
使用 Scrapy 構建可擴展 Web Scraper 的終極指南
已發表: 2022-03-10Web 抓取是一種無需訪問 API 或網站數據庫即可從網站獲取數據的方法。 你只需要訪問網站的數據——只要你的瀏覽器可以訪問數據,你就可以抓取它。
實際上,大多數情況下,您可以手動瀏覽網站並使用複制和粘貼“手動”獲取數據,但在很多情況下,這將花費您數小時的手動工作,最終可能會花費您遠遠超過數據的價值,特別是如果您聘請了某人為您完成任務。 當您可以讓程序每隔幾秒自動執行一次查詢時,為什麼還要雇人以每個查詢 1 到 2 分鐘的時間工作呢?
例如,假設您希望編制一份奧斯卡最佳影片獎得主名單,以及他們的導演、主演、上映日期和放映時間。 使用谷歌,你可以看到有幾個網站會按名稱列出這些電影,也許還有一些額外的信息,但通常你必須通過鏈接來獲取你想要的所有信息。
顯然,遍歷從 1927 年到今天的每個鏈接並手動嘗試通過每個頁面查找信息是不切實際且耗時的。 通過網絡抓取,我們只需要找到一個包含所有這些信息的頁面的網站,然後用正確的指令將我們的程序指向正確的方向。
在本教程中,我們將使用 Wikipedia 作為我們的網站,因為它包含我們需要的所有信息,然後使用 Python 上的 Scrapy 作為一種工具來抓取我們的信息。
在我們開始之前有幾點注意事項:
數據抓取涉及增加您正在抓取的站點的服務器負載,這意味著託管該站點的公司的成本更高,而該站點的其他用戶的體驗質量較低。 運行網站的服務器的質量、您嘗試獲取的數據量以及您向服務器發送請求的速率將緩和您對服務器的影響。 牢記這一點,我們需要確保遵守一些規則。
大多數站點的主目錄中還有一個名為robots.txt的文件。 該文件規定了網站不希望抓取工具訪問哪些目錄的規則。 網站的條款和條件頁面通常會讓您知道他們的數據抓取政策是什麼。 例如,IMDB 的條件頁面有以下子句:
機器人和屏幕抓取:您不得在本網站上使用數據挖掘、機器人、屏幕抓取或類似的數據收集和提取工具,除非得到我們如下所述的明確書面同意。
在我們嘗試獲取網站的數據之前,我們應該始終查看網站的條款和robots.txt ,以確保我們獲取的是合法數據。 在構建我們的爬蟲時,我們還需要確保我們不會用它無法處理的請求來壓倒服務器。
幸運的是,許多網站認識到用戶需要獲取數據,並通過 API 提供數據。 如果這些可用,通過 API 獲取數據通常比通過抓取更容易。
維基百科允許數據抓取,只要機器人不會“太快”,如robots.txt中所述。 他們還提供可下載的數據集,以便人們可以在自己的機器上處理數據。 如果我們走得太快,服務器會自動阻止我們的 IP,因此我們將實施計時器以保持在他們的規則範圍內。
入門,使用 Pip 安裝相關庫
首先,首先,讓我們安裝 Scrapy。
視窗
從 https://www.python.org/downloads/windows/ 安裝最新版本的 Python
注意: Windows 用戶還需要 Microsoft Visual C++ 14.0,您可以從此處的“Microsoft Visual C++ Build Tools”中獲取。
您還需要確保您擁有最新版本的 pip。
在cmd.exe中,輸入:
python -m pip install --upgrade pip pip install pypiwin32 pip install scrapy這將自動安裝 Scrapy 和所有依賴項。
Linux
首先,您需要安裝所有依賴項:
在終端中,輸入:
sudo apt-get install python3 python3-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev全部安裝完成後,只需輸入:
pip install --upgrade pip確保 pip 已更新,然後:
pip install scrapy這一切都完成了。
蘋果
首先,您需要確保您的系統上有一個 c 編譯器。 在終端中,輸入:
xcode-select --install之後,從 https://brew.sh/ 安裝自製軟件。
更新您的 PATH 變量,以便在系統包之前使用自製包:
echo "export PATH=/usr/local/bin:/usr/local/sbin:$PATH" >> ~/.bashrc source ~/.bashrc安裝 Python:
brew install python然後確保所有內容都已更新:
brew update; brew upgrade python完成後,只需使用 pip 安裝 Scrapy:
pip install Scrapy > ## Scrapy 概述、各部分如何組合、解析器、蜘蛛等您將編寫一個名為“蜘蛛”的腳本供 Scrapy 運行,但不要擔心,儘管 Scrapy 蜘蛛有名字,但它一點也不可怕。 Scrapy 蜘蛛和真正的蜘蛛唯一的相似之處是它們喜歡在網上爬行。
蜘蛛內部是一個你定義的class ,它告訴 Scrapy 要做什麼。 例如,從哪裡開始爬網、它發出的請求類型、如何跟踪頁面上的鏈接以及它如何解析數據。 您甚至可以添加自定義函數來處理數據,然後再輸出回文件。
要啟動我們的第一個蜘蛛,我們首先需要創建一個 Scrapy 項目。 為此,請在命令行中輸入:
scrapy startproject oscars這將為您的項目創建一個文件夾。
我們將從一個基本的蜘蛛開始。 以下代碼將被輸入到 python 腳本中。 在/oscars/spiders中打開一個新的 python 腳本並將其命名為oscars_spider.py
我們將導入 Scrapy。
import scrapy然後我們開始定義我們的 Spider 類。 首先,我們設置名稱,然後設置允許蜘蛛抓取的域。 最後,我們告訴蜘蛛從哪裡開始抓取。
class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ['https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture']接下來,我們需要一個函數來捕獲我們想要的信息。 現在,我們只獲取頁面標題。 我們使用 CSS 找到帶有標題文本的標籤,然後我們將其提取出來。 最後,我們將信息返回給 Scrapy 以記錄或寫入文件。
def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield data 現在將代碼保存在/oscars/spiders/oscars_spider.py
要運行此蜘蛛,只需轉到您的命令行並鍵入:
scrapy crawl oscars你應該看到這樣的輸出:
2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)
恭喜,你已經構建了你的第一個基本的 Scrapy 刮板!

完整代碼:
import scrapy class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield data顯然,我們希望它做更多的事情,所以讓我們看看如何使用 Scrapy 來解析數據。
首先,讓我們熟悉一下 Scrapy shell。 Scrapy shell 可以幫助您測試您的代碼,以確保 Scrapy 正在抓取您想要的數據。
要訪問 shell,請在命令行中輸入:
scrapy shell “https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture”這基本上會打開您將其定向到的頁面,並允許您運行單行代碼。 例如,您可以通過鍵入以下內容來查看頁面的原始 HTML:
print(response.text)或者在默認瀏覽器中輸入以下內容打開頁面:
view(response)我們的目標是找到包含我們想要的信息的代碼。 現在,讓我們嘗試只獲取電影名稱。
找到我們需要的代碼的最簡單方法是在瀏覽器中打開頁面並檢查代碼。 在此示例中,我使用的是 Chrome DevTools。 只需右鍵單擊任何電影標題並選擇“檢查”:
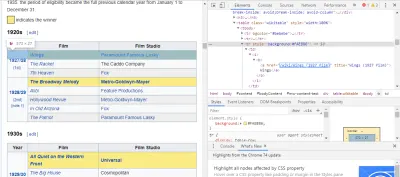
如您所見,奧斯卡獲獎者的背景為黃色,而提名者的背景則為純色。 還有一個關於電影標題的文章的鏈接,電影的鏈接以電影結尾film) 。 現在我們知道了這一點,我們可以使用 CSS 選擇器來獲取數據。 在 Scrapy shell 中,輸入:
response.css(r"tr[] a[href*='film)']").extract()如您所見,您現在擁有所有奧斯卡最佳影片獲獎者的名單!
> response.css(r"tr[] a[href*='film']").extract() ['<a href="/wiki/Wings_(1927_film)" title="Wings (1927 film)">Wings</a>', ... '<a href="/wiki/Green_Book_(film)" title="Green Book (film)">Green Book</a>', '<a href="/wiki/Jim_Burke_(film_producer)" title="Jim Burke (film producer)">Jim Burke</a>']回到我們的主要目標,我們想要一份奧斯卡最佳影片獎得主名單,以及他們的導演、主演、上映日期和放映時間。 為此,我們需要 Scrapy 從每個電影頁面中獲取數據。
我們將不得不重寫一些東西並添加一個新函數,但別擔心,這很簡單。
我們將首先以與以前相同的方式啟動刮板。
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] 但這一次,有兩件事會改變。 首先,我們將與scrapy一起導入time ,因為我們想創建一個計時器來限制機器人抓取的速度。 此外,當我們第一次解析頁面時,我們只想獲取每個標題的鏈接列表,因此我們可以從這些頁面中獲取信息。
def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req 在這裡,我們創建一個循環來查找頁面上以film)結尾的每個鏈接,其中包含黃色背景,然後我們將這些鏈接連接到一個 URL 列表中,我們將發送到函數parse_titles以進一步傳遞。 我們還設置了一個計時器,使其僅每 5 秒請求一次頁面。 請記住,我們可以使用 Scrapy shell 來測試我們的response.css字段,以確保我們得到正確的數據!
def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield data 真正的工作在我們的parse_data函數中完成,我們在其中創建一個名為data的字典,然後用我們想要的信息填充每個鍵。 同樣,所有這些選擇器都是使用 Chrome DevTools 找到的,如前所述,然後使用 Scrapy shell 進行測試。
最後一行將數據字典返回給 Scrapy 進行存儲。
完整代碼:
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield data有時我們會想要使用代理,因為網站會試圖阻止我們的抓取嘗試。
為此,我們只需要更改一些內容。 使用我們的示例,在我們的def parse()中,我們需要將其更改為以下內容:
def parse(self, response): for href in (r"tr[] a[href*='film)']::attr(href)").extract() : url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) req.meta['proxy'] = "https://yourproxy.com:80" yield req這將通過您的代理服務器路由請求。
部署和日誌記錄,展示如何在生產環境中實際管理蜘蛛
現在是時候運行我們的蜘蛛了。 要讓 Scrapy 開始抓取然後輸出到 CSV 文件,請在命令提示符中輸入以下內容:
scrapy crawl oscars -o oscars.csv你會看到一個很大的輸出,幾分鐘後,它會完成,你的項目文件夾中會有一個 CSV 文件。
編譯結果,展示如何使用前面步驟中編譯的結果
當您打開 CSV 文件時,您將看到我們想要的所有信息(按帶有標題的列排序)。 真的就是這麼簡單。
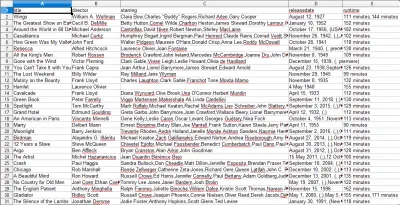
通過數據抓取,我們可以獲得幾乎任何我們想要的自定義數據集,只要信息是公開可用的。 你想用這些數據做什麼取決於你。 這項技能對於進行市場研究、更新網站上的信息以及許多其他事情非常有用。
設置您自己的網絡抓取工具以自行獲取自定義數據集相當容易,但是,請始終記住,可能還有其他方法可以獲取您需要的數據。 企業在提供您想要的數據方面投入了大量資金,因此我們尊重他們的條款和條件是公平的。
了解更多關於 Scrapy 和 Web Scraping 的其他資源
- Scrapy 官方網站
- Scrapy 的 GitHub 頁面
- “10 種最佳數據抓取工具和 Web 抓取工具”,Scraper API
- “在不被阻止或列入黑名單的情況下進行 Web 抓取的 5 個技巧”,Scraper API
- Parsel,一個使用正則表達式從 HTML 中提取數據的 Python 庫。