
CNN 中的圖像分類:你需要知道的一切
已發表: 2021-02-25目錄
介紹
在瀏覽 Facebook 提要時,您是否想過合影中的人是如何被 Facebook 的軟件自動標記的? 在你看到的每個 Facebook 交互式用戶界面的背後,都有一個複雜而強大的算法,用於識別和標記我們上傳到社交媒體平台的每張圖片。 對於我們的每一張照片,我們只會幫助提高算法的效率。 是的,圖像分類是我們看到人工智能應用最廣泛使用的算法之一。
最近,卷積神經網絡 (CNN) 已成為深度學習最有力的支持者之一。 這些卷積網絡的一種流行應用是圖像分類。 在本教程中,我們將了解卷積神經網絡的基礎知識,了解構建 CNN 模型所涉及的各個層,最後可視化圖像分類任務的示例。
圖像分類
在深入了解深度學習和卷積神經網絡的細節之前,讓我們了解一下圖像分類的基礎知識。 一般來說,圖像分類被定義為我們將圖像作為輸入給使用特定算法構建的模型的任務,該算法輸出圖像所屬的類別或類別的概率。 我們將圖像標記到特定類別的這個過程稱為監督學習。
我們看到圖像的方式與機器(計算機)看到相同圖像的方式之間存在巨大差異。 對我們來說,我們能夠可視化圖像並根據顏色和大小對其進行表徵。 另一方面,對於機器來說,它所看到的只是數字。 看到的數字稱為像素。
每個像素都有一個介於 0 和 255 之間的值。因此,使用這些數字數據,機器需要一些預處理步驟,以便導出一些將一個圖像與另一個圖像區分開來的特定模式或特徵。 卷積神經網絡幫助我們構建能夠從圖像中導出特定模式的算法。
我們看到的與計算機看到的
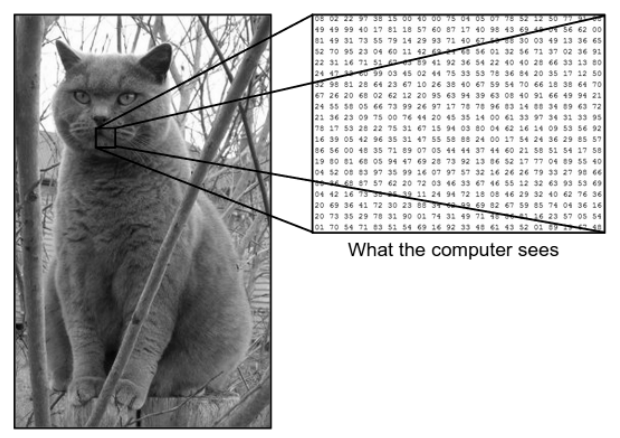 來源-計算機和人眼之間的差異
來源-計算機和人眼之間的差異

圖像分類的深度學習
現在我們已經了解了什麼是圖像分類,現在讓我們看看如何使用人工智能來實現它。 為此,我們使用流行的深度學習方法。 深度學習是人工智能的一個子集,它利用大型圖像數據集從各種圖像中識別和派生模式,以區分圖像數據集中存在的各種類別。
深度學習面臨的主要挑戰是,對於一個龐大的數據庫,它需要很長時間,並且計算成本很高。 然而,作為一種深度學習算法的捲積神經網絡很好地解決了這個問題。
卷積神經網絡
在深度學習中,卷積神經網絡是一類深度神經網絡,主要用於視覺圖像。 它們是由 Yann LeCunn 於 1998 年提出的人工神經網絡 (ANN) 的一種特殊架構。 卷積神經網絡由兩部分組成。
第一部分由卷積層和池化層組成,主要特徵提取過程在其中進行。 在第二部分中,Fully Connected 和 Dense 層對提取的特徵執行幾個非線性變換,並充當分類器部分。 學習 CNN 進行圖像分類。
考慮上面顯示的人和機器看到的圖像示例。 正如我們所看到的,計算機看到了一個像素陣列。 例如,如果圖像大小為 500×500,那麼數組的大小將為 500x500x3。 這裡,500 代表每個高度和寬度,3 代表 RGB 通道,其中每個顏色通道由一個單獨的數組表示。 像素強度從 0 到 255 不等。
現在對於圖像分類,計算機將在基本級別查找特徵。 根據我們人類的說法,貓的這些基本特徵是它的耳朵、鼻子和鬍鬚。 而對於計算機來說,這些基本特徵是曲率和邊界。 通過這種方式,通過使用幾個不同的層,例如卷積層和池化層,計算機從圖像中提取基本級別的特徵。
在卷積神經網絡模型中,有幾種類型的層,例如 -
- 輸入層
- 卷積層
- 池化層
- 全連接層
- 輸出層
- 激活函數
在我們進入圖像分類中的應用之前,讓我們簡要介紹每一層。
輸入層
從名稱中,我們了解到這是將輸入圖像輸入 CNN 模型的層。 根據我們的要求,我們可以將圖像重塑為不同的大小,例如 (28,28,3)
卷積層
然後是最重要的層,它由一個固定大小的過濾器(也稱為內核)組成。 卷積的數學運算是在輸入圖像和濾波器之間進行的。 這是從圖像中提取大部分基本特徵(例如銳邊和曲線)的階段,因此該層也稱為特徵提取器層。
池化層
執行卷積操作後,我們執行池化操作。 這也稱為下採樣,其中圖像的空間體積被減少。 例如,如果我們對尺寸為 28×28 的圖像執行步長為 2 的池化操作,則圖像尺寸縮小到 14×14,它會縮小到原始尺寸的一半。
全連接層
全連接層 (FC) 放置在 CNN 模型的最終分類輸出之前。 這些層用於在分類之前將結果展平。 它涉及幾個偏差、權重和神經元。 在分類之前附加一個 FC 層會產生一個 N 維向量,其中 N 是模型必須從中選擇一個類的多個類。
輸出層
最後,輸出層由標籤組成,該標籤主要使用 one-hot 編碼方法進行編碼。
激活函數
這些激活函數是任何卷積神經網絡模型的核心。 這些函數用於確定神經網絡的輸出。 簡而言之,它決定了一個特定的神經元是否應該被激活(“激發”)。 這些通常是對輸入信號執行的非線性函數。 然後將此轉換後的輸出作為輸入發送到下一層神經元。 有幾種激活函數,例如 Sigmoid、ReLU、Leaky ReLU、TanH 和 Softmax。
基本 CNN 架構
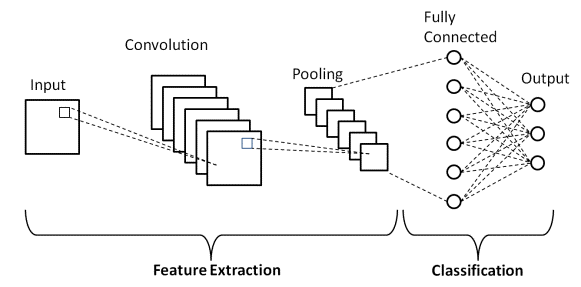
資料來源:基本 CNN 架構
如前所述,上圖是卷積神經網絡模型的基本架構。 現在我們已經準備好圖像分類和 CNN 的基礎知識,現在讓我們深入研究它的實時問題應用。 了解有關基本 CNN 架構的更多信息。
卷積神經網絡實現
現在我們已經了解了圖像分類和卷積神經網絡的基礎知識,讓我們用 Python 編碼可視化它在 TensorFlow/Keras 中的實現。 在此,我們將使用基本 LeNet 架構構建一個簡單的捲積神經網絡模型,在訓練集和測試集上訓練模型,最終獲得模型在測試集數據上的準確度。
問題集
在這篇用於構建和訓練卷積神經網絡模型的文章中,我們將使用著名的 Fashion MNIST 數據集。 MNIST 代表修改後的國家標準與技術研究所。 Fashion-MNIST 是 Zalando 文章圖像的數據集——由 60,000 個示例的訓練集和 10,000 個示例的測試集組成。 每個示例都是 28×28 灰度圖像,與來自 10 個類別的標籤相關聯。
每個訓練和測試示例都分配給以下標籤之一:
0 – T 卹/上衣
1 – 褲子
2 – 套頭衫
3 – 連衣裙
4 – 外套
5 – 涼鞋
6 – 襯衫
7 – 運動鞋
8 – 包
9 – 踝靴
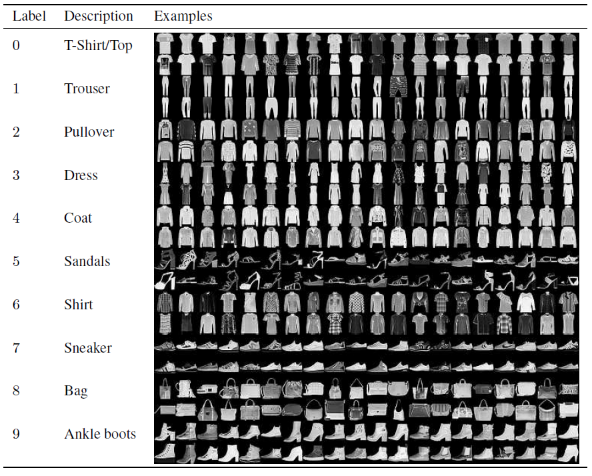
來源:時尚 MNIST 數據集圖像

程序代碼
第 1 步 - 導入庫
構建任何深度學習模型的第一步是導入程序所需的庫。 在我們的示例中,由於我們使用的是 TensorFlow 框架,我們將導入 Keras 庫以及其他重要的庫,例如用於計算的數字和用於繪圖的 matplotlib。
#TensorFlow – 導入庫
將 numpy 導入為 np
將 matplotlib.pyplot 導入為 plt
%matplotlib 內聯
將張量流導入為 tf
從張量流導入 Keras
第 2 步 - 獲取和拆分數據集
導入庫後,下一步是下載數據集並將 Fashion MNIST 數據集拆分為各自的 60,000 個訓練數據和 10,000 個測試數據。 幸運的是,keras 為我們提供了一個預定義的函數來導入 Fashion MNIST 數據集,我們可以使用自己理解的簡單代碼行將它們拆分到下一行。
#TensorFlow – 獲取和拆分數據集
fashion_mnist = keras.datasets.fashion_mnist
(train_images_tf, train_labels_tf), (test_images_tf, test_labels_tf) = fashion_mnist.load_data()
第 3 步 - 可視化數據
由於數據集與圖像及其相應標籤一起下載,為了讓用戶更清楚,始終建議查看數據,以便我們了解我們正在處理的數據類型,構建卷積神經網絡相應的網絡模型。 在這裡,通過下面給出的這個簡單代碼塊,我們將可視化隨機打亂的訓練數據集的前 3 張圖像。
#TensorFlow – 數據可視化
定義 imshowTensorFlow(img):
plt.imshow(img, cmap='灰色')
打印(“標籤:”,img [0])
imshowTensorFlow(train_images_tf[0])
標籤:9標籤:0標籤:3
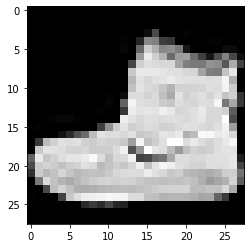


上面給出的圖像及其標籤可以使用上面 Fashion MNIST 數據集詳細信息中給出的標籤進行驗證。 由此,我們推斷我們的數據圖像是一個灰度圖像,高度為 28 像素,寬度為 28 像素。
因此,可以使用 (28,28,1) 的輸入大小來構建模型,其中 1 代表灰度圖像。
第 4 步 - 構建模型
如上所述,在本文中,我們將使用 LeNet 架構構建一個簡單的捲積神經網絡。 LeNet 是 Yann LeCun 等人提出的捲積神經網絡結構。 1989年。一般來說,LeNet是指LeNet-5,是一個簡單的捲積神經網絡。
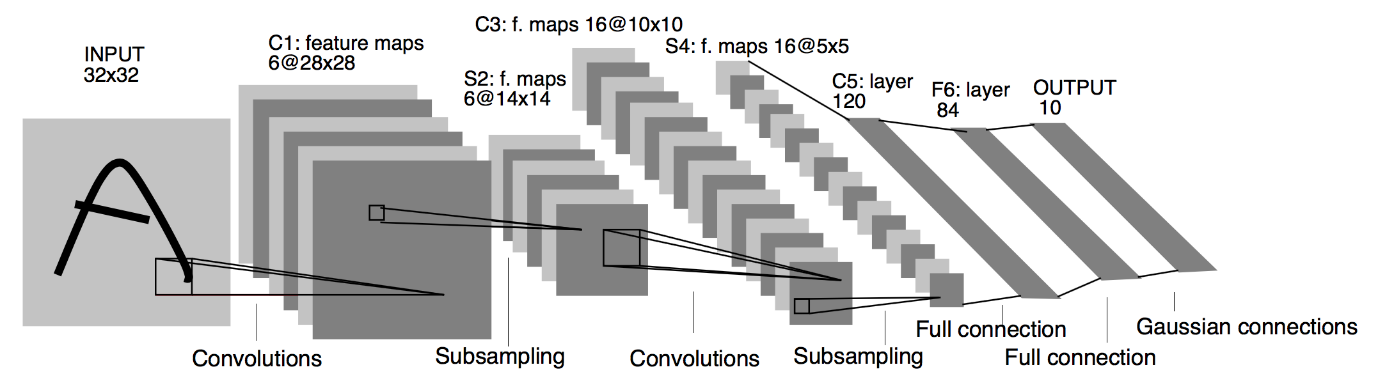
資料來源:LeNet 架構
從上面給出的 LeNet CNN 模型的架構圖中,我們看到有 5+2 層。 第一層和第二層是卷積層,然後是池化層。 同樣,第三和第四層由卷積層和池化層組成。 作為這些操作的結果,輸入圖像的大小從 28×28 減小到 7×7。
LeNet 模型的第五層是全連接層,它使前一層的輸出變平。 接下來是兩個 Dense 層,CNN 模型的最終輸出層由一個具有 10 個單元的 Softmax 激活函數組成。 Softmax 函數為 Fashion MNIST 數據集的 10 個類別中的每一個預測類別概率。
#TensorFlow – 構建模型
模型 = keras.Sequential([
keras.layers.Conv2D(input_shape=(28,28,1), filters=6, kernel_size=5, strides=1, padding=”same”, activation=tf.nn.relu),
keras.layers.AveragePooling2D(pool_size=2, strides=2),
keras.layers.Conv2D(16, kernel_size=5, strides=1, padding=”same”, activation=tf.nn.relu),
keras.layers.AveragePooling2D(pool_size=2, strides=2),
keras.layers.Flatten(),
keras.layers.Dense(120, 激活=tf.nn.relu),
keras.layers.Dense(84, 激活=tf.nn.relu),
keras.layers.Dense(10, 激活=tf.nn.softmax)
])
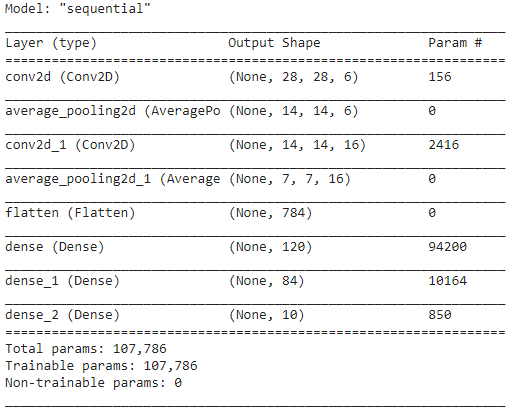
第 5 步 - 模型摘要
一旦 LeNet 模型的層最終確定,我們就可以繼續編譯模型並查看設計的 CNN 模型的摘要版本。
#TensorFlow – 模型摘要
model.compile(loss=keras.losses.categorical_crossentropy,
優化器='亞當',
指標=['acc'])
模型.summary()
在此,由於最終輸出有超過 2 個類(10 個類),我們使用分類交叉熵作為損失函數,並使用 Adam Optimizer 來構建我們的模型。 模型總結如下。
第 6 步 - 訓練模型
最後,我們開始了 LeNet CNN 模型的訓練過程。 首先,我們重塑訓練數據集並通過除以 255.0 將其歸一化為更小的值,以降低計算成本。 然後將訓練標籤從整數類向量轉換為二進制類矩陣。 例如,標籤 3 轉換為 [0, 0, 0, 1, 0, 0, 0, 0, 0]
#TensorFlow – 訓練模型
train_images_tensorflow = (train_images_tf / 255.0).reshape(train_images_tf.shape[0], 28, 28, 1)
test_images_tensorflow = (test_images_tf / 255.0).reshape(test_images_tf.shape[0], 28, 28 ,1)
train_labels_tensorflow=keras.utils.to_categorical(train_labels_tf)
test_labels_tensorflow=keras.utils.to_categorical(test_labels_tf)
H = model.fit(train_images_tensorflow, train_labels_tensorflow, epochs=30, batch_size=32)
在 30 個 epoch 後的訓練結束時,我們得到最終的訓練準確率和損失:
時代 30/30
1875/1875 [===============================] – 4s 2ms/步 – 損失:0.0421 – acc: 0.9850
訓練準確率:98.294997215271 %
訓練損失:0.04584110900759697
第 7 步 – 預測結果
最後,一旦我們完成了 CNN 模型的訓練過程,我們將在測試數據集上擬合相同的模型並預測 10,000 個測試圖像的準確性。
#TensorFlow – 比較結果
預測 = model.predict(test_images_tensorflow)
正確 = 0
對於 i, pred in enumerate(predictions):
如果 np.argmax(pred) == test_labels_tf[i]:
正確 += 1
print('Test Accuracy of the model on the {} test images: {}% with TensorFlow'.format(test_images_tf.shape[0],100 * correct/test_images_tf.shape[0]))
我們得到的輸出是,
模型在 10000 張測試圖像上的測試準確率:90.67% 使用 TensorFlow
至此,我們結束了使用卷積神經網絡構建圖像分類模型的程序。
另請閱讀:機器學習項目理念
結論
因此,在這篇關於在 CNN 中實現圖像分類的教程中,我們了解了圖像分類、卷積神經網絡背後的基本概念,以及它在 Python 編程語言和 TensorFlow 框架中的實現。
如果您有興趣了解有關機器學習的更多信息,請查看 IIIT-B 和 upGrad 的機器學習和人工智能 PG 文憑,該文憑專為工作專業人士設計,提供 450 多個小時的嚴格培訓、30 多個案例研究和作業、IIIT- B 校友身份、5 個以上實用的實踐頂點項目和頂級公司的工作協助。
哪種 CNN 模型被認為最適合圖像分類?
用於圖像分類的最佳 CNN 模型是 VGG-16,它代表用於大規模圖像識別的非常深卷積網絡。 VGG 被設計為深度 CNN,在 ImageNet 之外的各種任務和數據集上都優於基線。 該模型的顯著特點是,在創建它時,更多的注意力放在了合併優秀的捲積層上,而不是專注於添加大量的超參數。 它總共有 16 層,5 個塊,每個塊都有一個最大池化層,使其成為一個相當大的網絡。
使用 CNN 模型進行圖像分類的缺點是什麼?
在圖像分類方面,CNN 模型非常成功。 然而,使用 CNN 有幾個缺點。 如果要識別的圖片是傾斜的或者旋轉的,那麼CNN模型在準確識別圖像時就會出現問題。 當 CNN 可視化圖像時,沒有組件及其部分-整體連接的內部表示。 此外,如果要使用的 CNN 模型包括許多卷積層,則分類過程將需要很長時間。
為什麼使用 CNN 模型優於 ANN 將圖像數據作為輸入?
通過組合過濾器或轉換,CNN 可以為作為輸入提供的每張圖像學習多層特徵表示。 由於在 CNN 中要學習的網絡參數數量比多層神經網絡中的要少得多,因此減少了過度擬合。 使用 ANN 時,神經網絡可以學習圖像的單個特徵表示,但在復雜圖像的情況下,ANN 將無法提供改進的可視化或分類,因為它無法學習輸入圖像中存在的像素依賴性。