
2022 年 15 個機器學習面試問題和答案
已發表: 2021-01-08您是希望在機器學習領域取得成功的人嗎? 如果是這樣,對你來說太好了!
但首先,您必須為破冰船——ML 面試做好準備。
由於準備面試的過程可能會讓人不知所措,因此我們決定介入 - 這是機器學習面試中 15 個最常見問題的精選列表!
- 深度學習和機器學習有什麼區別?
機器學習涉及應用和使用高級算法來解析數據,發現數據中隱藏的模式並從中學習,最後應用所學的見解來做出明智的業務決策。 至於深度學習,它是機器學習的一個子集,涉及使用從人腦的神經網絡結構中汲取靈感的人工神經網絡。 深度學習廣泛用於特徵檢測。
- 定義——精確度和召回率。
精度或正預測值衡量或更精確地預測模型聲稱的真實陽性數量與其實際聲稱的陽性數量相比。
召回率或真陽性率是指模型聲稱的陽性數與整個數據中存在的實際陽性數相比。

加入來自世界頂級大學的在線機器學習課程——碩士、高管研究生課程和 ML 和 AI 高級證書課程,以加快您的職業生涯。
- 解釋術語“偏差”和“方差”。 '
在訓練過程中,學習算法的預期誤差通常被分類或分解為兩部分——偏差和方差。 雖然“偏差”是由於在學習算法中使用簡單假設而導致的錯誤情況,但“方差”表示由於該學習算法在數據分析中的複雜性而導致的錯誤。 偏差衡量學習算法創建的平均分類器與目標函數的接近程度,方差衡量學習算法的預測對於不同訓練數據集的變化程度。
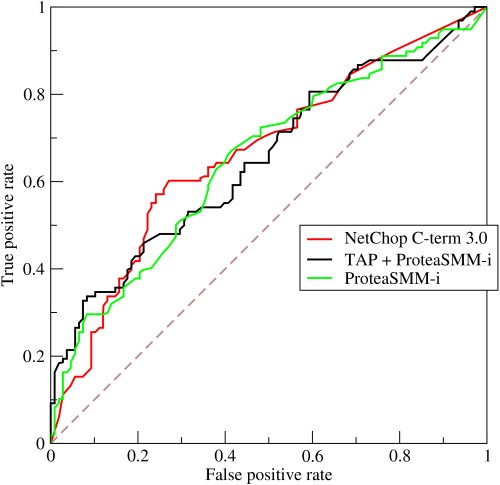
- ROC 曲線如何發揮作用?
ROC 或接收者操作特徵曲線是真陽性率和假陽性率在不同閾值下的變化的圖形表示。 它是診斷測試評估的基本工具,通常用作模型靈敏度(真陽性)與觸發誤報概率(假陽性)之間的權衡取捨。
資源
- 該曲線描繪了敏感性和特異性之間的權衡——如果敏感性增加,特異性就會降低。
- 如果曲線更靠近左軸和 ROC 空間的頂部,則測試通常更準確。 但是,如果曲線更接近 ROC 空間的 45 度對角線,則測試的準確性或可靠性會降低。
- 切點處切線的斜率表示該特定檢驗值的似然比 (LR)。
- 曲線下面積衡量測試精度。
- 解釋類型 1 和類型 2 錯誤之間的區別?
類型 1 錯誤是一種誤報錯誤,它“聲稱”發生了事件,而實際上沒有發生任何事情。 誤報錯誤的最佳示例是誤報火警——當沒有火災時警報開始響起。 與此相反,類型 2 錯誤是一種假陰性錯誤,當某些事情確實發生時,它“聲稱”沒有發生任何事情。 告訴孕婦她沒有懷孕是第 2 類錯誤。
- 為什麼貝葉斯被稱為“樸素貝葉斯”?
樸素貝葉斯之所以被稱為“樸素”,是因為它雖然有很多實際應用,但它基於在現實生活數據中不可能找到的假設——數據集中的所有特徵都是至關重要的、獨立的和平等的。 在樸素貝葉斯方法中,條件概率被計算為單個組件概率的純乘積,從而暗示特徵的完全獨立性。 不幸的是,這個假設在現實世界中永遠無法實現。
- 術語“過度擬合”是什麼意思? 你能避免嗎? 如果是這樣,怎麼做?
通常,在訓練過程中,模型會被輸入大量數據。 在這個過程中,數據甚至從樣本數據集中存在的不准確信息和噪聲中開始學習。 這會對模型在新數據上的性能產生負面影響,即模型無法準確地將新實例/數據與訓練集分開。 這被稱為過度擬合。
是的,可以避免過度擬合。 這是如何做:
- 收集更多數據(來自不同來源)以使用不同樣本訓練模型。
- 應用使用 bagging 方法的集成方法(例如,隨機森林),通過將多個決策樹的結果並列在數據集的不同單元上來最小化預測的變化。
- 確保使用交叉驗證技術。
- 命名監督學習中用於校準的兩種方法。
監督學習中的兩種校準方法是——普拉特校準和等滲回歸。 這兩種方法都是專門為二進制分類而設計的。
- 為什麼要修剪決策樹?
需要修剪決策樹以去除預測能力較弱的分支。 這有助於最小化決策樹模型的複雜度並優化其預測準確性。 修剪可以自上而下或自下而上進行。 減少錯誤修剪、成本複雜度修剪、錯誤複雜度修剪和最小錯誤修剪是一些最常用的決策樹修剪方法。

- F1分數是什麼意思?
簡單來說,F1 分數是衡量模型性能的指標——模型的 Precision 和 Recall 的平均值,接近 1 的結果是最好的,接近 0 的結果是最差的。 F1 分數可用於不重視真陰性的分類測試。
- 區分生成算法和判別算法。
生成算法學習數據的類別,而判別算法學習不同數據類別之間的區別。 在分類任務方面,判別模型通常超過生成模型。
- 什麼是集成學習?
集成學習使用學習算法的組合來優化模型的預測性能。 在這種方法中,分類器或專家等多個模型都被戰略性地生成和組合,以防止模型中的過度擬合。 它主要用於增強模型的預測、分類、函數逼近、性能等。
- 定義“內核技巧”。
內核技巧方法涉及使用可以在更高維和隱式特徵空間中操作的內核函數,而無需顯式計算該維度內點的坐標。 核函數計算特徵空間中存在的所有數據對的圖像之間的內積。 與坐標的顯式計算相比,此過程的計算成本更低,並且被稱為內核技巧。
- 您應該如何處理數據集中丟失或損壞的數據?
要在數據集中查找丟失/損壞的數據,您必須刪除行和列或將它們替換為其他值。 Pandas 庫有兩種很好的方法來查找丟失/損壞的數據——isnull() 和 dropna()。 這兩個函數都專門設計用於幫助您查找數據缺失/損壞的數據行/列並刪除這些值。
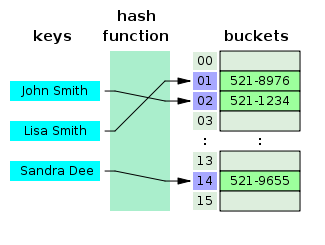
- 什麼是哈希表?
哈希表是一種創建關聯數組的數據結構,其中通過使用哈希函數將鍵映射到特定值。 哈希表主要用於數據庫索引。
資源
這個問題列表只是為了向您介紹機器學習的基礎知識,坦率地說,這二十個問題只是滄海一粟。 正如我們所說,機器學習正在進步,因此,隨著時間的推移,新的概念將會出現。 因此,完成 ML 面試的關鍵在於保持不斷學習和提陞技能的衝動。 因此,開始並在互聯網上肆虐、閱讀期刊、加入在線社區、參加 ML 會議和研討會——學習的方式有很多。
要進入一個大的組織,一個知名機構的證書是必不可少的。 查看 IIIT-B 的機器學習和 AI 執行 PG 計劃,並從頂級 ML 和 AI 公司獲得工作幫助。
集成學習的局限性是什麼?
集成方法可以幫助減少方差和開發更穩健的模型。 然而,使用集成技術也有一些缺點,例如缺乏可解釋性和性能。 此外,請記住,集成的功效源於它們聚合多個模型的能力,這些模型專注於問題的不同方面。 但是,它們確實有更長的預測期,因為您可能需要來自數百個模型的預測。 即使他們有更好的預測,準確性的提高也可能不值得。
學習機器學習需要多少時間?
在機器學習方面,用於相同目的的複雜技術可能很容易嚇到人們。 但是,一點一點地理解它並不難。 統計學、高等數學等方面的經驗無疑會幫助您快速掌握所有概念。 但是,由於教育背景和技能因人而異,一個人可能在三週內學習 ML,而另一個人可能需要一年時間。
機器學習如何在我們的日常生活中使用?
Gmail 通過使用機器學習將電子郵件分類為主要電子郵件、促銷電子郵件、社交電子郵件和更新電子郵件,將它們分類為重要電子郵件。 公司正在利用神經網絡根據最新交易頻率、交易金額和商家類型等數據檢測欺詐交易。 抄襲檢測器也利用機器學習。 說到 ML 工程,大約需要六個月的時間才能完成。