可能會說的任何內容來觸發這個意圖。 這可能是“Hi World”、“Howdy World”等。
Fulfillment JS 中發生了什麼?
那麼代碼在做什麼呢? 這是默認代碼:
const HelloWorldIntentHandler = { canHandle(handlerInput) { return Alexa.getRequestType(handlerInput.requestEnvelope) === 'IntentRequest' && Alexa.getIntentName(handlerInput.requestEnvelope) === 'HelloWorldIntent'; }, handle(handlerInput) { const speakOutput = 'Hello World!'; return handlerInput.responseBuilder .speak(speakOutput) .getResponse(); } }; 這是利用ask-sdk-core ,本質上是為我們構建 JSON。 canHandle讓 ask 知道它可以處理意圖,特別是“HelloWorldIntent”。 handle接受輸入,並構建響應。 這生成的內容如下所示:
{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }
我們可以在我們的 json 中看到speak輸出 ssml,這是用戶將聽到的 Alexa 所說的內容。

為 Google 助理構建
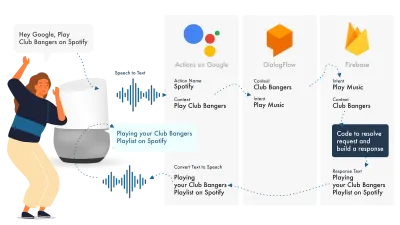
在 Google 上構建 Actions 的最簡單方法是將其 AoG 控制台與 Dialogflow 結合使用,您可以使用 firebase 擴展您的技能,但與 Amazon Alexa 教程一樣,讓我們保持簡單。
Google Assistant 使用三個主要部分,AoG 處理 NLP,Dialogflow 處理你的意圖,Firebase 滿足請求並產生將發送回 AoG 的響應。
與 Alexa 一樣,Dialogflow 允許您直接在平台內構建函數。
讓我們在 Google 上建立行動
Google 的解決方案可以同時使用三個平台,它們可以通過三個不同的控制台訪問,所以請注意!
設置對話流
讓我們從登錄 Dialogflow 控制台開始。 登錄後,從 Dialogflow 徽標正下方的下拉列表中創建一個新代理。
為您的代理命名,並添加“Google Project Dropdown”,同時選擇“Create a new Google project”。
點擊創建按鈕,讓它發揮它的魔力,設置代理需要一點時間,所以請耐心等待。
設置 Firebase 函數
好了,現在我們可以開始插入 Fulfillment 邏輯了。
前往履行選項卡。 勾選啟用內聯編輯器,並使用下面的 JS 片段:
index.js
'use strict'; // So that you have access to the dialogflow and conversation object const { dialogflow } = require('actions-on-google'); // So you have access to the request response stuff >> functions.https.onRequest(app) const functions = require('firebase-functions'); // Create an instance of dialogflow for your app const app = dialogflow({debug: true}); // Build an intent to be fulfilled by firebase, // the name is the name of the intent that dialogflow passes over app.intent('Default Welcome Intent', (conv) => { // Any extra logic goes here for the intent, before returning a response for firebase to deal with return conv.ask(`Welcome to a firebase fulfillment`); }); // Finally we export as dialogflowFirebaseFulfillment so the inline editor knows to use it exports.dialogflowFirebaseFulfillment = functions.https.onRequest(app);包.json
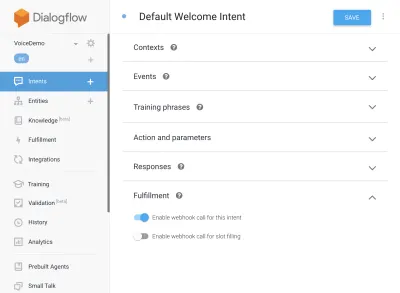
{ "name": "functions", "description": "Cloud Functions for Firebase", "scripts": { "lint": "eslint .", "serve": "firebase serve --only functions", "shell": "firebase functions:shell", "start": "npm run shell", "deploy": "firebase deploy --only functions", "logs": "firebase functions:log" }, "engines": { "node": "10" }, "dependencies": { "actions-on-google": "^2.12.0", "firebase-admin": "~7.0.0", "firebase-functions": "^3.3.0" }, "devDependencies": { "eslint": "^5.12.0", "eslint-plugin-promise": "^4.0.1", "firebase-functions-test": "^0.1.6" }, "private": true }現在回到您的意圖,轉到默認歡迎意圖,然後向下滾動到實現,確保選中“為此意圖啟用 webhook 調用”以查看您希望使用 javascript 實現的任何意圖。 點擊保存。
設置 AoG
我們現在正在接近終點線。 轉到集成選項卡,然後單擊頂部 Google 助理選項中的集成設置。 這將打開一個模式,所以讓我們點擊測試,這將使您的 Dialogflow 與 Google 集成,並在 Google 上的 Actions 上打開一個測試窗口。
在測試窗口上,我們可以單擊與我的測試應用程序交談(我們將在一秒鐘內更改它),瞧,我們的 javascript 消息顯示在谷歌助手測試中。
我們可以在頂部的“開發”選項卡中更改助手的名稱。
那麼在 Fulfillment JS 中發生了什麼?
首先,我們使用了兩個 npm 包,actions-on-google,它提供了 AoG 和 Dialogflow 所需的所有功能,其次是 firebase-functions,你猜對了,它包含 firebase 的幫助程序。
然後我們創建“app”,它是一個包含我們所有意圖的對象。
創建的每個意圖都傳遞了“conv”,它是 Google 上的 Actions 發送的對話對象。 我們可以使用 conv 的內容來檢測有關先前與用戶交互的信息(例如他們的 ID 和有關他們與我們的會話的信息)。
我們返回一個“conv.ask 對象”,其中包含我們給用戶的返回消息,準備好讓他們以另一個意圖進行響應。 如果我們想在那裡結束對話,我們可以使用“conv.close”來結束對話。
最後,我們將所有內容封裝在一個 firebase HTTPS 函數中,該函數為我們處理服務器端請求-響應邏輯。
同樣,如果我們查看生成的響應:
{ "payload": { "google": { "expectUserResponse": true, "richResponse": { "items": [ { "simpleResponse": { "textToSpeech": "Welcome to a firebase fulfillment" } } ] } } } } 我們可以看到conv.ask已將其文本注入到textToSpeech區域。 如果我們選擇了conv.close , expectUserResponse將設置為false ,並且在消息傳遞後對話將關閉。
第三方語音生成器
就像應用程序行業一樣,隨著語音越來越受歡迎,第 3 方工具已經開始出現,試圖減輕開發人員的負擔,允許他們構建一次部署兩次。
Jovo 和 Voiceflow 是目前最受歡迎的兩個,尤其是在 PullString 被 Apple 收購之後。 每個平台都提供了不同級別的抽象,所以這真的取決於你對界面的簡化程度。
擴展你的技能
現在您已經開始了解如何構建基本的“Hello World”技能,可以為您的技能添加大量的花里胡哨。 這些是語音助手蛋糕上的櫻桃,將為您的用戶帶來很多額外價值,從而帶來重複定制和潛在的商業機會。
SSML
SSML 代表語音合成標記語言,使用與 HTML 類似的語法運行,主要區別在於您正在構建語音響應,而不是網頁上的內容。
'SSML' 作為一個術語有點誤導,它可以做的不僅僅是語音合成! 你可以讓聲音並行,你可以包括環境噪音、speechcons(值得一聽,想想著名短語的表情符號)和音樂。
什麼時候應該使用 SSML?
SSML 很棒; 它為用戶提供了更具吸引力的體驗,但同時也降低了音頻輸出的靈活性。 我建議將它用於更靜態的語音區域。 您可以將其中的變量用於名稱等,但除非您打算構建 SSML 生成器,否則大多數 SSML 將是相當靜態的。
從您的技能中的簡單演講開始,一旦完成,使用 SSML 增強更靜態的區域,但在繼續花里胡哨之前先讓您的核心正確。 話雖如此,最近的一份報告稱 71% 的用戶更喜歡人類(真實)聲音而不是合成聲音,所以如果你有能力這樣做,那就去做吧!

在技能購買中
技能內購買(或 ISP)類似於應用內購買的概念。 技能往往是免費的,但有些技能允許在應用程序內購買“高級”內容/訂閱,這些可以增強用戶體驗、解鎖遊戲新關卡或允許訪問付費內容。
多式聯運
多模式響應所涵蓋的範圍遠不止語音,這就是語音助手可以在支持它們的設備上以互補的視覺效果真正閃耀的地方。 多模式體驗的定義要廣泛得多,本質上意味著多種輸入(鍵盤、鼠標、觸摸屏、語音等)。
多模式技能旨在補充核心語音體驗,提供額外的補充信息以提升用戶體驗。 在構建多模式體驗時,請記住語音是信息的主要載體。 許多設備沒有屏幕,因此您的技能仍然需要在沒有屏幕的情況下發揮作用,因此請確保使用多種設備類型進行測試; 無論是真實的還是在模擬器中。

多種語言
多語言技能是可以使用多種語言並將您的技能打開到多個市場的技能。
使你的技能多語言的複雜性取決於你的反應有多動態。 具有相對靜態響應的技能,例如每次返回相同的短語,或者只使用一小部分短語,比龐大的動態技能更容易製作多語言。
多語種的訣竅是擁有一個值得信賴的翻譯合作夥伴,無論是通過代理商還是 Fiverr 上的翻譯。 您需要能夠信任所提供的翻譯,特別是如果您不理解被翻譯成的語言。 谷歌翻譯不會在這裡減少芥末!
結論
如果有時間進入語音行業,那就是現在。 無論是處於鼎盛時期還是處於起步階段,以及九大巨頭,都在投入數十億美元來發展它,並將語音助手帶入每個人的家中和日常生活中。
選擇要使用的平台可能很棘手,但根據您打算構建的內容,要使用的平台應該大放異彩,否則,使用第三方工具來對沖您的賭注並在多個平台上構建,特別是如果您的技能運動部件更少,複雜度更低。
一方面,我對語音無處不在的未來感到興奮。 屏幕依賴將減少,客戶將能夠與他們的助手自然互動。 但首先,我們要培養人們希望從助手那裡獲得的技能。