
HTTP/3:性能改進(第 2 部分)
已發表: 2022-03-10歡迎回到這個關於新 HTTP/3 協議的系列。 在第 1 部分中,我們研究了為什麼我們需要 HTTP/3 和底層 QUIC 協議,以及它們的主要新特性是什麼。
在第二部分中,我們將重點介紹 QUIC 和 HTTP/3 為網頁加載帶來的性能改進。 但是,我們也會對這些新功能在實踐中的預期影響持懷疑態度。
正如我們將看到的,QUIC 和 HTTP/3 確實具有巨大的 Web 性能潛力,但主要針對慢速網絡的用戶。 如果您的普通訪問者使用的是快速有線或蜂窩網絡,他們可能不會從新協議中獲得太多好處。 但是,請注意,即使在通常具有快速上行鏈路的國家和地區,最慢的 1% 甚至 10% 的受眾(所謂的第 99或第 90 個百分位數)仍然有可能獲得很多收益。 這是因為 HTTP/3 和 QUIC 主要幫助處理當今互聯網上可能出現的一些不常見但潛在的高影響問題。
這部分比第一部分更具技術性,儘管它將大部分真正深入的東西卸載到外部資源,重點解釋為什麼這些東西對普通 Web 開發人員很重要。
- 第 1 部分:HTTP/3 歷史和核心概念
本文主要針對 HTTP/3 和一般協議的新手,主要討論基礎知識。 - 第 2 部分:HTTP/3 性能特性
這一個更深入和技術。 已經了解基礎知識的人可以從這裡開始。 - 第 3 部分:實用的 HTTP/3 部署選項
本系列的第三篇文章解釋了自己部署和測試 HTTP/3 所涉及的挑戰。 它詳細說明瞭如何以及是否應該更改您的網頁和資源。
速度入門
討論性能和“速度”很快就會變得複雜,因為許多潛在的方面都會導致網頁加載“緩慢”。 因為我們這里處理的是網絡協議,所以我們將主要看網絡方面,其中兩個最重要:延遲和帶寬。
延遲可以粗略定義為從 A 點(例如客戶端)發送數據包到 B 點(服務器)所需的時間。 它在物理上受到光速的限制,或者實際上,信號在電線或戶外傳播的速度有多快。 這意味著延遲通常取決於 A 和 B 之間的物理距離。
實際上,這意味著典型的延遲在概念上很小,大約在 10 到 200 毫秒之間。 然而,這只是一種方式:對數據包的響應也需要返回。 雙向延遲通常稱為往返時間 (RTT) 。
由於擁塞控制等功能(見下文),我們通常需要相當多的往返來加載甚至是單個文件。 因此,即使低於 50 毫秒的低延遲也會導致相當大的延遲。 這是內容交付網絡 (CDN) 存在的主要原因之一:它們將服務器放置在物理上更靠近最終用戶的位置,以盡可能減少延遲,從而減少延遲。
那麼,帶寬大致可以說是可以同時發送的數據包的數量。 這有點難以解釋,因為它取決於介質的物理特性(例如,使用的無線電波頻率)、網絡上的用戶數量以及互連不同子網的設備(因為它們通常每秒只能處理一定數量的數據包)。
一個常用的比喻是用來輸送水的管道。 管道的長度是延遲,而管道的寬度是帶寬。 然而,在互聯網上,我們通常有一系列連接的管道,其中一些可能比其他管道更寬(導致在最窄的鏈接處出現所謂的瓶頸)。 因此,A 點和 B 點之間的端到端帶寬通常受到最慢子部分的限制。
雖然這篇文章的其餘部分不需要對這些概念有一個完美的理解,但有一個通用的高級定義會很好。 有關更多信息,我建議查看 Ilya Grigorik 在他的《高性能瀏覽器網絡》一書中關於延遲和帶寬的優秀章節。
擁塞控制
性能的一個方面是關於傳輸協議如何有效地使用網絡的全部(物理)帶寬(即粗略地說,每秒可以發送或接收多少數據包)。 這反過來會影響頁面資源的下載速度。 有人聲稱 QUIC 在這方面比 TCP 做得更好,但事實並非如此。
你知道嗎?
例如,TCP 連接不僅僅開始以全帶寬發送數據,因為這可能最終導致網絡過載(或擁塞)。 這是因為,正如我們所說,每個網絡鏈接每秒只能(物理)處理一定數量的數據。 再給它,除了丟棄過多的數據包之外別無選擇,導致數據包丟失。
如第 1 部分所述,對於像 TCP 這樣的可靠協議,從丟包中恢復的唯一方法是重新傳輸數據的新副本,這需要一個往返。 尤其是在高延遲網絡上(例如,超過 50 毫秒的 RTT),數據包丟失會嚴重影響性能。
另一個問題是我們事先不知道最大帶寬是多少。 它通常取決於端到端連接中某處的瓶頸,但我們無法預測或知道它會在哪裡。 互聯網也沒有(還)向端點發送鏈路容量信號的機制。
此外,即使我們知道可用的物理帶寬,也不意味著我們可以自己使用所有這些帶寬。 幾個用戶通常同時在網絡上處於活動狀態,每個用戶都需要公平共享可用帶寬。
因此,連接不知道它可以安全或公平地預先使用多少帶寬,並且此帶寬會隨著用戶加入、離開和使用網絡而改變。 為了解決這個問題,TCP 會通過一種稱為擁塞控制的機制不斷嘗試發現可用帶寬。
在連接開始時,它只發送幾個數據包(實際上,範圍在 10 到 100 個數據包之間,或大約14 到 140 KB的數據)並等待一個往返,直到接收器發回對這些數據包的確認。 如果它們都被確認,這意味著網絡可以處理該發送速率,我們可以嘗試重複該過程,但需要更多數據(實際上,發送速率通常每次迭代都會翻倍)。
這樣,發送速率會繼續增長,直到某些數據包未被確認(這表明數據包丟失和網絡擁塞)。 這個第一階段通常被稱為“慢啟動”。 在檢測到數據包丟失時,TCP 會降低發送速率,並且(一段時間後)開始再次增加發送速率,儘管增量(小得多)。 此後,每次丟包都會重複這種先減少後增長的邏輯。 最終,這意味著 TCP 將不斷嘗試達到其理想的、公平的帶寬份額。 這種機制如圖 1 所示。
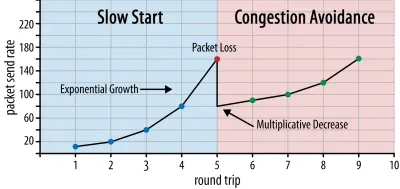
這是對擁塞控制的過度簡化的解釋。 在實踐中,還有許多其他因素在起作用,例如緩衝區膨脹、由於擁塞導致的 RTT 波動,以及多個並發發送者需要獲得其公平份額的帶寬這一事實。 因此,存在許多不同的擁塞控制算法,並且今天仍在發明大量算法,但沒有一種算法在所有情況下都表現最佳。
雖然 TCP 的擁塞控制使其健壯,但也意味著需要一段時間才能達到最佳發送速率,具體取決於 RTT 和實際可用帶寬。 對於網頁加載,這種慢啟動方法也會影響諸如第一次內容繪製等指標,因為在最初的幾次往返中只能傳輸少量數據(幾十到幾百 KB)。 (您可能聽說過將關鍵數據保持在 14 KB 以下的建議。)
因此,選擇更積極的方法可能會在高帶寬和高延遲網絡上產生更好的結果,尤其是在您不關心偶爾的數據包丟失的情況下。 這就是我再次看到許多關於 QUIC 工作原理的誤解的地方。
正如第 1 部分所討論的,QUIC 在理論上受到丟包(以及相關的線頭 (HOL) 阻塞)的影響較小,因為它獨立處理每個資源字節流上的丟包。 此外,QUIC 運行在用戶數據報協議(UDP) 上,與 TCP 不同,它沒有內置的擁塞控制功能; 它允許您嘗試以您想要的任何速率發送,並且不會重新傳輸丟失的數據。
這導致許多文章聲稱 QUIC 也不使用擁塞控制,QUIC 可以開始以更高的速率通過 UDP 發送數據(依靠去除 HOL 阻塞來處理數據包丟失),這就是為什麼QUIC 比 TCP 快得多。
實際上,事實並非如此: QUIC 實際上使用與 TCP 非常相似的帶寬管理技術。 它也以較低的發送速率開始,並隨著時間的推移而增長,使用確認作為衡量網絡容量的關鍵機制。 這是(除其他原因外)因為 QUIC 需要可靠才能對諸如 HTTP 之類的東西有用,因為它需要對其他 QUIC(和 TCP!)連接公平,並且因為它的 HOL 阻塞刪除不會實際上有助於防止數據包丟失(我們將在下面看到)。
然而,這並不意味著 QUIC 在管理帶寬方面不能(有點)比 TCP 更聰明。 這主要是因為QUIC 比 TCP 更靈活、更容易演進。 正如我們所說,擁塞控制算法今天仍在大力發展,例如,我們可能需要調整一些東西以充分利用 5G。
但是,TCP 通常在操作系統 (OS') 內核中實現,這是一個安全且更受限制的環境,對於大多數操作系統來說甚至不是開源的。 因此,調整擁塞邏輯通常只由少數幾個開發人員完成,而且發展緩慢。
相比之下,大多數 QUIC 實現目前是在“用戶空間”(我們通常運行本地應用程序)中完成的,並且是開源的,明確鼓勵更多開發人員進行實驗(如 Facebook 所示) )。
另一個具體的例子是 QUIC 的延遲確認頻率擴展提案。 雖然默認情況下,QUIC 每收到 2 個數據包發送一個確認,但此擴展允許端點確認,例如,每 10 個數據包。 這已被證明在衛星和超高帶寬網絡上具有很大的速度優勢,因為傳輸確認數據包的開銷降低了。 為 TCP 添加這樣的擴展需要很長時間才能被採用,而對於 QUIC,部署起來要容易得多。
因此,我們可以預期 QUIC 的靈活性會隨著時間的推移帶來更多的實驗和更好的擁塞控制算法,這反過來也可以反向移植到 TCP 以改進它。
你知道嗎?
官方的 QUIC Recovery RFC 9002 指定使用 NewReno 擁塞控制算法。 雖然這種方法很健壯,但它也有些過時,不再在實踐中廣泛使用。 那麼,為什麼它在 QUIC RFC 中呢? 第一個原因是,當 QUIC 啟動時,NewReno 是最新的擁塞控制算法,它本身是標準化的。 更高級的算法,例如 BBR 和 CUBIC,要么仍未標準化,要么最近才成為 RFC。
第二個原因是 NewReno 是一個相對簡單的設置。 因為算法需要一些調整來處理 QUIC 與 TCP 的差異,所以用更簡單的算法來解釋這些變化會更容易。 因此,RFC 9002 應該更多地理解為“如何使擁塞控制算法適應 QUIC”,而不是“這是你應該為 QUIC 使用的東西”。 事實上,大多數生產級 QUIC 實現都對 Cubic 和 BBR 進行了自定義實現。
值得重申的是,擁塞控制算法不是特定於 TCP 或 QUIC 的; 它們可以被任一協議使用,並且希望 QUIC 的進步最終也會找到通往 TCP 堆棧的方式。
你知道嗎?
請注意,在擁塞控制旁邊是一個相關的概念,稱為流量控制。 這兩個特性在 TCP 中經常被混淆,因為它們都被稱為使用“TCP 窗口” ,儘管實際上有兩個窗口:擁塞窗口和 TCP 接收窗口。 然而,對於我們感興趣的網頁加載用例,流控制發揮的作用要少得多,所以我們將在此處跳過它。 提供更深入的信息。
這是什麼意思呢?
QUIC 仍然受物理定律的約束,並且需要對互聯網上的其他發件人友善。 這意味著它不會比 TCP 更快地神奇地下載您的網站資源。 然而,QUIC 的靈活性意味著試驗新的擁塞控制算法將變得更加容易,這將在未來改善 TCP 和 QUIC 的情況。
0-RTT 連接設置
第二個性能方面是關於在新連接上發送有用的 HTTP 數據(例如,頁面資源)之前需要多少次往返。 有人聲稱 QUIC 比 TCP + TLS 快兩到三個往返,但我們會看到它實際上只有一個。
你知道嗎?
正如我們在第 1 部分中所說,連接通常會在 HTTP 請求和響應可以交換之前執行一次 (TCP) 或兩次 (TCP + TLS) 握手。 這些握手交換客戶端和服務器都需要知道的初始參數,以便例如加密數據。
正如您在下面的圖 2 中所見,每次握手至少需要一次往返才能完成(TCP + TLS 1.3,(b)),有時需要兩次(TLS 1.2 和之前的 (a))。 這是低效的,因為我們需要至少兩次握手等待時間(開銷)才能發送我們的第一個 HTTP 請求,這意味著至少要等待三個往返才能收到第一個 HTTP 響應數據(返回的紅色箭頭)在慢速網絡上,這可能意味著 100 到 200 毫秒的開銷。
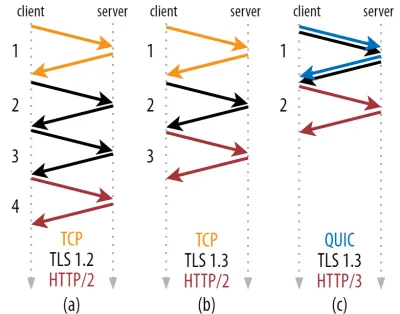
您可能想知道為什麼 TCP + TLS 握手不能簡單地組合在一起,在同一次往返中完成。 雖然這在概念上是可能的(QUIC 正是這樣做的),但最初並不是這樣設計的,因為我們需要能夠在頂部使用帶或不帶 TLS 的 TCP。 換句話說,TCP 根本不支持在握手期間發送非 TCP 內容。 已經努力通過 TCP Fast Open 擴展來添加它; 然而,正如第 1 部分中所討論的,事實證明這很難大規模部署。
幸運的是,QUIC 從一開始就考慮到了 TLS,因此將傳輸和加密握手結合在一個機制中。 這意味著 QUIC 握手總共只需要一次往返即可完成,比 TCP + TLS 1.3 少一次往返(參見上面的圖 2c)。
您可能會感到困惑,因為您可能已經讀過 QUIC 比 TCP 快兩甚至三次往返,而不僅僅是一次。 這是因為大多數文章只考慮最壞的情況(TCP + TLS 1.2,(a)),更不用說現代 TCP + TLS 1.3 也“只”需要兩次往返((b)很少顯示)。 雖然一次往返的速度提升很好,但這並不令人驚訝。 尤其是在快速網絡上(例如,小於 50 毫秒的 RTT),這幾乎不會引起注意,儘管慢速網絡和與遠程服務器的連接會帶來更多收益。
接下來,您可能想知道為什麼我們需要等待握手。 為什麼我們不能在第一次往返中發送 HTTP 請求? 這主要是因為,如果我們這樣做了,那麼第一個請求將被發送未加密,任何竊聽者都可以讀取,這顯然不利於隱私和安全。 因此,在發送第一個 HTTP 請求之前,我們需要等待加密握手完成。 還是我們?
這是在實踐中使用巧妙技巧的地方。 我們知道,用戶經常在第一次訪問後的短時間內重新訪問網頁。 因此,我們可以在未來使用初始加密連接來引導第二個連接。 簡而言之,在其生命週期的某個時候,第一個連接用於在客戶端和服務器之間安全地傳遞新的密碼參數。 然後可以使用這些參數從一開始就加密第二個連接,而無需等待完整的 TLS 握手完成。 這種方法稱為“會話恢復” 。
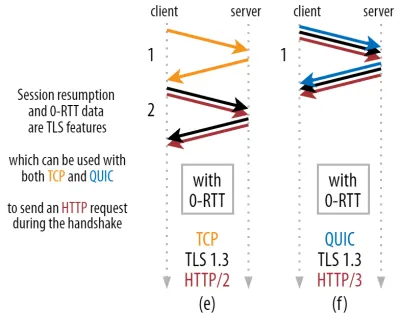
它允許進行強大的優化:我們現在可以安全地發送我們的第一個 HTTP 請求以及 QUIC/TLS 握手,節省另一個往返行程! 對於 TLS 1.3,這有效地消除了 TLS 握手的等待時間。 這種方法通常稱為 0-RTT(當然,HTTP 響應數據開始到達仍需要往返一次)。
再次,會話恢復和 0-RTT 都是我經常看到的被錯誤地解釋為 QUIC 特定功能的東西。 實際上,這些實際上是TLS 功能,在 TLS 1.2 中已經以某種形式存在,現在在 TLS 1.3 中完全成熟。
換句話說,正如您在下面的圖 3 中看到的那樣,我們也可以通過 TCP(以及 HTTP/2 甚至 HTTP/1.1)獲得這些功能的性能優勢! 我們看到,即使使用 0-RTT,QUIC 仍然只比運行最佳的 TCP + TLS 1.3 堆棧快一個往返。 QUIC 比圖 2 的 (a) 和圖 3 的 (f) 快三個往返的說法,正如我們所見,這並不公平。
最糟糕的是,當使用 0-RTT 時,由於安全性,QUIC 甚至不能真正使用獲得的往返行程。 要理解這一點,我們需要了解 TCP 握手存在的原因之一。 首先,它允許客戶端在向其發送任何更高層數據之前確保服務器在給定 IP 地址處實際可用。
其次,也是至關重要的一點,它允許服務器確保打開連接的客戶端實際上是他們在發送數據之前所說的身份和位置。 如果您還記得我們在第 1 部分中如何定義與 4 元組的連接,您就會知道客戶端主要由其 IP 地址標識。 這就是問題所在: IP 地址可以被欺騙!
假設攻擊者通過 QUIC 0-RTT 上的 HTTP 請求一個非常大的文件。 然而,他們欺騙了他們的 IP 地址,使得 0-RTT 請求看起來像是來自受害者的計算機。 如下圖 4 所示。 QUIC 服務器無法檢測 IP 是否被欺騙,因為這是它從該客戶端看到的第一個數據包。

如果服務器然後只是開始將大文件發送回欺騙 IP,它最終可能會使受害者的網絡帶寬過載(特別是如果攻擊者要並行執行許多這些虛假請求)。 請注意,受害者會丟棄 QUIC 響應,因為它不期望傳入數據,但這並不重要:他們的網絡仍然需要處理數據包!
這稱為反射或放大攻擊,它是黑客執行分佈式拒絕服務 (DDoS) 攻擊的一種重要方式。 請注意,當使用 0-RTT over TCP + TLS 時不會發生這種情況,正是因為 TCP 握手需要先完成,然後 0-RTT 請求甚至與 TLS 握手一起發送。
因此, QUIC 必須保守地回复 0-RTT 請求,限制它發送的響應數據量,直到客戶端被驗證為真正的客戶端而不是受害者。 對於 QUIC,此數據量已設置為從客戶端接收到的數據量的三倍。
換句話說,QUIC 的最大“放大係數”為 3,這被確定為性能有用性和安全風險之間可接受的權衡(特別是與放大係數超過 51,000 倍的某些事件相比)。 因為客戶端通常首先只發送一到兩個數據包,所以 QUIC 服務器的 0-RTT 回復將被限制在 4 到 6 KB (包括其他 QUIC 和 TLS 開銷!),這並不令人印象深刻。
此外,其他安全問題可能會導致例如“重放攻擊”,這會限制您可以執行的 HTTP 請求的類型。 例如,Cloudflare 僅允許 0-RTT 中不帶查詢參數的 HTTP GET 請求。 這些進一步限制了 0-RTT 的實用性。
幸運的是,QUIC 可以選擇讓它變得更好。 例如,服務器可以檢查 0-RTT 是否來自之前與其有效連接的 IP。 但是,這僅在客戶端保持在同一網絡上時才有效(在某種程度上限制了 QUIC 的連接遷移功能)。 而且即使它有效,QUIC 的響應仍然受到我們上面討論的擁塞控制器的慢啟動邏輯的限制; 因此,除了節省的一次往返行程之外,沒有額外的大幅速度提升。
你知道嗎?
有趣的是,QUIC 的三倍放大限制也適用於圖 2c 中的正常非 0-RTT 握手過程。 例如,如果服務器的 TLS 證書太大而無法容納 4 到 6 KB,這可能會成為問題。 在這種情況下,它必須被拆分,第二個塊必須等待第二次往返發送(在確認前幾個數據包進入後,表明客戶端的 IP 沒有被欺騙)。 在這種情況下, QUIC 的握手可能仍然需要兩次往返,等於 TCP + TLS! 這就是為什麼對於 QUIC 來說,證書壓縮等技術將格外重要。
你知道嗎?
某些高級設置可能足以緩解這些問題,從而使 0-RTT 更有用。 例如,服務器可以記住客戶端上次看到它時有多少可用帶寬,從而減少擁塞控制對重新連接(非欺騙)客戶端的緩慢啟動的限制。 這已經在學術界進行了調查,甚至在 QUIC 中提出了擴展來做到這一點。 幾家公司也已經在做這種事情來加速 TCP。
另一種選擇是讓客戶端發送超過一個或兩個數據包(例如,再發送 7 個帶有填充的數據包),因此即使在連接遷移之後,三倍的限制也會轉化為更有趣的 12 到 14 KB 響應。 我已經在我的一篇論文中寫到了這一點。
最後,(行為不端的)QUIC 服務器也可以故意增加三倍的限制,如果他們認為這樣做是安全的,或者他們不關心潛在的安全問題(畢竟,沒有協議警察阻止這一點)。
這是什麼意思呢?
QUIC 使用0-RTT 的更快連接設置實際上更像是一種微優化,而不是一項革命性的新功能。 與最先進的 TCP + TLS 1.3 設置相比,它最多可以節省一次往返。 在第一次往返中實際可以發送的數據量還受到許多安全考慮的限制。
因此,如果您的用戶在具有非常高延遲的網絡(例如,具有超過 200 毫秒 RTT 的衛星網絡)上,或者如果您通常不發送太多數據,則此功能將主要發揮作用。 後者的一些例子是大量緩存的網站,以及通過 API 和其他協議(如 DNS-over-QUIC)定期獲取小更新的單頁應用程序。 谷歌看到 QUIC 的 0-RTT 結果非常好的原因之一是它在其已經高度優化的搜索頁面上對其進行了測試,其中查詢響應非常小。
在其他情況下,您最多只能獲得幾十毫秒,如果您已經在使用 CDN(如果您關心性能,則應該這樣做!)。
連接遷移
通過保持現有連接完好無損,第三個性能特性使 QUIC 在網絡之間傳輸時更快。 雖然這確實有效,但這種類型的網絡更改並不經常發生,連接仍然需要重置其發送速率。
如第 1 部分所述,QUIC 的連接 ID (CID) 允許它在切換網絡時執行連接遷移。 我們通過一個客戶端從 Wi-Fi 網絡移動到 4G 並同時下載大文件來說明這一點。 在 TCP 上,下載可能必須中止,而對於 QUIC,它可能會繼續。
但是,首先要考慮這種情況實際發生的頻率。 您可能會認為,在建築物內的 Wi-Fi 接入點之間或在路上的蜂窩塔之間移動時也會發生這種情況。 然而,在這些設置中(如果正確完成),您的設備通常會保持其 IP 不變,因為無線基站之間的轉換是在較低的協議層完成的。 因此,它僅在您在完全不同的網絡之間移動時才會發生,我想說這種情況並不經常發生。
其次,我們可以詢問這是否也適用於除大文件下載和實時視頻會議和流媒體之外的其他用例。 如果您在切換網絡的確切時刻加載網頁,您可能確實需要重新請求一些(後來的)資源。
但是,加載頁面通常需要幾秒鐘的時間,因此與網絡切換同時發生的情況也不會很常見。 此外,對於這是一個緊迫問題的用例,其他緩解措施通常已經到位。 例如,提供大文件下載的服務器可以支持 HTTP 範圍請求以允許可恢復下載。
由於網絡 1 斷開和網絡 2 可用之間通常有一些重疊時間,因此視頻應用程序可以打開多個連接(每個網絡 1 個),在舊網絡完全消失之前同步它們。 用戶仍會注意到這個開關,但它不會完全放棄視頻源。
第三,不能保證新網絡的可用帶寬與舊網絡一樣多。 因此,即使概念連接保持不變,QUIC 服務器也不能僅僅保持高速發送數據。 相反,為了避免新網絡過載,它需要重置(或至少降低)發送速率並在擁塞控制器的慢啟動階段重新啟動。
因為這個初始發送速率通常太低而無法真正支持諸如視頻流之類的東西,所以即使在 QUIC 上,您也會看到一些質量損失或打嗝。 在某種程度上,連接遷移更多的是為了防止連接上下文混亂和服務器上的開銷,而不是提高性能。
你知道嗎?
請注意,正如上面針對 0-RTT 所討論的,我們可以設計一些高級技術來改進連接遷移。 例如,我們可以再次嘗試記住上次給定網絡上有多少可用帶寬,並嘗試更快地提升到該級別以進行新的遷移。 此外,我們可以設想不只是在網絡之間切換,而是同時使用兩者。 這個概念稱為多路徑,我們將在下面更詳細地討論它。
到目前為止,我們主要討論了主動連接遷移,即用戶在不同網絡之間移動。 但是,也存在被動連接遷移的情況,其中某個網絡本身會更改參數。 一個很好的例子是網絡地址轉換 (NAT) 重新綁定。 雖然對 NAT 的全面討論超出了本文的範圍,但它主要意味著連接的端口號可以在任何給定時間更改,而不會發出警告。 在大多數路由器中,UDP 比 TCP 更經常發生這種情況。
如果發生這種情況,QUIC CID 不會改變,並且大多數實現會假設用戶仍然在同一個物理網絡上,因此不會重置擁塞窗口或其他參數。 QUIC 還包括一些功能,例如 PING 和超時指示器,以防止這種情況發生,因為這通常發生在長空閒連接中。
我們在第 1 部分討論了 QUIC 不只是出於安全原因使用單個 CID。 相反,它會在執行主動遷移時更改 CID。 在實踐中,它甚至更複雜,因為客戶端和服務器都有單獨的 CID 列表(在 QUIC RFC 中稱為源和目標 CID)。 這在下面的圖 5 中進行了說明。
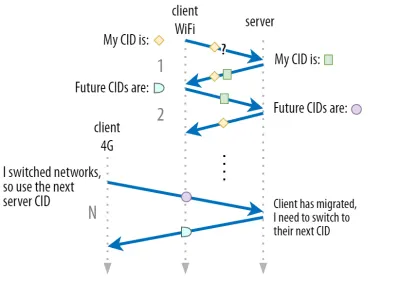
這樣做是為了允許每個端點選擇自己的 CID 格式和內容,這反過來對於允許高級路由和負載平衡邏輯至關重要。 通過連接遷移,負載均衡器不再僅僅查看 4 元組來識別連接並將其發送到正確的後端服務器。 但是,如果所有 QUIC 連接都使用隨機 CID,這將大大增加負載均衡器的內存需求,因為它需要存儲 CID 到後端服務器的映射。 此外,這仍然不適用於連接遷移,因為 CID 會更改為新的隨機值。
因此,部署在負載均衡器後面的 QUIC 後端服務器具有可預測的 CID 格式非常重要,這樣負載均衡器即使在遷移之後也可以從 CID 派生正確的後端服務器。 IETF 的提議文件中描述了一些用於執行此操作的選項。 為了使這一切成為可能,服務器需要能夠選擇他們自己的 CID,如果連接發起者(對於 QUIC 來說,它始終是客戶端)選擇了 CID,這是不可能的。 這就是 QUIC 中客戶端和服務器 CID 之間存在分裂的原因。
這是什麼意思呢?
因此,連接遷移是一種情境特徵。 例如,谷歌的初步測試顯示其用例的改進百分比很低。 許多 QUIC 實現還沒有實現這個特性。 即使是那些這樣做的人,通常也會將其限制為移動客戶端和應用程序,而不是它們的桌面等價物。 有些人甚至認為不需要該功能,因為在大多數情況下,使用 0-RTT 打開新連接應該具有相似的性能屬性。
儘管如此,根據您的用例或用戶資料,它可能會產生很大的影響。 如果您的網站或應用程序最常在移動中使用(例如,Uber 或 Google 地圖之類的),那麼您可能會比您的用戶通常坐在辦公桌後獲得更多好處。 同樣,如果您專注於持續互動(無論是視頻聊天、協作編輯還是遊戲),那麼與擁有新聞網站相比,您的最壞情況應該會有所改善。
去除線頭阻塞
第四個性能特性旨在通過減輕線頭 (HoL) 阻塞問題來使 QUIC 在具有大量丟包的網絡上更快。 雖然這在理論上是正確的,但我們將看到在實踐中這可能只會為網頁加載性能提供很小的好處。
不過,要理解這一點,我們首先需要繞道而行,談談流優先級和多路復用。
流優先級
如第 1 部分所述,單個 TCP 數據包丟失可能會延遲多個傳輸中資源的數據,因為 TCP 的字節流抽象將所有數據視為單個文件的一部分。 另一方面,QUIC 非常清楚有多個並發字節流,並且可以在每個流的基礎上處理丟失。 然而,正如我們也看到的那樣,這些流並沒有真正並行傳輸數據:相反,流數據被多路復用到單個連接上。 這種多路復用可以以許多不同的方式發生。
For example, for streams A, B, and C, we might see a packet sequence of ABCABCABCABCABCABCABCABC , where we change the active stream in each packet (let's call this round-robin). However, we might also see the opposite pattern of AAAAAAAABBBBBBBBCCCCCCCC , where each stream is completed in full before starting the next one (let's call this sequential). Of course, many other options are possible in between these extremes ( AAAABBCAAAAABBC… , AABBCCAABBCC… , ABABABCCCC… , etc.). The multiplexing scheme is dynamic and driven by an HTTP-level feature called stream prioritization (discussed later in this article).
As it turns out, which multiplexing scheme you choose can have a huge impact on website loading performance. You can see this in the video below, courtesy of Cloudflare, as every browser uses a different multiplexer. The reasons why are quite complex, and I've written several academic papers on the topic, as well as talked about it in a conference. Patrick Meenan, of Webpagetest fame, even has a three-hour tutorial on just this topic.
Luckily, we can explain the basics relatively easily. As you may know, some resources can be render blocking. This is the case for CSS files and for some JavaScript in the HTML head element. While these files are loading, the browser cannot paint the page (or, for example, execute new JavaScript).
What's more, CSS and JavaScript files need to be downloaded in full in order to be used (although they can often be incrementally parsed and compiled). As such, these resources need to be loaded as soon as possible, with the highest priority. Let's contemplate what would happen if A, B, and C were all render-blocking resources.
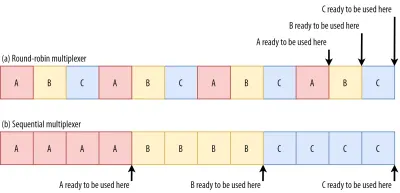
If we use a round-robin multiplexer (the top row in figure 6), we would actually delay each resource's total completion time, because they all need to share bandwidth with the others. Since we can only use them after they are fully loaded, this incurs a significant delay. However, if we multiplex them sequentially (the bottom row in figure 6), we would see that A and B complete much earlier (and can be used by the browser), while not actually delaying C's completion time.

However, that doesn't mean that sequential multiplexing is always the best, because some (mostly non-render-blocking) resources (such as HTML and progressive JPEGs) can actually be processed and used incrementally . In those (and some other) cases, it makes sense to use the first option (or at least something in between).
Still, for most web-page resources, it turns out that sequential multiplexing performs best . This is, for example, what Google Chrome is doing in the video above, while Internet Explorer is using the worst-case round-robin multiplexer.
Packet Loss Resilience
Now that we know that all streams aren't always active at the same time and that they can be multiplexed in different ways, we can consider what happens if we have packet loss. As explained in part 1, if one QUIC stream experiences packet loss, then other active streams can still be used (whereas, in TCP, all would be paused).
However, as we've just seen, having many concurrent active streams is typically not optimal for web performance, because it can delay some critical (render-blocking) resources, even without packet loss! We'd rather have just one or two active at the same time, using a sequential multiplexer. However, this reduces the impact of QUIC's HoL blocking removal.
Imagine, for example, that the sender could transmit 12 packets at a given time (see figure 7 below) — remember that this is limited by the congestion controller). If we fill all 12 of those packets with data for stream A (because it's high priority and render-blocking — think main.js ), then we would have only one active stream in that 12-packet window.
If one of those packets were to be lost, then QUIC would still end up fully HoL blocked because there would simply be no other streams it could process besides A : All of the data is for A , and so everything would still have to wait (we don't have B or C data to process), similar to TCP.

We see that we have a kind of contradiction: Sequential multiplexing ( AAAABBBBCCCC ) is typically better for web performance, but it doesn't allow us to take much advantage of QUIC's HoL blocking removal. Round-robin multiplexing ( ABCABCABCABC ) would be better against HoL blocking, but worse for web performance. As such, one best practice or optimization can end up undoing another .
而且情況會變得更糟。 Up until now, we've sort of assumed that individual packets get lost one at a time. However, this isn't always true, because packet loss on the Internet is often “bursty”, meaning that multiple packets often get lost at the same time .
As discussed above, an important reason for packet loss is that a network is overloaded with too much data, having to drop excess packets. This is why the congestion controller starts sending slowly. However, it then keeps growing its send rate until… there is packet loss!
Put differently, the mechanism that's intended to prevent overloading the network actually overloads the network (albeit in a controlled fashion). On most networks, that occurs after quite a while, when the send rate has increased to hundreds of packets per round trip. When those reach the limit of the network, several of them are typically dropped together, leading to the bursty loss patterns.
Did You Know?
This is one of the reasons why we wanted to move to using a single (TCP) connection with HTTP/2, rather than the 6 to 30 connections with HTTP/1.1. Because each individual connection ramps up its send rate in pretty much the same way, HTTP/1.1 could get a good speed-up at the start, but the connections could actually start causing massive packet loss for each other as they caused the network to become overloaded.
At the time, Chromium developers speculated that this behaviour caused most of the packet loss seen on the Internet. This is also one of the reasons why BBR has become an often used congestion-control algorithm, because it uses fluctuations in observed RTTs, rather than packet loss, to assess available bandwidth.
Did You Know?
Other causes of packet loss can lead to fewer or individual packets becoming lost (or unusable), especially on wireless networks. There, however, the losses are often detected at lower protocol layers and solved between two local entities (say, the smartphone and the 4G cellular tower), rather than by retransmissions between the client and the server. These usually don't lead to real end-to-end packet loss, but rather show up as variations in packet latency (or “jitter”) and reordered packet arrivals.
So, let's say we are using a per-packet round-robin multiplexer ( ABCABCABCABCABCABCABCABC… ) to get the most out of HoL blocking removal, and we get a bursty loss of just 4 packets. We see that this will always impact all 3 streams (see figure 8, middle row)! In this case, QUIC's HoL blocking removal provides no benefits, because all streams have to wait for their own retransmissions .
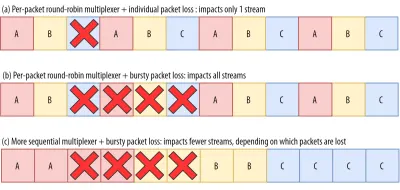
To lower the risk of multiple streams being affected by a lossy burst, we need to concatenate more data for each stream. For example, AABBCCAABBCCAABBCCAABBCC… is a small improvement, and AAAABBBBCCCCAAAABBBBCCCC… (see bottom row in figure 8 above) is even better. You can again see that a more sequential approach is better, even though that reduces the chances that we have multiple concurrent active streams.
In the end, predicting the actual impact of QUIC's HoL blocking removal is difficult, because it depends on the number of streams, the size and frequency of the loss bursts, how the stream data is actually used, etc. However, most results at this time indicate it will not help much for the use case of web-page loading, because there we typically want fewer concurrent streams.
If you want even more detail on this topic or just some concrete examples, please check out my in-depth article on HTTP HoL blocking.
Did You Know?
As with the previous sections, some advanced techniques can help us here. For example, modern congestion controllers use packet pacing. This means that they don't send, for example, 100 packets in a single burst, but rather spread them out over an entire RTT. This conceptually lowers the chances of overloading the network, and the QUIC Recovery RFC strongly recommends using it. Complementarily, some congestion-control algorithms such as BBR don't keep increasing their send rate until they cause packet loss, but rather back off before that (by looking at, for example, RTT fluctuations, because RTTs also rise when a network is becoming overloaded).
While these approaches lower the overall chances of packet loss, they don't necessarily lower its burstiness.
這是什麼意思呢?
While QUIC's HoL blocking removal means, in theory, that it (and HTTP/3) should perform better on lossy networks, in practice this depends on a lot of factors. Because the use case of web-page loading typically favours a more sequential multiplexing set-up, and because packet loss is unpredictable, this feature would, again, likely affect mainly the slowest 1% of users . However, this is still a very active area of research, and only time will tell.
Still, there are situations that might see more improvements. These are mostly outside of the typical use case of the first full page load — for example, when resources are not render blocking, when they can be processed incrementally, when streams are completely independent, or when less data is sent at the same time.
Examples include repeat visits on well-cached pages and background downloads and API calls in single-page apps. For example, Facebook has seen some benefits from HoL blocking removal when using HTTP/3 to load data in its native app.
UDP 和 TLS 性能
QUIC 和 HTTP/3 的第五個性能方面是關於它們在網絡上實際創建和發送數據包的效率和性能。 我們將看到 QUIC 對 UDP 和重度加密的使用可以使它比 TCP 慢一點(但情況正在改善)。
首先,我們已經討論過 QUIC 對 UDP 的使用更多的是關於靈活性和可部署性,而不是性能。 直到最近,通過 UDP 發送 QUIC 數據包通常比發送 TCP 數據包慢得多的事實更加證明了這一點。 這部分是因為這些協議通常在何處以及如何實施(參見下面的圖 9)。
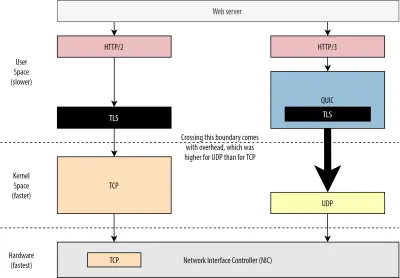
如上所述,TCP 和 UDP 通常直接在操作系統的快速內核中實現。 相比之下,TLS 和 QUIC 實現大多在較慢的用戶空間中(請注意,這對於 QUIC 來說並不是真正需要的——它主要是因為它更靈活而完成)。 這使得 QUIC 已經比 TCP 慢了一點。
此外,當從我們的用戶空間軟件(例如,瀏覽器和 Web 服務器)發送數據時,我們需要將這些數據傳遞給操作系統內核,然後使用 TCP 或 UDP 將其實際放到網絡上。 傳遞這些數據是使用內核 API(系統調用)完成的,每個 API 調用都會產生一定的開銷。 對於 TCP,這些開銷遠低於 UDP。
這主要是因為從歷史上看,TCP 的使用比 UDP 多得多。 因此,隨著時間的推移,許多優化被添加到 TCP 實現和內核 API 中,以將數據包發送和接收開銷降至最低。 許多網絡接口控制器 (NIC) 甚至具有用於 TCP 的內置硬件卸載功能。 然而,UDP 就沒有那麼幸運了,因為它更有限的使用並不能證明對額外優化的投資是合理的。 幸運的是,在過去五年中,這種情況發生了變化,大多數操作系統也為 UDP 添加了優化選項。
其次,QUIC 有很多開銷,因為它單獨加密每個數據包。 這比在 TCP 上使用 TLS 慢,因為在那裡您可以以塊的形式加密數據包(一次最多大約 16 KB 或 11 個數據包),這樣效率更高。 這是在 QUIC 中做出的有意識的權衡,因為批量加密會導致其自身形式的 HoL 阻塞。
與第一點不同,我們可以添加額外的 API 以使 UDP(以及因此 QUIC)更快,在這裡,QUIC 總是比 TCP + TLS 具有固有的劣勢。 然而,這在實踐中也很容易管理,例如優化的加密庫和允許批量加密 QUIC 數據包標頭的巧妙方法。
結果,雖然谷歌最早的 QUIC 版本仍然比 TCP + TLS 慢兩倍,但從那以後情況肯定有所改善。 例如,在最近的測試中,微軟經過高度優化的 QUIC 堆棧能夠達到 7.85 Gbps,而在同一系統上 TCP + TLS 的速度為 11.85 Gbps(因此,在這裡,QUIC 的速度大約是 TCP + TLS 的 66%)。
這與最近的 Windows 更新有關,它使 UDP 更快(為了全面比較,該系統上的 UDP 吞吐量為 19.5 Gbps)。 谷歌 QUIC 堆棧的最優化版本目前比 TCP + TLS 慢 20% 左右。 Fastly 較早在一個不太先進的系統上進行的測試甚至聲稱具有相同的性能(約 450 Mbps),這表明 QUIC 絕對可以與 TCP 競爭,具體取決於用例。
然而,即使 QUIC 的速度是 TCP + TLS 的兩倍,它也不是那麼糟糕。 首先,QUIC 和 TCP + TLS 處理通常不是服務器上發生的最繁重的事情,因為其他邏輯(例如,HTTP、緩存、代理等)也需要執行。 因此,您實際上不需要兩倍的服務器來運行 QUIC (不過,尚不清楚它對真實數據中心的影響有多大,因為沒有一家大公司發布過這方面的數據)。
其次,未來仍有很多優化 QUIC 實現的機會。 例如,隨著時間的推移,一些 QUIC 實現將(部分)移動到操作系統內核(很像 TCP)或繞過它(有些已經這樣做,如 MsQuic 和 Quant)。 我們還可以期待 QUIC 特定的硬件可用。
儘管如此,仍可能存在一些 TCP + TLS 仍將是首選選項的用例。 例如,Netflix 表示它可能不會很快遷移到 QUIC,因為它已經大量投資於自定義 FreeBSD 設置以通過 TCP + TLS 流式傳輸其視頻。
同樣,Facebook 表示 QUIC 可能主要用於最終用戶和 CDN 的邊緣之間,但不會在數據中心之間或邊緣節點和源服務器之間使用,因為它的開銷更大。 一般來說,非常高帶寬的場景可能會繼續偏愛 TCP + TLS,尤其是在未來幾年。
你知道嗎?
優化網絡堆棧是一個深刻的技術兔子洞,上面的內容只是觸及表面(並遺漏了很多細微差別)。 如果您足夠勇敢,或者如果您想知道GRO/GSO、SO_TXTIME、內核繞過以及sendmmsg()和recvmmsg()含義,我也可以推荐一些 Cloudflare 和 Fastly 的關於優化 QUIC 的優秀文章作為 Microsoft 的廣泛代碼演練和 Cisco 的深入討論。 最後,一位谷歌工程師做了一個非常有趣的主題演講,關於隨著時間的推移優化他們的 QUIC 實現。
這是什麼意思呢?
QUIC 對 UDP 和 TLS 協議的特殊使用在歷史上使其比 TCP + TLS 慢得多。 然而,隨著時間的推移,已經做出了一些改進(並將繼續實施),從而在一定程度上縮小了差距。 不過,在網頁加載的典型用例中,您可能不會注意到這些差異,但如果您維護大型服務器場,它們可能會讓您頭疼。
HTTP/3 特性
到目前為止,我們主要討論了 QUIC 與 TCP 的新性能特性。 但是,HTTP/3 與 HTTP/2 的區別是什麼? 正如第 1 部分中所討論的, HTTP/3 實際上是 HTTP/2-over-QUIC ,因此,新版本中沒有引入真正的、大的新特性。 這與從 HTTP/1.1 到 HTTP/2 的轉變不同,後者更大,並引入了諸如標頭壓縮、流優先級和服務器推送等新功能。 這些特性都仍然在 HTTP/3 中,但它們在底層實現的方式存在一些重要差異。
這主要是因為 QUIC 移除 HoL 阻塞的工作原理。 正如我們所討論的,流 B 的丟失不再意味著流 A 和 C 將不得不等待 B 的重新傳輸,就像他們通過 TCP 所做的那樣。 因此,如果 A、B 和 C 各自按該順序發送一個 QUIC 數據包,則它們的數據很可能會以 A、C、B 的形式傳送到瀏覽器(並由瀏覽器處理)! 換句話說,與 TCP 不同,QUIC不再在不同的流中完全排序!
這是 HTTP/2 的一個問題,它在設計許多特性時真正依賴於 TCP 的嚴格排序,這些特性使用散佈在數據塊中的特殊控制消息。 在 QUIC 中,這些控制消息可能以任何順序到達(並被應用),甚至可能使功能與預期相反! 同樣,本文不需要技術細節,但本文的前半部分應該讓您了解這會變得多麼愚蠢複雜。
因此,必須針對 HTTP/3 更改功能的內部機制和實現。 一個具體的例子是HTTP 標頭壓縮,它降低了重複的大型 HTTP 標頭(例如,cookie 和用戶代理字符串)的開銷。 在 HTTP/2 中,這是使用 HPACK 設置完成的,而對於 HTTP/3,這已被重新設計為更複雜的 QPACK。 兩個系統都提供相同的功能(即標頭壓縮),但方式完全不同。 可以在 Litespeed 博客上找到有關此主題的一些出色的深入技術討論和圖表。
驅動流多路復用邏輯的優先級特性也是如此,我們在上面已經簡要討論過。 在 HTTP/2 中,這是使用複雜的“依賴樹”設置實現的,該設置明確地嘗試對所有頁面資源及其相互關係進行建模(更多信息請參見“HTTP 資源優先級的終極指南”)。 直接在 QUIC 上使用這個系統會導致一些潛在的非常錯誤的樹佈局,因為將每個資源添加到樹中將是一個單獨的控制消息。
此外,這種方法被證明是不必要的複雜,導致許多實施錯誤和效率低下以及許多服務器上的性能不佳。 這兩個問題都導致以更簡單的方式為 HTTP/3 重新設計優先級系統。 這種更直接的設置使得一些高級場景難以或不可能強制執行(例如,在單個連接上代理來自多個客戶端的流量),但仍然為網頁加載優化提供了廣泛的選項。
同樣,這兩種方法提供相同的基本功能(引導流多路復用),但希望 HTTP/3 更簡單的設置將減少實現錯誤。
最後,還有服務器推送。 此功能允許服務器發送 HTTP 響應,而無需先等待明確的請求。 從理論上講,這可以帶來出色的性能提升。 然而,在實踐中,事實證明它很難正確使用且實施不一致。 因此,它甚至可能會從 Google Chrome 中刪除。
儘管如此,它仍然被定義為 HTTP/3 中的一個特性(儘管很少有實現支持它)。 雖然它的內部工作方式沒有像前兩個功能那樣發生很大變化,但它也已經適應了 QUIC 的非確定性排序。 但遺憾的是,這對於解決其一些長期存在的問題無濟於事。
這是什麼意思呢?
正如我們之前所說,HTTP/3 的大部分潛力來自底層的 QUIC,而不是 HTTP/3 本身。 雖然該協議的內部實現與 HTTP/2非常不同,但它的高級性能特性以及它們可以和應該如何使用都保持不變。
值得關注的未來發展
在本系列文章中,我經常強調更快的演進和更高的靈活性是 QUIC(以及擴展的 HTTP/3)的核心方面。 因此,人們已經在研究協議的新擴展和應用也就不足為奇了。 下面列出的是您可能會在某處遇到的主要問題:
前向糾錯
再次,該技術的目的是提高 QUIC 對丟包的恢復能力。 它通過發送數據的冗余副本來做到這一點(儘管經過巧妙的編碼和壓縮,因此它們沒有那麼大)。 然後,如果數據包丟失但冗餘數據到達,則不再需要重傳。
這最初是 Google QUIC 的一部分(也是人們說 QUIC 可以很好地防止丟包的原因之一),但它沒有包含在標準化的 QUIC 版本 1 中,因為它的性能影響尚未得到證實。 不過,研究人員現在正在使用它進行積極的實驗,您可以使用 PQUIC-FEC 下載實驗應用程序幫助他們。多路徑 QUIC
我們之前已經討論過連接遷移以及從 Wi-Fi 遷移到蜂窩網絡時它如何提供幫助。 但是,這是否也意味著我們可以同時使用 Wi-Fi 和蜂窩網絡? 同時使用這兩個網絡將為我們提供更多可用帶寬和更高的魯棒性! 這是多路徑背後的主要概念。
這也是谷歌嘗試過的東西,但由於其固有的複雜性,它沒有進入 QUIC 版本 1。 然而,研究人員已經展示了它的巨大潛力,它可能會成為 QUIC 版本 2。請注意,TCP 多路徑也存在,但它已經花了將近十年的時間才變得實用。QUIC 和 HTTP/3 上的不可靠數據
正如我們所見,QUIC 是一個完全可靠的協議。 但是,由於它運行在不可靠的 UDP 上,我們可以在 QUIC 中添加一個功能來發送不可靠的數據。 這在建議的數據報擴展中進行了概述。 你當然不想用它來發送網頁資源,但它可能對遊戲和實時視頻流等事情很方便。 這樣,用戶將獲得 UDP 的所有好處,但具有 QUIC 級加密和(可選)擁塞控制。網絡傳輸
瀏覽器不會將 TCP 或 UDP 直接暴露給 JavaScript,主要是出於安全考慮。 相反,我們必須依賴 HTTP 級別的 API,例如 Fetch 以及更靈活的 WebSocket 和 WebRTC 協議。 這一系列選項中最新的稱為 WebTransport,它主要允許您以更底層的方式使用 HTTP/3(以及擴展的 QUIC)(儘管如果需要它也可以回退到 TCP 和 HTTP/2 )。
至關重要的是,它將包括通過 HTTP/3 使用不可靠數據的能力(請參閱前一點),這將使諸如游戲之類的事情在瀏覽器中更容易實現。 對於普通的 (JSON) API 調用,您當然仍會使用 Fetch,它還會在可能的情況下自動使用 HTTP/3。 WebTransport 目前仍在大量討論中,因此尚不清楚它最終會是什麼樣子。 在這些瀏覽器中,目前只有 Chromium 正在開發一個公開的概念驗證實現。DASH 和 HLS 視頻流
對於非實時視頻(想想 YouTube 和 Netflix),瀏覽器通常使用基於 HTTP 的動態自適應流式傳輸 (DASH) 或 HTTP 實時流式傳輸 (HLS) 協議。 兩者基本上都意味著您將視頻編碼為更小的塊(2 到 10 秒)和不同的質量級別(720p、1080p、4K 等)。
在運行時,瀏覽器估計您的網絡可以處理的最高質量(或給定用例的最佳質量),並通過 HTTP 從服務器請求相關文件。 因為瀏覽器不能直接訪問 TCP 堆棧(通常在內核中實現),所以它偶爾會在這些估計中犯一些錯誤,或者需要一段時間才能對不斷變化的網絡條件做出反應(導致視頻停頓) .
因為 QUIC 是作為瀏覽器的一部分實現的,所以可以通過讓流估計器訪問低級協議信息(例如丟失率、帶寬估計等)來大大改善這一點。 其他研究人員也一直在嘗試將可靠和不可靠的數據混合用於視頻流,並取得了一些有希望的結果。HTTP/3 以外的協議
由於 QUIC 是一種通用傳輸協議,我們可以預期現在在 TCP 上運行的許多應用層協議也將在 QUIC 之上運行。 一些正在進行的工作包括 DNS-over-QUIC、SMB-over-QUIC,甚至 SSH-over-QUIC。 因為這些協議通常具有與 HTTP 和網頁加載非常不同的要求,所以我們討論過的 QUIC 的性能改進可能對這些協議更有效。
這是什麼意思呢?
QUIC 版本 1只是一個開始。 谷歌早先嘗試過的許多面向性能的高級功能並沒有進入第一次迭代。 然而,目標是快速發展協議,以高頻率引入新的擴展和特性。 因此,隨著時間的推移,QUIC(和 HTTP/3)應該明顯比 TCP(和 HTTP/2)更快、更靈活。
結論
在本系列的第二部分中,我們討論了HTTP/3 尤其是 QUIC 的許多不同性能特性和方面。 我們已經看到,雖然這些功能中的大多數看起來非常有影響力,但實際上,在我們一直在考慮的網頁加載用例中,它們可能對普通用戶沒有那麼大的作用。
例如,我們已經看到QUIC使用UDP並不意味著它可以突然使用比TCP更多的帶寬,也不意味著它可以更快地下載你的資源。 經常受到稱讚的 0-RTT 功能實際上是一種微優化,可以為您節省一次往返,其中您可以發送大約 5 KB(在最壞的情況下)。
如果出現突發數據包丟失或加載渲染阻塞資源時,HoL 阻塞刪除效果不佳。 連接遷移是高度情境化的,HTTP/3 沒有任何重要的新功能可以使其比 HTTP/2 更快。
因此,您可能希望我建議您跳過 HTTP/3 和 QUIC。 為什麼要打擾,對吧? 但是,我絕對不會做這樣的事情! 儘管這些新協議可能對快速(城市)網絡上的用戶沒有多大幫助,但新功能確實有可能對高度移動的用戶和慢速網絡上的人產生巨大影響。
即使在像我自己的比利時這樣的西方市場,我們通常擁有快速設備並可以訪問高速蜂窩網絡,這些情況也會影響 1% 甚至 10% 的用戶群,具體取決於您的產品。 一個例子是火車上的某人拼命地試圖在您的網站上查找一條關鍵信息,但必須等待 45 秒才能加載。 我當然知道我一直處於這種情況,希望有人部署了 QUIC 來讓我擺脫困境。
但是,還有其他國家和地區的情況要糟糕得多。 在那裡,普通用戶可能看起來更像比利時最慢的 10%,而最慢的 1% 可能根本看不到加載的頁面。 在世界許多地方,Web 性能是一個可訪問性和包容性問題。
這就是為什麼我們永遠不應該只在我們自己的硬件上測試我們的頁面(還要使用像 Webpagetest 這樣的服務),也是為什麼你絕對應該部署 QUIC 和 HTTP/3的原因。 特別是如果您的用戶經常在移動或不太可能訪問快速蜂窩網絡,這些新協議可能會帶來不同的世界,即使您在有線 MacBook Pro 上沒有註意到太多。 有關更多詳細信息,我強烈推薦 Fastly 關於該問題的帖子。
如果這不能完全說服您,那麼請考慮一下 QUIC 和 HTTP/3 將在未來幾年繼續發展並變得更快。 獲得一些協議的早期經驗將在未來獲得回報,讓您盡快獲得新功能的好處。 此外,QUIC 在後台執行安全和隱私最佳實踐,這使世界各地的所有用戶受益。
終於信服了? 然後繼續閱讀本系列的第 3 部分,了解如何在實踐中使用新協議。
- 第 1 部分:HTTP/3 歷史和核心概念
本文主要針對 HTTP/3 和一般協議的新手,主要討論基礎知識。 - 第 2 部分:HTTP/3 性能特性
這一個更深入和技術。 已經了解基礎知識的人可以從這裡開始。 - 第 3 部分:實用的 HTTP/3 部署選項
本系列的第三篇文章解釋了自己部署和測試 HTTP/3 所涉及的挑戰。 它詳細說明瞭如何以及是否應該更改您的網頁和資源。