
用戶體驗設計師的定量數據工具
已發表: 2022-03-10許多用戶體驗設計師有點害怕數據,認為它需要對統計和數學有深入的了解。 儘管這對於高級數據科學來說可能是正確的,但對於大多數 UX 設計師所需的基礎研究數據分析來說卻並非如此。 由於我們生活在一個日益數據驅動的世界,基本的數據素養對幾乎所有專業人士都有用——不僅僅是用戶體驗設計師。
Google 的交互設計師 Aaron Gitlin 認為,許多設計師還不是數據驅動的:
“雖然許多企業宣傳自己是數據驅動的,但大多數設計師都是由直覺、協作和定性研究方法驅動的。”
— Aaron Gitlin,“成為數據感知設計師”
通過這篇文章,我想為用戶體驗設計師提供知識和工具,以將數據整合到他們的日常生活中。
但首先,一些數據概念
在本文中,我將討論結構化數據,即可以在表格中表示的數據,包括行和列。 正如 Devin Pickell(G2 Crowd 的內容營銷專家,撰寫有關數據和分析的文章)在他的文章“結構化數據與非結構化數據 - 有什麼區別?”中指出的那樣,非結構化數據本身就是一個主題,更難分析。 如果結構化數據可以用表格的形式表示,主要的概念是:
數據集
我們打算分析的整個數據集。 例如,這可以是 Excel 表格。 存儲數據集的另一種流行格式是逗號分隔值文件 (CSV)。 CSV 文件是簡單的文本文件,用於存儲類似表格的信息。 每個 CSV 行對應於表格中的一行,並且每個 CSV 行都有(自然地)用逗號分隔的值,這些值對應於表格單元格。
數據點
數據集表中的單行是一個數據點。 這樣,數據集就是數據點的集合。
數據變量
數據點行中的單個值表示一個數據變量——簡單地說,一個表格單元格。 我們可以有兩種類型的數據變量:定性變量和定量變量。 定性變量(也稱為分類變量)具有一組離散的值,例如color = red/green/blue 。 定量變量具有數值,例如height = 167 。 與定性變量不同,定量變量可以取任何值。
創建我們的數據項目
現在我們知道了基礎知識,是時候動手創建我們的第一個數據項目了。 該項目的範圍是通過導入、處理和繪製數據的整個數據流來分析數據集。 首先,我們將選擇我們的數據集,然後我們將下載並安裝用於分析數據的工具。
汽車數據集
出於本文的目的,我選擇了一個汽車數據集,因為它簡單直觀。 數據分析將簡單地確認我們對汽車的了解——這很好,因為我們的重點是數據流和工具。
我們可以從免費數據集的最大來源之一 Kaggle 下載二手車數據集。 您需要先註冊。
下載文件後,打開並查看。 這是一個非常大的 CSV 文件,但您應該了解要點。 此文件中的一行將如下所示:
19500,2015,2965,Miami,FL,WBA3B1G54FNT02351,BMW,3如您所見,這個數據點有幾個用逗號分隔的變量。 既然我們現在有了數據集,讓我們來談談工具。
貿易工具
我們將使用 R 語言和 RStudio 來分析數據集。 R 是一種非常流行且易於學習的語言,不僅被數據科學家使用,還被金融市場、醫學和許多其他領域的人們使用。 RStudio 是開發 R 項目的環境,並且有免費版本,對於我們作為 UX 設計師的需求已經綽綽有餘。
一些用戶體驗設計師很可能使用 Excel 來處理他們的數據工作流。 如果這意味著您,請嘗試 R — 您很有可能會喜歡它,因為它易於學習,並且比 Excel 更靈活、更強大。 將 R 添加到您的工具包中會有所作為。
安裝工具
首先,我們需要下載並安裝 R 和 RStudio。 您應該先安裝 R,然後再安裝 RStudio。 R 和 RStudio 的安裝過程都簡單明了。
項目設置
安裝完成後,創建一個項目文件夾——我稱之為used-cars-prj 。 在該文件夾中,創建一個名為data的子文件夾,然後將數據集文件(從 Kaggle 下載)複製到該文件夾中,並將其重命名為used-cars.csv 。 現在回到我們的項目文件夾( used-cars-prj )並創建一個名為used-cars.r的純文本文件。 您最終應該得到與下面的屏幕截圖相同的結構。
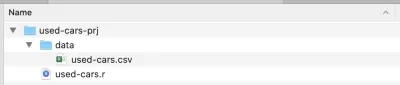
現在我們有了文件夾結構,我們可以打開 RStudio 並創建一個新的 R 項目。 從File菜單中選擇New Project...並選擇第二個選項Existing Directory 。 然後選擇項目目錄( used-cars-prj )。 最後,按下Create Project按鈕,您就完成了。 創建項目後,在 RStudio 中打開used-cars.r——這是我們將添加所有 R 代碼的文件。
導入數據
我們將在used-cars.r中添加第一行,用於從used-cars.csv文件中讀取數據。 請記住,CSV 文件只是用於存儲數據的純文本文件。 我們的第一行 R 代碼將如下所示:
cars <- read.csv("./data/used-cars.csv", stringsAsFactors = FALSE, sep=",") 它可能看起來有點嚇人,但實際上並非如此——順便說一句,這是整篇文章中最複雜的一行。 我們這裡有read.csv函數,它接受三個參數。
第一個參數是要讀取的文件,在我們的例子中是used-cars.csv ,它位於數據文件夾中。 第二個參數stringsAsFactors=FALSE設置為確保“BMW”或“Audi”之類的字符串不會轉換為因子(分類數據的 R 術語)——正如您所回憶的那樣,定性或分類變量只能具有離散值,例如red/green/blue 。 最後,第三個參數sep=","指定用於分隔 CSV 文件中的值的分隔符類型:逗號。
讀取 CSV 文件後,將數據存儲到cars數據框對像中。 數據框是一種二維數據結構(如 Excel 表格),它在 R 中對操作數據非常有用。 引入線路並運行後,將為您創建一個cars數據框。 如果您查看 RStudio 的右上角象限,您會注意到cars數據框,位於Environment選項卡下的Data部分。 如果您雙擊汽車,將在 RStudio 的左上角打開一個新選項卡,並顯示cars數據框。 如您所料,它看起來像一個 Excel 表格。
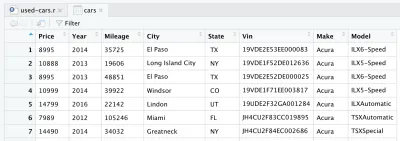
這實際上是我們從 Kaggle 下載的原始數據。 但是由於我們要進行數據分析,我們需要先處理我們的數據集。
數據處理
通過處理,我們的意思是刪除、轉換或添加信息到我們的數據集,以便為我們想要執行的分析做準備。 我們在數據框對像中有數據,所以現在我們需要安裝dplyr庫,這是一個用於處理數據的強大庫。 要在我們的 R 環境中安裝庫,我們需要在 R 文件的頂部編寫以下行。
install.packages("dplyr")然後,要將庫添加到我們當前的項目中,我們將使用下一行:
library(dplyr) 一旦將dplyr庫添加到我們的項目中,我們就可以開始處理數據了。 我們有一個非常大的數據集,我們只需要代表同一汽車製造商和型號的數據,以便將其與價格相關聯。 我們將使用以下 R 代碼僅保留有關 BMW 3 系的數據,並刪除其餘數據。 當然,您可以從數據集中選擇任何其他製造商和型號,並期望具有相同的數據特徵。
cars <- cars %>% filter(Make == "BMW", Model == "3")現在我們有了一個更易於管理的數據集,雖然仍然包含超過 11,000 個數據點,但它符合我們的預期目的:分析汽車的價格、年齡和里程分佈,以及它們之間的相關性。 為此,我們只需要保留“Price”、“Year”和“Mileage”列並刪除其餘列 - 這是通過以下行完成的。
cars <- cars %>% select(Price, Year, Mileage)刪除其他列後,我們的數據框將如下所示:
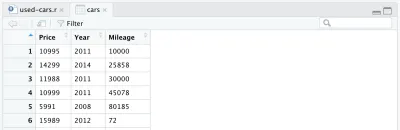
我們還想對我們的數據集進行另一項更改:將製造年份替換為汽車的年齡。 我們可以添加以下兩行,第一行計算年齡,第二行更改列名。

cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)最後,我們完整處理的數據框如下所示:
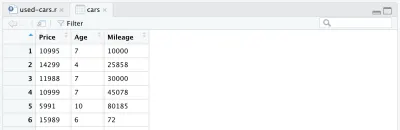
此時,我們的 R 代碼將如下所示,這就是數據處理的全部內容。 我們現在可以看到 R 語言是多麼簡單和強大。 我們只用幾行代碼就非常顯著地處理了初始數據集。
install.packages("dplyr") library(dplyr) cars = read.csv("./data/cars.csv", stringsAsFactors = FALSE, sep=",") cars <- cars %>% filter(Make == "BMW", Model == "3") cars <- cars %>% select(Price, Year, Mileage) cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)數據分析
我們的數據現在是正確的形狀,所以我們可以去繪製一些圖。 如前所述,我們將關注兩個方面:單個變量的分佈,以及它們之間的相關性。 可變分佈有助於我們了解二手車的中價或高價——或高於特定價格的汽車的百分比。 這同樣適用於汽車的年齡和里程。 另一方面,相關性有助於理解年齡和里程等變量如何相互關聯。
也就是說,我們將使用兩種數據可視化:用於變量分佈的直方圖和用於相關性的散點圖。
價格分佈
用 R 語言繪製汽車價格直方圖就像這樣簡單:
hist(cars$Price)一個小提示:如果你在 RStudio 中,你可以逐行運行代碼; 例如,在我們的例子中,您只需要運行上面的行來顯示直方圖。 由於您已經運行過一次,因此無需再次運行所有代碼。 直方圖應如下所示:
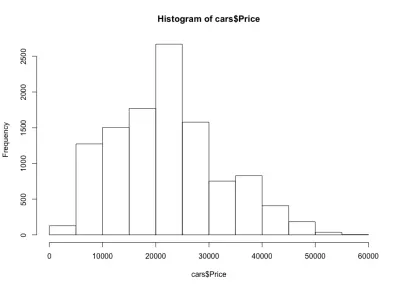
如果我們查看直方圖,我們會注意到汽車價格的鐘形分佈,這正是我們的預期。 大多數汽車都在中檔,隨著我們向兩邊移動,我們的車越來越少。 幾乎 80% 的汽車價格在 10,000 美元到 30,000 美元之間,我們最多有 2,500 多輛汽車在 20,000 美元到 25,000 美元之間。 在左側,我們可能有大約 150 輛低於 5,000 美元的汽車,而右側則更少。 我們可以很容易地看到這些圖對於深入了解數據有多麼有用。
年齡分佈
就像汽車的價格一樣,我們將使用類似的線來繪製汽車的年齡直方圖。
hist(cars$Age)這是直方圖:
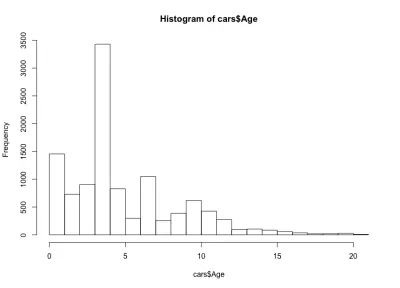
這次直方圖看起來違反直覺——我們這裡有四個鈴鐺,而不是簡單的鈴鐺形狀。 基本上,分佈具有三個局部最大值和一個全局最大值,這是出乎意料的。 看看這種奇怪的汽車年齡分佈是否適用於另一家汽車製造商和車型,將會很有趣。 出於本文的目的,我們將繼續使用 BMW 3 係數據集,但如果您好奇,可以深入挖掘數據。 關於我們的車齡分佈,我們注意到超過 90% 的汽車車齡不到 10 年,超過 80% 的車車齡不到 7 年。 此外,我們注意到大多數汽車的使用年限不到 5 年。
里程分配
現在,關於里程我們能說什麼? 當然,我們希望擁有與價格相同的鐘形。 這是R代碼和直方圖:
hist(cars$Mileage) 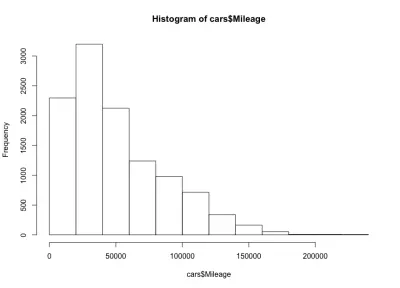
這裡我們有一個左傾斜的鐘形,這意味著市場上有更多里程更少的汽車。 我們還注意到大多數汽車的行駛里程不到 60,000 英里,而我們的最大行駛里程約為 20,000 到 40,000 英里。
年齡-價格相關
關於相關性,讓我們仔細看看汽車年齡與價格的相關性。 我們可能會認為價格與年齡呈負相關——隨著汽車年齡的增加,其價格會下降。 我們將使用 R plot函數來顯示價格-年齡相關性,如下所示:
plot(cars$Age, cars$Price)情節是這樣的:
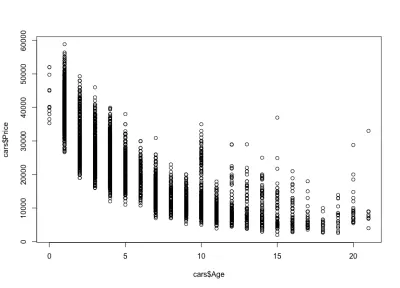
我們注意到汽車的價格隨著年齡的增長而下降:有昂貴的新車,也有更便宜的舊車。 我們還可以看到任何特定年齡的價格變化區間,該變化隨著汽車的年齡而減小。 這種變化很大程度上是由汽車的里程、配置和整體狀態驅動的。 例如,一輛 4 年車齡的汽車,價格在 10,000 美元到 40,000 美元之間變化。
里程-年齡相關性
考慮到里程與年齡的相關性,我們預計里程會隨著年齡的增長而增加,這意味著正相關。 這是代碼:
plot(cars$Mileage, cars$Age)這是情節:
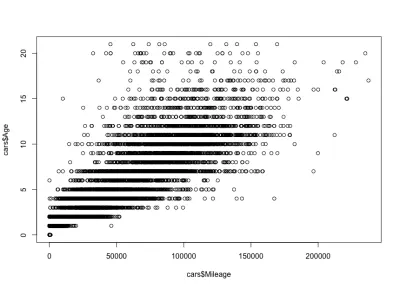
正如你所看到的,汽車的年齡和里程是正相關的,不像汽車的價格和年齡是負相關的。 我們還有一個特定年齡的預期里程變化; 也就是說,同一年齡的汽車具有不同的里程。 例如,大多數 4 年車齡的汽車的行駛里程在 10,000 到 80,000 英里之間。 但也有異常值,里程更大。
里程價格相關性
正如預期的那樣,汽車的行駛里程與價格之間將存在負相關,這意味著增加行駛里程會降低價格。
plot(cars$Mileage, cars$Price)這是情節:
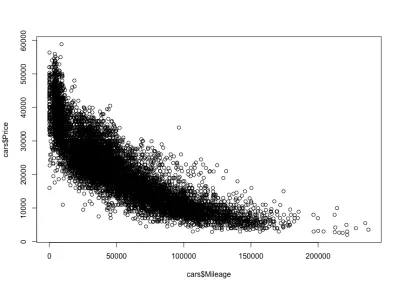
正如我們所料,負相關。 我們還可以注意到 3,000 美元到 50,000 美元之間的總價格區間,以及 0 到 150,000 美元之間的里程。 如果我們仔細觀察分佈形狀,我們會發現里程較少的汽車的價格下降速度要快於里程較多的汽車。 有些汽車的里程幾乎為零,價格急劇下降。 此外,超過 200,000 英里的範圍——因為里程非常高——價格保持不變。
從數字到數據可視化
在本文中,我們使用了兩種類型的可視化:數據分佈的直方圖和數據相關性的散點圖。 直方圖是採用數據變量(實際數字)的值並顯示它們如何在一個範圍內分佈的可視化表示。 我們使用 R hist()函數繪製直方圖。
另一方面,散點圖採用成對的數字並在兩個軸上表示它們。 散點圖使用plot()函數並提供兩個參數:我們要研究的相關性的第一個和第二個數據變量。 因此,兩個 R 函數hist()和plot()幫助我們將數字集轉換為有意義的視覺表示。
結論
在完成了導入、處理和繪製數據的整個數據流之後,現在事情看起來更加清晰了。 您可以將相同的數據流應用於您將遇到的任何閃亮的新數據集。 例如,在用戶研究中,您可以繪製任務時間或錯誤分佈圖,還可以繪製任務時間與錯誤相關性。
要了解有關 R 語言的更多信息,Quick-R 是一個不錯的起點,但您也可以考慮 R Bloggers。 有關 R 包的文檔,例如dplyr ,您可以訪問 RDocumentation。 玩數據可能很有趣,但它對數據驅動世界中的任何 UX 設計師都非常有幫助。 隨著越來越多的數據被收集並用於為業務決策提供信息,設計人員從事數據可視化或數據產品的機會越來越多,在這些產品中,了解數據的性質至關重要。