
使用機器學習進行股市預測 [分步實施]
已發表: 2021-02-26目錄
介紹
股票市場的預測和分析是一些最複雜的任務。 造成這種情況的原因有很多,例如市場波動以及決定市場上特定股票價值的許多其他獨立和獨立因素。 這些因素使得任何股票市場分析師都很難準確地預測漲跌。
然而,隨著機器學習及其強大算法的出現,最新的市場分析和股市預測發展已經開始將這些技術用於理解股市數據。
簡而言之,機器學習算法被許多組織廣泛用於分析和預測股票價值。 本文將通過使用 Python 中的幾種機器學習算法來分析和預測一個流行的全球在線零售店的股票價值的簡單實現。
問題陳述
在我們開始執行程序以預測股票市場價值之前,讓我們可視化我們將要處理的數據。 在這裡,我們將分析來自全國證券交易商自動報價協會 (NASDAQ) 的微軟公司 (MSFT) 的股票價值。 股票價值數據將以逗號分隔文件 (.csv) 的形式呈現,可以使用 Excel 或電子表格打開和查看。
MSFT 的股票在納斯達克註冊,並在股票市場的每個工作日更新其價值。 請注意,市場不允許在周六和周日進行交易; 因此,兩個日期之間存在間隔。 對於每個日期,記錄股票的開盤價、該股票在同一天的最高價和最低價,以及當天結束時的收盤價。
調整後的收盤價顯示了股息發布後的股票價值(技術性太強!)。 此外,還給出了市場中股票的總成交量,有了這些數據,機器學習/數據科學家的工作就可以研究數據並實施可以從微軟公司股票歷史中提取模式的幾種算法數據。

長短期記憶
為了開發機器學習模型來預測微軟公司的股票價格,我們將使用長短期記憶(LSTM)技術。 它們用於通過乘法和加法對信息進行小的修改。 根據定義,長期記憶 (LSTM) 是一種用於深度學習的人工循環神經網絡 (RNN) 架構。
與標準的前饋神經網絡不同,LSTM 具有反饋連接。 它可以處理單個數據點(如圖像)和整個數據序列(如語音或視頻)。 為了理解 LSTM 背後的概念,讓我們舉一個手機在線客戶評論的簡單例子。
假設我們要購買手機,我們通常會參考認證用戶的網絡評論。 根據他們的想法和投入,我們決定手機的好壞,然後購買。 當我們繼續閱讀評論時,我們會尋找諸如“驚人”、“好相機”、“最佳電池備份”等關鍵字,以及與手機相關的許多其他術語。
我們往往會忽略英語中的“it”、“gave”、“this”等常用詞。因此,當我們決定是否購買手機時,我們只記得上面定義的這些關鍵詞。 很可能,我們忘記了其他詞。
這與長短期記憶算法的工作方式相同。 它只記住相關信息並使用它來進行預測,而忽略不相關的數據。 通過這種方式,我們必須建立一個 LSTM 模型,該模型基本上只識別有關該股票的基本數據並排除其異常值。
資源
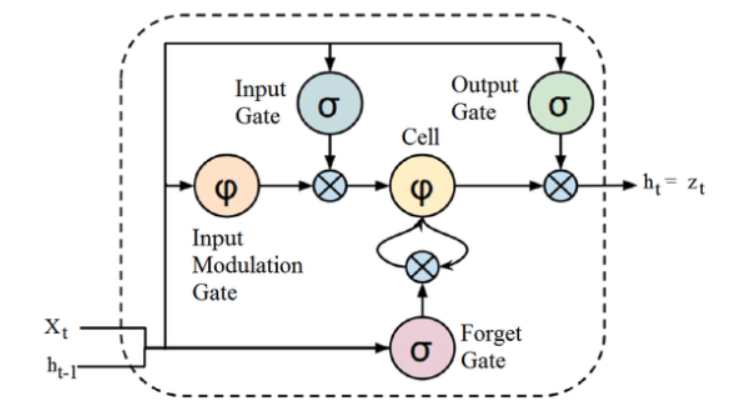
雖然上面給出的 LSTM 架構的結構起初看起來很有趣,但記住 LSTM 是循環神經網絡的高級版本就足夠了,它保留了內存來處理數據序列。 它可以刪除或添加信息到細胞狀態,由稱為門的結構仔細調節。
LSTM 單元包括一個單元、一個輸入門、一個輸出門和一個遺忘門。 細胞在任意時間間隔內記住值,三個門調節信息流入和流出細胞。
計劃實施
我們將繼續使用 LSTM 在 Python 中使用機器學習預測股票價值的部分。
第 1 步 - 導入庫
眾所周知,第一步是導入預處理微軟公司股票數據所需的庫,以及構建和可視化 LSTM 模型輸出所需的其他庫。 為此,我們將使用 TensorFlow 框架下的 Keras 庫。 所需的模塊是從 Keras 庫中單獨導入的。
#導入庫
將熊貓作為 PD 導入
將 NumPy 導入為 np
%matplotlib 內聯
導入matplotlib。 pyplot 作為 plt
導入 matplotlib
來自sklearn。 預處理導入 MinMaxScaler
來自喀拉斯。 層導入 LSTM,密集,輟學
從 sklearn.model_selection 導入 TimeSeriesSplit
從 sklearn.metrics 導入 mean_squared_error, r2_score
導入matplotlib。 日期作為任務
來自sklearn。 預處理導入 MinMaxScaler
從 sklearn 導入線性模型
來自喀拉斯。 模型導入順序
來自喀拉斯。 圖層導入密集
導入 Keras。 後端為 K
來自喀拉斯。 回調導入 EarlyStopping
來自喀拉斯。 優化器導入 Adam
來自喀拉斯。 模型導入 load_model
來自喀拉斯。 圖層導入 LSTM
來自喀拉斯。 utils.vis_utils 導入 plot_model
第 2 步 – 可視化數據
使用 Pandas Data 閱讀器庫,我們將本地系統的股票數據作為逗號分隔值 (.csv) 文件上傳,並將其存儲到 pandas DataFrame。 最後,我們還要查看數據。
#獲取數據集
df = pd.read_csv(“MicrosoftStockData.csv”,na_values=['null'],index_col='Date',parse_dates=True,infer_datetime_format=True)
df.head()
從世界頂級大學在線獲得AI 認證- 碩士、行政研究生課程和 ML 和 AI 高級證書課程,以加快您的職業生涯。
第 3 步 – 打印 DataFrame 形狀並檢查 Null 值。
在這又一個關鍵步驟中,我們首先打印數據集的形狀。 為了確保數據框中沒有空值,我們檢查它們。 數據集中存在的空值往往會在訓練期間引起問題,因為它們充當異常值,導致訓練過程中出現很大差異。
#打印數據框形狀並檢查空值
打印(“數據框形狀:”,df.shape)
打印(“空值存在:”,df.IsNull().values.any())
>> 數據框形狀:(7334, 6)
>>存在空值:False
| 日期 | 打開 | 高的 | 低的 | 關閉 | 調整關閉 | 體積 |
| 1990-01-02 | 0.605903 | 0.616319 | 0.598090 | 0.616319 | 0.447268 | 53033600 |
| 1990-01-03 | 0.621528 | 0.626736 | 0.614583 | 0.619792 | 0.449788 | 113772800 |
| 1990-01-04 | 0.619792 | 0.638889 | 0.616319 | 0.638021 | 0.463017 | 125740800 |
| 1990-01-05 | 0.635417 | 0.638889 | 0.621528 | 0.622396 | 0.451678 | 69564800 |
| 1990-01-08 | 0.621528 | 0.631944 | 0.614583 | 0.631944 | 0.458607 | 58982400 |
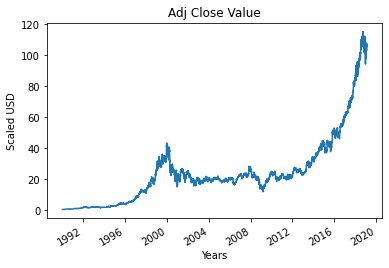
第 4 步 – 繪製真實調整後的收盤價
使用機器學習模型預測的最終輸出值是調整後的收盤值。 該值代表股票在該特定股票市場交易日的收盤價。
#繪製真正的調整關閉值
df['Adj Close'].plot()
第 5 步 – 設置目標變量並選擇特徵
在下一步中,我們將輸出列分配給目標變量。 在這種情況下,它是微軟股票的調整後相對價值。 此外,我們還選擇了作為目標變量(因變量)的自變量的特徵。 考慮到培訓目的,我們選擇了四個特徵,它們是:
- 打開
- 高的
- 低的
- 體積
#設置目標變量
output_var = PD.DataFrame(df['Adj Close'])
#選擇特徵
features = ['Open', 'High', 'Low', 'Volume']
第 6 步 - 縮放
為了減少表中數據的計算成本,我們將股票值縮小到 0 到 1 之間的值。這樣,所有的大數據都被減少了,從而減少了內存使用。 此外,我們可以通過縮小規模來獲得更高的準確性,因為數據不會以巨大的價值分散。 這是由 sci-kit-learn 庫的 MinMaxScaler 類執行的。

#縮放
縮放器 = MinMaxScaler()
feature_transform = scaler.fit_transform(df[features])
feature_transform= pd.DataFrame(columns=features, data=feature_transform, index=df.index)
feature_transform.head()
| 日期 | 打開 | 高的 | 低的 | 體積 |
| 1990-01-02 | 0.000129 | 0.000105 | 0.000129 | 0.064837 |
| 1990-01-03 | 0.000265 | 0.000195 | 0.000273 | 0.144673 |
| 1990-01-04 | 0.000249 | 0.000300 | 0.000288 | 0.160404 |
| 1990-01-05 | 0.000386 | 0.000300 | 0.000334 | 0.086566 |
| 1990-01-08 | 0.000265 | 0.000240 | 0.000273 | 0.072656 |
如上所述,我們看到與上面給出的真實值相比,特徵變量的值被縮小到更小的值。
第 7 步 - 拆分為訓練集和測試集。
在將數據輸入訓練模型之前,我們需要將整個數據集拆分為訓練集和測試集。 機器學習 LSTM 模型將根據訓練集中存在的數據進行訓練,並在測試集上測試其準確性和反向傳播。
為此,我們將使用 sci-kit-learn 庫的 TimeSeriesSplit 類。 我們將分割數設置為 10,表示將 10% 的數據用作測試集,90% 的數據將用於訓練 LSTM 模型。 使用這種時間序列拆分的優勢在於,拆分的時間序列數據樣本以固定的時間間隔進行觀察。
#拆分為訓練集和測試集
timesplit= TimeSeriesSplit(n_splits=10)
對於 train_index,timesplit.split(feature_transform) 中的 test_index:
X_train, X_test = feature_transform[:len(train_index)], feature_transform[len(train_index): (len(train_index)+len(test_index))]
y_train, y_test = output_var[:len(train_index)].values.ravel(), output_var[len(train_index): (len(train_index)+len(test_index))].values.ravel()
第 8 步 - 為 LSTM 處理數據
一旦訓練集和測試集準備就緒,我們就可以在構建 LSTM 模型後將其輸入。 在此之前,我們需要將訓練集和測試集數據轉換為 LSTM 模型能夠接受的數據類型。 我們首先將訓練數據和測試數據轉換為 NumPy 數組,然後將它們重塑為格式(樣本數,1,特徵數),因為 LSTM 要求數據以 3D 形式提供。 我們知道,訓練集中的樣本數是7334的90%,也就是6667,特徵數是4,訓練集reshape為(6667, 1, 4)。 同樣,測試集也被重塑。
#處理LSTM的數據
trainX =np.array(X_train)
testX =np.array(X_test)
X_train = trainX.reshape(X_train.shape[0], 1, X_train.shape[1])
X_test = testX.reshape(X_test.shape[0], 1, X_test.shape[1])
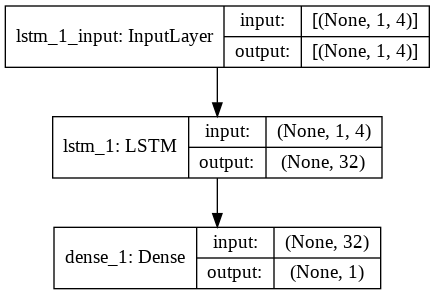
第 9 步 - 構建 LSTM 模型
最後,我們來到了構建 LSTM 模型的階段。 在這裡,我們創建了一個帶有一個 LSTM 層的 Sequential Keras 模型。 LSTM 層有 32 個單元,緊隨其後的是 1 個神經元的密集層。
我們使用 Adam Optimizer 和均方誤差作為編譯模型的損失函數。 這兩者是 LSTM 模型最優選的組合。 此外,還繪製了模型並顯示在下方。
#構建 LSTM 模型
lstm = 順序()
lstm.add(LSTM(32, input_shape=(1, trainX.shape[1]), activation='relu', return_sequences=False))
lstm.add(密集(1))
lstm.compile(損失='mean_squared_error',優化器='adam')
plot_model(lstm, show_shapes=True, show_layer_names=True)
第 10 步 - 訓練模型
最後,我們使用 fit 函數在 100 個 epoch 的訓練數據上訓練上面設計的 LSTM 模型,批量大小為 8。
#模型訓練
歷史= lstm.fit(X_train,y_train,epochs=100,batch_size=8,verbose=1,shuffle=False)
紀元 1/100
834/834 [===============================] – 3s 2ms/step – 損失:67.1211
紀元 2/100
834/834 [===============================] – 1s 2ms/步 – 損失:70.4911
紀元 3/100
834/834 [===============================] – 1s 2ms/步 – 損失:48.8155
紀元 4/100
834/834 [===============================] – 1s 2ms/步 – 損失:21.5447
紀元 5/100
834/834 [===============================] – 1s 2ms/步 – 損失:6.1709
時代 6/100
834/834 [===============================] – 1s 2ms/步 – 損失:1.8726
紀元 7/100
834/834 [===============================] – 1s 2ms/步 – 損失:0.9380
紀元 8/100
834/834 [===============================] – 2s 2ms/步 – 損失:0.6566
紀元 9/100
834/834 [===============================] – 1s 2ms/步 – 損失:0.5369
紀元 10/100
834/834 [===============================] – 2s 2ms/步 – 損失:0.4761
.
.
.
.
紀元 95/100
834/834 [===============================] – 1s 2ms/步 – 損失:0.4542
紀元 96/100
834/834 [===============================] – 2s 2ms/步 – 損失:0.4553
紀元 97/100
834/834 [===============================] – 1s 2ms/步 – 損失:0.4565
紀元 98/100
834/834 [===============================] – 1s 2ms/步 – 損失:0.4576
99/100 紀元
834/834 [===============================] – 1s 2ms/步 – 損失:0.4588
紀元 100/100
834/834 [===============================] – 1s 2ms/步 – 損失:0.4599
最後,我們看到損失值在 100 個 epoch 的訓練過程中隨時間呈指數下降,達到了 0.4599
第 11 步 – LSTM 預測
準備好我們的模型後,就可以在測試集上使用使用 LSTM 網絡訓練的模型並預測 Microsoft 股票的相鄰收盤價了。 這是通過在構建的 lstm 模型上使用簡單的預測功能來執行的。
#LSTM 預測
y_pred= lstm.predict(X_test)
第 12 步 – 真實與預測的 Adj 收盤值 – LSTM
最後,由於我們已經預測了測試集的值,我們可以繪製圖表來比較 Adj Close 的真實值和 Adj Close 的 LSTM 機器學習模型的預測值。
#True 與預測的 Adj 收盤價 – LSTM
plt.plot(y_test, label='真值')
plt.plot(y_pred, label='LSTM 值')
plt.title(“LSTM 預測”)
plt.xlabel('時間刻度')
plt.ylabel('按比例縮放美元')
plt.legend()
plt.show()
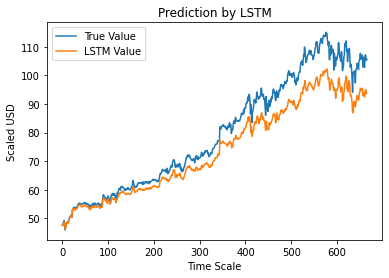
上圖顯示,上面構建的非常基本的單個 LSTM 網絡模型檢測到了一些模式。 通過微調幾個參數並在模型中添加更多 LSTM 層,我們可以更準確地表示任何給定公司的股票價值。
結論
如果您有興趣了解有關人工智能示例、機器學習的更多信息,請查看 IIIT-B 和 upGrad 的機器學習和 AI 執行 PG 計劃,該計劃專為工作專業人士設計,提供 450 多個小時的嚴格培訓、30 多個案例研究和分配,IIIT-B 校友身份,5 個以上實用的實踐頂點項目和頂級公司的工作協助。
你能用機器學習預測股市嗎?
今天,我們有許多指標來幫助預測市場趨勢。 然而,我們只需要一台高性能計算機就能找到最準確的股市指標。 股票市場是一個開放的系統,可以看作是一個複雜的網絡。 該網絡由股票、公司、投資者和交易量之間的關係組成。 通過使用像支持向量機這樣的數據挖掘算法,您可以應用數學公式來提取這些變量之間的關係。 股市現在超出了人類的預測。
哪種算法最適合股市預測?
為獲得最佳結果,您應該使用線性回歸。 線性回歸是一種統計方法,用於確定兩個不同變量之間的關係。 在這個例子中,變量是價格和時間。 在股市預測中,價格是自變量,時間是因變量。 如果可以確定這兩個變量之間的線性關係,那麼就有可能準確預測未來任何時候股票的價值。
股市預測是分類問題還是回歸問題?
在我們回答之前,我們需要了解股市預測的含義。 是二分類問題還是回歸問題? 假設我們想預測一隻股票的未來,未來意味著下一天、下週、下個月或下一年。 如果股票在某個時間點的過去表現是輸入,未來是輸出,那麼這是一個回歸問題。 如果一隻股票的過去表現和一隻股票的未來是獨立的,那麼它就是一個分類問題。