
2022 年 15 大 Hadoop 面試問答
已發表: 2021-01-09隨著數據分析的發展勢頭強勁,對擅長處理大數據的人的需求激增。 從數據分析師到數據科學家,大數據今天正在創建一系列工作檔案。 您需要親身體驗的第一件事是 Hadoop。
無論何種工作角色/資料,您都可能以一種或另一種方式在 Hadoop 上工作。 因此,您總是可以期望面試官按照您的方式提出一些 Hadoop 問題。
為此,讓我們看一下在您參加的任何面試中都可能出現的 15 個 Hadoop 面試問題。
什麼是 Hadoop? Hadoop的主要組件是什麼?
Hadoop 是一種基礎設施,配備了處理和存儲大數據所需的相關工具和服務。 準確地說,Hadoop 是所有大數據挑戰的“解決方案”。 此外,Hadoop 框架還可以幫助組織分析大數據並做出更好的業務決策。
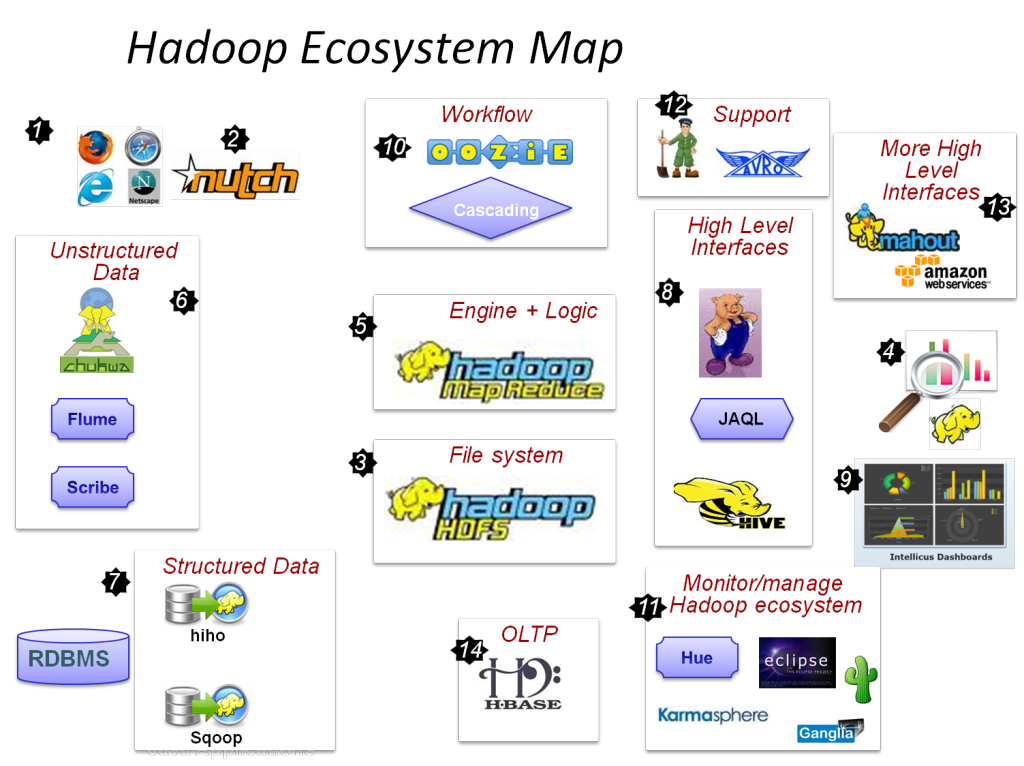
Hadoop的主要組件是:
- 高密度文件系統
- Hadoop MapReduce
- Hadoop 通用
- 紗
- PIG 和 HIVE – 數據訪問組件。
- HBase – 用於數據存儲
- Ambari、Oozie 和 ZooKeeper – 數據管理和監控組件
- Thrift 和 Avro – 數據序列化組件
- Apache Flume、Sqoop、Chukwa – 數據集成組件
- Apache Mahout 和 Drill – 數據智能組件
Hadoop框架的核心概念是什麼?
Hadoop 基本上基於兩個核心概念。 他們是:
- HDFS:HDFS 或 Hadoop 分佈式文件系統是一種基於 Java 的可靠文件系統,用於以塊格式存儲大量數據集。 主從架構為其提供動力。
- MapReduce:MapReduce 是一種有助於處理大型數據集的編程結構。 該函數進一步分為兩部分——“map”將數據集分離為元組,“reduce”使用映射元組並創建較小元組塊的組合。
說出 Hadoop 中最常見的輸入格式?
Hadoop中有三種常見的輸入格式:
- 文本輸入格式:這是 Hadoop 中的默認輸入格式。
- 序列文件輸入格式:此輸入格式用於按順序讀取文件。
- Key Value Input Format:這個是用來讀取純文本文件的。
什麼是紗線?
YARN 是 Yet Another Resource Negotiator 的縮寫。 它是 Hadoop 的數據處理框架,用於管理數據資源並為成功處理創建環境。 
什麼是“機架意識”?
“機架感知”是 NameNode 用來確定數據塊及其副本存儲在 Hadoop 集群中的模式的算法。 這是在機架定義的幫助下實現的,這些定義減少了同一機架中包含的數據節點之間的擁塞。

什麼是主動和被動 NameNode?
一個高可用性 Hadoop 系統通常包含兩個 NameNode——Active NameNode 和 Passive NameNode。
運行 Hadoop 集群的 NameNode 稱為 Active NameNode,存儲 Active NameNode 數據的備用 NameNode 稱為 Passive NameNode。
擁有兩個 NameNode 的目的是,如果 Active NameNode 崩潰,Passive NameNode 可以帶頭。 因此,NameNode 始終在集群中運行,系統永遠不會出現故障。
Hadoop 框架中有哪些不同的調度程序?
Hadoop框架中有三種不同的調度器:
- COSHH – COSHH 通過審查集群和工作負載以及異構性來幫助安排決策。
- FIFO 調度程序 – FIFO 根據到達時間在隊列中排列作業,不使用異質性。
- 公平共享——公平共享為單個用戶創建了一個包含多個地圖的池,並減少了資源上的插槽,他們可以使用這些資源執行特定的作業。
什麼是投機執行?
通常在 Hadoop 框架中,某些節點的運行速度可能比其他節點慢。 這往往會限制整個程序。 為了克服這個問題,Hadoop 首先檢測或“推測”某個任務的運行速度是否比平時慢,然後為該任務啟動等效備份。 因此,在這個過程中,主節點同時執行這兩個任務,並且首先完成的任務被接受,而另一個被殺死。 Hadoop 的這種備份功能稱為推測執行。

命名 Apache HBase 的主要組件?
Apache HBase 由三個組件組成:
- Region Server:一張表被劃分為多個Region後,這些Region的集群通過Region Server轉發給客戶端。
- HMaster:這是一個幫助管理和協調Region服務器的工具。
- ZooKeeper:ZooKeeper 是 HBase 分佈式環境中的協調器。 它通過會話中的通信幫助維護集群內的服務器狀態。
什麼是“檢查點”? 它有什麼好處?
檢查點是指將 FsImage 和 Edit log 組合以形成新 FsImage 的過程。 因此,NameNode 可以直接從 FsImage 加載最終的內存狀態,而不是重播編輯日誌。 輔助 NameNode 負責此過程。
Checkpointing 提供的好處是它最大限度地減少了 NameNode 的啟動時間,從而使整個過程更加高效。
流行文化中的大數據應用
如何調試 Hadoop 代碼?
要調試 Hadoop 代碼,首先,您需要檢查當前正在運行的 MapReduce 任務列表。 然後您需要檢查是否有任何孤立任務同時運行。 如果是這樣,您需要按照以下簡單步驟查找資源管理器日誌的位置:
運行“ps –ef | grep –I ResourceManager”,然後在顯示的結果中,嘗試查找是否存在與特定作業 id 相關的錯誤。
現在,確定用於執行任務的工作節點。 登錄節點並運行“ps –ef | grep –iNodeManager。”
最後,仔細檢查節點管理器日誌。 大多數錯誤是從每個 map-reduce 作業的用戶級別日誌生成的。
Hadoop 中 RecordReader 的用途是什麼?
Hadoop 將數據分解為塊格式。 RecordReader 有助於將這些數據塊集成到單個可讀記錄中。 例如,如果輸入數據被分成兩個塊——
第 1 行 - 歡迎來到
第 2 行 - 升級
RecordReader 會將其讀取為“歡迎來到 UpG rad”。
Hadoop 可以在哪些模式下運行?
Hadoop可以運行的模式有:
- 獨立模式 – 這是 Hadoop 的默認模式,用於調試目的。 它不支持 HDFS。
- 偽分佈式模式——該模式需要配置mapred-site.xml、core-site.xml和hdfs-site.xml文件。 這裡的主節點和從節點都是一樣的。
- 完全分佈式模式——完全分佈式模式是 Hadoop 的生產階段,其中數據分佈在 Hadoop 集群上的各個節點上。 這裡,主節點和從節點是分開分配的。
列舉一些 Hadoop 的實際應用。
以下是 Hadoop 發揮作用的一些真實實例:
- 管理街道交通
- 欺詐檢測和預防
- 實時分析客戶數據以改善客戶服務
- 訪問來自醫生、HCP 等的非結構化醫療數據,以改善醫療保健服務。
可以提高大數據性能的重要 Hadoop 工具有哪些?
顯著提高大數據性能的 Hadoop 工具是

• 蜂巢
• HDFS
• HBase
• SQL
• NoSQL
• Oozie
• 雲
• Avro
• 水槽
• 動物園管理員
大數據工程師:神話與現實
結論
這些 Hadoop 面試問題應該對你下次面試有很大幫助。 雖然有時面試官傾向於扭曲一些 Hadoop 面試問題,但如果你已經整理好基礎知識,這對你來說應該不是問題。
如果您有興趣了解有關大數據的更多信息,請查看我們的 PG 大數據軟件開發專業文憑課程,該課程專為在職專業人士設計,提供 7 多個案例研究和項目,涵蓋 14 種編程語言和工具,實用的動手操作研討會,超過 400 小時的嚴格學習和頂級公司的就業幫助。