
混合有形和無形:使用 Adobe XD 設計多模式界面
已發表: 2022-03-10(本文由 Adobe 贊助。)用戶界面在不斷發展。 支持語音的界面正在挑戰圖形用戶界面的長期主導地位,並迅速成為我們日常生活中常見的一部分。 自動語音識別 (APS) 和自然語言處理 (NLP) 方面的重大進展,以及令人印象深刻的消費者基礎(數百萬內置語音助手的移動設備),影響了基於語音的界面的快速開發和採用。
以語音為主要界面的產品越來越受歡迎。 僅在美國,就有 4730 萬成年人可以使用智能揚聲器(占美國成年人口的五分之一),而且這個數字還在增長。 但語音接口不僅在個人和家庭使用中有著光明的未來。 隨著人們習慣於語音界面,他們也會在商業環境中期待它們。 想像一下,很快您就可以通過說“顯示我的演示文稿”之類的話來觸發會議室投影儀。
很明顯,人機交流正在迅速擴展到包括書面和口頭互動。 但這是否意味著未來的界面將是純語音的? 儘管有一些科幻小說的描述,但語音不會完全取代圖形用戶界面。 相反,我們將在一種新的界面格式中實現語音、視覺和手勢的協同作用:支持語音的多模式界面。
在本文中,我們將:
- 探索啟用語音的界面的概念並審查不同類型的啟用語音的界面;
- 找出為什麼支持語音的多模式用戶界面將成為首選的用戶體驗;
- 了解如何使用 Adobe XD 構建多模式 UI。
語音用戶界面 (VUI) 的狀態
在深入了解語音用戶界面的細節之前,我們必須定義什麼是語音輸入。 語音輸入是一種人機交互,其中用戶說出命令而不是編寫命令。 語音輸入的美妙之處在於它對人們來說是一種更自然的交互——用戶在與系統交互時不受特定語法的限制; 他們可以用許多不同的方式來組織他們的輸入,就像他們在人類對話中所做的那樣。
語音用戶界面為其用戶帶來以下好處:
- 更少的交互成本
儘管使用支持語音的界面確實會產生交互成本,但這個成本(理論上)比學習新 GUI 的成本要小。 - 免提控制
VUI 非常適合用戶忙碌的時候——例如,在開車、做飯或鍛煉時。 - 速度
當提出問題比打字和閱讀結果更快時,語音非常好。 例如,在汽車中使用語音時,嚮導航系統說出地點比在觸摸屏上輸入位置更快。 - 情感和個性
即使我們聽到聲音但看不到說話者的圖像,我們也可以在腦海中想像說話者。 這有機會提高用戶參與度。 - 可訪問性
視覺障礙用戶和行動障礙用戶可以使用語音與系統交互。
三種類型的語音接口
根據語音的使用方式,它可能是以下類型的接口之一。
屏幕優先設備中的語音代理
Apple Siri 和 Google Assistant 是語音代理的主要例子。 對於這樣的系統,語音更像是對現有 GUI 的增強。 在許多情況下,代理是用戶旅程的第一步:用戶觸發語音代理並通過語音提供命令,而所有其他交互都使用觸摸屏完成。 例如,當您向 Siri 提問時,它會以列表的形式提供答案,您需要與該列表進行交互。 結果,用戶體驗變得支離破碎——我們使用語音來啟動交互,然後轉向觸摸來繼續它。
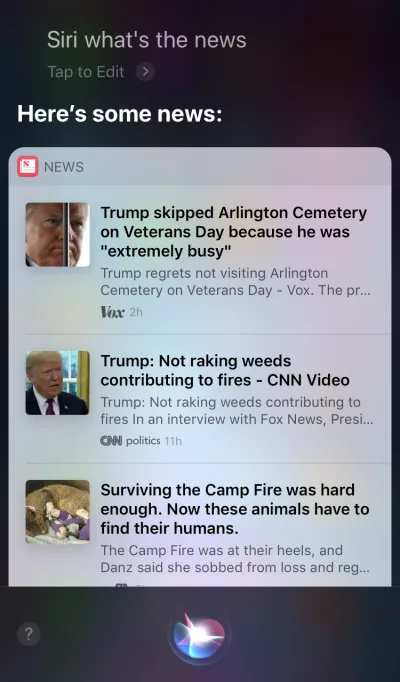
純語音設備
這些設備沒有視覺顯示; 用戶依賴音頻進行輸入和輸出。 Amazon Echo 和 Google Home 智能揚聲器是此類產品的主要示例。 缺乏視覺顯示是對設備向用戶傳達信息和選項的能力的重大限制。 因此,大多數人使用這些設備來完成簡單的任務,例如播放音樂和獲得簡單問題的答案。

語音優先設備
使用語音優先系統,該設備主要通過語音命令接受用戶輸入,但也有一個集成的屏幕顯示。 這意味著語音是主要的用戶界面,但不是唯一的。 “一圖胜千言”這句老話仍然適用於現代語音系統。 人腦擁有令人難以置信的圖像處理能力——當我們在視覺上看到復雜的信息時,我們可以更快地理解複雜的信息。 與純語音設備相比,語音優先設備允許用戶訪問更多信息並使許多任務更容易。
Amazon Echo Show 是採用語音優先系統的設備的典型示例。 視覺信息逐漸成為整體系統的一部分——屏幕上沒有加載應用程序圖標; 相反,該系統鼓勵用戶嘗試不同的語音命令(建議口頭命令,例如“試試‘Alexa,告訴我下午 5:00 的天氣’”)。 屏幕甚至使諸如在烹飪時檢查食譜等常見任務變得更加容易——用戶無需仔細聆聽並將所有信息留在腦海中; 當他們需要信息時,他們只需看一下屏幕。

引入多模式接口
在 UI 設計中使用語音時,不要將語音視為可以單獨使用的東西。 Amazon Echo Show 等設備包括一個屏幕,但使用語音作為主要輸入方法,從而提供更全面的用戶體驗。 這是邁向新一代用戶界面的第一步:多模式界面。
多模式界面是將語音、觸摸、音頻和不同類型的視覺效果融合在一個無縫的 UI 中的界面。 Amazon Echo Show 是充分利用支持語音的多模式界面的設備的絕佳示例。 當用戶與 Show 交互時,他們會像使用純語音設備一樣發出請求; 但是,他們收到的響應可能是多模式的,包含語音和視覺響應。
多模式產品比僅依賴視覺或僅依賴語音的產品更複雜。 為什麼任何人都應該首先創建多模式界面? 要回答這個問題,我們需要退後一步,看看人們如何看待他們周圍的環境。 人有五種感官,我們的感官共同作用就是我們感知事物的方式。 例如,當我們在現場音樂會上聽音樂時,我們的感官會協同工作。 去除一種感覺(例如,聽覺),體驗就會呈現出完全不同的背景。

長期以來,我們一直認為用戶體驗完全是視覺或手勢設計。 是時候改變這種想法了。 多模式設計是一種思考和設計將我們的感官能力聯繫在一起的體驗的方式。
多模式界面讓用戶和機器的交流感覺更人性化。 它們為更深入的互動開闢了新的機會。 而今天,設計多模式界面變得更加容易,因為過去限制與產品交互的技術限制正在被消除。
GUI和多模式界面之間的區別
這裡的關鍵區別在於,像 Amazon Echo Show 這樣的多模式界面同步語音和視覺界面。 因此,當我們在設計體驗時,聲音和視覺不再是獨立的部分; 它們是系統提供的體驗的組成部分。
視覺和語音頻道:何時使用
將語音和視覺視為輸入和輸出的渠道很重要。 每個渠道都有自己的優勢和劣勢。
讓我們從視覺效果開始。 很明顯,有些信息在我們看到時比在聽到時更容易理解。 當您需要提供以下內容時,視覺效果會更好:
- 很長的選項列表(閱讀很長的列表將花費大量時間並且難以理解);
- 數據量大的信息(例如圖表);
- 產品信息(例如,在線商店中的產品;很可能,您希望在購買前查看產品)和產品比較(由於選項列表很長,僅使用語音很難提供所有信息) .
然而,對於某些信息,我們可以很容易地依靠口頭交流。 語音可能適合以下情況:
- 用戶命令(語音是一種高效的輸入方式,允許用戶快速向系統發出命令並繞過複雜的導航菜單);
- 簡單的用戶說明(例如,對處方的例行檢查);
- 警告和通知(例如,在駕駛過程中與語音通知配對的音頻警告)。
雖然這些是視覺和語音結合的一些典型案例,但重要的是要知道我們不能將兩者分開。 只有語音和視覺協同工作,我們才能創造更好的用戶體驗。 例如,假設我們想購買一雙新鞋。 我們可以使用語音向系統請求“給我看 New Balance 鞋子”。 系統會處理您的請求並直觀地提供產品信息(我們比較鞋子的一種更簡單的方法)。
設計支持語音的多模式界面需要了解的內容
語音是 UX 設計師最激動人心的挑戰之一。 儘管它很新穎,但設計支持語音的多模式界面的基本規則與我們用於創建視覺設計的規則相同。 設計師應該關心他們的用戶。 他們的目標應該是通過以有效的方式解決他們的問題來減少用戶的摩擦,並優先考慮清晰性以使用戶的選擇清晰。
但多模式界面也有一些獨特的設計原則。
確保您解決了正確的問題
設計應該解決問題。 但解決正確的問題至關重要; 否則,您可能會花費大量時間來創建不會給用戶帶來太多價值的體驗。 因此,請確保您專注於解決正確的問題。 語音交互應該對用戶有意義; 用戶應該有令人信服的理由使用語音而不是其他交互方式(例如點擊或點擊)。 這就是為什麼當你創建一個新產品時——甚至在開始設計之前——進行用戶研究並確定語音是否會改善用戶體驗是至關重要的。
從創建用戶旅程圖開始。 分析旅程圖並找到將語音作為渠道的地方將使用戶體驗受益。
- 尋找用戶可能會遇到摩擦和挫折的旅程中的地方。 使用語音會減少摩擦嗎?
- 考慮用戶的上下文。 語音是否適用於特定環境?
- 想想語音的獨特之處。 記住使用語音的獨特優勢,例如免提和免眼交互。 語音可以為體驗增加價值嗎?
創建對話流
理想情況下,您設計的界面應該需要零交互成本:用戶應該能夠滿足他們的需求,而無需花費額外的時間來學習如何與系統進行交互。 僅當語音交互類似於真實對話而不是以語音命令格式包裝的系統對話時才會發生這種情況。 良好 UI 的基本規則很簡單:計算機應該適應人類,而不是相反。
人們很少有平坦的、線性的對話(只持續一回合的對話)。 這就是為什麼要使與系統的交互感覺像現場對話,設計師應該專注於創建對話流。 每個對話流都包含對話——系統和用戶之間發生的路徑。 每個對話都將包括系統的提示和用戶可能的反應。
會話流可以以流程圖的形式呈現。 每個流程都應該關註一個特定的用例(例如,使用系統設置鬧鐘)。 對於流程中的大多數對話,當事情脫軌時,考慮錯誤路徑至關重要。
用戶的每個語音命令都包含三個關鍵要素:意圖、話語和時隙。
- 意圖是用戶與啟用語音的系統交互的目標。
意圖只是定義一組詞背後的目的的一種奇特方式。 與系統的每次交互都會給用戶帶來一些實用性。 無論是信息還是動作,實用程序都是有目的的。 了解用戶的意圖是啟用語音的界面的關鍵部分。 當我們設計 VUI 時,我們並不總是能確定用戶的意圖是什麼,但我們可以很準確地猜測出來。 - 話語是用戶如何表達他們的請求。
通常,用戶有不止一種方法來製定語音命令。 例如,我們可以通過說“將鬧鐘設置為早上 8 點”、“鬧鐘明天早上 8 點”甚至“我需要早上 8 點起床”來設置鬧鐘。 設計者需要考慮每一種可能的話語變化。 - 槽是用戶在命令中使用的變量。 有時用戶需要在請求中提供附加信息。 在我們的鬧鐘示例中,“8 am”是一個時隙。
不要把話放在用戶的嘴裡
人們知道如何說話。 不要試圖教他們命令。 避免使用諸如“要發送會議預約,您需要說‘日曆,會議,創建新會議’”之類的短語。 如果必須解釋命令,則需要重新考慮設計系統的方式。 始終以自然語言對話為目標,並嘗試適應不同的說話風格)。
力求一致性
您需要在不同環境中實現語言和語音的一致性。 一致性將有助於在交互中建立熟悉度。
始終提供反饋
系統狀態的可見性是良好 GUI 設計的基本原則之一。 系統應始終在合理的時間內通過適當的反饋讓用戶了解正在發生的事情。 同樣的規則也適用於 VUI 設計。
- 讓用戶知道系統正在監聽。
當設備正在偵聽或處理用戶請求時顯示視覺指示器。 沒有反饋,用戶只能猜測系統是否在做某事。 這就是為什麼即使像 Amazon Echo 和 Google Home 這樣的純語音設備在收聽或搜索答案時也會給我們很好的視覺反饋(閃光燈)。 - 提供對話標記。
對話標記告訴用戶他們在對話中的位置。 - 確認任務何時完成。
例如,當用戶向支持語音的智能家居系統詢問“關掉車庫的燈”時,系統應該讓用戶知道該命令已成功執行。 未經確認,用戶將需要走進車庫並檢查燈光。 它違背了智能家居系統的目的,即讓用戶的生活更輕鬆。
避免長句
在設計支持語音的系統時,請考慮向用戶提供信息的方式。 當您使用長句子時,相對容易讓用戶因過多的信息而不知所措。 首先,用戶無法在短期記憶中保留大量信息,因此很容易忘記一些重要信息。 此外,音頻是一種慢速媒介——大多數人的閱讀速度比他們聽的快得多。
尊重用戶的時間; 不要朗讀冗長的音頻獨白。 在設計響應時,使用的詞越少越好。 但請記住,您仍然需要為用戶提供足夠的信息來完成他們的任務。 因此,如果您不能用幾句話概括答案,請將其顯示在屏幕上。
按順序提供後續步驟
用戶不僅會被長句子壓得喘不過氣來,而且一次選擇的數量也會讓用戶不知所措。 將與支持語音的系統的交互過程分解成小塊至關重要。 限制用戶在任何時候的選擇數量,並確保他們每時每刻都知道該做什麼。
在設計具有許多功能的複雜語音系統時,您可以使用漸進式披露技術:僅提供完成任務所需的選項或信息。
擁有強大的錯誤處理策略
當然,系統應該首先防止錯誤發生。 但是,無論您的語音系統有多好,您都應該始終針對系統無法理解用戶的場景進行設計。 您的責任是針對此類情況進行設計。
以下是創建策略的一些實用技巧:
- 不要責怪用戶。
在對話中,沒有錯誤。 盡量避免諸如“你的答案不正確”之類的回答。 - 提供錯誤恢復流程。
提供在對話中來回切換的選項,甚至退出系統,而不會丟失重要信息。 保存用戶在旅程中的狀態,以便他們可以從上次中斷的地方重新與系統互動。 - 讓用戶重播信息。
提供使系統重複問題或答案的選項。 這對於用戶難以將所有信息提交到他們的工作記憶中的複雜問題或答案可能會有所幫助。 - 提供停止措辭。
在某些情況下,用戶對收聽某個選項不感興趣,並希望系統停止談論它。 停止措辭應該幫助他們做到這一點。 - 優雅地處理意料之外的話語。
無論你在系統設計上投入多少,都會出現系統不理解用戶的情況。 優雅地處理此類案件至關重要。 不要害怕讓系統承認缺乏理解。 系統應該傳達它所理解的內容並提供有用的提示。 - 使用分析來改進您的錯誤策略。
分析可以幫助您識別錯誤的轉折和誤解。
跟踪上下文
確保系統理解用戶輸入的上下文。 例如,當有人說他們想預訂下週飛往舊金山的航班時,他們可能會在對話流中提到“它”或“城市”。 系統應該記住所說的內容,並能夠將其與新收到的信息相匹配。

了解您的用戶以創建更強大的交互
當啟用語音的系統使用附加信息(例如用戶上下文或過去的行為)來了解用戶想要什麼時,它會變得更加複雜。 這種技術被稱為智能解釋,它要求系統主動了解用戶並能夠相應地調整他們的行為。 這些知識將幫助系統為複雜的問題提供答案,例如“我應該為妻子的生日買什麼禮物?”
賦予您的 VUI 個性
無論您是否計劃,每個支持語音的系統都會對用戶產生情感影響。 人們將聲音與人類而非機器聯繫起來。 根據 Speak Easy Global Edition 的研究,74% 的語音技術普通用戶希望品牌能夠為其支持語音的產品提供獨特的聲音和個性。 通過個性建立同理心並實現更高水平的用戶參與度是可能的。
嘗試在您呈現的聲音和語氣中反映您獨特的品牌和身份。 構建啟用語音的代理的角色,並在創建對話時依賴此角色。
建立信任
當用戶不信任一個系統時,他們就沒有使用它的動力。 這就是為什麼建立信任是產品設計的要求。 有兩個因素對建立的信任水平有重大影響:系統能力和有效結果。
建立信任始於設定用戶期望。 傳統的 GUI 有很多視覺細節來幫助用戶了解系統的功能。 借助支持語音的系統,設計人員可以依賴的工具更少。 儘管如此,讓系統自然可發現仍然至關重要。 用戶應該了解系統可以做什麼和不可以做什麼。 這就是為什麼啟用語音的系統可能需要用戶入職,在其中討論系統可以做什麼或知道什麼。 在設計入職培訓時,嘗試提供有意義的示例,讓人們知道它可以做什麼(示例比說明更有效)。
當談到有效的結果時,人們知道支持語音的系統是不完美的。 當系統提供答案時,一些用戶可能會懷疑答案是否正確。 發生這種情況是因為用戶沒有任何關於他們的請求是否被正確理解或使用什麼算法來找到答案的信息。 為防止出現信任問題,請使用支持證據的屏幕——在屏幕上顯示原始查詢——並提供有關算法的一些關鍵信息。 例如,當用戶詢問“給我看 2018 年排名前五的電影”時,系統可以說,“這裡是 2018 年美國票房排名前五的電影”。
不要忽視安全和數據隱私
與屬於個人的移動設備不同,語音設備往往屬於某個位置,例如廚房。 通常,同一地點有不止一個人。 試想一下,其他人可以與可以訪問您所有個人數據的系統進行交互。 Amazon Alexa、Google Assistant 和 Apple Siri 等一些 VUI 系統可以識別個人聲音,這為系統增加了一層安全性。 儘管如此,它並不能保證系統能夠在 100% 的情況下根據用戶獨特的語音簽名識別用戶。
語音識別在不斷改進,在不久的將來模仿聲音將很難或幾乎不可能。 但是,在當前現實中,提供額外的身份驗證層以向用戶保證他們的數據是安全的至關重要。 如果您設計的應用程序可以處理敏感數據,例如健康信息或銀行詳細信息,您可能需要包含額外的身份驗證步驟,例如密碼或指紋或面部識別。
進行可用性測試
可用性測試是任何系統的強制性要求。 儘早測試,經常測試應該是您設計過程的基本規則。 儘早收集用戶研究數據,並迭代您的設計。 但測試多模式接口有其自身的特點。 以下是應考慮的兩個階段:
- 構思階段
試駕您的示例對話框。 練習大聲朗讀示例對話。 一旦你有了一些對話流,記錄對話的雙方(用戶的話語和系統的響應),並聽錄音以了解它們聽起來是否自然。 - 產品開發的早期階段(使用 lo-fi 原型進行測試)
綠野仙踪測試非常適合測試會話界面。 綠野仙踪測試是一種測試,參與者與他們認為由計算機操作但實際上由人操作的系統進行交互。 測試參與者提出一個問題,另一端有一個真人回答。 這種方法得名於弗蘭克鮑姆的《綠野仙踪》一書。 書中,一個普通人躲在窗簾後面,偽裝成一個強大的巫師。 該測試允許您繪製出所有可能的交互場景,從而創建更自然的交互。 Say Wizard 是一款出色的工具,可幫助您在 macOS 上運行綠野仙踪語音界面測試。 - 產品開發的後期階段(使用高保真原型進行測試)
在圖形用戶界面的可用性測試中,我們經常要求用戶在與系統交互時大聲說出來。 對於支持語音的系統,這並不總是可行的,因為系統會收聽該旁白。 因此,最好觀察用戶與系統的交互,而不是讓他們大聲說出來。
如何使用 Adobe XD 創建多模式界面
現在您已經對什麼是多模式界面以及設計它們時要記住的規則有了深入的了解,我們可以討論如何製作多模式界面的原型。
原型設計是設計過程的基本部分。 能夠將想法變為現實並與他人分享非常重要。 到目前為止,想要在原型設計中加入語音的設計師幾乎沒有可以依賴的工具,其中最強大的是流程圖。 描繪用戶如何與系統交互需要查看流程圖的人的大量想像力。 借助 Adobe XD,設計師現在可以訪問語音媒體,並可以在他們的原型中使用它。 XD 在一個應用程序中無縫連接屏幕和語音原型。
新體驗,相同流程
儘管語音是一種與視覺完全不同的媒介,但在 Adobe XD 中為語音製作原型的過程與為 GUI 製作原型的過程幾乎相同。 Adobe XD 團隊以一種讓任何設計師都感覺自然和直觀的方式集成語音。 設計人員可以使用語音觸發器和語音播放與原型進行交互:
- 當用戶說出特定的單詞或短語(話語)時,語音觸發器會開始交互。
- 語音播放使設計人員可以訪問文本到語音引擎。 XD 會說出設計師定義的單詞和句子。 語音播放可用於許多不同的目的。 例如,它可以作為確認(讓用戶放心)或指導(讓用戶知道下一步該做什麼)。
XD 的偉大之處在於它不會強迫您了解每個語音平台的複雜性。
說得夠多了——讓我們看看它是如何工作的。 對於您將在下面看到的所有示例,我使用了使用用於 Amazon Alexa 的 Adobe XD UI 工具包創建的畫板(這是下載工具包的鏈接)。 該套件包含為 Amazon Alexa 創建體驗所需的所有樣式和組件。
假設我們有以下畫板:
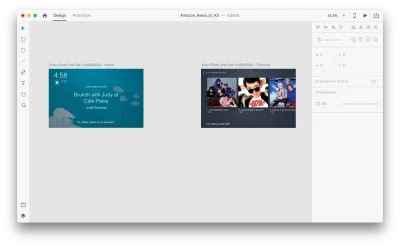
讓我們進入原型模式以添加一些語音交互。 我們將從語音觸發器開始。 除了點擊和拖動等觸發器外,我們現在還可以使用語音作為觸發器。 我們可以將任何圖層用於語音觸發器,只要它們有通向另一個畫板的句柄即可。 讓我們將畫板連接在一起。
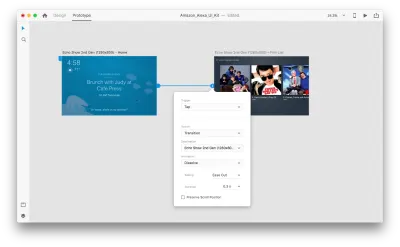
一旦我們這樣做,我們將在“觸發器”下找到一個新的“語音”選項。 當我們選擇此選項時,我們將看到一個“命令”字段,我們可以使用它來輸入話語——這就是 XD 實際監聽的內容。 用戶需要說出此命令才能激活觸發器。
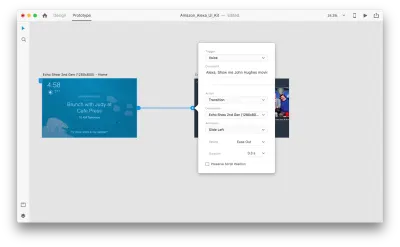
就這樣! 我們已經定義了我們的第一個語音交互。 現在,用戶可以說點什麼,原型就會做出響應。 但是我們可以通過添加語音播放來使這種交互更加強大。 正如我之前提到的,語音播放允許系統說出一些單詞。
選擇整個第二個畫板,然後單擊藍色手柄。 選擇一個帶有延遲的“時間”觸發器並將其設置為 0.2 秒。 在該動作下,您會找到“語音播放”。 我們將記下虛擬助手對我們說的話。
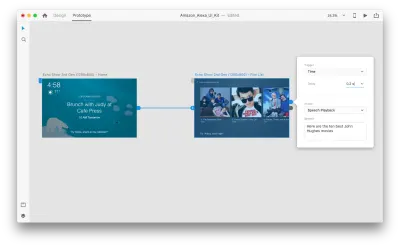
我們已準備好測試我們的原型。 選擇第一個畫板,然後單擊右上角的播放按鈕將啟動一個預覽窗口。 與語音原型交互時,請確保您的麥克風已打開。 然後,按住空格鍵說出語音命令。 這個輸入觸發原型中的下一個動作。
使用自動動畫使體驗更加動態
動畫給 UI 設計帶來了很多好處。 它具有明確的功能目的,例如:
- 傳達對象之間的空間關係(對象來自哪裡?這些對像是否相關?);
- 交流可供性(接下來我能做什麼?)
但功能性目的並不是動畫的唯一好處。 動畫還使體驗更加生動和動態。 這就是為什麼 UI 動畫應該是多模式界面的自然組成部分。
借助 Adobe XD 中的“自動動畫”功能,創建具有沉浸式動畫過渡的原型變得更加容易。 Adobe XD 為您完成所有繁重的工作,因此您無需擔心。 要在兩個畫板之間創建動畫過渡,您只需複制一個畫板,修改克隆中的對象屬性(大小、位置和旋轉等屬性),然後應用自動動畫操作。 XD 將自動為每個畫板之間的屬性差異設置動畫。
讓我們看看它在我們的設計中是如何工作的。 假設我們在 Amazon Echo Show 中有一個現有的購物清單,並且想要使用語音向清單中添加一個新對象。 複製以下畫板:
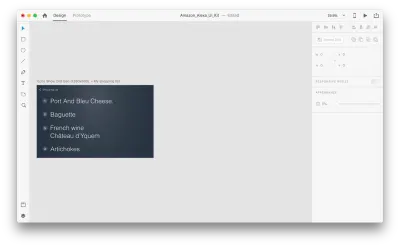
讓我們介紹一下佈局的一些變化: 添加一個新對象。 我們不限於此,因此我們可以輕鬆地修改任何屬性,例如文本屬性、顏色、不透明度、對象的位置——基本上,我們所做的任何更改,XD 都會在它們之間生成動畫。
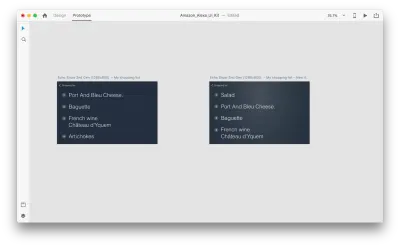
當您在原型模式下使用“動作”中的自動動畫將兩個畫板連接在一起時,XD 將自動為每個畫板之間的屬性差異設置動畫。
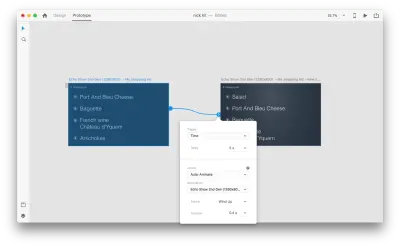
以下是用戶對交互的看法:

需要提及的一件關鍵事情:保持所有層的名稱相同; 否則,Adobe XD 將無法應用自動動畫。
結論
我們正處於用戶界面革命的黎明。 新一代的界面——多模式界面——不僅會給用戶更多的權力,也會改變用戶與系統交互的方式。 We will probably still have displays, but we won't need keyboards to interact with the systems.
At the same time, the fundamental requirements for designing multimodal interfaces won't be much different from those of designing modern interfaces. Designers will need to keep the interaction simple; focus on the user and their needs; design, prototype, test and iterate.
And the great thing is that you don't need to wait to start designing for this new generation of interfaces. You can start today.
本文是 Adobe 贊助的 UX 設計系列的一部分。 Adobe XD 工具專為快速流暢的 UX 設計流程而設計,因為它可以讓您更快地從構思轉變為原型。 設計、原型製作和分享——都在一個應用程序中。 您可以在 Behance 上查看使用 Adobe XD 創建的更多鼓舞人心的項目,還可以註冊 Adobe 體驗設計時事通訊,以隨時了解 UX/UI 設計的最新趨勢和見解。