
如何在機器學習中實現分類?
已發表: 2021-03-12機器學習在各個領域的應用在過去幾年中突飛猛進,而且還在繼續。 機器學習模型最受歡迎的任務之一是識別對象並將它們分成指定的類。
這是分類方法,是機器學習最流行的應用之一。 分類用於將大量數據分成一組離散值,這些離散值可能是二進制的,例如 0/1、是/否,也可能是多類的,例如動物、汽車、鳥類等。
在接下來的文章中,我們將了解機器學習中分類的概念,所涉及的數據類型,並了解機器學習中用於對多個數據進行分類的一些最流行的分類算法。
目錄
什麼是監督學習?
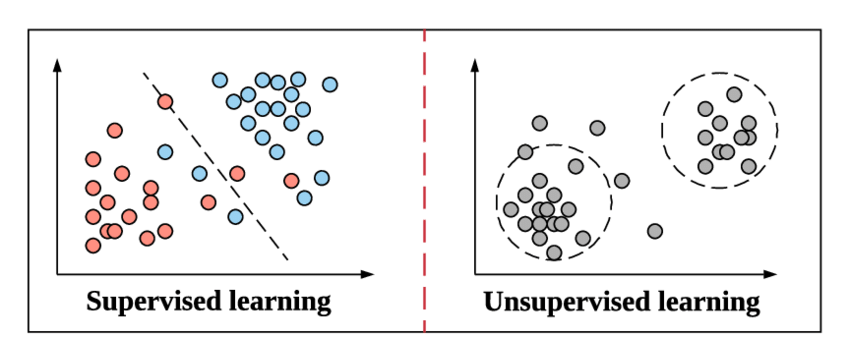
當我們準備深入了解分類及其類型的概念時,讓我們快速了解監督學習的含義以及它與機器學習中其他無監督學習方法的區別。
讓我們從高中物理課上舉一個簡單的例子來理解這一點。 假設有一個涉及新方法的簡單問題。 如果我們遇到一個必須使用相同方法解決的問題,我們難道不都參考使用相同方法的示例問題並嘗試解決它嗎? 一旦我們對那個方法有信心,我們就不需要再次引用它並繼續解決它。
資源

這與監督學習在機器學習中的工作方式相同。 它通過例子來學習。 為了讓它更簡單,在監督學習中,整個數據都被提供了它們相應的標籤,因此在訓練過程中,機器學習模型看起來將其特定數據的輸出與相同數據的真實輸出進行比較,並嘗試最小化預測標籤值和真實標籤值之間的誤差。
我們將在本文中介紹的分類算法遵循這種監督學習方法,例如垃圾郵件檢測和對象識別。
無監督學習是上面的一個步驟,其中數據不帶有標籤。 從數據中導出模式並給出輸出取決於機器學習模型的責任和效率。 聚類算法遵循這種無監督學習方法。
什麼是分類?
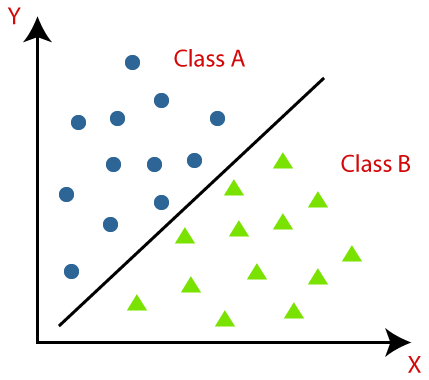
分類被定義為識別、理解並將對像或數據分組到預設的類別中。 通過在機器學習模型的訓練過程之前對數據進行分類,我們可以使用各種分類算法將數據分類為幾個類別。 與回歸不同,分類問題是輸出變量是一個類別,例如“是”或“否”或“疾病”或“無疾病”。
在大多數機器學習問題中,一旦將數據集加載到程序中,在訓練之前,將數據集分成固定比例的訓練集和測試集(通常為 70% 的訓練集和 30% 的測試集)。 這種分裂過程允許模型執行反向傳播,其中它試圖通過幾個數學近似來糾正其預測值與真實值的誤差。
同樣,在我們開始分類之前,會創建訓練數據集。 分類算法對其進行訓練,同時在每次迭代(稱為一個時期)對測試數據集進行測試。
資源
最常見的分類算法應用程序之一是過濾電子郵件,以確定它們是“垃圾郵件”還是“非垃圾郵件”。 簡而言之,我們可以將機器學習中的分類定義為“模式識別”的一種形式,其中這些應用於訓練數據的算法用於從數據中提取多種模式(例如相似的單詞或數字序列、情緒等.)。
分類是將給定的一組數據分類為類的過程; 它可以在結構化或非結構化數據上執行。 它首先預測給定數據點的類別。 這些類也稱為輸出變量、目標標籤等。一些算法具有內置的數學函數來近似從輸入數據點變量到輸出目標類的映射函數。 分類的主要目標是確定新數據將屬於哪個類/類別。
機器學習中的分類算法類型
根據應用分類算法的數據類型,有兩大類算法,線性模型和非線性模型。
線性模型
- 邏輯回歸
- 支持向量機 (SVM)
非線性模型
- K-最近鄰(KNN)分類
- 內核支持向量機
- 樸素貝葉斯分類
- 決策樹分類
- 隨機森林分類
在本文中,我們將簡要介紹上述每種算法背後的概念。
機器學習中分類模型的評估
在我們進入上述這些算法的概念之前,我們必須了解如何評估基於這些算法構建的機器學習模型。 評估我們的模型在訓練集和測試集上的準確性至關重要。
交叉熵損失或對數損失
這是我們將用於評估輸出在 0 到 1 之間的分類器性能的第一種類型的損失函數。這主要用於二元分類模型。 對數損失公式由下式給出,
對數損失 = -((1 – y) * log(1 – yhat) + y * log(yhat))
其中,這是預測值,y 是實際值。
混淆矩陣
混淆矩陣是一個 NXN 矩陣,其中 N 是被預測的類數。 混淆矩陣為我們提供了一個矩陣/表格作為輸出,並描述了模型的性能。 它由矩陣形式的預測結果組成,我們可以從中得出幾個性能指標來評估分類模型。 它的形式是,
| 實際正面 | 實際負數 | |
| 預測陽性 | 真陽性 | 假陽性 |
| 預測負數 | 假陰性 | 真陰性 |
下面給出了可以從上表中得出的一些性能指標。
1.Accuracy——正確預測總數的比例。
2. 陽性預測值或精度——正確識別的陽性病例的比例。
3. 負預測值——正確識別的負例的比例。
4. 敏感性或召回率——正確識別的實際陽性病例的比例。
5. 特異性——被正確識別的實際負面案例的比例。
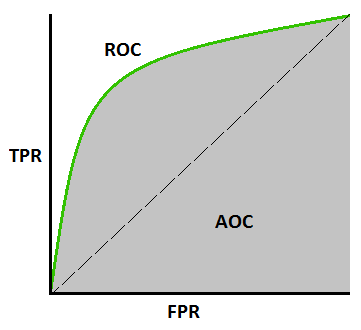
AUC-ROC 曲線 –
這是評估任何機器學習模型的另一個重要曲線指標。 ROC曲線代表接收器操作特徵曲線,AUC代表曲線下面積。 ROC 曲線是用 TPR 和 FPR 繪製的,其中 TPR(真陽性率)在 Y 軸上,FPR(假陽性率)在 X 軸上。 它顯示了分類模型在不同閾值下的性能。
資源
1. 邏輯回歸
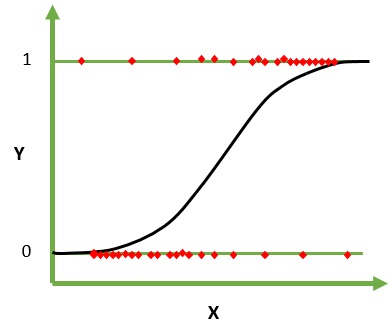
邏輯回歸是一種用於分類的機器學習算法。 在該算法中,描述單個試驗的可能結果的概率使用邏輯函數建模。 它假設輸入變量是數字的並且具有高斯(鐘形曲線)分佈。
邏輯函數,也稱為 sigmoid 函數,最初被統計學家用來描述生態學中的人口增長。 sigmoid 函數是一種數學函數,用於將預測值映射到概率。 Logistic 回歸具有 S 形曲線,可以取 0 到 1 之間的值,但從不完全處於這些限制。
資源

邏輯回歸主要用於預測二元結果,例如是/否和通過/失敗。 自變量可以是分類變量或數值變量,但因變量始終是分類變量。 Logistic 回歸的公式由下式給出,
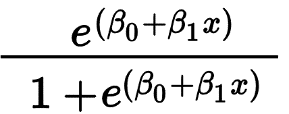
其中 e 表示 S 形曲線,其值介於 0 和 1 之間。
2. 支持向量機
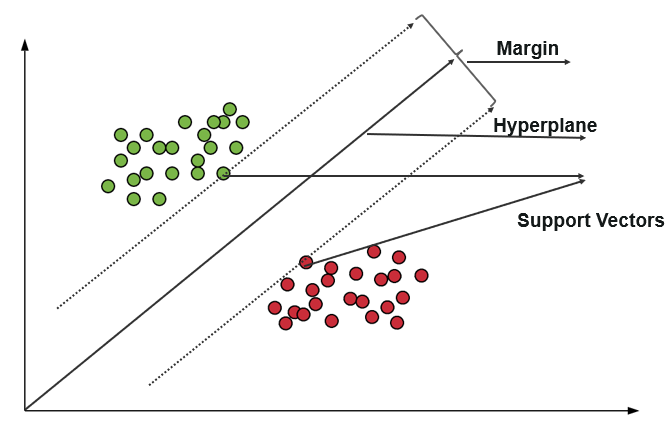
支持向量機 (SVM) 使用算法在極性程度內訓練和分類數據,使其達到超出 X/Y 預測的程度。 在 SVM 中,用於分隔類的線稱為超平面。 超平面兩側最靠近超平面的數據點稱為支持向量,用於繪製邊界線。
這種分類中的支持向量機將訓練數據表示為空間中的數據點,其中許多類別被分成超平麵類別。 當一個新點進入時,通過預測它們屬於哪個類別並屬於特定空間來對其進行分類。
資源
支持向量機的主要目的是最大化兩個支持向量之間的邊距。
加入來自世界頂級大學的ML在線課程——碩士、高級管理人員研究生課程和 ML 和 AI 高級證書課程,以加快您的職業生涯。
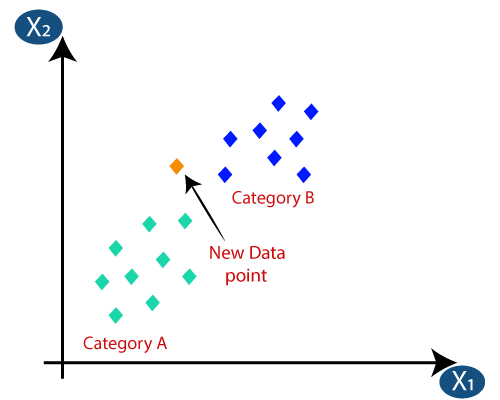
3. K-最近鄰(KNN)分類
KNN分類是分類中最簡單的算法之一,但因其高效易用而被高度使用。 在這種方法中,整個數據集最初存儲在機器中。 然後,選擇一個值 - k,它表示鄰居的數量。 這樣,當一個新的數據點被添加到數據集中時,它會將 k 個最近鄰居的類標籤的多數票投給該新數據點。 通過這次投票,新數據點被添加到投票最高的特定類中。
資源
4. 內核支持向量機
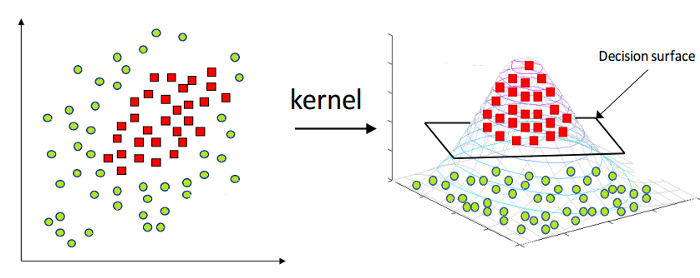
如上所述,線性支持向量機本質上只能應用於線性數據。 然而,世界上所有的數據都不是線性可分的。 因此,我們需要開發一個支持向量機來解釋也是非線性可分的數據。 這裡出現了內核技巧,也稱為內核支持向量機或內核 SVM。
在 Kernel SVM 中,我們選擇 RBF 或 Gaussian Kernel 等內核。 所有數據點都映射到更高的維度,在那裡它們成為線性可分的。 通過這種方式,我們可以在數據集的不同類別之間創建決策邊界。
資源
因此,通過這種方式,利用支持向量機的基本概念,我們可以設計一個非線性的核 SVM。
5.樸素貝葉斯分類
樸素貝葉斯分類的根源屬於貝葉斯定理,假設數據集的所有自變量(特徵)都是獨立的。 它們在預測結果方面具有同等重要性。 貝葉斯定理的這個假設給出了名稱——“樸素”。 它用於各種任務,例如垃圾郵件過濾和其他文本分類領域。 樸素貝葉斯計算數據點是否屬於某個類別的可能性。
樸素貝葉斯分類的公式由下式給出,
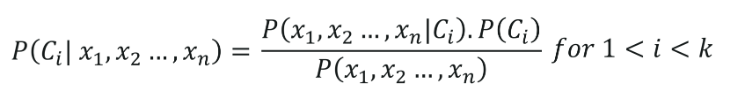
6.決策樹分類
決策樹是一種監督學習算法,非常適合分類問題,因為它可以在精確的級別上對類進行排序。 它以流程圖的形式運行,在其中分離每個級別的數據點。 最終的結構看起來像一棵有節點和葉子的樹。

資源
一個決策節點將有兩個或多個分支,一個葉子代表一個分類或決策。 在上面的決策樹示例中,通過提出幾個問題,創建了一個流程圖,這有助於我們解決預測是否上市的簡單問題。
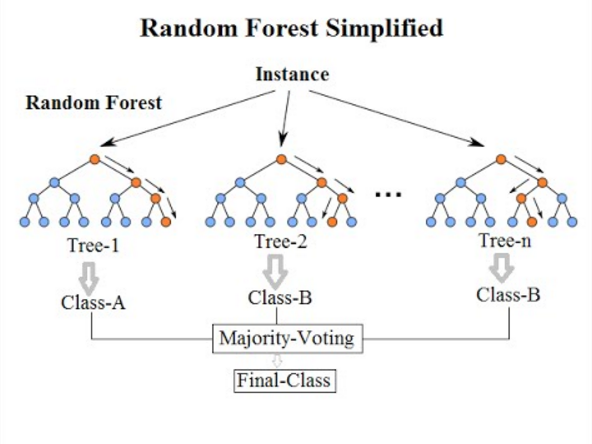
7. 隨機森林分類
來到這個列表的最後一個分類算法,隨機森林只是決策樹算法的擴展。 隨機森林是一種具有多個決策樹的集成學習方法。 它的工作方式與決策樹相同。
資源
隨機森林算法是對現有決策樹算法的改進,它存在“過度擬合”的主要問題。 與決策樹算法相比,它也被認為更快、更準確。
另請閱讀:機器學習項目的想法和主題
結論
因此,在這篇關於機器學習分類方法的文章中,我們了解了分類和監督學習的基礎知識、分類模型的類型和評估指標,最後總結了所有最常用的機器學習分類模型。
如果您有興趣了解有關機器學習的更多信息,請查看 IIIT-B 和 upGrad 的機器學習和 AI 執行 PG 計劃,該計劃專為工作專業人士設計,提供 450 多個小時的嚴格培訓、30 多個案例研究和作業、IIIT -B 校友身份,5 個以上實用的實踐頂點項目和頂級公司的工作協助。
Q1。 機器學習中最常用的算法是什麼?
機器學習採用了許多不同的算法,大致可以分為三大類——監督學習算法、無監督學習算法和強化學習算法。 現在,為了縮小和命名一些最常用的算法,必須提到的是線性回歸、邏輯回歸、SVM、決策樹、隨機森林算法、kNN、樸素貝葉斯理論、K-Means、降維、和梯度提升算法。 XGBoost、GBM、LightGBM 和 CatBoost 算法在梯度提升算法中值得特別提及。 這些算法可用於解決幾乎任何類型的數據問題。
Q2。 什麼是機器學習中的分類和回歸?
分類和回歸算法都廣泛用於機器學習。 但是,它們之間存在許多差異,最終決定了它們的用途或目的。 主要區別在於,雖然分類算法用於分類或預測離散值,如男性-女性或真假,但回歸算法用於預測非離散、連續值,如工資、年齡、價格等。決策樹,隨機森林、核支持向量機和邏輯回歸是一些最常見的分類算法,而簡單和多元線性回歸、支持向量回歸、多項式回歸和決策樹回歸是機器學習中最流行的一些回歸算法。
Q3。 學習機器學習的先決條件是什麼?
要開始機器學習,您無需成為精通的數學家或專家級程序員。 然而,鑑於該領域的廣闊,當您即將開始您的機器學習之旅時,您可能會感到害怕。 在這種情況下,了解先決條件可以幫助您順利開始。 先決條件本質上是理解機器學習概念所需的核心技能。 因此,首先,確保您學習如何使用 Python 進行編碼。 接下來,對統計學和數學,尤其是線性代數和多元微積分的基本了解,將是一個額外的優勢。