
機器學習的 KNN 分類器:您需要知道的一切
已發表: 2021-09-28還記得人工智能(AI)只是科幻小說和電影的概念嗎? 好吧,由於技術進步,人工智能是我們現在每天生活的東西。 從 Alexa 和 Siri 隨時待命,到 OTT 平台“精心挑選”我們想看的電影,人工智能幾乎已成為主流,並且在可預見的未來也將出現。
這一切都歸功於先進的 ML 算法。 今天,我們將討論一種這樣有用的 ML 算法,即 K-NN 分類器。
作為人工智能和計算機科學的一個分支,機器學習使用數據和算法來模仿人類的理解,同時逐漸提高算法的準確性。 機器學習涉及訓練算法以進行預測或分類,並挖掘推動企業和應用程序內戰略決策制定的關鍵見解。
KNN(k-nearest neighbour)算法是一種基本的監督機器學習算法,用於解決回歸和分類問題陳述。 所以,讓我們深入了解更多關於 K-NN 分類器的信息。
目錄
監督與無監督機器學習
監督學習和無監督學習是兩種基本的數據科學方法,在我們深入了解 KNN 的細節之前了解它們的區別是恰當的。
監督學習是一種機器學習方法,它使用標記的數據集來幫助預測結果。 此類數據集旨在“監督”或訓練算法預測結果或準確分類數據。 因此,標記的輸入和輸出使模型能夠隨著時間的推移學習,同時提高其準確性。

監督學習涉及兩類問題——分類和回歸。 在分類問題中,算法將測試數據分配到離散的類別中,例如將貓與狗分開。
一個重要的現實示例是將垃圾郵件分類到與收件箱分開的文件夾中。 另一方面,監督學習的回歸方法訓練算法來理解自變量和因變量之間的關係。 它使用不同的數據點來預測數值,例如預測企業的銷售收入。
相反,無監督學習使用機器學習算法對未標記的數據集進行分析和聚類。 因此,算法無需人工干預(“無監督”)來識別數據中的隱藏模式。
無監督學習模型具有三個主要應用——關聯、聚類和降維。 但是,我們不會詳細介紹,因為它超出了我們的討論範圍。
K-最近鄰 (KNN)
K-Nearest Neighbor或KNN算法是一種基於監督學習模型的機器學習算法。 K-NN 算法的工作原理是假設相似的事物彼此靠近。 因此,K-NN 算法利用新數據點與訓練集中點(可用案例)之間的特徵相似性來預測新數據點的值。 本質上,K-NN 算法根據最新數據點與訓練集中的點的相似程度為其分配一個值。 K-NN 算法在分類和回歸問題中都有應用,但主要用於分類問題。
這是一個理解 K-NN 分類器的例子。

資源
在上圖中,輸入值是與貓和狗都相似的生物。 但是,我們想將它分類為貓或狗。 因此,我們可以使用 K-NN 算法進行此分類。 K-NN 模型將發現新數據集(輸入)與可用貓狗圖像(訓練數據集)之間的相似性。 隨後,模型將根據最相似的特徵將新數據點放入貓或狗類別中。
同樣,A 類(綠點)和 B 類(橙點)具有上述圖形示例。 我們還有一個新的數據點(藍點)將屬於任一類別。 我們可以使用 K-NN 算法解決這個分類問題並識別新的數據點類別。
定義 K-NN 算法的屬性
以下兩個屬性最好地定義了 K-NN 算法:
- 它是一種惰性學習算法,因為 K-NN 算法不是立即從訓練集中學習,而是存儲數據集並在分類時從數據集中訓練。
- K-NN 也是一種非參數算法,這意味著它不對基礎數據做出任何假設。
K-NN 算法的工作原理
現在,讓我們看一下以下步驟,以了解 K-NN 算法的工作原理。
第 1 步:加載訓練和測試數據。
第二步:選擇最近的數據點,即K的值。
第三步:計算K個鄰居的距離(每行訓練數據和測試數據的距離)。 歐幾里得方法最常用於計算距離。
第四步:根據計算出的歐幾里得距離取K個最近鄰。
Step 5:在最近的K個鄰居中,統計每個類別的數據點個數。
第 6 步:將新數據點分配給鄰居數最多的類別。
第七步:結束。 模型現已準備就緒。
加入來自世界頂級大學的在線人工智能課程——碩士、高級管理人員研究生課程和 ML 和 AI 高級證書課程,以加快您的職業生涯。
選擇 K 的值
K 是 K-NN 算法中的一個關鍵參數。 因此,在決定 K 值之前,我們需要記住一些要點。
使用誤差曲線是確定 K 值的常用方法。下圖顯示了測試和訓練數據的不同 K 值的誤差曲線。

資源
在上面的圖形示例中,訓練數據中 K=1 時的訓練誤差為零,因為該點的最近鄰居是該點本身。 然而,即使 K 值較低,測試誤差也很高。這稱為高方差或數據過度擬合。 測試誤差隨著我們增加 K 值而減小,但是在 K 達到一定值之後,我們看到測試誤差再次增加,稱為偏差或欠擬合。 因此,由於方差,測試數據誤差最初很高,隨後降低並趨於穩定,隨著 K 值的進一步增加,由於偏差,測試誤差再次上升。

因此,取測試誤差穩定且較低的K值作為K的最優值。考慮到上述誤差曲線,K=8為最優值。
一個理解 K-NN 算法工作的例子
考慮如下繪製的數據集:

資源
假設在 (60,60) 處有一個新數據點(黑點),我們必須將其分類為紫色或紅色類。 我們將使用 K=3,這意味著新數據點將找到三個最近的數據點,兩個在紅色類中,一個在紫色類中。
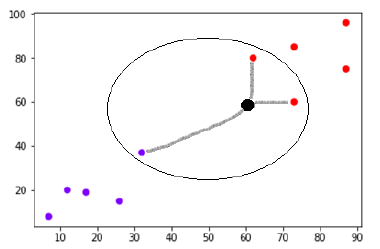
資源
最近鄰是通過計算兩點之間的歐幾里得距離來確定的。 這是一個說明如何完成計算的插圖。

資源
現在,由於新數據點(黑點)的最近鄰居中有兩個(三個中的一個)位於紅色類中,因此新數據點也將被分配給紅色類。
加入來自世界頂級大學的在線機器學習課程——碩士、高級管理人員研究生課程和 ML 和 AI 高級證書課程,以加快您的職業生涯。
K-NN 作為分類器(Python 中的實現)
現在我們已經對 K-NN 算法進行了簡單的解釋,讓我們通過 Python 實現 K-NN 算法。 我們將只關注 K-NN 分類器。
第 1 步:導入必要的 Python 包。

資源
第 2 步:從 UCI 機器學習存儲庫下載 iris 數據集。 它的網址是“https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data”
第 3 步:為數據集分配列名。

資源
第 4 步:將數據集讀取到 Pandas DataFrame。

資源
第 5 步:使用以下腳本行完成數據預處理。

資源
第 6 步:將數據集劃分為測試和訓練拆分。 下面的代碼會將數據集拆分為 40% 的測試數據和 60% 的訓練數據。

資源
第七步:數據縮放如下:

資源
第 8 步:使用 sklearn 的 KNeighborsClassifier 類訓練模型。

資源
第 9 步:使用以下腳本進行預測:

資源
第 10 步:打印結果。

資源
輸出:

資源
接下來是什麼? 註冊 IIT Madras 和 upGrad 的機器學習高級證書課程
假設你渴望成為一名熟練的數據科學家或機器學習專業人士。 在這種情況下,來自 IIT Madras 和 upGrad 的機器學習和雲高級認證課程就是為您準備的!
這個為期 12 個月的在線課程專為希望掌握機器學習、大數據處理、數據管理、數據倉庫、雲和機器學習模型部署方面的概念的在職專業人士而設計。
以下是一些課程亮點,可讓您更好地了解該計劃提供的內容:
- IIT Madras 全球認可的著名認證
- 500 多個小時的學習,20 多個案例研究和項目,25 多個行業指導課程,8 多個編碼任務
- 全面覆蓋 7 種編程語言和工具
- 為期 4 週的行業頂點項目
- 實用的實踐研討會
- 離線對等網絡
立即註冊以了解有關該計劃的更多信息!
結論
隨著時間的推移,大數據不斷增長,人工智能越來越與我們的生活交織在一起。 因此,對數據科學專業人員的需求急劇增加,他們可以利用機器學習模型的力量來收集數據洞察力並改進關鍵業務流程,總的來說,我們的世界。 毫無疑問,人工智能和機器學習領域看起來確實很有前景。 使用upGrad ,您可以放心,您在機器學習和雲計算領域的職業生涯是值得的!
為什麼 K-NN 是一個好的分類器?
與其他機器學習算法相比,K-NN 的主要優勢在於我們可以方便地使用 K-NN 進行多類分類。 因此,如果我們需要將數據分為兩個以上的類別,或者如果數據包含兩個以上的標籤,K-NN 是最好的算法。 此外,它非常適合非線性數據,並且具有較高的準確性。
K-NN算法的局限性是什麼?
K-NN 算法通過計算數據點之間的距離來工作。 因此,很明顯它是一種相對耗時的算法,並且在某些情況下會花費更多時間進行分類。 因此,在使用 K-NN 進行多類分類時,最好不要使用過多的數據點。 其他限制包括高內存存儲和對不相關特徵的敏感性。
K-NN 的實際應用是什麼?
K-NN 在機器學習中有幾個現實生活用例,例如手寫檢測、語音識別、視頻識別和圖像識別。 在銀行業,K-NN 用於根據個人是否具有與違約者相似的特徵來預測個人是否有資格獲得貸款。 在政治上,K-NN 可用於將潛在選民分為不同的類別,例如“將投票給 X 黨”或“將投票給 Y 黨”等。