
如何為機器學習選擇特徵選擇方法
已發表: 2021-06-22目錄
功能選擇介紹
機器學習模型使用了許多特徵,其中只有少數是重要的。 如果使用不必要的特徵來訓練數據模型,則模型的準確性會降低。 此外,模型的複雜性增加,泛化能力下降,導致模型有偏差。 “有時越少越好”這句話與機器學習的概念很吻合。 許多用戶都面臨過這個問題,他們發現很難從他們的數據中識別出相關的特徵集,而忽略所有不相關的特徵集。 不太重要的特徵被稱為是因為它們對目標變量沒有貢獻。
因此,機器學習中的重要過程之一是特徵選擇。 目標是為機器學習模型的開發選擇最好的特徵集。 特徵選擇對模型的性能有巨大的影響。 除了數據清理,特徵選擇應該是模型設計的第一步。
機器學習中的特徵選擇可以概括為
- 自動或手動選擇對預測變量或輸出貢獻最大的那些特徵。
- 不相關特徵的存在可能會導致模型的準確性降低,因為它會從不相關的特徵中學習。
特徵選擇的好處
- 減少數據的過度擬合:更少的數據會導致更少的冗餘。 因此,對噪聲做出決策的機會較少。
- 提高模型的準確性:誤導數據的可能性較小,提高了模型的準確性。
- 訓練時間減少:去除不相關的特徵會降低算法複雜度,因為只存在較少的數據點。 因此,算法訓練得更快。
- 模型的複雜性隨著對數據的更好解釋而降低。
有監督和無監督的特徵選擇方法
特徵選擇算法的主要目標是為模型的開發選擇一組最佳特徵。 機器學習中的特徵選擇方法可以分為監督方法和無監督方法。
- 監督方法:監督方法用於從標記數據中選擇特徵,也用於相關特徵的分類。 因此,所建立的模型的效率有所提高。
- 無監督方法:這種特徵選擇方法用於未標記的數據。
監督方法下的方法列表
機器學習中特徵選擇的監督方法可以分為

1. 包裝方法
這種類型的特徵選擇算法基於算法的結果來評估特徵的性能過程。 也稱為貪心算法,它使用特徵子集迭代地訓練算法。 停止標准通常由訓練算法的人定義。 模型中特徵的添加和刪除是基於模型的先前訓練進行的。 在這種搜索策略中可以應用任何類型的學習算法。 與過濾方法相比,這些模型更準確。
Wrapper 方法中使用的技術有:
- 前向選擇:前向選擇過程是一個迭代過程,在每次迭代後添加改進模型的新特徵。 它從一組空的功能開始。 迭代將繼續並停止,直到添加不會進一步提高模型性能的特徵。
- 向後選擇/消除:該過程是一個迭代過程,從所有特徵開始。 每次迭代後,從初始特徵集中移除最不重要的特徵。 迭代的停止標準是模型的性能沒有隨著特徵的移除而進一步提高。 這些算法在 mlxtend 包中實現。
- 雙向消除:在雙向消除方法中同時應用前向選擇和後向消除技術兩種方法,以達到一個獨特的解決方案。
- 詳盡的特徵選擇:也稱為評估特徵子集的蠻力方法。 創建了一組可能的子集,並為每個子集構建了一個學習算法。 選擇其模型提供最佳性能的子集。
- 遞歸特徵消除(RFE):該方法被稱為貪心方法,因為它通過遞歸地考慮越來越小的特徵集來選擇特徵。 一組初始特徵用於訓練估計器,並使用 feature_importance_attribute 獲得它們的重要性。 然後刪除最不重要的特徵,只留下所需數量的特徵。 這些算法在 scikit-learn 包中實現。
圖 4:展示遞歸特徵消除技術的代碼示例
2. 嵌入式方法
機器學習中的嵌入式特徵選擇方法通過包含特徵交互並保持合理的計算成本,相對於過濾器和包裝器方法具有一定的優勢。 嵌入式方法中使用的技術有:
- 正則化:模型通過對模型的參數添加懲罰來避免數據的過度擬合。 係數與懲罰相加,導致一些係數為零。 因此,那些具有零係數的特徵被從特徵集中移除。 特徵選擇的方法使用 Lasso(L1 正則化)和彈性網絡(L1 和 L2 正則化)。
- SMLR(Sparse Multinomial Logistic Regression):該算法通過 ARD 先驗(自動相關性確定)對經典的多國邏輯回歸進行稀疏正則化。 這種正則化估計每個特徵的重要性並修剪對預測無用的維度。 該算法的實現是在 SMLR 中完成的。
- ARD(自動相關性確定回歸):該算法將係數權重移向零,並且基於貝葉斯嶺回歸。 該算法可以在 scikit-learn 中實現。
- 隨機森林重要性:此特徵選擇算法是指定數量的樹的聚合。 該算法中基於樹的策略根據增加節點的雜質或減少雜質(基尼雜質)進行排序。 樹的末端由雜質減少最少的節點組成,樹的開始由雜質減少最大的節點組成。 因此,可以通過修剪特定節點下的樹來選擇重要的特徵。
3.過濾方法
在預處理步驟期間應用這些方法。 這些方法非常快速且成本低廉,並且在刪除重複、相關和冗餘特徵方面效果最好。 不是應用任何監督學習方法,而是根據特徵的固有特徵來評估特徵的重要性。 與特徵選擇的包裝方法相比,該算法的計算成本更低。 但是,如果沒有足夠的數據來推導特徵之間的統計相關性,則結果可能比包裝方法更差。 因此,這些算法用於高維數據,如果要應用包裝器方法,這將導致更高的計算成本。

Filter 方法中使用的技術是:
- 信息增益:信息增益是指從特徵中獲得多少信息來識別目標值。 然後它測量熵值的減少。 考慮到特徵選擇的目標值,計算每個屬性的信息增益。
- 卡方檢驗:卡方法(X 2 )一般用於檢驗兩個分類變量之間的關係。 該測試用於識別來自數據集不同屬性的觀察值與其期望值之間是否存在顯著差異。 零假設表明兩個變量之間沒有關聯。
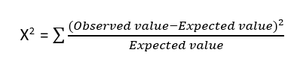
資源
卡方檢驗的公式
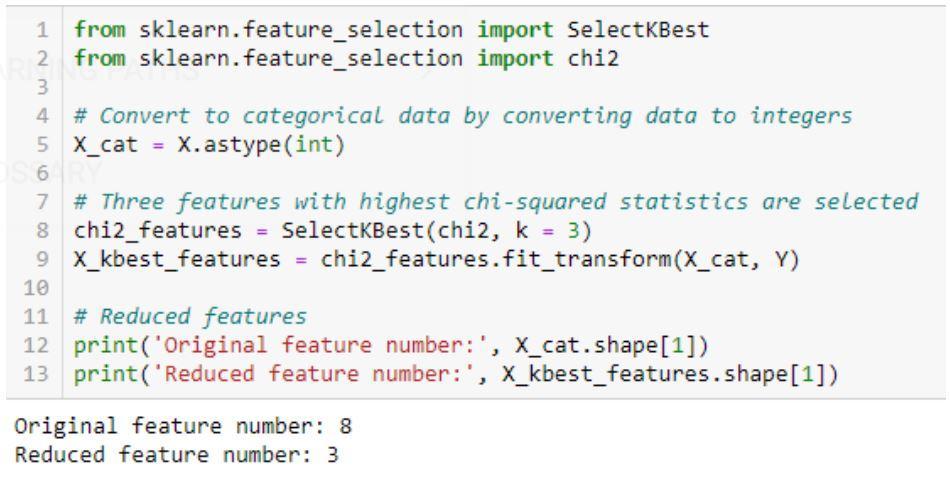
卡方算法的實現:sklearn、scipy
卡方檢驗代碼示例
資源
- CFS(基於相關性的特徵選擇):該方法遵循“CFS(基於相關的特徵選擇)的實現:scikit-feature
加入來自世界頂級大學的AI 和 ML在線課程——碩士、高級管理人員研究生課程和 ML 和 AI 高級證書課程,以加快您的職業生涯。
- FCBF(Fast correlation-based filter):與上述Relief和CFS方法相比,FCBF方法更快更高效。 最初,對所有特徵進行對稱不確定性的計算。 使用這些標準,然後對特徵進行分類並刪除冗餘特徵。
對稱不確定性= x 的信息增益 | y 除以它們的熵之和。 FCBF的實現:skfeature
- Fischer 分數: Fischer 比率 (FIR) 定義為每個特徵的每個類別的樣本均值之間的距離除以它們的方差。 每個特徵都是根據他們在 Fisher 標準下的分數獨立選擇的。 這導致了一組次優的特徵。 較大的 Fisher 分數表示選擇更好的特徵。
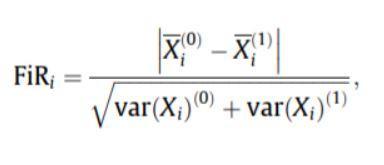
資源
Fischer 分數的公式
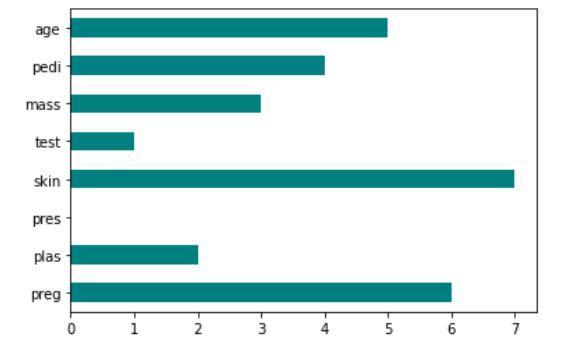
Fisher分數的實現:scikit-feature
顯示 Fisher 評分技術的代碼輸出
資源
皮爾遜相關係數:它是量化兩個連續變量之間關聯的量度。 相關係數的值範圍從 -1 到 1,它定義了變量之間的關係方向。
- 方差閾值:方差不滿足特定閾值的特徵被移除。 通過這種方法去除具有零方差的特徵。 考慮的假設是更高方差的特徵可能包含更多信息。
圖 15:顯示方差閾值實現的代碼示例
- 平均絕對差 (MAD):該方法計算平均絕對差
與平均值的差異。
顯示平均絕對差 (MAD) 實現的代碼示例及其輸出
資源
- 色散比:色散比定義為給定特徵的算術平均值 (AM) 與幾何平均值 (GM) 的比值。 對於給定的特徵,它的值範圍從 +1 到 ∞,因為 AM ≥ GM。
較高的色散比意味著較高的 Ri 值,因此是更相關的特徵。 相反,當 Ri 接近 1 時,表示低相關性特徵。
- 相互依賴:該方法用於衡量兩個變量之間的相互依賴。 從一個變量獲得的信息可用於獲得另一個變量的信息。
- 拉普拉斯分數:來自同一類的數據通常彼此接近。 一個特徵的重要性可以通過它的局部保存能力來評估。 計算每個特徵的拉普拉斯分數。 最小值決定了重要的尺寸。 拉普拉斯分數的實現:scikit-feature。
結論
機器學習過程中的特徵選擇可以概括為任何機器學習模型開發的重要步驟之一。 特徵選擇算法的過程導致數據維數的減少,同時刪除了與所考慮的模型不相關或不重要的特徵。 相關特徵可以加快模型的訓練時間,從而獲得高性能。
如果您有興趣了解有關機器學習的更多信息,請查看 IIIT-B 和 upGrad 的機器學習和 AI 執行 PG 計劃,該計劃專為工作專業人士設計,提供 450 多個小時的嚴格培訓、30 多個案例研究和作業、IIIT -B 校友身份,5 個以上實用的實踐頂點項目和頂級公司的工作協助。
過濾器方法與包裝器方法有何不同?
包裝器方法有助於根據分類器性能衡量特徵的幫助程度。 另一方面,過濾器方法使用單變量統計而不是交叉驗證性能來評估特徵的內在質量,這意味著它們判斷特徵的相關性。 結果,包裝方法更有效,因為它優化了分類器性能。 然而,由於重複的學習過程和交叉驗證,包裝技術在計算上比過濾方法更昂貴。
什麼是機器學習中的順序前向選擇?
這是一種順序特徵選擇,儘管它比過濾器選擇成本高得多。 這是一種貪心搜索技術,它根據分類器的性能迭代地選擇特徵,以發現理想的特徵子集。 它從一個空的特徵子集開始,並在每一輪中繼續添加一個特徵。 這一個特徵是從不在我們特徵子集中的所有特徵池中選擇的,當與其他特徵結合時,它會產生最好的分類器性能。
使用過濾器方法進行特徵選擇有什麼限制?
過濾器方法在計算上比包裝器和嵌入式特徵選擇方法便宜,但它有一些缺點。 在單變量方法的情況下,該策略在選擇特徵時經常忽略特徵相互依賴性並獨立評估每個特徵。 與其他兩種特徵選擇方法相比,這有時可能會導致計算性能不佳。