
使用 React 和 Tesseract.js (OCR) 進行圖像到文本的轉換
已發表: 2022-03-10數據是每個軟件應用程序的支柱,因為應用程序的主要目的是解決人類問題。 為了解決人類的問題,有必要掌握一些關於它們的信息。
這些信息被表示為數據,尤其是通過計算。 在網絡上,數據主要以文本、圖像、視頻等形式收集。 有時,圖像包含旨在處理以實現特定目的的基本文本。 這些圖像大多是手動處理的,因為沒有辦法以編程方式處理它們。
無法從圖像中提取文本是我在上一家公司親身經歷的數據處理限制。 我們需要處理掃描的禮品卡,而且我們必須手動完成,因為我們無法從圖像中提取文本。
公司內部有一個叫做“運營”的部門,負責手動確認禮品卡和記入用戶賬戶。 雖然我們有一個網站,用戶可以通過它與我們聯繫,但禮品卡的處理是在幕後手動進行的。
當時,我們的網站主要使用 PHP(Laravel)作為後端,JavaScript(jQuery 和 Vue)作為前端。 只要管理層認為這個問題很重要,我們的技術堆棧就足以與 Tesseract.js 一起工作。
我願意解決問題,但從業務或管理層的角度來看,沒有必要解決問題。 離開公司後,我決定做一些研究,試圖找到可能的解決方案。 最終,我發現了 OCR。
什麼是 OCR?
OCR 代表“光學字符識別”或“光學字符閱讀器”。 它用於從圖像中提取文本。
OCR 的演變可以追溯到幾項發明,但 Optophone、“Gismo”、CCD 平板掃描儀、Newton MesssagePad 和 Tesseract 是將字符識別提升到另一個實用水平的主要發明。
那麼,為什麼要使用 OCR? 嗯,光學字符識別解決了很多問題,其中一個觸發了我寫這篇文章。 我意識到從圖像中提取文本的能力確保了很多可能性,例如:
- 規定
由於某些原因,每個組織都需要規範用戶的活動。 該法規可用於保護用戶的權利並保護他們免受威脅或詐騙。
從圖像中提取文本使組織能夠處理圖像上的文本信息以進行監管,尤其是當圖像由某些用戶提供時。
例如,可以通過 OCR 實現類似於 Facebook 的對用於廣告的圖像上的文本數量的調節。 此外,OCR 還可以在 Twitter 上隱藏敏感內容。 - 可搜索性
搜索是最常見的活動之一,尤其是在互聯網上。 搜索算法主要基於操作文本。 通過光學字符識別,可以識別圖像上的字符,並使用它們為用戶提供相關的圖像結果。 簡而言之,現在可以藉助 OCR 搜索圖像和視頻。 - 可訪問性
圖像上的文本一直是可訪問性的挑戰,並且圖像上的文本很少是經驗法則。 使用 OCR,屏幕閱讀器可以訪問圖像上的文本,從而為其用戶提供一些必要的體驗。 - 數據處理自動化 數據處理主要是自動化的規模化。 圖像上的文本是數據處理的一個限制,因為除了手動之外無法處理文本。 光學字符識別 (OCR) 使得以編程方式提取圖像上的文本成為可能,從而確保數據處理自動化,尤其是在處理圖像上的文本時。
- 印刷材料的數字化
一切都在數字化,還有很多文件需要數字化。 支票、證書和其他物理文件現在可以使用光學字符識別進行數字化。
找出上面所有的用途加深了我的興趣,所以我決定更進一步,問一個問題:
“我如何在 Web 上使用 OCR,尤其是在 React 應用程序中?”
這個問題讓我想到了 Tesseract.js。
什麼是 Tesseract.js?
Tesseract.js 是一個 JavaScript 庫,可將原始 Tesseract 從 C 編譯為 JavaScript WebAssembly,從而使 OCR 在瀏覽器中可訪問。 Tesseract.js 引擎最初是用 ASM.js 編寫的,後來被移植到 WebAssembly,但在某些不支持 WebAssembly 的情況下,ASM.js 仍然充當備份。
正如 Tesseract.js 網站上所說,它支持 100 多種語言,自動文本定位和腳本檢測,用於閱讀段落、單詞和字符邊界框的簡單界面。
Tesseract 是用於各種操作系統的光學字符識別引擎。 它是免費軟件,在 Apache 許可證下發布。 Hewlett-Packard 在 1980 年代開發了 Tesseract 作為專有軟件。 它於 2005 年作為開源版本發布,自 2006 年以來其開發一直由 Google 贊助。
Tesseract 的最新版本第 4 版於 2018 年 10 月發布,它包含一個新的 OCR 引擎,該引擎使用基於長短期記憶 (LSTM) 的神經網絡系統,旨在產生更準確的結果。
了解 Tesseract API
要真正了解 Tesseract 的工作原理,我們需要分解它的一些 API 及其組件。 根據 Tesseract.js 文檔,有兩種方法可以使用它。 以下是第一種方法及其分解:
Tesseract.recognize( image,language, { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { console.log(result); }) } recognize方法將圖像作為第一個參數,語言(可以是多個)作為第二個參數, { logger: m => console.log(me) }作為最後一個參數。 Tesseract 支持的圖像格式是 jpg、png、bmp 和 pbm,它們只能作為元素(img、視頻或畫布)、文件對象( <input> )、blob 對象、圖像的路徑或 URL 和 base64 編碼圖像提供. (閱讀此處了解有關 Tesseract 可以處理的所有圖像格式的更多信息。)
語言以字符串形式提供,例如eng 。 +符號可用於連接多種語言,如eng+chi_tra 。 語言參數用於確定要在圖像處理中使用的訓練語言數據。
注意:您會在此處找到所有可用的語言及其代碼。
{ logger: m => console.log(m) }對於獲取有關正在處理的圖像的進度信息非常有用。 logger 屬性採用一個函數,該函數將在 Tesseract 處理圖像時被多次調用。 logger 函數的參數應該是一個具有workerId 、 jobId 、 status和progress作為其屬性的對象:
{ workerId: 'worker-200030', jobId: 'job-734747', status: 'recognizing text', progress: '0.9' } progress是一個介於 0 和 1 之間的數字,以百分比表示圖像識別過程的進度。
Tesseract 自動生成對像作為 logger 函數的參數,但也可以手動提供。 隨著識別過程的發生,每次調用函數時都會更新logger對象屬性。 因此,它可用於顯示轉換進度條、更改應用程序的某些部分或用於實現任何所需的結果。
上面代碼中的result是圖像識別過程的結果。 result的每個屬性都有屬性 bbox 作為其邊界框的 x/y 坐標。
以下是result對象的屬性、含義或用途:
{ text: "I am codingnninja from Nigeria..." hocr: "<div class='ocr_page' id= ..." tsv: "1 1 0 0 0 0 0 0 1486 ..." box: null unlv: null osd: null confidence: 90 blocks: [{...}] psm: "SINGLE_BLOCK" oem: "DEFAULT" version: "4.0.0-825-g887c" paragraphs: [{...}] lines: (5) [{...}, ...] words: (47) [{...}, {...}, ...] symbols: (240) [{...}, {...}, ...] }-
text:所有已識別的文本作為字符串。 -
lines:每個已識別的文本行的數組。 -
words: 每個已識別單詞的數組。 -
symbols:每個已識別字符的數組。 -
paragraphs:每個已識別段落的數組。 我們將在本文後面討論“信心”。
Tesseract 也可以更強制地使用,如:
import { createWorker } from 'tesseract.js'; const worker = createWorker({ logger: m => console.log(m) }); (async () => { await worker.load(); await worker.loadLanguage('eng'); await worker.initialize('eng'); const { data: { text } } = await worker.recognize('https://tesseract.projectnaptha.com/img/eng_bw.png'); console.log(text); await worker.terminate(); })();這種方法與第一種方法有關,但實現方式不同。
createWorker(options)創建一個 Web 工作者或節點子進程,該進程創建一個 Tesseract 工作者。 工作人員幫助設置 Tesseract OCR 引擎。 load()方法加載 Tesseract 核心腳本, loadLanguage()加載作為字符串提供給它的任何語言, initialize()確保 Tesseract 完全準備好使用,然後使用識別方法處理提供的圖像。 terminate() 方法停止工作程序並清理所有內容。
注意:請查看 Tesseract API 文檔以獲取更多信息。
現在,我們必須構建一些東西來真正了解 Tesseract.js 的有效性。
我們要建造什麼?
我們將構建一個禮品卡 PIN 提取器,因為從禮品卡中提取 PIN 是導致這次寫作冒險的問題。
我們將構建一個從掃描的禮品卡中提取 PIN 的簡單應用程序。 當我著手構建一個簡單的禮品卡別針提取器時,我將帶您了解我在此過程中面臨的一些挑戰、我提供的解決方案以及根據我的經驗得出的結論。
- 轉到源代碼 →
下面是我們將用於測試的圖像,因為它具有一些在現實世界中可能存在的真實屬性。

我們將從卡中提取AQUX-QWMB6L-R6JAU 。 那麼,讓我們開始吧。
React 和 Tesseract 的安裝
在安裝 React 和 Tesseract.js 之前有一個問題需要解決,問題是,為什麼將 React 與 Tesseract 一起使用? 實際上,我們可以將 Tesseract 與 Vanilla JavaScript、任何 JavaScript 庫或框架(如 React、Vue 和 Angular)一起使用。
在這種情況下使用 React 是個人喜好。 最初,我想使用 Vue,但我決定使用 React,因為我對 React 比對 Vue 更熟悉。
現在,讓我們繼續安裝。
要使用 create-react-app 安裝 React,您必須運行以下代碼:
npx create-react-app image-to-text cd image-to-text yarn add Tesseract.js要么
npm install tesseract.js我決定使用 yarn 來安裝 Tesseract.js,因為我無法使用 npm 安裝 Tesseract,但 yarn 可以輕鬆完成工作。 您可以使用 npm,但根據我的經驗,我建議使用 yarn 安裝 Tesseract。
現在,讓我們通過運行以下代碼來啟動我們的開發服務器:
yarn start要么
npm start運行 yarn start 或 npm start 後,您的默認瀏覽器應該會打開一個如下所示的網頁:

如果頁面未自動啟動,您也可以在瀏覽器中導航到localhost:3000 。
安裝 React 和 Tesseract.js 之後,下一步是什麼?
設置上傳表單
在這種情況下,我們將調整我們剛剛在瀏覽器中查看的主頁(App.js)以包含我們需要的表單:
import { useState, useRef } from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={imagePath} className="App-logo" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> </main> </div> ); } export default App 上面代碼中需要我們注意的部分是函數handleChange 。
const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } 在該函數中, URL.createObjectURL通過event.target.files[0]獲取選定的文件,並創建一個可以與 HTML 標籤(如 img、audio 和 video)一起使用的參考 URL。 我們使用setImagePath將 URL 添加到狀態。 現在,現在可以使用imagePath訪問 URL。
<img src={imagePath} className="App-logo" alt="image"/> 我們將圖像的 src 屬性設置為{imagePath}以便在處理之前在瀏覽器中預覽它。
將所選圖像轉換為文本
由於我們已經抓取了所選圖像的路徑,我們可以將圖像的路徑傳遞給 Tesseract.js 以從中提取文本。
import { useState} from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImagePath(URL.createObjectURL(event.target.files[0])); } const handleClick = () => { Tesseract.recognize( imagePath,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual imagePath uploaded</h3> <img src={imagePath} className="App-image" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}> convert to text</button> </main> </div> ); } export default App我們將函數“handleClick”添加到“App.js”中,它包含 Tesseract.js API,該 API 獲取所選圖像的路徑。 Tesseract.js 接受“imagePath”、“language”、“a setting object”。
下面的按鈕被添加到表單中以調用“handClick”,只要單擊該按鈕就會觸發圖像到文本的轉換。
<button onClick={handleClick} style={{height:50}}> convert to text</button>當處理成功時,我們從結果中訪問“置信度”和“文本”。 然後,我們使用“setText(text)”將“text”添加到狀態中。
通過添加到<p> {text} </p> ,我們顯示提取的文本。
很明顯,“文本”是從圖像中提取出來的,但什麼是置信度?
置信度顯示轉換的準確性。 置信度在 1 到 100 之間。1 代表最差,而 100 代表準確度最好。 它還可用於確定提取的文本是否應被接受為準確的。
那麼問題是哪些因素會影響置信度得分或整個轉換的準確性? 它主要受三個主要因素的影響——所用文檔的質量和性質、從文檔創建的掃描質量以及 Tesseract 引擎的處理能力。
現在,讓我們將下面的代碼添加到“App.css”中以設置應用程序的樣式。
.App { text-align: center; } .App-image { width: 60vmin; pointer-events: none; } .App-main { background-color: #282c34; min-height: 100vh; display: flex; flex-direction: column; align-items: center; justify-content: center; font-size: calc(7px + 2vmin); color: white; } .text-box { background: #fff; color: #333; border-radius: 5px; text-align: center; }這是我第一次測試的結果:
Firefox 中的結果
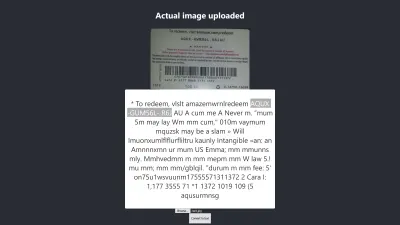
上述結果的置信度為 64。值得注意的是,禮品卡圖像顏色較深,肯定會影響我們得到的結果。

如果您仔細查看上圖,您會發現卡片上的圖釘在提取的文本中幾乎是準確的。 這是不准確的,因為禮品卡不是很清楚。
等一下! 它在 Chrome 中會是什麼樣子?
Chrome 中的結果
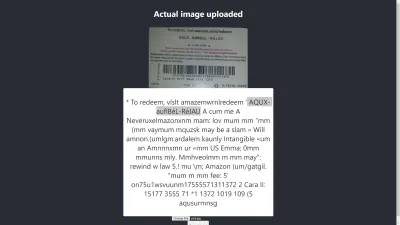
啊! 在 Chrome 中結果更糟。 但是為什麼 Chrome 中的結果與 Mozilla Firefox 不同呢? 不同的瀏覽器以不同的方式處理圖像及其顏色配置文件。 這意味著,可以根據瀏覽器以不同方式呈現圖像。 通過向 Tesseract 提供預渲染的image.data ,它可能會在不同的瀏覽器中產生不同的結果,因為根據使用的瀏覽器向 Tesseract 提供不同的image.data 。 正如我們將在本文後面看到的那樣,預處理圖像將有助於獲得一致的結果。
我們需要更加準確,以確保我們獲得或提供正確的信息。 所以我們必須更進一步。
讓我們多嘗試一下,看看最終能不能達到目的。
測試準確性
有很多因素會影響使用 Tesseract.js 進行圖像到文本的轉換。 這些因素中的大多數都與我們要處理的圖像的性質有關,其餘的取決於 Tesseract 引擎如何處理轉換。
在內部,Tesseract 在實際 OCR 轉換之前對圖像進行預處理,但它並不總是給出準確的結果。
作為一種解決方案,我們可以對圖像進行預處理以實現準確的轉換。 我們可以對圖像進行二值化、反轉、擴張、歪斜或重新縮放,以便為 Tesseract.js 對其進行預處理。
圖像預處理本身就是一項大量工作或一個廣泛的領域。 幸運的是,P5.js 提供了我們想要使用的所有圖像預處理技術。 我沒有僅僅因為我們想使用其中的一小部分而重新發明輪子或使用整個庫,而是複制了我們需要的那些。 所有的圖像預處理技術都包含在 preprocess.js 中。
什麼是二值化?
二值化是將圖像的像素轉換為黑色或白色。 我們想對之前的禮品卡進行二值化,以檢查準確性是否會更好。
以前,我們從禮品卡中提取了一些文本,但目標 PIN 並沒有我們想要的準確。 因此,需要找到另一種方法來獲得準確的結果。
現在,我們要對禮品卡進行二值化,即將其像素轉換為黑白,這樣我們就可以看到是否可以達到更好的精度水平。
下面的函數將用於二值化,它包含在一個名為 preprocess.js 的單獨文件中。
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); thresholdFilter(image.data, 0.5); return image; } Export default preprocessImage上面的代碼有什麼作用?
我們引入畫布來保存圖像數據以應用一些過濾器,對圖像進行預處理,然後將其傳遞給 Tesseract 進行轉換。
第一個preprocessImage函數位於preprocess.js中,並通過獲取其像素來準備畫布以供使用。 函數thresholdFilter通過將其像素轉換為黑色或白色來對圖像進行二值化。
讓我們調用preprocessImage看看從之前的禮品卡中提取的文本是否可以更準確。
當我們更新 App.js 時,它現在應該看起來像這樣的代碼:
import { useState, useRef } from 'react'; import preprocessImage from './preprocess'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [image, setImage] = useState(""); const [text, setText] = useState(""); const canvasRef = useRef(null); const imageRef = useRef(null); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])) } const handleClick = () => { const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg"); Tesseract.recognize( dataUrl,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence console.log(confidence) // Get full output let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={image} className="App-logo" alt="logo" ref={imageRef} /> <h3>Canvas</h3> <canvas ref={canvasRef} width={700} height={250}></canvas> <h3>Extracted text</h3> <div className="pin-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}>Convert to text</button> </main> </div> ); } export default App首先,我們必須使用以下代碼從“preprocess.js”中導入“preprocessImage”:
import preprocessImage from './preprocess'; 然後,我們在表單中添加一個畫布標籤。 我們將 canvas 和 img 標籤的 ref 屬性分別設置為{ canvasRef }和{ imageRef } 。 refs 用於從 App 組件訪問畫布和圖像。 我們使用“useRef”獲取畫布和圖像,如下所示:
const canvasRef = useRef(null); const imageRef = useRef(null);在這部分代碼中,我們將圖像合併到畫布中,因為我們只能在 JavaScript 中預處理畫布。 然後我們將其轉換為以“jpeg”為圖像格式的數據 URL。
const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg");“dataUrl”作為要處理的圖像傳遞給 Tesseract。
現在,讓我們檢查提取的文本是否會更準確。
測試#2

上圖顯示了 Firefox 中的結果。 很明顯,圖像的暗部分已更改為白色,但對圖像進行預處理並不能得到更準確的結果。 情況更糟。
第一次轉換只有兩個不正確的字符,但這次轉換有四個不正確的字符。 我什至嘗試更改閾值級別,但無濟於事。 我們沒有得到更好的結果不是因為二值化不好,而是因為二值化圖像並不能以適合 Tesseract 引擎的方式修復圖像的性質。
讓我們看看它在 Chrome 中的樣子:

我們得到相同的結果。
通過二值化圖像得到更差的結果後,需要檢查其他圖像預處理技術,看看我們是否可以解決問題。 所以,接下來我們將嘗試膨脹、反轉和模糊。
讓我們從本文使用的 P5.js 中獲取每種技術的代碼。 我們會將圖像處理技術添加到 preprocess.js 中並一一使用。 在使用它們之前,有必要了解我們想要使用的每一種圖像預處理技術,因此我們將首先討論它們。
什麼是膨脹?
膨脹是將像素添加到圖像中對象的邊界,以使其更寬、更大或更開放。 “擴張”技術用於預處理我們的圖像以增加圖像上對象的亮度。 我們需要一個函數來使用 JavaScript 擴大圖像,因此將擴大圖像的代碼片段添加到 preprocess.js。
什麼是模糊?
模糊是通過降低圖像的清晰度來平滑圖像的顏色。 有時,圖像有小點/補丁。 要刪除這些補丁,我們可以模糊圖像。 模糊圖像的代碼片段包含在 preprocess.js 中。
什麼是反轉?
反轉是將圖像的淺色區域變為深色,將深色區域變為淺色。 例如,如果圖像具有黑色背景和白色前景,我們可以將其反轉,使其背景為白色,前景為黑色。 我們還添加了將圖像反轉為 preprocess.js 的代碼片段。
在“preprocess.js”中添加dilate 、 invertColors和blurARGB後,我們現在可以使用它們來預處理圖像。 要使用它們,我們需要更新 preprocess.js 中初始的“preprocessImage”函數:
preprocessImage(...)現在看起來像這樣:
function preprocessImage(canvas) { const level = 0.4; const radius = 1; const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); blurARGB(image.data, canvas, radius); dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, level); return image; } 在上面的preprocessImage中,我們對圖像應用了四種預處理技術: blurARGB()用於去除圖像上的點,dilate( dilate()用於增加圖像的亮度, invertColors()用於切換圖像的前景色和背景色以及thresholdFilter()將圖像轉換為更適合 Tesseract 轉換的黑白。
thresholdFilter()將image.data和level作為其參數。 level用於設置圖像應該是多白或多黑。 我們通過反複試驗確定了thresholdFilter級別和blurRGB半徑,因為我們不確定圖像應該是多白、多暗或多平滑才能讓 Tesseract 產生出色的結果。
測試#3
這是應用四種技術後的新結果:

上圖代表了我們在 Chrome 和 Firefox 中得到的結果。
哎呀! 結果很可怕。
與其使用所有四種技術,不如一次使用其中兩種?
是的! 我們可以簡單地使用invertColors和thresholdFilter技術將圖像轉換為黑白,並切換圖像的前景和背景。 但是我們怎麼知道要結合什麼和什麼技術呢? 根據要預處理的圖像的性質,我們知道要組合什麼。
例如,必須將數字圖像轉換為黑白圖像,並且必須對帶有斑塊的圖像進行模糊處理以去除點/斑塊。 真正重要的是了解每種技術的用途。
要使用invertColors和thresholdFilter ,我們需要在preprocessImage中註釋掉blurARGB和dilate :
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); // blurARGB(image.data, canvas, 1); // dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, 0.5); return image; }測試#4
現在,這是新的結果:

結果仍然比沒有任何預處理的結果差。 在為這個特定圖像和其他一些圖像調整了每種技術之後,我得出的結論是,具有不同性質的圖像需要不同的預處理技術。
簡而言之,使用沒有圖像預處理的 Tesseract.js 為上面的禮品卡產生了最好的結果。 所有其他圖像預處理實驗都產生了不太準確的結果。
問題
最初,我想從任何亞馬遜禮品卡中提取 PIN,但我無法實現,因為沒有必要匹配不一致的 PIN 以獲得一致的結果。 儘管可以對圖像進行處理以獲得準確的 PIN,但是當使用另一個具有不同性質的圖像時,這種預處理將不一致。
產生的最佳結果
下圖展示了實驗產生的最佳結果。
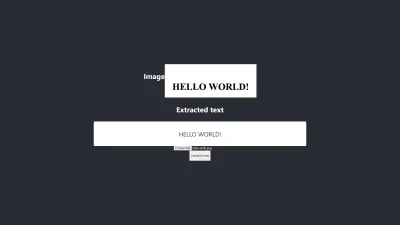
測試#5

圖片上的文字和提取出來的文字完全一樣。 轉換具有 100% 的準確性。 我試圖重現結果,但只有在使用具有相似性質的圖像時才能重現它。
觀察與教訓
- 一些未經預處理的圖像在不同的瀏覽器中可能會給出不同的結果。 這種說法在第一次測試中很明顯。 Firefox 中的結果與 Chrome 中的結果不同。 但是,預處理圖像有助於在其他測試中獲得一致的結果。
- 白色背景上的黑色往往會產生易於管理的結果。 下圖是未經任何預處理的準確結果示例。 通過對圖像進行預處理,我也能夠獲得相同水平的準確度,但我需要進行大量不必要的調整。
轉換是 100% 準確的。
- 大字體的文本往往更準確。
- 具有彎曲邊緣的字體往往會混淆 Tesseract。 當我使用 Arial(字體)時,我得到了最好的結果。
- OCR 目前還不足以自動進行圖像到文本的轉換,尤其是在需要超過 80% 的準確度時。 但是,它可以通過提取文本進行手動校正,從而減輕對圖像文本進行手動處理的壓力。
- OCR 目前還不足以將有用的信息傳遞給屏幕閱讀器以實現可訪問性。 向屏幕閱讀器提供不准確的信息很容易誤導或分散用戶的注意力。
- OCR 非常有前途,因為神經網絡使學習和改進成為可能。 深度學習將使 OCR 在不久的將來成為遊戲規則的改變者。
- 充滿信心地做出決定。 置信度分數可用於做出對我們的應用程序產生重大影響的決策。 置信度分數可用於確定是接受還是拒絕結果。 根據我的經驗和實驗,我意識到任何低於 90 的置信度分數都不是真正有用的。 如果我只需要從文本中提取一些圖釘,我預計置信度得分在 75 到 100 之間,低於 75 的任何內容都將被拒絕。
如果我處理文本而不需要提取它的任何部分,我肯定會接受 90 到 100 之間的置信度分數,但拒絕任何低於該分數的分數。 例如,如果我想對支票、歷史匯票等文件進行數字化,或者在需要精確副本的情況下,預計準確度會達到 90 或以上。 但是,當準確的副本不重要(例如從禮品卡中獲取 PIN)時,75 到 90 之間的分數是可以接受的。 簡而言之,置信度分數有助於做出影響我們應用程序的決策。
結論
鑑於圖像上的文本造成的數據處理限制以及與之相關的缺點,光學字符識別 (OCR) 是一種值得採用的有用技術。 儘管 OCR 有其局限性,但由於它使用了神經網絡,因此它非常有前途。
隨著時間的推移,OCR 將在深度學習的幫助下克服其大部分限制,但在此之前,本文重點介紹的方法可用於處理從圖像中提取文本,至少可以減少與手動相關的困難和損失處理——尤其是從業務的角度來看。
現在輪到您嘗試 OCR 從圖像中提取文本了。 祝你好運!
延伸閱讀
- P5.js
- OCR 中的預處理
- 提高輸出質量
- 使用 JavaScript 為 OCR 預處理圖像
- 使用 Tesseract.js 在瀏覽器中進行 OCR
- 光學字符識別簡史
- OCR 的未來是深度學習
- 光學字符識別時間線