
構建推薦系統機器學習的簡單指南 [2022]
已發表: 2021-03-11當今的大多數互聯網企業都傾向於提供個性化的用戶體驗。 機器學習中的推薦系統是一種特殊類型的基於 Web 的個性化應用程序,它為用戶提供有關他們可能感興趣的內容的個性化推薦。 推薦系統也稱為推薦系統。
目錄
什麼是推薦系統?
機器學習中的推薦系統可以預測用戶對一堆事物的需求,並推薦最需要的事物。
推薦系統是應用於企業的機器學習技術最廣泛的應用之一。
我們可以在零售、視頻點播或音樂流媒體中找到大規模的推薦系統。
推薦系統試圖將獨特的數據揭示模型的一部分自動化,其中個人試圖發現具有相似品味的其他人,然後要求他們推薦新項目。
加入來自世界頂級大學的在線機器學習課程——碩士、高管研究生課程和 ML 和 AI 高級證書課程,以加快您的職業生涯。

推薦系統的類型
- 根據您的興趣進行個性化推薦。
- 非個性化 - 其他客戶現在正在查看的內容。
推薦系統的需求是什麼?
我們在機器學習中需要推薦系統的關鍵原因之一是,由於互聯網,人們可以選擇購買的選擇太多。
過去,人們過去常常在實體店購物,那裡的商品供應有限。
例如,放置在視頻租賃店的電影數量取決於商店的規模。 網絡允許人們訪問大量的在線資源。 Netflix 擁有大量電影。 隨著可用信息量的增加,出現了一個新問題,人們發現很難從各種各樣的選項中進行選擇。 因此,推薦系統應運而生。
推薦系統在哪裡使用?
- 大型電子商務網站使用此工具來推薦消費者可能希望購買的商品。
- 網絡個性化。
推薦系統如何工作?
- 我們可以向客戶推薦在其他客戶中普遍受歡迎的東西。
- 我們可以根據客戶的產品選擇將客戶分成幾組,並建議他們可能購買的東西。
上述兩種技術都有其缺點。 在第一種情況下,最流行、最主流的東西對每個客戶都是一樣的。 因此,每個人都可能會收到類似的建議。 而在第二個中,隨著客戶數量的增加,作為建議突出顯示的事物的數量也會增加。 因此,很難將所有客戶端分組到不同的部分。
現在,我們將看看推薦系統是如何工作的。
數據採集
這是創建推薦系統的第一步,也是最重要的一步。 信息經常通過兩種方法收集:顯式和隱式。
顯性信息將是故意提供的數據,即客戶做出的貢獻,如電影評論。 隱含信息是指未特意提供但從可訪問的信息流中收集的數據,例如點擊、搜索歷史、請求歷史等。
資料庫
信息量表明模型建議的真實性。 信息類型在從大量人群中挑選數據方面具有重要作用。 該容量可以包括一個標準的 SQL 和 NoSQL 信息庫或一種形式的文章存儲。
數據過濾
在收集和存儲之後,需要對這些數據進行過濾以提取信息以做出最終推薦。 各種算法使過濾過程更容易。
推薦系統算法
軟件系統利用項目/用戶的歷史迭代和屬性向用戶提供建議。
構建推薦系統有兩種方法。
1. 基於內容的推薦
- 使用項目/用戶的屬性
- 推薦與用戶過去喜歡的項目相似的項目
2.協同過濾
- 推薦類似用戶喜歡的項目
- 探索多樣化的內容
基於內容的推薦
監督機器學習誘導分類器區分有趣和不感興趣的用戶項目。

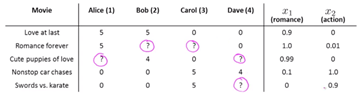
推薦系統的目標是預測用戶未評級事物的分數。 內容過濾背後的基本思想是,每件事都有一些亮點 x。
例如,電影《最後的愛》是一部愛情片,精彩片段 x1 得分高,而 x2 得分低。
(電影收視數據)
資源
每個人都有一個參數 θ,它告訴他們有多喜歡愛情片,有多喜歡動作片。
如果 θ = [1, 0.1],個人喜歡愛情片而不是動作片。
我們可以通過線性回歸為每個人找到最佳 θ。
(符號)
r(i,j):如果用戶 j 對電影 i 評分,則為 1(否則為 0)
y(i,j):用戶 j 對電影 i 的評分(如果已定義)
θ(j):用戶向量參數
x(i):電影 i 特徵向量
預測評分[用戶 j,電影 i]:(θ(j))ᵀx(i)
m(j): # 用戶 j 率的電影數量
nᵤ:用戶數
n:電影的特徵數
閱讀:機器學習項目的想法和主題
協同過濾
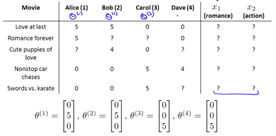
內容過濾的缺點是它需要所有內容的輔助數據。
例如,愛情和動作等分類是電影的輔助數據。 找到觀看電影並為每部電影添加輔助數據的人的成本很高。
基本假設
- 興趣相近的用戶有著共同的偏好。
- 有足夠多的用戶偏好可用。
主要方法
- 基於用戶
- 基於項目
怎麼可能列出電影的所有特徵? 如果想添加新功能怎麼辦? 我們是否應該將新功能添加到所有電影中?
協同過濾解決了這個問題。
(預測電影的特點)來源
機器學習中推薦系統的問題與維護
問題
- 不確定的用戶輸入結構
- 尋找用戶參與批評研究
- 弱計算
- 結果不佳
- 信息不暢
- 缺乏信息
- 隱私控制(可能不會與收據明確結合)
維護
- 昂貴
- 信息過時了
- 信息質量(巨大,圈層空間發展)
機器學習中的推薦系統植根於各個研究領域,例如信息檢索、文本分類,以及應用來自不同領域的不同方法,例如機器學習、數據挖掘和基於知識的系統。
推薦系統的未來
- 提取物通過檢查帶回來的東西來理解負面評價。
- 如何將當地與提案結合起來。
- 稍後將使用推薦系統來預測對商品的興趣,從而使之前的通信能夠返回到商店網絡。
使用 upGrad 提升您在機器學習領域的職業生涯
如果您有興趣了解有關機器學習的更多信息,請查看 IIIT-B 和 upGrad 的機器學習和 AI 執行 PG 計劃,該計劃專為工作專業人士設計,提供 450 多個小時的嚴格培訓、30 多個案例研究和作業、IIIT -B 校友身份,5 個以上實用的實踐頂點項目和頂級公司的工作協助。
你在哪裡可以找到現實生活中的推薦系統?
推薦系統或推薦系統可以被概念化為採用機器學習功能的數據過濾應用程序。 如今,推薦系統被廣泛用於向特定用戶組或個人消費者發送有關最相關產品或服務的推薦。 它搜索隱藏在客戶行為數據中的特定模式,顯式或隱式收集信息,然後相應地生成建議。 使用推薦系統的一些最著名的品牌是谷歌、Netflix、Facebook 和亞馬遜,以及其他全球組織。 事實上,研究表明,亞馬遜 35% 的整體購買是產品推薦的結果。
今天有哪些公司在使用人工智能?
從增強客戶體驗到提高跨行業的業務生產力和提高運營效率,組織現在都在大力投資人工智能。 事實上,無論有意或無意,我們所有人在日常生活中也經常接觸到人工智能。 除了特斯拉、蘋果和谷歌,今天其他一些成功使用人工智能的知名組織包括 Twitter、優步、亞馬遜、YouTube 等。Twitter 自 2017 年以來一直在使用人工智能和自然語言處理,而 Netflix 則專注於整個圍繞數據和人工智能進行操作。
當今印度最熱門的 AI 工作是什麼?
隨著人工智能領域的大規模發展,市場對人工智能專業人士的需求空前高漲。 因此,對於那些希望在該技術領域開拓一席之地的人來說,該行業看起來很有希望,並提供一系列令人興奮的工作選擇,而且薪水也很可觀。 當今人工智能領域的一些頂級職位包括首席數據科學家、人工智能研究工程師、計算機科學家、機器學習工程師等職位,根據工作經驗,年薪從 9.5 到 180 萬印度盧比不等、技能組合和其他不同的因素。