
多項式回歸:重要性,逐步實施
已發表: 2021-01-29目錄
介紹
在這個廣闊的機器學習領域,我們大多數人會研究的第一個算法是什麼? 是的,它是線性回歸。 線性回歸主要是人們在機器學習編程的最初幾天學習的第一個程序和算法,它對線性類型的數據具有其自身的重要性和力量。
如果我們遇到的數據集不是線性可分的怎麼辦? 如果線性回歸模型無法在自變量和因變量之間推導出任何類型的關係怎麼辦?
還有另一種類型的回歸,稱為多項式回歸。 顧名思義,多項式回歸是一種回歸算法,它將因變量 (y) 和自變量 (x) 之間的關係建模為 n 次多項式。 在本文中,我們將了解多項式回歸背後的算法和數學以及它在 Python 中的實現。
什麼是多項式回歸?
如前所述,多項式回歸是線性回歸的一種特殊情況,其中具有指定 (n) 次的多項式方程擬合在非線性數據上,從而在因變量和自變量之間形成曲線關係。
y= b 0 +b 1 x 1 + b 2 x 1 2 + b 3 x 1 3 +…… b n x 1 n
這裡,

y是因變量(輸出變量)
x1是自變量(預測變量)
b 0是偏差
b 1 , b 2 , ....bn是回歸方程中的權重。
隨著多項式方程( n )的階數越高,多項式方程越複雜,模型可能會出現過擬合,這將在後面討論。
回歸方程的比較
簡單線性回歸 ===> y= b0+b1x
多元線性回歸 ===> y= b0+b1x1+ b2x2+ b3x3+…… bnxn
多項式回歸 ===> y= b0+b1x1+ b2x12+ b3x13+…… bnx1n
從以上三個等式中,我們可以看出它們之間存在一些細微的差別。 簡單和多元線性回歸與多項式回歸方程的不同之處在於它的次數僅為 1。多元線性回歸由多個變量 x1、x2 等組成。 儘管多項式回歸方程只有一個變量 x1,但它有一個度數 n,可以將其與其他兩個區別開來。
需要多項式回歸
從下圖中我們可以看到,在第一個圖中,試圖將一條線性線擬合到給定的一組非線性數據點上。 可以理解,直線很難與這種非線性數據形成關係。 因此,當我們訓練模型時,損失函數會增加,從而導致高誤差。
另一方面,當我們應用多項式回歸時,可以清楚地看到這條線非常適合數據點。 這意味著擬合數據點的多項式方程得出了數據集中變量之間的某種關係。 因此,對於數據點以非線性方式排列的這種情況,我們需要多項式回歸模型。
Python中多項式回歸的實現
從這裡開始,我們將在 Python 中構建一個機器學習模型,實現多項式回歸。 我們將比較線性回歸和多項式回歸得到的結果。 讓我們首先了解我們要用多項式回歸解決的問題。
問題描述
在這種情況下,考慮一家初創公司希望從一家公司僱用幾名候選人的情況。 公司中不同的職位有不同的職位空缺。 初創公司有前公司每個角色的薪水細節。 因此,當候選人提到他或她以前的薪水時,初創公司的 HR 需要用現有數據進行驗證。 因此,我們有兩個獨立變量,即位置和級別。 因變量(輸出)是要使用多項式回歸預測的薪水。
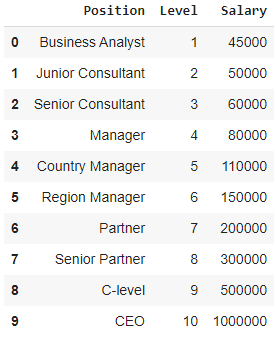
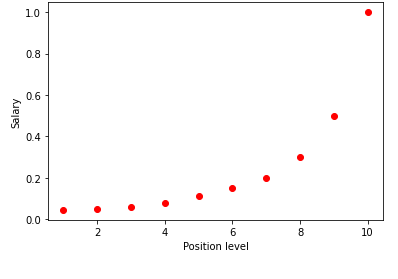
在圖表中可視化上表時,我們看到數據本質上是非線性的。 換句話說,隨著水平的提高,工資會以更高的速度增長,從而給我們一個如下所示的曲線。
第 1 步:數據預處理構建任何機器學習模型的第一步是導入庫。 在這裡,我們只需要導入三個基本庫。 之後,從我的 GitHub 存儲庫中導入數據集,並分配因變量和自變量。 自變量存儲在變量 X 中,因變量存儲在變量 y 中。
將 numpy 導入為 np
將 matplotlib.pyplot 導入為 plt
將熊貓導入為 pd
dataset = pd.read_csv('https://raw.githubusercontent.com/mk-gurucharan/Regression/master/PositionSalaries_Data.csv')

X = dataset.iloc[:, 1:-1].values
y = dataset.iloc[:, -1].values
這裡在術語 [:, 1:-1] 中,第一個冒號表示必須取所有行,術語 1:-1 表示要包含的列是從第一列到倒數第二列,由下式給出-1。
第 2 步:線性回歸模型在下一步中,我們將建立一個多元線性回歸模型,並使用它從自變量中預測工資數據。 為此,從 sklearn 庫中導入了 LinearRegression 類。 然後將其擬合到變量 X 和 y 上以進行訓練。
從 sklearn.linear_model 導入線性回歸
回歸器 = 線性回歸()
regressor.fit(X, y)
建立模型後,在可視化結果時,我們會得到下圖。
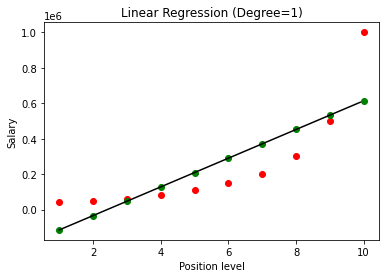
可以清楚地看到,通過嘗試在非線性數據集上擬合一條直線,機器學習模型不會導出任何關係。 因此,我們需要使用多項式回歸來獲得變量之間的關係。
第三步:多項式回歸模型在下一步中,我們將在該數據集上擬合多項式回歸模型並可視化結果。 為此,我們從名為 PolynomialFeatures 的 sklearn 模塊中導入另一個類,在其中我們給出要構建的多項式方程的次數。 然後使用 LinearRegression 類將多項式方程擬合到數據集。
從 sklearn.preprocessing 導入 PolynomialFeatures
從 sklearn.linear_model 導入線性回歸
poly_reg = 多項式特徵(度 = 2)
X_poly = poly_reg.fit_transform(X)
lin_reg = 線性回歸()
lin_reg.fit(X_poly, y)
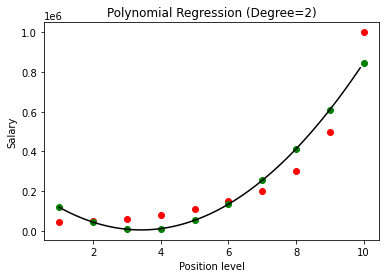
在上面的例子中,我們給了多項式方程的次數等於 2。在繪製圖形時,我們看到有某種曲線是推導出來的,但仍然與實際數據有很大的偏差(紅色)和預測曲線點(綠色)。 因此,在下一步中,我們將多項式的次數增加到更高的數字,例如 3 和 4,然後將其相互比較。
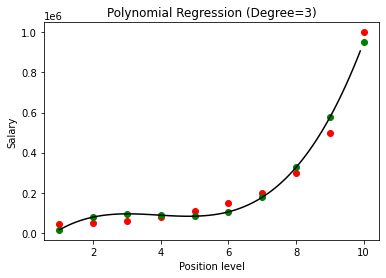
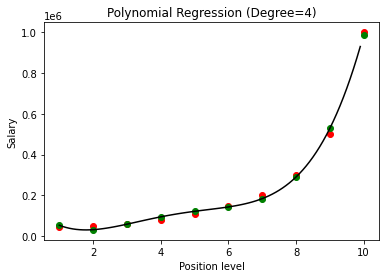
在將多項式回歸的結果與 3 和 4 進行比較時,我們看到隨著度數的增加,模型可以很好地與數據一起訓練。 因此,我們可以推斷出更高的次數使多項式方程能夠更準確地擬合訓練數據。 然而,這是過擬合的完美案例。 因此,精確選擇 n 的值以防止過度擬合變得很重要。
什麼是過擬合?
顧名思義,當一個函數(或本例中的機器學習模型)過於接近一組有限的數據點時,過度擬合被稱為統計中的一種情況。 這會導致函數在處理新數據點時表現不佳。
在機器學習中,如果說模型在給定的一組訓練數據點上過擬合,那麼當將相同的模型引入一組全新的點(比如測試數據集)時,它的表現就會非常糟糕,因為過擬合模型沒有很好地概括數據,只是在訓練數據點上過擬合。
在多項式回歸中,隨著多項式次數的增加,模型很有可能在訓練數據上過擬合。 在上面顯示的示例中,我們看到了多項式回歸中過度擬合的典型案例,可以僅通過反複試驗來選擇最佳度數值來糾正這種情況。
另請閱讀:機器學習項目理念
結論
總而言之,多項式回歸可用於因變量和自變量之間存在非線性關係的許多情況。 儘管該算法對異常值很敏感,但可以通過在擬合回歸線之前對其進行處理來對其進行校正。 因此,在本文中,我們介紹了多項式回歸的概念,以及它在 Python 編程中對簡單數據集的實現示例。
如果您有興趣了解有關機器學習的更多信息,請查看 IIIT-B 和 upGrad 的機器學習和人工智能 PG 文憑,該文憑專為工作專業人士設計,提供 450 多個小時的嚴格培訓、30 多個案例研究和作業、IIIT- B 校友身份、5 個以上實用的實踐頂點項目和頂級公司的工作協助。
從世界頂級大學學習ML 課程。 獲得碩士、Executive PGP 或高級證書課程以加快您的職業生涯。
線性回歸是什麼意思?
線性回歸是一種預測性數值分析,通過它我們可以在因變量的幫助下找到未知變量的值。 它還解釋了一個因變量和一個或多個自變量之間的聯繫。 線性回歸是一種統計技術,用於證明兩個變量之間的聯繫。 線性回歸從一組數據點繪製趨勢線。 線性回歸可用於從看似隨機的數據(例如癌症診斷或股票價格)生成預測模型。 有幾種計算線性回歸的方法。 普通的最小二乘法是最流行的方法之一,它估計數據中的未知變量並在視覺上轉換為數據點和趨勢線之間的垂直距離之和。
線性回歸的一些缺點是什麼?
在大多數情況下,回歸分析用於研究以確定變量之間存在聯繫。 然而,相關性並不意味著因果關係,因為兩個變量之間的聯繫並不意味著一個變量會導致另一個變量的發生。 即使是非常適合數據點的基本線性回歸中的一條線也可能無法確保環境與邏輯結果之間的關係。 使用線性回歸模型,您可以確定變量之間是否存在任何相關性。 需要額外的調查和統計分析來確定鏈接的確切性質以及一個變量是否導致另一個變量。
線性回歸的基本假設是什麼?
在線性回歸中,有三個關鍵假設。 首先,因變量和自變量必須具有線性關係。 因變量和自變量的散點圖用於檢查這種關係。 其次,數據集中自變量之間的多重共線性應該最小或為零。 這意味著自變量是不相關的。 該值必須受到限制,這由域要求決定。 第三個因素是同方差性。 誤差均勻分佈的假設是最基本的假設之一。