
機器學習背後的數學:你需要知道什麼?
已發表: 2021-03-10機器學習是人工智能的一個部門,專注於通過準確處理可用數據來構建應用程序。 機器學習的主要目的是幫助計算機在沒有人為乾預的情況下處理計算。 這是通過允許機器通過有監督或無監督的學習方法來學習模仿人類智能來實現的。
機器學習是許多領域的組合,包括統計、概率、線性代數、微積分等,基於這些領域,機器學習模型可以創建或輸入算法以根據人類智能進行即興創作。 應用程序越複雜,其算法就越複雜。
從數字助理和智能設備到根據您的在線活動推薦您喜歡的產品的網站,以及通知您航班時刻表的手機,基於機器學習的產品和工具無處不在。 隨著我們對智能設備和電器的依賴增加,對機器學習實施的需求也將增加。
為此,在本文中,我們將探討編寫機器學習算法並實現它們所需的數學概念。
目錄
數學在機器學習中的意義是什麼?
機器學習應用程序提供從可用數據中收集的分析和見解,這些數據有助於企業製定可行的決策。 由於機器學習圍繞著研究和實施算法,所以加強你的數學技能很重要。 它有助於消除不確定性並準確預測涉及復雜數據參數和特徵的數據值。 它還有助於我們更好地理解偏差-方差權衡。
掌握機器學習需要了解數學概念,如線性代數、向量微積分、解析幾何、矩陣分解、概率和統計。 深入掌握這些有助於創建直觀的機器學習應用程序。

線性代數
線性代數關注向量和矩陣,主要圍繞計算展開。 它在機器學習和深度學習技術中起著不可或缺的作用。 根據 Skyler Speakman的說法,它是 21 世紀的數學。
ML 工程師和數據科學家或研究人員通常使用線性代數來構建線性算法、邏輯回歸、決策樹和支持向量機。
結石
微積分驅動機器學習算法。 如果不了解其概念,就不可能使用給定的數據集預測結果。 微積分有助於分析數量變化的速率,並關注機器學習算法的最佳性能。 積分、微分、極限和導數是一些有助於訓練深度神經網絡的微積分概念。
可能性
機器學習中的概率預測了一組結果,而統計數據將有利的結果推向了結論。 事件可以像扔硬幣一樣簡單。 概率可以分為兩類:條件概率和聯合概率。 當事件彼此獨立時發生聯合概率,而當一個事件取代另一個事件時發生條件概率。
統計數據
統計側重於算法的定量和定性方面。 它通過簡潔地呈現它幫助我們確定目標並將收集的數據轉換為精確的觀察結果。 機器學習中的統計側重於描述性統計和推論統計。
描述性統計涉及描述和總結模型正在處理的小型數據集。 這裡使用的方法是平均值、中位數、眾數、標準差和變異。 最終結果以圖形表示。
推論統計處理在處理大型數據集時從給定樣本中提取見解。 推理統計允許機器分析超出所提供信息範圍的數據。 假設檢驗、抽樣分佈、方差分析是推論統計的某些方面。
除此之外,編碼能力是機器學習的關鍵先決條件。 Python 和 Java 等語言的專業知識有助於更好地理解數據建模。 字符串格式化、定義函數、具有多個變量迭代器的循環、if 或 else 條件表達式是它的一些基本功能。
至於數據建模,它是我們估計數據集結構並檢測可能的變化和模式的過程。 為了能夠做出準確的預測,必須了解集體數據的各種屬性。
你如何學習機器學習?
雖然機器學習是一個利潤豐厚的領域,但它需要大量的練習和耐心。 鑑於其在當今幾乎所有行業中的應用,機器學習工程師的需求量很大。
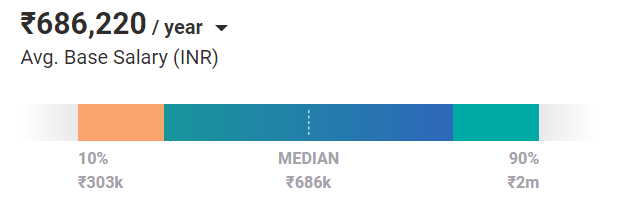
具有機器學習背景的入門級工程師的平均工資為 68.6 萬盧比/年。 隨著經驗和技能的提高,獲得更高薪水的潛力呈指數級增長。
有幾門課程可供希望增強機器學習知識基礎的人使用。 掌握這門學科至少需要 6 個月到 2 年的時間。
至少擁有學士學位和一年的工作經驗,最好是數學或統計學學位,您可以在upGrad上攻讀以下任何一門課程,以增加您在該領域取得成功的機會。

- IIT班加羅爾機器學習和深度學習高級證書課程(6個月)
- IIT Bangalore機器學習和 NLP 高級證書課程(6 個月)
- 來自 IIT 班加羅爾的機器學習和人工智能執行 PG 計劃(12 個月)
- IIT Madras機器學習和雲高級認證(12 個月)
- LJMU 和 IIT Bangalore機器學習和人工智能理學碩士(18 個月)
所有這些課程都提供至少 240 多個小時的學習時間和至少 5 個案例研究,這將幫助您深入了解機器學習及其各種輔助領域。 您可以涵蓋構成編碼支柱的基本主題,如 Python、MySQL、Tensor、NLTK、statsmodels、excel 等。 以下是機器學習中各種upGrad 課程的詳細介紹,因此您可以選擇最適合您的課程。
加入來自世界頂級大學的在線人工智能課程——碩士、高管研究生課程和 ML 和 AI 高級證書課程,以加快您的職業生涯。
機器學習的應用
機器學習在我們的日常生活中發揮著至關重要的作用,無論是在專業領域還是個人領域。 它的分析和直覺能力有可能極大地影響我們執行日常任務的方式。 事實證明,它在為組織節省金錢和時間方面足智多謀。
雖然機器學習是一個廣泛的領域,幾乎在每個行業都有應用,但這裡有一些最突出的例子:
- 圖像識別是最常用的應用程序之一,因為它有助於人臉檢測,因此為每個人創建一個單獨的數據庫。 它也可以用來識別手寫風格。
- 衛生部門的機器學習增強了衛生保健提供者的能力。 它可以用於更快的醫療診斷。 在許多情況下,人工智能有助於疾病的早期診斷,從而使醫生能夠提出有可能挽救生命的治療和預防措施。
- 機器學習在涉及投資、併購的金融領域有重要應用。 它幫助銀行和其他經濟機構做出明智的選擇。
- 它的有效性可能在客戶關懷和服務行業最為明顯,因為機器學習可以簡化操作并快速、更有效地提供解決方案。
- 機器學習使原本必須由現場人員執行的任務自動化。 例如,如果我們要考慮虛擬助手,它可能是一項簡單的任務,比如更改密碼,或者晚上檢查你的銀行餘額。 通過機器學習,現在可以將人力資源分配給需要復雜決策或人工操作才能完成的更緊迫的任務。
機器學習的未來範圍
儘管機器學習已經存在了幾十年,但它的應用在今天最為明顯。 該行業尚未繁榮,即興發揮,這意味著機器學習的未來是光明的。 大多數大型公司已經從機器學習中獲益,並擴展其服務和產品以推動增長。
自然地,機器學習工程師的需求量很大,機器學習本身就是一個利潤豐厚的職業。 它代表了企業所需的優勢。 到目前為止,人工智能已經創造了大約 230 萬個就業機會。 預計到 2022 年底,全球機器學習行業將以 42.2% 的複合年增長率增長,達到 90 億美元。
以下是機器學習的幾個主要趨勢:
- 越來越多的算法正在學習無監督實現。 企業正在投資基於這些有可能改變機器學習的無監督算法的量子計算。 這些有助於分析和得出有意義的見解,從而幫助企業實現使用經典機器學習技術無法實現的更好結果。
- 人工智能驅動的機器人正在被部署來開展業務運營。 然而,這些技術還處於初期階段,隨著企業投資建立人工智能和機器學習的立足點,機器人將很快幫助成倍地提高生產力。 舉個例子,我們在消費市場上將無人機偽裝成強大的商業工具,用於完成商業運營和交付貨物等簡單任務。
- 機器學習算法支持增強的個性化。 這些算法調查潛在客戶的在線行為並將信息發送回公司。 這些公司反過來向他們發送產品和服務建議。 這些機器學習技術有助於識別客戶的好惡。 通過機器學習,公司可以為客戶提供他們想要的東西,並在他們想要的時候提供,從而提高客戶保留率並為組織吸引更多業務。 改進的個性化是機器學習的未來。
- 得益於增強的機器學習算法,移動和 Web 應用程序現在比以往任何時候都更加智能。 改進的認知服務允許開發人員根據視覺識別、他們的語音、聲音、語音等為每個客戶創建單獨的數據庫。
這將我們帶到了文章的結尾。 我們希望這些信息對您有所幫助!
為什麼線性回歸需要同方差性?
同方差性描述了數據與平均值的相似程度或偏離程度。 這是一個重要的假設,因為參數統計測試對差異很敏感。 異方差性不會在係數估計中引起偏差,但會降低它們的精度。 精度越低,係數估計就越可能偏離正確的總體值。 為了避免這種情況,同方差性是斷言的關鍵假設。
線性回歸中多重共線性的兩種類型是什麼?
數據和結構多重共線性是多重共線性的兩種基本類型。 當我們從其他項中創建一個模型項時,我們會得到結構多重共線性。 換句話說,它不是出現在數據本身中,而是我們提供的模型的結果。 雖然數據多重共線性不是我們模型的產物,但它存在於數據本身中。 數據多重共線性在觀察性調查中更為常見。
使用 t 檢驗進行獨立檢驗的缺點是什麼?
使用配對樣本 t 檢驗時,重複測量而不是組設計之間的差異存在問題,這會導致結轉效應。 由於 I 類錯誤,t 檢驗不能用於多重比較。 在對一組樣本進行配對 t 檢驗時,很難拒絕原假設。 獲取樣本數據的主題是研究過程中耗時且成本高昂的一個方面。