
學習機器學習的樸素貝葉斯算法 [附示例]
已發表: 2021-02-25目錄
介紹
在數學和編程中,一些最簡單的解決方案通常是最強大的解決方案。 樸素貝葉斯算法就是這種說法的一個經典例子。 即使隨著機器學習領域的強勁和快速的進步和發展,這種樸素貝葉斯算法仍然是最廣泛使用和最有效的算法之一。 樸素貝葉斯算法在各種問題中都有應用,包括分類任務和自然語言處理 (NLP) 問題。
貝葉斯定理的數學假設是這種樸素貝葉斯算法背後的基本概念。 在本文中,我們將介紹貝葉斯定理的基礎知識,樸素貝葉斯算法及其在 Python 中的實現以及一個實時示例問題。 除了這些,我們還將看看樸素貝葉斯算法與其競爭對手相比的一些優點和缺點。
概率基礎
在我們冒險理解貝葉斯定理和朴素貝葉斯算法之前,讓我們先回顧一下我們現有的概率基礎知識。
正如我們都知道的定義,給定一個事件 A,該事件發生的概率由 P(A) 給出。 在概率上,如果事件 A 的發生不改變事件 B 的發生概率,則將兩個事件 A 和 B 稱為獨立事件,反之亦然。 另一方面,如果一個事件的發生改變了另一個事件的概率,那麼它們被稱為從屬事件。
讓我們介紹一個叫做條件概率的新術語。 在數學中,由 P (A| B) 給出的兩個事件 A 和 B 的條件概率定義為在事件 B 已經發生的情況下,事件 A 發生的概率。 根據兩個事件 A 和 B 之間的關係,它們是獨立的還是獨立的,條件概率以兩種方式計算。
- 兩個相關事件A 和 B的條件概率由 P (A| B) = P (A and B) / P (B) 給出
- 兩個獨立事件A 和 B的條件概率表達式為: P (A| B) = P (A)
了解了概率和條件概率背後的數學原理,現在讓我們繼續研究貝葉斯定理。

貝葉斯定理
在統計和概率論中,貝葉斯定理也稱為貝葉斯規則,用於確定事件的條件概率。 換句話說,貝葉斯定理基於對可能與事件相關的條件的先驗知識來描述事件的概率。
為了以更簡單的方式理解它,請考慮我們需要知道房屋價格的概率非常高。 如果我們知道其他參數,例如附近的學校、醫療商店和醫院的存在,那麼我們可以對其進行更準確的評估。 這正是貝葉斯定理所執行的。
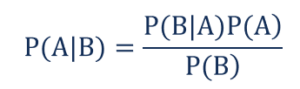
這樣,
- P(A|B) – 事件 A 發生的條件概率,假設事件 B 已經發生,也稱為後驗概率。
- P(B|A) – 事件 B 發生的條件概率,假設事件 A 已經發生,也稱為似然概率。
- P(A) – 事件 A 發生的概率,也稱為先驗概率。
- P(B) – 事件 B 發生的概率,也稱為邊際概率。
假設我們有一個簡單的機器學習問題,其中包含“n”個自變量,而作為輸出的因變量是一個布爾值(真或假)。 假設獨立屬性本質上是分類的,讓我們在這個例子中考慮 2 個類別。 因此,使用這些數據,我們需要計算似然概率 P(B|A) 的值。
因此,通過觀察上述內容,我們發現我們需要計算 2*(2^ n -1 ) 個參數才能學習此機器學習模型。 同樣,如果我們有 30 個布爾獨立屬性,那麼要計算的參數總數將接近 30 億個,這在計算成本上是非常高的。
使用貝葉斯定理構建機器學習模型的困難導致了樸素貝葉斯算法的誕生和發展。
樸素貝葉斯算法
為了實用,需要降低貝葉斯定理的上述複雜度。 這正是在樸素貝葉斯算法中通過做一些假設來實現的。 所做的假設是每個特徵都對結果做出獨立且平等的貢獻。
樸素貝葉斯算法是一種監督學習算法,它基於主要用於解決分類問題的貝葉斯定理。 它是構建機器學習模型以進行快速預測的最簡單和最準確的分類器之一。 在數學上,它是一個概率分類器,因為它使用事件的概率函數進行預測。
示例問題
為了理解假設背後的邏輯,讓我們通過一個簡單的數據集來獲得更好的直覺。
| 顏色 | 類型 | 起源 | 盜竊? |
| 黑色的 | 轎車 | 進口的 | 是的 |
| 黑色的 | 越野車 | 進口的 | 不 |
| 黑色的 | 轎車 | 國內的 | 是的 |
| 黑色的 | 轎車 | 進口的 | 不 |
| 棕色的 | 越野車 | 國內的 | 是的 |
| 棕色的 | 越野車 | 國內的 | 不 |
| 棕色的 | 轎車 | 進口的 | 不 |
| 棕色的 | 越野車 | 進口的 | 是的 |
| 棕色的 | 轎車 | 國內的 | 不 |
從上面給出的數據集中,我們可以推導出我們為上面的樸素貝葉斯算法定義的兩個假設的概念。
- 第一個假設是所有特徵都是相互獨立的。 在這裡,我們看到每個屬性都是獨立的,例如顏色“紅色”獨立於汽車的類型和產地。
- 接下來,每個特徵都被賦予同等的重要性。 同樣,僅了解汽車的類型和來源並不足以預測問題的輸出。 因此,沒有一個變量是不相關的,因此它們都對結果做出了同等的貢獻。
綜上所述,A 和 B 在給定 C 條件下是條件獨立的,當且僅當,在已知 C 發生的情況下,A 是否發生的知識不能提供 B 發生的可能性的信息,而 B 是否發生的知識不能提供關於 B 發生可能性的信息。 A發生的可能性。 這些假設使貝葉斯算法 -樸素。 因此得名樸素貝葉斯算法。
因此,對於上述問題,貝葉斯定理可以重寫為 -
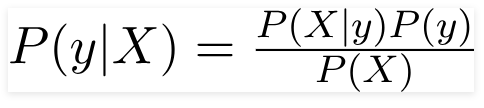
這樣,
- 獨立的特徵向量,X = (x 1 , x 2 , x 3 ……x n ) 表示汽車的顏色、類型和起源等特徵。
- 輸出變量 y 只有兩個結果是或否。
因此,通過代入上述值,我們得到樸素貝葉斯公式:
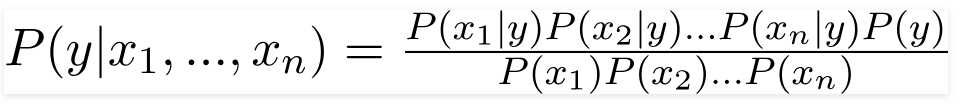
為了計算後驗概率 P(y|X),我們必須針對輸出為每個屬性創建一個頻率表。 然後將頻率表轉換為似然表,然後我們最終使用樸素貝葉斯方程來計算每個類的後驗概率。 具有最高後驗概率的類被選為預測的結果。 以下是所有三個預測變量的頻率和可能性表。
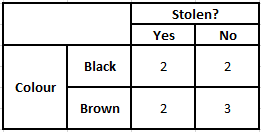
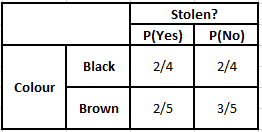
顏色頻率表 顏色似然表
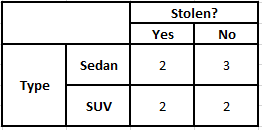
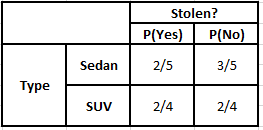
類型頻率表 類型似然表

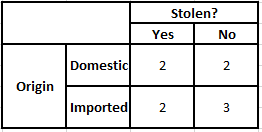
起源頻率表 起源似然表
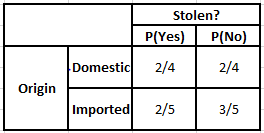
考慮我們需要計算以下給定條件的後驗概率的情況——
| 顏色 | 類型 | 起源 |
| 棕色的 | 越野車 | 進口的 |
因此,根據上面給出的公式,我們可以計算出後驗概率,如下所示 -
P(是 | X) = P(布朗 | 是) * P(SUV | 是) * P(進口 | 是) * P(是)
= 2/5 * 2/4 * 2/5 * 1
= 0.08
P(No | X) = P(Brown | No) * P(SUV | No) * P(進口| No) * P(No)
= 3/5 * 2/4 * 3/5 * 1
= 0.18
從以上計算的數值,由於No的後驗概率大於Yes(0.18>0.08),則可以推斷進口產地為棕色、SUV類型的汽車被歸類為“No”。 因此,汽車沒有被盜。
用 Python 實現
現在我們已經了解了樸素貝葉斯算法背後的數學原理,並通過一個示例對其進行了可視化,讓我們來看看它的 Python 語言機器學習代碼。
相關:樸素貝葉斯分類器
問題分析
為了使用 Python 在機器學習中實現樸素貝葉斯分類程序,我們將使用非常著名的“鳶尾花數據集”。 鳶尾花數據集或費舍爾鳶尾花數據集是英國統計學家、優生學家和生物學家 Ronald Fisher 於 1998 年引入的多元數據集。這是一個非常小且基本的數據集,由非常少的數字數據組成,包含有關 3 類的信息屬於鳶尾屬植物的花是——
- 鳶尾花
- 鳶尾花
- 弗吉尼亞鳶尾
這三個物種中的每一個都有 50 個樣本,總計 150 行的數據集。 該數據集中使用的 4 個屬性(或)自變量是——
- 萼片長度(厘米)
- 萼片寬度厘米
- 花瓣長度厘米
- 花瓣寬度厘米
因變量是由上述給定的四個屬性標識的花的“物種”。
第 1 步 - 導入庫
與往常一樣,構建任何機器學習模型的首要步驟是導入相關庫。 為此,我們將加載 NumPy、Mathplotlib 和 Pandas 庫來預處理數據。
將 numpy 導入為 np
將 matplotlib.pyplot 導入為 plt
將熊貓導入為 pd
第 2 步 - 加載數據集
用於訓練樸素貝葉斯分類器的鳶尾花數據集應加載到 Pandas DataFrame 中。 4 個自變量應分配給變量 X,最終輸出種類變量分配給 y。
dataset = pd.read_csv(' https://raw.githubusercontent.com/mk-gurucharan/Classification/master/IrisDataset.csv' )X = dataset.iloc[:,:4].values
y = 數據集['species'].valuesdataset.head(5)>>
萼片長度 萼片寬度 花瓣長度 花瓣寬度 種
5.1 3.5 1.4 0.2 塞托薩
4.9 3.0 1.4 0.2 塞托薩
4.7 3.2 1.3 0.2 塞托薩
4.6 3.1 1.5 0.2 塞托薩
5.0 3.6 1.4 0.2 塞托薩
第 3 步 - 將數據集拆分為訓練集和測試集
加載數據集和變量後,下一步是準備將接受訓練過程的變量。 在這一步中,我們必須將 X 和 y 變量拆分為訓練和測試數據集。 為此,我們將隨機分配 80% 的數據到將用於訓練目的的訓練集,其餘 20% 的數據作為測試集,在其上測試經過訓練的樸素貝葉斯分類器的準確性。
從 sklearn.model_selection 導入 train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
第 4 步 - 特徵縮放
雖然這是這個小數據集的附加過程,但我添加它是為了讓您在更大的數據集中使用它。 在這種情況下,訓練和測試集中的數據被縮小到 0 到 1 之間的值範圍。這降低了計算成本。
從 sklearn.preprocessing 導入 StandardScaler
sc = 標準縮放器()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
第 5 步 – 在訓練集上訓練樸素貝葉斯分類模型
正是在這一步中,我們從 sklearn 庫中導入了樸素貝葉斯類。 對於這個模型,我們使用高斯模型,還有其他幾個模型,如伯努利、分類和多項式。 因此,將 X_train 和 y_train 擬合到分類器變量以進行訓練。
從 sklearn.naive_bayes 導入 GaussianNB
分類器 = GaussianNB()
分類器.fit(X_train, y_train)
第 6 步 – 預測測試集結果 –
我們使用訓練的模型預測測試集的物種類別,並將其與物種類別的真實值進行比較。
y_pred = 分類器.predict(X_test)
df = pd.DataFrame({'真實值':y_test, '預測值':y_pred})
df>>
實際值 預測值
setosa setosa
setosa setosa
弗吉尼亞弗吉尼亞
雜色雜色
setosa setosa
setosa setosa
………………
維吉尼亞雜色
弗吉尼亞弗吉尼亞
setosa setosa
setosa setosa
雜色雜色
雜色雜色
在上面的比較中,我們看到有一個錯誤的預測是預測 Versicolor 而不是Virginica。
第 7 步 - 混淆矩陣和準確性
當我們處理分類時,評估我們的分類器模型的最佳方法是在測試集上打印混淆矩陣及其準確性。
從 sklearn.metrics 導入混淆矩陣
cm=confusion_matrix(y_test, y_pred) from sklearn.metrics import accuracy_score
打印(“準確性:”,accuracy_score(y_test,y_pred))
厘米>>精度:0.9666666666666667
>>array([[14, 0, 0],
[ 0, 7, 0],
[ 0, 1, 8]])
結論
因此,在本文中,我們已經了解了樸素貝葉斯算法的基礎知識,了解了分類背後的數學原理以及一個手動解決的示例。 最後,我們實現了一個機器學習代碼來使用樸素貝葉斯分類算法來解決一個流行的數據集。
如果您有興趣了解更多關於人工智能、機器學習的信息,請查看 IIIT-B 和 upGrad 的機器學習和人工智能 PG 文憑,該文憑專為在職專業人士設計,提供 450 多個小時的嚴格培訓、30 多個案例研究和作業, IIIT-B 校友身份、5 個以上實用的實踐頂點項目和頂級公司的工作協助。
概率在機器學習中有何幫助?
我們可能不得不根據現實世界場景中的部分或不完整信息做出決策。 概率幫助我們量化此類系統中的不確定性並管理任務的風險。 傳統方法僅適用於特定行動的確定性結果,但在任何預測模型中總是存在一定範圍的不確定性。 這種不確定性可能來自輸入數據中的許多參數,例如數據中的噪聲。 此外,來自概率定理的貝葉斯觀點可以幫助從輸入數據中識別模式。 為此,概率使用最大似然估計概念,因此有助於產生相關結果。
混淆矩陣有什麼用?
混淆矩陣是一個 2x2 矩陣,用於解釋分類模型的性能。 必須知道輸入數據的真實值才能使其正常工作,因此無法表示未標記的數據。 它由假陽性(FP)、真陽性(TP)、假陰性(FN)和真陰性(TN)的數量組成。 使用來自訓練集和測試集的計數將預測分類為這些類。 它幫助我們可視化有用的參數,例如準確度、精確度、召回率和特異性。 它相對容易理解,並讓您對算法有一個清晰的了解。
樸素貝葉斯模型有哪些不同類型?
所有類型都主要基於貝葉斯定理。 樸素貝葉斯模型一般有高斯、伯努利和多項式三種。 高斯樸素貝葉斯輔助輸入參數的連續值,它假設所有輸入數據類別都是均勻分佈的。 伯努利的樸素貝葉斯是一種基於事件的模型,其中數據特徵是獨立的並以布爾值的形式出現。 多項樸素貝葉斯也是基於基於事件的模型。 它具有矢量形式的數據特徵,表示基於事件發生的相關頻率。