
介紹基於組件的 API
已發表: 2022-03-10本文於 2019 年 1 月 31 日更新,以回應讀者的反饋。 作者在基於組件的 API 中添加了自定義查詢功能,並描述了它的工作原理。
API 是應用程序從服務器加載數據的通信通道。 在 API 的世界中,REST 一直是更成熟的方法,但最近被 GraphQL 所掩蓋,它提供了優於 REST 的重要優勢。 REST 需要多個 HTTP 請求來獲取一組數據來呈現組件,而 GraphQL 可以在單個請求中查詢和檢索此類數據,並且響應將完全符合要求,而不會像通常發生在休息。
在本文中,我將描述另一種獲取數據的方法,我設計並稱為“PoP”(並在此處開源),它擴展了 GraphQL 引入的在單個請求中為多個實體獲取數據的想法,並將其作為更進一步,即當 REST 為一個資源獲取數據,而 GraphQL 為一個組件中的所有資源獲取數據時,基於組件的 API 可以從一個頁面中的所有組件中獲取所有資源的數據。
當網站本身使用組件構建時,使用基於組件的 API 最有意義,即當網頁迭代地由包裝其他組件的組件組成時,直到在最頂部,我們獲得一個代表頁面的組件。 例如,下圖中顯示的網頁是由組件構建的,這些組件用正方形勾勒出來:
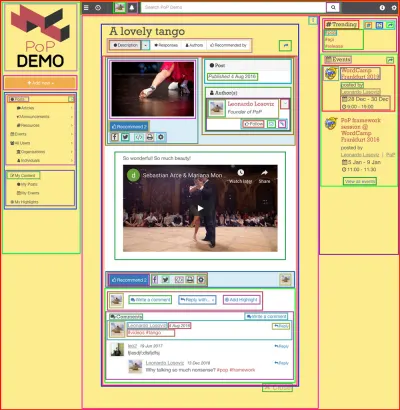
基於組件的 API 能夠通過請求每個組件(以及頁面中的所有組件)中所有資源的數據來向服務器發出單個請求,這是通過將組件之間的關係保持在API 結構本身。
除其他外,這種結構提供以下幾個好處:
- 一個包含很多組件的頁面只會觸發一個請求,而不是很多;
- 跨組件共享的數據只能從數據庫中獲取一次,並且在響應中只能打印一次;
- 它可以大大減少——甚至完全消除——對數據存儲的需求。
我們將在整篇文章中詳細探討這些內容,但首先,讓我們探討一下組件實際上是什麼,以及我們如何基於這些組件構建站點,最後,探討基於組件的 API 是如何工作的。
推薦閱讀: GraphQL 入門:為什麼我們需要一種新的 API
通過組件構建站點
組件只是一組 HTML、JavaScript 和 CSS 代碼組合在一起以創建一個自治實體。 然後,它可以包裝其他組件以創建更複雜的結構,並且本身也被其他組件包裝。 組件有一個用途,可以是非常基本的東西(例如鍊接或按鈕),也可以是非常複雜的東西(例如輪播或拖放圖像上傳器)。 當組件是通用的並且通過注入的屬性(或“道具”)啟用自定義時,組件最有用,因此它們可以服務於廣泛的用例。 在最極端的情況下,網站本身成為一個組件。
術語“組件”通常用於指代功能和設計。 例如,在功能方面,React 或 Vue 等 JavaScript 框架允許創建客戶端組件,這些組件能夠自我渲染(例如,在 API 獲取所需數據之後),並使用 props 為其設置配置值包裝組件,實現代碼可重用性。 在設計方面,Bootstrap 通過其前端組件庫標準化了網站的外觀和感覺,並且團隊創建設計系統來維護他們的網站已成為一種健康的趨勢,這允許不同的團隊成員(設計師和開發人員,但也營銷人員和銷售人員)說統一的語言並表達一致的身份。
組件化網站是使網站變得更易於維護的一種非常明智的方法。 使用 JavaScript 框架(如 React 和 Vue)的站點已經是基於組件的(至少在客戶端)。 使用像 Bootstrap 這樣的組件庫並不一定會使網站基於組件(它可能是一大塊 HTML),但是,它為用戶界面結合了可重用元素的概念。
如果網站是一大塊 HTML,為了將其組件化,我們必須將佈局分解為一系列重複出現的模式,為此我們必鬚根據功能和样式的相似性來識別和分類頁面上的部分,並打破這些將部分細分為盡可能細化的層,試圖讓每一層都專注於一個目標或行動,並嘗試匹配不同部分的公共層。
注意: Brad Frost 的“原子設計”是識別這些常見模式和構建可重用設計系統的絕佳方法。
因此,通過組件構建站點類似於玩樂高。 每個組件要么是一個原子功能,要么是其他組件的組合,要么是兩者的組合。
如下圖,一個基礎組件(頭像)由其他組件迭代組成,直到獲得最頂部的網頁:

基於組件的 API 規範
對於我設計的基於組件的 API,組件被稱為“模塊”,因此從現在起“組件”和“模塊”這兩個術語可以互換使用。
所有模塊相互包裹的關係,從最頂層的模塊一直到最後一層,稱為“組件層次結構”。 這種關係可以通過服務器端的關聯數組(key => property 的數組)來表示,其中每個模塊將其名稱聲明為 key 屬性,並將其內部模塊聲明為屬性modules 。 然後 API 簡單地將此數組編碼為 JSON 對像以供使用:
// Component hierarchy on server-side, eg through PHP: [ "top-module" => [ "modules" => [ "module-level1" => [ "modules" => [ "module-level11" => [ "modules" => [...] ], "module-level12" => [ "modules" => [ "module-level121" => [ "modules" => [...] ] ] ] ] ], "module-level2" => [ "modules" => [ "module-level21" => [ "modules" => [...] ] ] ] ] ] ] // Component hierarchy encoded as JSON: { "top-module": { modules: { "module-level1": { modules: { "module-level11": { ... }, "module-level12": { modules: { "module-level121": { ... } } } } }, "module-level2": { modules: { "module-level21": { ... } } } } } }模塊之間的關係是按照嚴格的自上而下的方式定義的:一個模塊包裝了其他模塊並且知道它們是誰,但它不知道——也不關心——哪些模塊包裝了他。
例如,在上面的 JSON 代碼中,模塊module-level1知道它包裝了模塊module-level11 -level11 和module-level12 ,並且,它也知道它包裝了module-level121 ; 但是模塊module-level11不關心誰在包裝它,因此不知道module-level1 。
有了基於組件的結構,我們現在可以添加每個模塊所需的實際信息,這些信息分為設置(例如配置值和其他屬性)和數據(例如查詢的數據庫對象的 ID 和其他屬性) ,並相應地放置在條目modulesettings和moduledata下:
{ modulesettings: { "top-module": { configuration: {...}, ..., modules: { "module-level1": { configuration: {...}, ..., modules: { "module-level11": { repeat... }, "module-level12": { configuration: {...}, ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { configuration: {...}, ..., modules: { "module-level21": { repeat... } } } } } }, moduledata: { "top-module": { dbobjectids: [...], ..., modules: { "module-level1": { dbobjectids: [...], ..., modules: { "module-level11": { repeat... }, "module-level12": { dbobjectids: [...], ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { dbobjectids: [...], ..., modules: { "module-level21": { repeat... } } } } } } } 接下來,API 將添加數據庫對像數據。 此信息不是放在每個模塊下,而是放在名為databases的共享部分下,以避免在兩個或多個不同模塊從數據庫中獲取相同對象時重複信息。
此外,API 以關係的方式表示數據庫對像數據,以避免當兩個或多個不同的數據庫對象與一個共同的對象相關時(例如兩個具有相同作者的帖子),信息重複。 換句話說,數據庫對像數據是標準化的。
推薦閱讀:為您的靜態站點構建無服務器聯繫表
該結構是一個字典,首先組織在每個對像類型下,然後是對象 ID,我們可以從中獲取對象屬性:
{ databases: { primary: { dbobject_type: { dbobject_id: { property: ..., ... }, ... }, ... } } }這個 JSON 對像已經是來自基於組件的 API 的響應。 它的格式本身就是一個規範:只要服務器以所需格式返回 JSON 響應,客戶端就可以獨立使用 API,而不管它是如何實現的。 因此,API 可以在任何語言上實現(這是 GraphQL 的優點之一:作為規範而不是實際的實現,使它可以在無數種語言中使用。)
注意:在即將發表的文章中,我將描述我在 PHP 中實現基於組件的 API(這是 repo 中可用的 API)。
API 響應示例
例如,下面的 API 響應包含一個包含兩個模塊的組件層次結構, page => post-feed ,其中模塊post-feed獲取博客文章。 請注意以下事項:
- 每個模塊都從屬性
dbobjectids(博客文章的 ID4和9)知道哪些是它查詢的對象 - 每個模塊從屬性
dbkeys中知道其查詢對象的對像類型(每個帖子的數據都在posts下找到,帖子的作者數據,對應於在帖子的屬性author下給出的 ID 的作者,在users下找到) - 因為數據庫對像數據是相關的,所以屬性
author包含作者對象的 ID,而不是直接打印作者數據。
{ moduledata: { "page": { modules: { "post-feed": { dbobjectids: [4, 9] } } } }, modulesettings: { "page": { modules: { "post-feed": { dbkeys: { id: "posts", author: "users" } } } } }, databases: { primary: { posts: { 4: { title: "Hello World!", author: 7 }, 9: { title: "Everything fine?", author: 7 } }, users: { 7: { name: "Leo" } } } } }從基於資源、基於模式和基於組件的 API 中獲取數據的差異
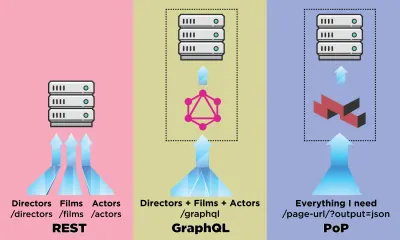
讓我們看看基於組件的 API(如 PoP)在獲取數據時如何與基於資源的 API(如 REST)和基於模式的 API(如 GraphQL)進行比較。
假設 IMDB 有一個頁面,其中包含兩個需要獲取數據的組件:“精選導演”(顯示 George Lucas 的描述和他的電影列表)和“為您推薦的電影”(顯示諸如《星球大戰:第一集》之類的電影) ——幻影威脅和終結者)。 它可能看起來像這樣:
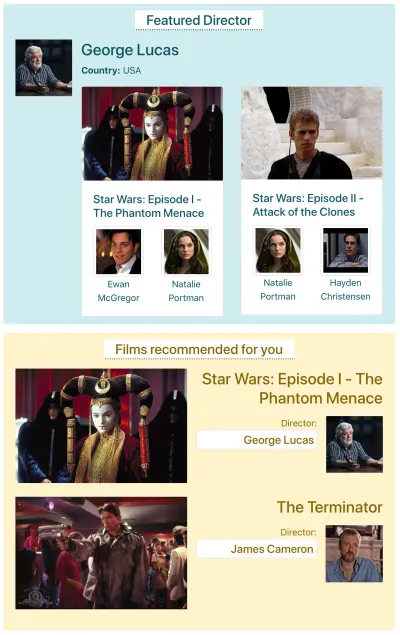
讓我們看看通過每個 API 方法獲取數據需要多少個請求。 對於此示例,“精選導演”組件帶來了一個結果(“喬治·盧卡斯”),它從中檢索了兩部電影( 《星球大戰:第一集——幻影威脅》和《星球大戰:第二集——克隆人的進攻》 ),以及每部電影有兩名演員(第一部電影為“伊万麥格雷戈”和“娜塔莉波特曼”,第二部電影為“娜塔莉波特曼”和“海登克里斯滕森”)。 “為您推薦的電影”組件帶來了兩個結果( 《星球大戰:第一集 - 幻影威脅》和《終結者》 ),然後獲取他們的導演(分別為“喬治盧卡斯”和“詹姆斯卡梅隆”)。
使用 REST 渲染組件featured-director ,我們可能需要以下 7 個請求(這個數量可能會根據每個端點提供的數據量而有所不同,即實現了多少過度獲取):
GET - /featured-director GET - /directors/george-lucas GET - /films/the-phantom-menace GET - /films/attack-of-the-clones GET - /actors/ewan-mcgregor GET - /actors/natalie-portman GET - /actors/hayden-christensen GraphQL 允許通過強類型模式在每個組件的單個請求中獲取所有必需的數據。 通過 GraphQL 為組件featuredDirector獲取數據的查詢如下所示(在我們實現了相應的模式之後):
query { featuredDirector { name country avatar films { title thumbnail actors { name avatar } } } }它會產生以下響應:
{ data: { featuredDirector: { name: "George Lucas", country: "USA", avatar: "...", films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", actors: [ { name: "Ewan McGregor", avatar: "...", }, { name: "Natalie Portman", avatar: "...", } ] }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "...", actors: [ { name: "Natalie Portman", avatar: "...", }, { name: "Hayden Christensen", avatar: "...", } ] } ] } } }查詢“為您推薦的電影”組件會產生以下響應:
{ data: { films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", director: { name: "George Lucas", avatar: "...", } }, { title: "The Terminator", thumbnail: "...", director: { name: "James Cameron", avatar: "...", } } ] } } PoP 只會發出一個請求來獲取頁面中所有組件的所有數據,並對結果進行規範化。 要調用的端點與我們需要獲取數據的 URL 相同,只是添加了一個額外的參數output=json來指示以 JSON 格式而不是將其打印為 HTML:
GET - /url-of-the-page/?output=json 假設模塊結構有一個名為page的頂級模塊,其中包含模塊featured-director和films-recommended-for-you ,並且這些模塊也有子模塊,如下所示:
"page" modules "featured-director" modules "director-films" modules "film-actors" "films-recommended-for-you" modules "film-director"單個返回的 JSON 響應將如下所示:
{ modulesettings: { "page": { modules: { "featured-director": { dbkeys: { id: "people", }, modules: { "director-films": { dbkeys: { films: "films" }, modules: { "film-actors": { dbkeys: { actors: "people" }, } } } } }, "films-recommended-for-you": { dbkeys: { id: "films", }, modules: { "film-director": { dbkeys: { director: "people" }, } } } } } }, moduledata: { "page": { modules: { "featured-director": { dbobjectids: [1] }, "films-recommended-for-you": { dbobjectids: [1, 3] } } } }, databases: { primary: { people { 1: { name: "George Lucas", country: "USA", avatar: "..." films: [1, 2] }, 2: { name: "Ewan McGregor", avatar: "..." }, 3: { name: "Natalie Portman", avatar: "..." }, 4: { name: "Hayden Christensen", avatar: "..." }, 5: { name: "James Cameron", avatar: "..." }, }, films: { 1: { title: "Star Wars: Episode I - The Phantom Menace", actors: [2, 3], director: 1, thumbnail: "..." }, 2: { title: "Star Wars: Episode II - Attack of the Clones", actors: [3, 4], thumbnail: "..." }, 3: { title: "The Terminator", director: 5, thumbnail: "..." }, } } } }讓我們分析一下這三種方法在速度和檢索數據量方面的比較。
速度
通過 REST,必須獲取 7 個請求才能渲染一個組件可能非常慢,主要是在移動和不穩定的數據連接上。 因此,從 REST 跳轉到 GraphQL 對速度的影響很大,因為我們能夠只用一個請求來渲染一個組件。
PoP,因為它可以在一個請求中獲取多個組件的所有數據,所以一次渲染多個組件會更快; 但是,很可能不需要這樣做。 讓組件按順序呈現(就像它們出現在頁面中一樣)已經是一種很好的做法,對於那些出現在折疊下的組件,當然不會急於呈現它們。 因此,基於模式的 API 和基於組件的 API 都已經相當不錯,並且明顯優於基於資源的 API。
數據量
在每個請求中,GraphQL 響應中的數據可能會重複:女演員“娜塔莉·波特曼”在第一個組件的響應中被提取兩次,當考慮兩個組件的聯合輸出時,我們還可以找到共享數據,例如電影星球大戰:第一集——幽靈的威脅。
另一方面,PoP 對數據庫數據進行規範化並只打印一次,但是它帶來了打印模塊結構的開銷。 因此,根據是否具有重複數據的特定請求,基於模式的 API 或基於組件的 API 將具有更小的大小。
總之,GraphQL 等基於模式的 API 和 PoP 等基於組件的 API 在性能方面同樣出色,並且優於 REST 等基於資源的 API。
推薦閱讀:理解和使用 REST API
基於組件的 API 的特殊屬性
如果基於組件的 API 在性能方面不一定比基於模式的 API 更好,您可能想知道,那麼我想通過這篇文章實現什麼目標?
在本節中,我將嘗試讓您相信這樣的 API 具有令人難以置信的潛力,它提供了一些非常理想的特性,使其成為 API 領域的有力競爭者。 我在下面描述並展示了它的每一個獨特的強大功能。
可以從組件層次結構中推斷要從數據庫中檢索的數據
當模塊顯示來自 DB 對象的屬性時,模塊可能不知道或不關心它是什麼對象; 它所關心的只是定義加載對象的哪些屬性是必需的。
例如,考慮下圖。 一個模塊從數據庫中加載一個對象(在這種情況下是一個帖子),然後它的後代模塊將顯示該對象的某些屬性,例如title和content :
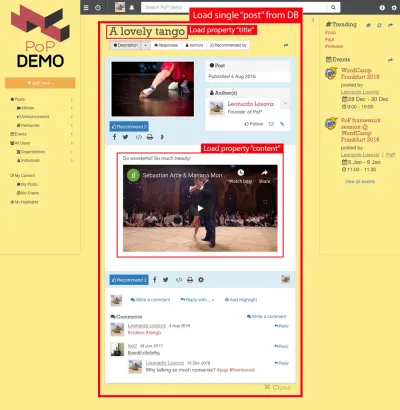
因此,沿著組件層次結構,“數據加載”模塊將負責加載查詢的對象(在這種情況下是加載單個帖子的模塊),其後代模塊將定義需要來自 DB 對象的哪些屬性( title和content ,在這種情況下)。
可以通過遍歷組件層次結構自動獲取 DB 對象所需的所有屬性:從數據加載模塊開始,我們一直迭代其所有後代模塊,直到到達新的數據加載模塊,或者直到樹的末尾; 在每一層,我們獲取所有需要的屬性,然後將所有屬性合併在一起並從數據庫中查詢它們,所有這些都只需要一次。
在下面的結構中,模塊single-post從 DB(ID 為 37 的帖子)中獲取結果,子模塊post-title和post-content定義要為查詢的 DB 對象加載的屬性(分別為title和content ); 子模塊post-layout和fetch-next-post-button不需要任何數據字段。
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "fetch-next-post-button"要執行的查詢是根據組件層次結構及其所需的數據字段自動計算的,其中包含所有模塊及其子模塊所需的所有屬性:
SELECT title, content FROM posts WHERE id = 37 通過直接從模塊中獲取要檢索的屬性,只要組件層次結構發生變化,查詢就會自動更新。 例如,如果我們添加子模塊post-thumbnail ,它需要數據字段thumbnail :
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-thumbnail" => Load property "thumbnail" "fetch-next-post-button"然後查詢會自動更新以獲取附加屬性:
SELECT title, content, thumbnail FROM posts WHERE id = 37因為我們已經建立了要以關係方式檢索的數據庫對像數據,所以我們也可以將這種策略應用到數據庫對象本身之間的關係中。
考慮下圖: 從對像類型post開始,向下移動組件層次結構,我們需要將 DB 對像類型轉換為user和comment ,分別對應於帖子的作者和每個帖子的評論,然後,對於每個評論,它必須再次將對像類型更改為評論作者對應的user 。
從數據庫對象移動到關係對象(可能改變對像類型,如post => author從post到user ,或不改變,如author => follower 從user到user )是我所說的“切換域”。
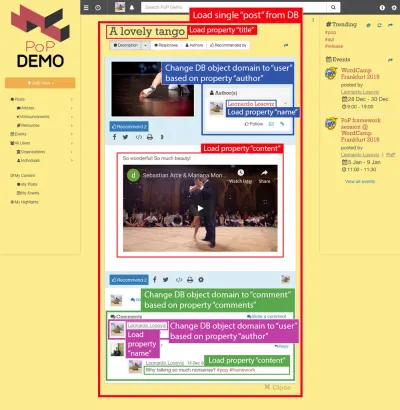
切換到新域後,從組件層次結構的該級別向下,所有必需的屬性都將受制於新域:
-
name從user對像中獲取(代表帖子的作者), - 從
comment像中獲取content(代表每個帖子的評論), -
name從user對像中獲取(代表每個評論的作者)。
遍歷組件層次結構,API 知道它何時切換到新域,並適當地更新查詢以獲取關係對象。
例如,如果我們需要顯示來自帖子作者的數據,堆疊子模塊post-author會將該級別的域從post更改為相應的user ,並且從該級別向下加載到傳遞給模塊的上下文中的 DB 對像是用戶。 然後, post-author下的子模塊user-name和user-avatar會加載user對像下的屬性name和avatar :
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-author" => Switch domain from "post" to "user", based on property "author" modules "user-layout" modules "user-name" => Load property "name" "user-avatar" => Load property "avatar" "fetch-next-post-button"導致以下查詢:
SELECT p.title, p.content, p.author, u.name, u.avatar FROM posts p INNER JOIN users u WHERE p.id = 37 AND p.author = u.id總之,通過適當地配置每個模塊,無需編寫查詢來獲取基於組件的 API 的數據。 查詢是從組件層次結構本身自動生成的,獲取數據加載模塊必須加載的對象、每個後代模塊定義的每個加載對像要檢索的字段以及每個後代模塊定義的域切換。
添加、刪除、替換或更改任何模塊都會自動更新查詢。 執行查詢後,檢索到的數據將正是所需要的——不多也不少。
觀察數據併計算附加屬性
從組件層次結構的數據加載模塊開始,任何模塊都可以觀察返回的結果並根據它們計算額外的數據項或feedback值,這些數據項放置在入口moduledata下。
例如,模塊fetch-next-post-button可以添加一個屬性,指示是否有更多結果要獲取(基於此反饋值,如果沒有更多結果,按鈕將被禁用或隱藏):
{ moduledata: { "page": { modules: { "single-post": { modules: { "fetch-next-post-button": { feedback: { hasMoreResults: true } } } } } } } }所需數據的隱含知識降低了複雜性並使“端點”的概念變得過時
如上所示,基於組件的 API 可以準確地獲取所需的數據,因為它具有服務器上所有組件的模型以及每個組件需要哪些數據字段。 然後,它可以隱含所需數據字段的知識。
優點是定義組件需要哪些數據可以只在服務器端更新,而無需重新部署 JavaScript 文件,並且客戶端可以變得愚蠢,只要求服務器提供它需要的任何數據,從而降低客戶端應用程序的複雜性。
此外,調用 API 來檢索特定 URL 的所有組件的數據可以簡單地通過查詢該 URL 並添加額外參數output=json來指示返回 API 數據而不是打印頁面來執行。 因此,URL 成為它自己的端點,或者以不同的方式考慮,“端點”的概念變得過時了。
檢索數據子集:可以為特定模塊獲取數據,在組件層次結構的任何級別都可以找到
如果我們不需要獲取頁面中所有模塊的數據,而只需獲取從組件層次結構的任何級別開始的特定模塊的數據,會發生什麼? 例如,如果一個模塊實現了無限滾動,當向下滾動時,我們必須只為該模塊獲取新數據,而不是為頁面上的其他模塊獲取新數據。
這可以通過過濾將包含在響應中的組件層次結構的分支來完成,以包含僅從指定模塊開始的屬性並忽略此級別之上的所有內容。 在我的實現中(我將在下一篇文章中描述),通過將參數modulefilter=modulepaths添加到 URL 來啟用過濾,並且通過modulepaths[]參數指示選定的模塊(或多個模塊),其中“模塊路徑” 是從最頂層模塊開始到特定模塊的模塊列表(例如module1 => module2 => module3具有模塊路徑 [ module1 , module2 , module3 ],並作為 URL 參數作為module1.module2.module3 ) .

例如,在每個模塊下方的組件層次結構中,都有一個條目dbobjectids :
"module1" dbobjectids: [...] modules "module2" dbobjectids: [...] modules "module3" dbobjectids: [...] "module4" dbobjectids: [...] "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] 然後請求網頁 URL 添加參數modulefilter=modulepaths和modulepaths[]=module1.module2.module5將產生以下響應:
"module1" modules "module2" modules "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] 本質上,API 從module1 => module2 => module5開始加載數據。 這就是為什麼module6下的module5也帶來了它的數據,而module3和module4沒有。
此外,我們可以創建自定義模塊過濾器以包含一組預先安排的模塊。 例如,使用modulefilter=userstate調用頁面可以僅打印那些需要用戶狀態才能在客戶端呈現它們的模塊,例如模塊module3和module6 :
"module1" modules "module2" modules "module3" dbobjectids: [...] "module5" modules "module6" dbobjectids: [...] 其中啟動模塊的信息位於requestmeta部分下,在條目filteredmodules模塊下,作為模塊路徑數組:
requestmeta: { filteredmodules: [ ["module1", "module2", "module3"], ["module1", "module2", "module5", "module6"] ] }此功能允許實現簡單的單頁應用程序,其中站點的框架在初始請求時加載:
"page" modules "navigation-top" dbobjectids: [...] "navigation-side" dbobjectids: [...] "page-content" dbobjectids: [...] 但是,從它們開始,我們可以將參數modulefilter=page附加到所有請求的 URL,過濾掉框架並只帶來頁面內容:
"page" modules "navigation-top" "navigation-side" "page-content" dbobjectids: [...] 與上面描述的模塊過濾器用戶userstate和page類似,我們可以實現任何自定義模塊過濾器並創建豐富的用戶體驗。
模塊是它自己的 API
如上所示,我們可以過濾 API 響應以從任何模塊開始檢索數據。 因此,每個模塊都可以通過將其模塊路徑添加到包含它的網頁 URL 來從客戶端到服務器與其自身進行交互。
我希望你能原諒我的過度興奮,但我真的不能足夠強調這個功能是多麼美妙。 在創建組件時,我們不需要創建一個 API 來與它一起檢索數據(REST、GraphQL 或其他任何東西),因為該組件已經能夠在服務器中與自己對話並加載它自己的數據——它是完全自主和自服務的。
每個數據加載模塊都在datasetmodulemeta部分下的條目dataloadsource下導出 URL 以與其交互:
{ datasetmodulemeta: { "module1": { modules: { "module2": { modules: { "module5": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5" }, modules: { "module6": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5.module6" } } } } } } } } } }獲取數據是跨模塊和 DRY 解耦的
為了說明在基於組件的 API 中獲取數據是高度解耦和 DRY 的(我們自己不會重複),我首先需要展示在GraphQL等基於模式的 API 中如何減少解耦和不干燥。
在 GraphQL 中,獲取數據的查詢必須指明組件的數據字段,其中可能包括子組件,這些也可能包括子組件,等等。 然後,最頂層的組件也需要知道它的每個子組件都需要哪些數據,以獲取該數據。
例如,渲染<FeaturedDirector>組件可能需要以下子組件:
Render <FeaturedDirector>: <div> Country: {country} {foreach films as film} <Film film={film} /> {/foreach} </div> Render <Film>: <div> Title: {title} Pic: {thumbnail} {foreach actors as actor} <Actor actor={actor} /> {/foreach} </div> Render <Actor>: <div> Name: {name} Photo: {avatar} </div> 在這種情況下,GraphQL 查詢是在<FeaturedDirector>級別實現的。 然後,如果子組件<Film>被更新,通過屬性filmTitle而不是title請求標題,來自<FeaturedDirector>組件的查詢也需要更新,以反映這個新信息(GraphQL 有一個版本控制機制可以處理有這個問題,但遲早我們還是應該更新信息)。 這會產生維護複雜性,當內部組件經常更改或由第三方開發人員生產時,可能難以處理。 因此,組件之間沒有徹底解耦。
類似地,我們可能希望直接渲染某些特定電影的<Film>組件,然後我們還必須在此級別實現 GraphQL 查詢,以獲取電影及其演員的數據,這會添加冗餘代碼:相同的查詢將存在於組件結構的不同級別。 所以GraphQL 不是 DRY 。
因為基於組件的 API 已經知道它的組件是如何在自己的結構中相互包裝的,所以這些問題就完全避免了。 一方面,客戶端能夠簡單地請求所需的數據,無論這些數據是什麼; if a subcomponent data field changes, the overall model already knows and adapts immediately, without having to modify the query for the parent component in the client. Therefore, the modules are highly decoupled from each other.
For another, we can fetch data starting from any module path, and it will always return the exact required data starting from that level; there are no duplicated queries whatsoever, or even queries to start with. Hence, a component-based API is fully DRY . (This is another feature that really excites me and makes me get wet.)
(Yes, pun fully intended. Sorry about that.)
Retrieving Configuration Values In Addition To Database Data
Let's revisit the example of the featured-director component for the IMDB site described above, which was created — you guessed it! — with Bootstrap. Instead of hardcoding the Bootstrap classnames or other properties such as the title's HTML tag or the avatar max width inside of JavaScript files (whether they are fixed inside the component, or set through props by parent components), each module can set these as configuration values through the API, so that then these can be directly updated on the server and without the need to redeploy JavaScript files. Similarly, we can pass strings (such as the title Featured director ) which can be already translated/internationalized on the server-side, avoiding the need to deploy locale configuration files to the front-end.
Similar to fetching data, by traversing the component hierarchy, the API is able to deliver the required configuration values for each module and nothing more or less.
The configuration values for the featured-director component might look like this:
{ modulesettings: { "page": { modules: { "featured-director": { configuration: { class: "alert alert-info", title: "Featured director", titletag: "h3" }, modules: { "director-films": { configuration: { classes: { wrapper: "media", avatar: "mr-3", body: "media-body", films: "row", film: "col-sm-6" }, avatarmaxsize: "100px" }, modules: { "film-actors": { configuration: { classes: { wrapper: "card", image: "card-img-top", body: "card-body", title: "card-title", avatar: "img-thumbnail" } } } } } } } } } } } Please notice how — because the configuration properties for different modules are nested under each module's level — these will never collide with each other if having the same name (eg property classes from one module will not override property classes from another module), avoiding having to add namespaces for modules.
Higher Degree Of Modularity Achieved In The Application
According to Wikipedia, modularity means:
The degree to which a system's components may be separated and recombined, often with the benefit of flexibility and variety in use. The concept of modularity is used primarily to reduce complexity by breaking a system into varying degrees of interdependence and independence across and 'hide the complexity of each part behind an abstraction and interface'.
Being able to update a component just from the server-side, without the need to redeploy JavaScript files, has the consequence of better reusability and maintenance of components. I will demonstrate this by re-imagining how this example coded for React would fare in a component-based API.
Let's say that we have a <ShareOnSocialMedia> component, currently with two items: <FacebookShare> and <TwitterShare> , like this:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> </ul> But then Instagram got kind of cool, so we need to add an item <InstagramShare> to our <ShareOnSocialMedia> component, too:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> <li>Share on Instagram: <InstagramShare url={window.location.href} /></li> </ul> In the React implementation, as it can be seen in the linked code, adding a new component <InstagramShare> under component <ShareOnSocialMedia> forces to redeploy the JavaScript file for the latter one, so then these two modules are not as decoupled as they could be.
但是,在基於組件的 API 中,我們可以很容易地使用 API 中已經描述的模塊之間的關係將模塊耦合在一起。 雖然最初我們會有這樣的回應:
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} } } } } }添加 Instagram 後,我們將獲得升級後的響應:
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} }, "instagram-share": { configuration: {...} } } } } } 只需迭代modulesettings["share-on-social-media"].modules下的所有值,即可升級組件<ShareOnSocialMedia>以顯示<InstagramShare>組件,而無需重新部署任何 JavaScript 文件。 因此,API 支持添加和刪除模塊,而不會影響其他模塊的代碼,從而獲得更高程度的模塊化。
本機客戶端緩存/數據存儲
檢索到的數據庫數據在字典結構中進行規範化和標準化,以便從dbobjectids上的值開始,只需按照條目dbkeys指示的路徑即可訪問databases下的任何數據,無論其結構方式如何. 因此,組織數據的邏輯已經是 API 本身的原生邏輯。
我們可以通過多種方式從這種情況中受益。 例如,可以將每個請求的返回數據添加到客戶端緩存中,該緩存包含用戶在整個會話期間請求的所有數據。 因此,可以避免向應用程序添加諸如 Redux 之類的外部數據存儲(我的意思是關於數據的處理,而不涉及其他功能,例如撤消/重做、協作環境或時間旅行調試)。
此外,基於組件的結構促進了緩存:組件層次結構不取決於 URL,而是取決於該 URL 中需要哪些組件。 這樣, /events/1/和/events/2/下的兩個事件將共享相同的組件層次結構,並且可以在它們之間重用需要哪些模塊的信息。 因此,所有屬性(除了數據庫數據)都可以在獲取第一個事件後緩存在客戶端上並從那時起重新使用,因此必須僅獲取每個後續事件的數據庫數據,而不是其他任何內容。
可擴展性和再利用
API 的databases部分可以擴展,從而能夠將其信息分類為自定義的子部分。 默認情況下,所有數據庫對像數據都放在條目primary下,但是,我們也可以創建自定義條目來放置特定的數據庫對象屬性。
例如,如果前面描述的組件“為您推薦的電影”在film數據庫對像上的屬性friendsWhoWatchedFilm下顯示登錄用戶觀看過這部電影的朋友列表,因為該值會根據登錄而改變用戶然後我們將這個屬性保存在用戶userstate條目下,所以當用戶註銷時,我們只從客戶端緩存數據庫中刪除這個分支,但所有primary數據仍然保留:
{ databases: { userstate: { films: { 5: { friendsWhoWatchedFilm: [22, 45] }, } }, primary: { films: { 5: { title: "The Terminator" }, } "people": { 22: { name: "Peter", }, 45: { name: "John", }, }, } } }此外,在一定程度上,API 響應的結構可以重新調整用途。 特別是,數據庫結果可以打印在不同的數據結構中,例如數組而不是默認字典。
例如,如果對像類型只有一個(例如films ),它可以被格式化為一個數組,直接輸入到 typeahead 組件中:
[ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "..." }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "..." }, { title: "The Terminator", thumbnail: "..." }, ]支持面向方面的編程
除了獲取數據,基於組件的 API 還可以發布數據,例如創建帖子或添加評論,並執行任何類型的操作,例如登錄或註銷用戶、發送電子郵件、日誌記錄、分析、等等。 沒有任何限制:底層 CMS 提供的任何功能都可以通過模塊在任何級別調用。
沿著組件層次結構,我們可以添加任意數量的模塊,每個模塊都可以執行自己的操作。 因此,並非所有操作都必須與請求的預期操作相關,例如在 REST 中執行 POST、PUT 或 DELETE 操作或在 GraphQL 中發送突變時,但可以添加以提供額外功能,例如發送電子郵件當用戶創建新帖子時向管理員發送。
因此,通過依賴注入或配置文件定義組件層次結構,可以說 API 支持面向切面的編程,“一種旨在通過允許分離橫切關注點來增加模塊化的編程範式”。
推薦閱讀:使用功能策略保護您的網站
增強的安全性
模塊的名稱在輸出時不一定是固定的,但可以縮短、修改、隨機更改或(簡而言之)以任何預期的方式可變。 雖然最初考慮縮短 API 輸出(以便模塊名稱carousel-featured-posts或drag-and-drop-user-images可以縮短為基本 64 表示法,例如a1 , a2等,用於生產環境),此功能允許出於安全原因頻繁更改 API 響應中的模塊名稱。
例如,輸入名稱默認命名為其對應的模塊; 然後,名為username和password的模塊在客戶端中分別呈現為<input type="text" name="{input_name}">和<input type="password" name="{input_name}"> ,可以為其輸入名稱設置不同的隨機值(例如今天的zwH8DSeG和QBG7m6EF ,以及明天的c3oMLBjo和c46oVgN6 ),從而使垃圾郵件發送者和機器人更難瞄準該站點。
通過替代模型實現多功能性
模塊的嵌套允許分支到另一個模塊以添加對特定介質或技術的兼容性,或者更改一些樣式或功能,然後返回到原始分支。
例如,假設網頁具有以下結構:
"module1" modules "module2" modules "module3" "module4" modules "module5" modules "module6" 在這種情況下,我們想讓網站也適用於 AMP,但是模塊module2 、 module4和module5不兼容 AMP。 我們可以將這些模塊分支成類似的 AMP 兼容模塊module2AMP 、 module4AMP和module5AMP ,之後我們繼續加載原始組件層次結構,因此只有這三個模塊被替換(僅此而已):
"module1" modules "module2AMP" modules "module3" "module4AMP" modules "module5AMP" modules "module6"這使得從單個代碼庫生成不同的輸出變得相當容易,只根據需要在這里和那裡添加分支,並且始終限定和限製到單個模塊。
演示時間
如本文所述,實現 API 的代碼可在此開源存儲庫中找到。
出於演示目的,我在https://nextapi.getpop.org下部署了 PoP API。 該網站在 WordPress 上運行,因此 URL 永久鏈接是 WordPress 的典型鏈接。 如前所述,通過向它們添加參數output=json ,這些 URL 成為它們自己的 API 端點。
該站點由來自 PoP Demo 網站的相同數據庫支持,因此可以通過查詢其他網站中的相同 URL 來完成組件層次結構和檢索數據的可視化(例如訪問https://demo.getpop.org/u/leo/解釋了來自https://nextapi.getpop.org/u/leo/?output=json的數據)。
下面的鏈接演示了前面描述的案例的 API:
- 主頁、單個帖子、作者、帖子列表和用戶列表。
- 一個事件,從特定模塊過濾。
- 一個標籤,過濾模塊,需要用戶狀態和過濾才能從單頁應用程序中只帶來一個頁面。
- 一組位置,用於輸入預輸入。
- “我們是誰”頁面的替代模型:正常、可打印、可嵌入。
- 更改模塊名稱:原始與損壞。
- 過濾信息:只有模塊設置、模塊數據加數據庫數據。
結論
一個好的 API 是創建可靠、易於維護和強大的應用程序的墊腳石。 在本文中,我描述了支持基於組件的 API 的概念,我相信它是一個非常好的 API,我希望我也能說服你。
到目前為止,API 的設計和實現已經經歷了多次迭代,耗時五年多——而且還沒有完全準備好。 但是,它處於相當不錯的狀態,尚未準備好投入生產,而是作為穩定的 alpha 版本。 這些天來,我仍在努力; 致力於定義開放規範、實現附加層(例如渲染)和編寫文檔。
在即將發表的文章中,我將描述我的 API 實現是如何工作的。 在那之前,如果你對此有任何想法——無論是積極的還是消極的——我很樂意在下面閱讀你的評論。
更新(1 月 31 日):自定義查詢功能
Alain Schlesser 評論說,無法從客戶端自定義查詢的 API 毫無價值,將我們帶回 SOAP,因此它無法與 REST 或 GraphQL 競爭。 經過幾天的思考後,我不得不承認他是對的。 然而,我並沒有將基於組件的 API 視為一種善意但尚未完全實現的努力,而是做了一些更好的事情:我必須為它實現自定義查詢功能。 它就像一個魅力!
在以下鏈接中,資源或資源集合的數據通常通過 REST 進行獲取。 但是,通過參數fields ,我們還可以指定要為每個資源檢索哪些特定數據,從而避免數據過度或不足:
- 單個帖子和帖子集合添加參數
fields=title,content,datetime時間 - 一個用戶和一組用戶添加參數
fields=name,username,description
上面的鏈接演示了僅為查詢的資源獲取數據。 他們的關係呢? 例如,假設我們要檢索包含字段"title"和"content"的帖子列表,包含字段"content"和"date"的每個帖子的評論,以及包含字段"name"和“的每個評論的作者"url" 。 為了在 GraphQL 中實現這一點,我們將實現以下查詢:
query { post { title content comments { content date author { name url } } } } 對於基於組件的 API 的實現,我將查詢翻譯成相應的“點語法”表達式,然後可以通過參數fields提供。 查詢“post”資源,該值為:
fields=title,content,comments.content,comments.date,comments.author.name,comments.author.url 或者它可以被簡化,使用| 對應用於同一資源的所有字段進行分組:
fields=title|content,comments.content|date,comments.author.name|url在單個帖子上執行此查詢時,我們會準確獲取所有相關資源所需的數據:
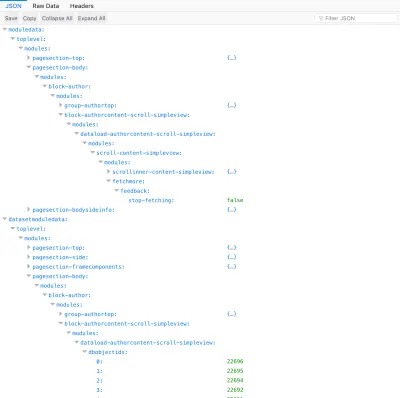
{ "datasetmodulesettings": { "dataload-dataquery-singlepost-fields": { "dbkeys": { "id": "posts", "comments": "comments", "comments.author": "users" } } }, "datasetmoduledata": { "dataload-dataquery-singlepost-fields": { "dbobjectids": [ 23691 ] } }, "databases": { "posts": { "23691": { "id": 23691, "title": "A lovely tango", "content": "<div class=\"responsiveembed-container\"><iframe loading="lazy" width=\"480\" height=\"270\" src=\"https:\\/\\/www.youtube.com\\/embed\\/sxm3Xyutc1s?feature=oembed\" frameborder=\"0\" allowfullscreen><\\/iframe><\\/div>\n", "comments": [ "25094", "25164" ] } }, "comments": { "25094": { "id": "25094", "content": "<p><a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/videos\\/\">#videos<\\/a>\\u00a0<a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/tango\\/\">#tango<\\/a><\\/p>\n", "date": "4 Aug 2016", "author": "851" }, "25164": { "id": "25164", "content": "<p>fjlasdjf;dlsfjdfsj<\\/p>\n", "date": "19 Jun 2017", "author": "1924" } }, "users": { "851": { "id": 851, "name": "Leonardo Losoviz", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo\\/" }, "1924": { "id": 1924, "name": "leo2", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo2\\/" } } } } 因此,我們可以以 REST 方式查詢資源,並以 GraphQL 方式指定基於模式的查詢,我們將準確獲得所需的內容,而不會過度或不足獲取數據,並對數據庫中的數據進行規範化,以免數據重複。 有利的是,查詢可以包括任意數量的關係,嵌套在深處,並且這些關係通過線性複雜度時間來解決:最壞的情況是 O(n+m),其中 n 是切換域的節點數(在這種情況下為 2: comments和comments.author ),m 是檢索結果的數量(在本例中為 5:1 個帖子 + 2 個評論 + 2 個用戶),平均情況為 O(n)。 (這比 GraphQL 更有效,GraphQL 的多項式複雜度時間為 O(n^c),並且隨著級別深度的增加,執行時間也會增加)。
最後,該 API 還可以在查詢數據時應用修飾符,例如過濾檢索到的資源,例如可以通過 GraphQL 完成。 為了實現這一點,API 簡單地位於應用程序之上,並且可以方便地使用其功能,因此無需重新發明輪子。 例如,添加參數filter=posts&searchfor=internet將從帖子集合中過濾所有包含"internet"的帖子。
這個新特性的實現將在下一篇文章中描述。