
將結構化數據烘焙到設計過程中
已發表: 2022-03-10搜索引擎優化 (SEO) 對幾乎所有類型的網站都是必不可少的,但其更精細的點仍然是一種專長。 即使在今天,搜索引擎優化也經常被視為事後可以附加的東西。 它可以達到一定程度,但實際上不應該如此。 搜索引擎每天都變得更智能,網站也有辦法變得更智能。
SEO 的基礎與以往一樣:明確標記的出色內容遲早會贏得勝利——無論有多少人試圖玩弄這個系統。 問題是,這些標籤比以前複雜得多。 元標題、圖像替代文本和反向鏈接很重要,但在 2020 年,它們也相當原始。 還有另一層元數據,目前只有一小部分網站在使用:結構化數據。
所有搜索引擎都有相同的目的:組織網絡內容並為搜索查詢提供最相關、最有用的結果。 自 Lycos 和 Ask Jeeves 時代以來,他們實現這一目標的方式發生了巨大變化。 僅谷歌就使用了 200 多個排名因素,而這些只是我們所知道的。
SEO 現在是一個巨大的領域,我告訴你,結構化數據是未來幾年理解和實施的一個非常非常重要的因素。 它不僅可以提高您在相關查詢中獲得高排名的機會。 更重要的是,它有助於讓您的網站變得更好——向各種有用的網絡體驗開放。
推薦閱讀: SEO在您的網頁設計過程中屬於哪裡?
什麼是結構化數據?
結構化數據是一種在網頁上標記內容的方式。 使用來自 Schema.org 的詞彙,它消除了 SEO 中的大部分歧義。 與其相信谷歌、必應、百度和 DuckDuckGo 之類的公司來計算你的內容是什麼,你告訴他們。 這是搜索引擎猜測頁面內容與確定了解之間的區別。
正如 Schema.org 所說:
通過在網頁的 HTML 中添加額外的標籤(例如“嘿,搜索引擎,此信息描述了這個特定的電影、地點、人物或視頻”的標籤),您可以幫助搜索引擎和其他應用程序更好地理解您的內容並以有用的、相關的方式顯示它。
Schema.org 於 2011 年推出,是由 Google、Microsoft、Yahoo 和 Yandex 共享的項目。 換句話說,這是一個“兩黨”的努力——如果你願意的話。 標記超越任何一個搜索引擎。 用 Schema.org 自己的話說,
“共享詞彙表使網站管理員和開發人員更容易決定模式並從他們的努力中獲得最大收益。”
在許多方面,它是微格式(2005 年左右推出)的更廣泛的表親,將語義和結構化數據嵌入 HTML,主要是為了搜索引擎和聚合器的利益。 儘管目前仍支持微格式,但 Schema.org 庫的“官方”性質使其成為長壽的更安全選擇。
關聯數據的 JSON (JSON-LD) 已成為結構化數據的主要基礎標準,儘管微數據和 RDFa 也受支持並用於相同目的。 Schema.org 根據您最熟悉的內容為每種類型提供示例。
例如,假設 Joe Bloggs 撰寫了 Joseph Heller 1961 年小說Catch-22的評論並將其發佈在他的博客上。 可悲的是,博客的品味很差,給了五顆星中的兩顆。 對於查看頁面的人來說,這些信息會不假思索地理解,但計算機程序必須連接幾個點才能得出相同的結論。
對於結構化數據,可以將以下標記添加到頁面的<head>代碼中。 (這是一種 JSON-LD 方法。微數據和 RDFa 可用於將相同的信息編織到<body>內容中):
<script type="application/ld+json"> { "@context" : "https://schema.org", "@type" : "Book", "name" : "Catch-22", "author" : { "@type" : "Person", "name" : "Joseph Heller" }, "datePublished" : "1961-11-10", "review" : { "@type" : "Review", "author" : { "@type" : "Person", "name" : "Joe Bloggs" }, "reviewRating" : { "@type" : "Rating", "ratingValue" : "2", "worstRating" : "0", "bestRating" : "5" }, "reviewBody" : "A disaster. The worst book I've ever read, and I've read The Da Vinci Code." } } </script>這確定了該頁面是關於Catch-22的,這是 Joseph Heller 於 1961 年 11 月 10 日出版的小說。審稿人已確定,評分系統的參數也已確定。 不同的模式可以組合(或分層)來描述不同的事物。 例如,通過此類標記,您可以明確頁面是露天電影放映的事件列表,而有問題的電影是 Wes Anderson與 Steve Zissou 合作的 The Life Aquatic 。
推薦閱讀:更好的研究、更好的設計、更好的結果
為什麼這有關係?
好的,太好了。 我可以將我的網站標記為它的眼球,它看起來完全一樣,但有什麼好處? 在我看來,在網站中包含結構化數據有兩個主要好處:
- 它使搜索引擎的工作變得更加容易。
他們可以更準確地索引內容,這反過來意味著他們可以更豐富地呈現內容。 - 它有助於使 Web 內容更加全面和有用。
結構化數據為您提供內容的“計算機視角”。 優質的內容非常棒。 徹底標記的優質內容是夢想的東西。
您知道何時看到包含星級的時髦搜索結果嗎? 那是結構化數據。 豐富的影評片段? 結構化數據。 當一系列食譜出現時,配料、準備時間等等? 你猜對了。 深入研究任何這些頁面的代碼,您就會在某處找到標記。 搜索引擎使用結構化數據獎勵網站,因為它準確地告訴他們他們正在處理什麼。
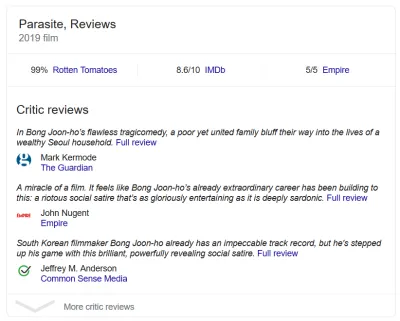
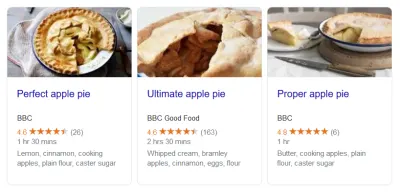
要清楚,這也不僅僅是搜索。 這是其中很大一部分,但不是全部。 結構化數據主要是關於標記和組織內容。 豐富的搜索結果只是使用所述內容的一種方式。 例如,Google 數據集搜索使用 Schema.org/Dataset 標記。
以下是一些有用的結構化數據示例:
- 食譜
- 評論
- 常見問題
- 語音查詢
- 活動列表
- 內容操作。
還有數千人。 就像,從字面上看。 Schema.org 最近甚至加快了 Covid-19 標記的發布。 這是一個不斷發展的圖書館。
在許多方面,結構化數據是語義網的一個分支,它致力於實現完全機器可讀的互聯網。 它為您提供了一個機器可讀的 Web 內容視角(如果實施得當),可以為人們提供更豐富的功能。
因此,幾乎任何擁有網站的人都會從了解什麼是結構化數據及其工作原理中受益。 根據 W3Techs 的數據,只有 29.6% 的網站使用 JSON-LD,而 43.2% 的網站根本不使用任何結構化數據格式。 當然,沒有義務。 不是每個人都關心 SEO 或機器可讀性。 另一方面,對於那些這樣做的人來說,目前有很大的機會與競爭對手的網站一較高下。
就像 HTML 迫使您思考內容的組織方式一樣,結構化數據讓您思考內容。 它讓你更徹底。 無論您的網站是關於什麼的,如果您梳理相關的架構文檔,您幾乎肯定會發現您事先沒有想到包含的細節。
作為人類,很容易將信息之間的聯繫視為理所當然。 搜索引擎和計算機程序很聰明,但沒有那麼聰明。 還沒有。 結構化數據將內容翻譯成他們可以理解的術語。 這反過來又使他們能夠提供更豐富的體驗。
資源和進一步閱讀
- “SEO結構化數據初學者指南:兩部分系列”,Moz的Bridget Randolph
- “什麼是模式標記以及為什麼它對 SEO 很重要,” Chuck Price,搜索引擎雜誌
- “什麼是架構? 結構化數據初學者指南,”Luke Harsel,SEMrush
- “JSON-LD:構建有意義的數據 API”,Benjamin Young,推出博客
- “了解結構化數據的工作原理”,面向開發人員的 Google 搜索
- “使用結構化數據標記您的網站”,必應
將結構化數據融入網站設計
將結構化數據編入網站並不像更改元標題那樣簡單。 它是您網絡內容的數據 DNA。 如果你想正確地實施它,那麼你需要願意進入雜草——至少一點點。 以下是開發人員可以採取的幾個簡單步驟,將結構化數據編織到設計過程中。

注意:我個人讚同整體設計方法,設計和實質齊頭並進。 雜耍一堆學科對於網頁設計來說並不是什麼新鮮事,這只是另一個,如果它融合得很好,它可以加強它周圍的其他元素。 將其視為對您網站引擎的增強。 這輛車看起來可能沒什麼不同,但它的操控性要好得多。
從一個概念開始
我將以我自己為例。 五年來,我和兩個朋友每週都在回顧一張專輯作為一種愛好(其他人不時介入)。 我們冷嘲熱諷、令人難以忍受的散文目前存放在一個 WordPress 網站中,在我善意但完全無知的關心下,它已經成長為科學怪人的插件怪物。
我們正在重新設計網站,其中(除其他外)需要將結構化數據引入核心設計。 在這裡,與任何其他項目一樣,首先要做的是確定您的內容是關於什麼的。 這個問題你回答得越好,接下來的事情就會越簡單。
在我們的例子中,這些是必需品:
- 我們審查音樂專輯;
- 每篇評論都有三名評論者,他們每人通過選擇最多三個最喜歡的曲目並在十個中分配個人分數來撰寫摘要;
- 這三個分數合併為 30 分的最終分數;
- 從這三個摘要中,我們選擇了一段作為我們所有想法的“一目了然”的總結。
其中一些可能聽起來有點具體,甚至有點武斷(因為確實如此),但您會驚訝地發現其中有多少可以使用結構化數據編織在一起。
下面是修改後的評論頁面的樣機,以及可以轉換為模式標記的信息:
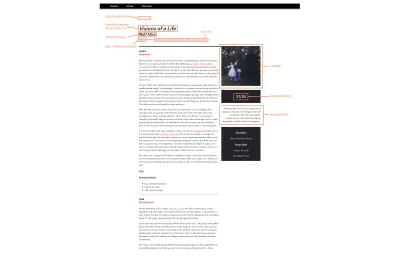
這個過程沒有技巧。 我知道內容是關於什麼的,所以我知道在哪裡查看文檔。 在這種情況下,我去 Schema.org/MusicAlbum 並遇到了各種潛在的屬性,包括:
-
albumReleaseType -
byArtist -
genre -
producer -
datePublished -
recordedAt
有幾十個; 有些是 MusicAlbum 獨有的,有些則屬於 CreativeWork 的更大範圍。 深入研究文檔,我發現標記可以連接到音樂元數據百科全書 MusicBrainz。 當我轉到 Review 文檔時,會展開相同的過程。
從這個簡單的頁面中,可以收集和組織以下信息:
<script type="application/ld+json"> { "@context": "https://schema.org/", "@type": "Review", "reviewBody": "Whereas My Love is Cool was guilty of trying too hard no such thing can be said of Visions. The riffs roar and the melodies soar, with the band playing beautifully to Ellie Rowsell's strengths.", "datePublished": "October 4, 2017", "author": [{ "@type": "Person", "name": "Andre Dack" }, { "@type": "Person", "name": "Frederick O'Brien" }, { "@type": "Person", "name": "Marcus Lawrence" }], "itemReviewed": { "@type": "MusicAlbum", "@id": "https://musicbrainz.org/release-group/7f231c61-20b2-49d6-ac66-1cacc4cc775f", "byArtist": { "@type": "MusicGroup", "name": "Wolf Alice", "@id": "https://musicbrainz.org/artist/3547f34a-db02-4ab7-b4a0-380e1ef951a9" }, "image": "https://lesoreillescurieuses.files.wordpress.com/2017/10/a1320370042_10.jpg", "albumProductionType": "https://schema.org/StudioAlbum", "albumReleaseType": "https://schema.org/AlbumRelease", "name": "Visions of a Life", "numTracks": "12", "datePublished": "September 29, 2017" }, "reviewRating": { "@type": "Rating", "ratingValue": 27, "worstRating": 0, "bestRating": 30 } } </script>老實說,我可能還會添加更多內容。 最初,我發現了評論頁面結構中已經包含的內容(即藝術家、專輯名稱、總分),但隨後新的問題開始出現。 還有什麼更清楚的? 我能補充什麼?
這顯然應該通過什麼是不必要的問題來抵消。 僅僅因為您可以做某事並不意味著您應該做某事。 有“信息太多”之類的東西。 儘管如此,有時更多的細節確實可以使頁面更上一層樓。
熟悉架構
沒有辦法解決它; 讓球滾動的最好方法是讓自己沉浸在文檔中。 有一些工具可以為您實現它(更多內容見下文),但如果您對它的工作原理有適當的了解,您將從標記中獲得更多收益。
瀏覽 Schema.org 文檔。 無論您是誰,無論您的網站是為了什麼,都有可能有很多相關的模式。 該站點的示例非常好,因此不必停留在理論上。
當然,除此之外的步驟是找到您想要模擬的豐富搜索結果,訪問頁面,並使用瀏覽器開發工具查看他們在做什麼。 它們通常是了解其內容的優秀網站示例。 您還可以將代碼片段或 URL 輸入 Google 的結構化數據標記助手,然後生成適當的架構。
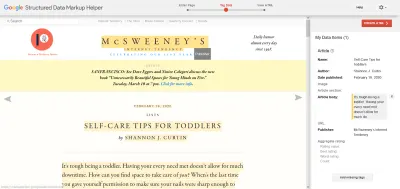
基本原理其實很簡單。 一旦您了解它們,就會發現需要花時間去探索和玩弄的選項的廣度。 您不希望成為完成設計過程、查看模式選項並開始事後猜測已完成的所有事情的人。
提出正確的問題
既然您已經掌握了豐富的結構化數據知識,那麼您就可以更好地為強大的網站奠定基礎。 結構化數據有一條相當獨特的路線。 在直接意義上,它存在於“引擎蓋下”並且是為了計算機的利益而存在的。 同時,它可以為用戶帶來更豐富的體驗。
因此,從技術和用戶的角度來看結構化數據是值得的。 結構化數據如何幫助我更好地理解我的網站? 還有哪些其他資源、在線數據庫或硬件(例如智能揚聲器)可能對您正在做的事情感興趣? 文檔中出現了哪些我沒有考慮到的選項? 我要添加它們嗎?
識別重複出現的內容類型尤為重要。 可以肯定地說,隨著時間的推移,博客可以期待大量的博客文章,因此將結構化數據整合到文章模板中會產生最多的結果。 我上面給出的例子本身就很好,但是標記過程沒有理由不能自動化。 這就是我們的計劃。
還要考慮人們可能會找到您的內容的方式。 例如,如果有機會突出顯示用於語音搜索的副本片段,那就去做吧。 就是這樣,或者讓搜索引擎自己解決。 沒有人比您更了解您的內容,因此請使用描述性標記來利用這種理解。
您無需猜測結構化數據將如何理解內容。 使用 Google 的 Rich Results Tester 之類的工具,您可以準確了解它如何提供可能被忽略的內容形式和含義。
資源和進一步閱讀
- “使用微數據開始使用 Schema.org”,Schema.org
- “Schema.org 項目存儲庫”,GitHub 社區
- “結構化數據標記助手”,谷歌網站管理員
- “將結構化數據添加到您的網頁”,Google Developers Codelabs
- “豐富的結果測試”,谷歌
優質內容值得優質標記
你會發現沒有比我更支持偉大內容的人了。 每當谷歌推出重大搜索更新時,搜索引擎優化行業就會失去集體意識。 對歇斯底里的反應總是一樣的:製作高質量的內容。 我補充說:正確標記它。
熟悉文檔並清楚您的網站是關於什麼的。 您標記的每條信息都使其更容易被索引並與合適的人共享。
無論您是 Google 的忠實擁護者還是 DuckDuckGo 的忠實擁護者,精神始終如一。 這不是關於排名,而是關於使網站盡可能好。 容納結構化數據將使您網站的其他方面更好。
您無需相信技術就能了解您的內容是關於什麼的——您可以告訴它。 從評論到食譜再到音頻搜索,開發人員可以為其內容添加全新的複雜程度。
優化網站以進行搜索的核心和靈魂從未改變:製作出色的內容並儘可能清楚地說明它是什麼以及為什麼有用。 結構化數據是用於此目的的另一種工具,因此請使用它。