
GraphQL 入門:API 設計的演變(第 2 部分)
已發表: 2022-03-10在第 1 部分中,我們研究了 API 在過去幾十年中是如何演變的,以及每個 API 如何讓位於下一個。 我們還討論了使用 REST 進行移動客戶端開發的一些特殊缺點。 在本文中,我想看看移動客戶端 API 設計的發展方向——特別強調 GraphQL。
當然,多年來有很多人、公司和項目試圖解決 REST 的缺點:HAL、Swagger/OpenAPI、OData JSON API 和許多其他小型或內部項目都試圖為 REST 帶來秩序。無規範的 REST 世界。 與其按照世界的本來面目提出漸進式改進,或者嘗試組裝足夠多的不同部分以使 REST 成為我所需要的,我想嘗試一個思想實驗。 鑑於對過去有效和無效的技術的理解,我想利用今天的限制和我們極具表現力的語言來嘗試勾勒出我們想要的 API。 讓我們從開發人員的經驗向後工作,而不是向前實現(我在看你的 SQL)。
最小的 HTTP 流量
我們知道每個(HTTP/1)網絡請求的成本在從延遲到電池壽命的很多方面都很高。 理想情況下,我們的新 API 的客戶將需要一種方法,以盡可能少的往返請求他們需要的所有數據。
最小有效載荷
我們還知道,普通客戶端在帶寬、CPU 和內存方面是資源受限的,因此我們的目標應該是只發送客戶端需要的信息。 為此,我們可能需要一種方法讓客戶端請求特定的數據。
人類可讀
我們從 SOAP 時代了解到,API 很難與之交互,人們一提到它就會做鬼臉。 工程團隊希望使用我們多年來一直依賴的相同工具,例如curl 、 wget和Charles以及我們瀏覽器的網絡選項卡。
工具豐富
我們從 XML-RPC 和 SOAP 中學到的另一件事是,客戶端/服務器契約和類型系統尤其有用。 如果可能的話,任何新的 API 都將具有 JSON 或 YAML 等格式的輕量級,並具有更結構化和類型安全的合約的自省能力。
局部推理的保留
多年來,我們已經就如何組織大型代碼庫的一些指導原則達成一致——主要的原則是“關注點分離”。 不幸的是,對於大多數項目來說,這往往會以集中式數據訪問層的形式出現故障。 如果可能,應用程序的不同部分應該可以選擇管理自己的數據需求以及其他功能。
由於我們正在設計一個以客戶端為中心的 API,讓我們從在這樣的 API 中獲取數據的情況開始。 如果我們知道我們需要進行最少的往返,並且我們需要能夠過濾掉我們不想要的字段,我們需要一種方法來遍歷大量數據並隻請求其中的部分對我們有用。 查詢語言似乎很適合這裡。
我們不需要像處理數據庫一樣詢問我們的數據問題,因此像 SQL 這樣的命令式語言似乎是錯誤的工具。 事實上,我們的主要目標是遍歷預先存在的關係並限制我們應該能夠用相對簡單和聲明性的東西來做的事情。 業界已經很好地將 JSON 用於非二進制數據,所以讓我們從類似 JSON 的聲明性查詢語言開始。 我們應該能夠描述我們需要的數據,並且服務器應該返回包含這些字段的 JSON。

聲明式查詢語言滿足最小負載和最小 HTTP 流量的要求,但還有另一個好處可以幫助我們實現另一個設計目標。 許多聲明性語言、查詢和其他語言都可以像數據一樣被有效地操作。 如果我們仔細設計,我們的查詢語言將允許開發人員將大型請求分解並以對他們的項目有意義的任何方式重新組合它們。 使用這樣的查詢語言將幫助我們朝著保留本地推理的最終目標邁進。
一旦您的查詢變成“數據”,您就可以做很多令人興奮的事情。 例如,您可以攔截所有請求並將它們批處理,類似於虛擬 DOM 批處理 DOM 更新的方式,您還可以使用編譯器在構建時提取小查詢以預緩存數據,或者您可以構建複雜的緩存系統像阿波羅緩存。
API 願望清單上的最後一項是工具。 我們已經通過使用查詢語言獲得了其中的一些,但真正的力量來自於將它與類型系統配對。 通過服務器上的簡單類型模式,豐富的工具幾乎有無限的可能性。 查詢可以根據合約進行靜態分析和驗證,IDE 集成可以提供提示或自動完成,編譯器可以對查詢進行構建時優化,或者可以將多個模式拼接在一起以形成一個連續的 API 表面。

設計一個將查詢語言和類型系統配對的 API 可能聽起來像是一個戲劇性的提議,但多年來人們一直在以各種形式對此進行試驗。 XML-RPC 在 90 年代中期推動了類型化響應,其繼任者 SOAP 統治了多年! 最近,還有 Meteor 的 MongoDB 抽象、RethinkDB (RIP) Horizon、Netflix 令人驚嘆的 Falcor,它們多年來一直用於 Netflix.com,最後是 Facebook 的 GraphQL。 在本文的其餘部分,我將專注於 GraphQL,因為雖然 Falcor 等其他項目正在做類似的事情,但社區的思想份額似乎壓倒性地支持它。
什麼是 GraphQL?
首先,我不得不說我撒了一點謊。 我們上面構建的 API 是 GraphQL。 GraphQL 只是你的數據的類型系統,一種用於遍歷它的查詢語言——其餘的只是細節。 在 GraphQL 中,您將數據描述為互連圖,並且您的客戶專門詢問它需要的數據子集。 有很多關於 GraphQL 實現的令人難以置信的事情的演講和寫作,但核心概念非常易於管理且不復雜。
為了使這些概念更加具體,並幫助說明 GraphQL 如何嘗試解決第 1 部分中的一些問題,本文的其餘部分將構建一個 GraphQL API,該 API 可以為本系列第 1 部分中的博客提供支持。 在進入代碼之前,需要記住一些關於 GraphQL 的事情。
GraphQL 是規範(不是實現)
GraphQL 只是一個規範。 它定義了一個類型系統以及一個簡單的查詢語言,僅此而已。 首先,GraphQL 不以任何方式綁定到特定語言。 從 Haskell 到 C++ 都有超過兩打的實現,其中 JavaScript 只是其中之一。 規範公佈後不久,Facebook 發布了 JavaScript 的參考實現,但由於他們不在內部使用它,Go 和 Clojure 等語言的實現可能會更好或更快。
GraphQL 的規範沒有提及客戶端或數據
如果您閱讀規範,您會注意到明顯缺少兩件事。 首先,除了查詢語言之外,沒有提到客戶端集成。 由於 GraphQL 的設計,像 Apollo、Relay、Loka 等工具是可能的,但它們絕不是使用它的一部分或必需的。 其次,沒有提到任何特定的數據層。 同一個 GraphQL 服務器可以並且經常這樣做,從一組異構的源中獲取數據。 它可以從 Redis 請求緩存數據,從 USPS API 進行地址查找並調用基於 protobuff 的微服務,而客戶端永遠不會知道其中的區別。
複雜性的逐步披露
對許多人來說,GraphQL 已經達到了強大和簡單的罕見交集。 它在使簡單的事情變得簡單和使困難的事情成為可能方面做得非常出色。 讓服務器運行並通過 HTTP 提供類型化數據只需幾行代碼,使用幾乎任何你能想像到的語言。
例如,GraphQL 服務器可以包裝現有的 REST API,其客戶端可以通過常規 GET 請求獲取數據,就像您與其他服務交互一樣。 你可以在這裡看到一個演示。 或者,如果項目需要更複雜的工具集,則可以使用 GraphQL 執行字段級身份驗證、發布/訂閱訂閱或預編譯/緩存查詢等操作。
示例應用程序
本示例的目的是用大約 70 行 JavaScript 代碼展示 GraphQL 的強大功能和簡單性,而不是編寫詳盡的教程。 我不會詳細介紹語法和語義,但這裡的所有代碼都是可運行的,並且在文章末尾有一個指向該項目的可下載版本的鏈接。 如果在經歷了這些之後,您想更深入地挖掘,我的博客上有一個資源集合,可以幫助您構建更大更強大的服務。
對於演示,我將使用 JavaScript,但任何語言的步驟都非常相似。 讓我們從使用令人驚嘆的 Mocky.io 的一些示例數據開始。
作者
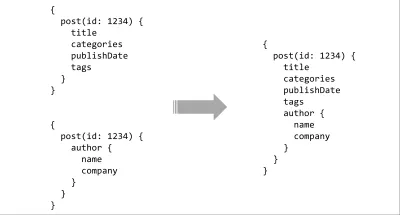
{ 9: { id: 9, name: "Eric Baer", company: "Formidable" }, ... }帖子
[ { id: 17, author: "author/7", categories: [ "software engineering" ], publishdate: "2016/03/27 14:00", summary: "...", tags: [ "http/2", "interlock" ], title: "http/2 server push" }, ... ] 第一步是使用express和express-graphql中間件創建一個新項目。
bash npm init -y && npm install --save graphql express express-graphql 並使用快速服務器創建index.js文件。
const app = require("express")(); const PORT = 5000; app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); 要開始使用 GraphQL,我們可以從 REST API 中的數據建模開始。 在名為schema.js的新文件中添加以下內容:
const { GraphQLInt, GraphQLList, GraphQLObjectType, GraphQLSchema, GraphQLString } = require("graphql"); const Author = new GraphQLObjectType({ name: "Author", fields: { id: { type: GraphQLInt }, name: { type: GraphQLString }, company: { type: GraphQLString }, } }); const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author }, categories: { type: new GraphQLList(GraphQLString) }, publishDate: { type: GraphQLString }, summary: { type: GraphQLString }, tags: { type: new GraphQLList(GraphQLString) }, title: { type: GraphQLString } } }); const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post) } } }); module.exports = new GraphQLSchema({ query: Blog }); 上面的代碼將我們 API 的 JSON 響應中的類型映射到 GraphQL 的類型。 一個GraphQLObjectType對應一個 JavaScript Object ,一個GraphQLString對應一個 JavaScript String等等。 需要注意的一種特殊類型是最後幾行的GraphQLSchema 。 GraphQLSchema是 GraphQL 的根級導出——查詢遍歷圖的起點。 在這個基本示例中,我們只定義query ; 這是您定義突變(寫入)和訂閱的地方。

接下來,我們將在index.js文件中將模式添加到我們的 express 服務器。 為此,我們將添加express-graphql中間件並將模式傳遞給它。
const graphqlHttp = require("express-graphql"); const schema = require("./schema.js"); const app = require("express")(); const PORT = 5000; app.use(graphqlHttp({ schema, // Pretty Print the JSON response pretty: true, // Enable the GraphiQL dev tool graphiql: true })); app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); 此時,雖然我們沒有返回任何數據,但我們有一個工作的 GraphQL 服務器,它向客戶端提供其模式。 為了使啟動應用程序更容易,我們還將在package.json添加一個啟動腳本。
"scripts": { "start": "nodemon index.js" }, 運行項目並轉到 https://localhost:5000/ 應該會顯示一個名為 GraphiQL 的數據瀏覽器。 只要 HTTP Accept標頭未設置為application/json ,GraphiQL 就會默認加載。 使用application/json通過fetch或cURL調用相同的 URL 將返回 JSON 結果。 隨意使用內置文檔並編寫查詢。

完成服務器唯一剩下要做的就是將底層數據連接到模式中。 為此,我們需要定義resolve函數。 在 GraphQL 中,查詢從上到下運行,並在遍歷樹時調用resolve函數。 例如,對於以下查詢:
query homepage { posts { title } } GraphQL 將首先調用posts.resolve(parentData)然後調用 posts.title.resolve posts.title.resolve(parentData) 。 讓我們從在我們的博客文章列表中定義解析器開始。
const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post), resolve: () => { return fetch('https://www.mocky.io/v2/594a3ac810000053021aa3a7') .then((response) => response.json()) } } } }); 我在這裡使用isomorphic-fetch包來發出 HTTP 請求,因為它很好地演示瞭如何從解析器返回 Promise,但你可以使用任何你喜歡的東西。 這個函數將返回一個博客類型的帖子數組。 GraphQL 的 JavaScript 實現的默認解析函數是parentData.<fieldName> 。 例如,作者姓名字段的默認解析器是:
rawAuthorObject => rawAuthorObject.name這個單一的覆蓋解析器應該為整個 post 對象提供數據。 我們仍然需要為 Author 定義解析器,但是如果您運行查詢以獲取主頁所需的數據,您應該會看到它正在工作。
由於我們的帖子 API 中的 author 屬性只是作者 ID,因此當 GraphQL 查找定義名稱和公司的 Object 並找到 String 時,它只會返回null 。 要連接作者,我們需要將 Post 模式更改為如下所示:
const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author, resolve: (subTree) => { // Get the AuthorId from the post data const authorId = subTree.author.split("/")[1]; return fetch('https://www.mocky.io/v2/594a3bd21000006d021aa3ac') .then((response) => response.json()) .then(authors => authors[authorId]); } }, ... } });現在,我們有一個完整工作的 GraphQL 服務器,它包裝了一個 REST API。 完整的源代碼可以從這個 Github 鏈接下載,或者從這個 GraphQL 啟動板運行。
您可能想知道使用這樣的 GraphQL 端點需要使用哪些工具。 有很多選擇,例如 Relay 和 Apollo,但首先,我認為簡單的方法是最好的。 如果您經常使用 GraphiQL,您可能已經註意到它的 URL 很長。 此 URL 只是您的查詢的 URI 編碼版本。 要在 JavaScript 中構建 GraphQL 查詢,您可以執行以下操作:
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);或者,如果您願意,您可以直接從 GraphiQL 複製粘貼 URL,如下所示:
https://localhost:5000/?query=query%20homepage%20%7B%0A%20%20posts%20%7B%0A%20%20%20%20title%0A%20%20%20%20author%20%7B%0A%20%20%20%20%20%20name%0A%20%20%20%20%7D%0A%20%20%7D%0A%7D&operationName=homepage由於我們有一個 GraphQL 端點和使用它的方法,我們可以將它與我們的 RESTish API 進行比較。 我們需要編寫的使用 RESTish API 獲取數據的代碼如下所示:
使用 RESTish API
const getPosts = () => fetch(`${API_ROOT}/posts`); const getPost = postId => fetch(`${API_ROOT}/post/${postId}`); const getAuthor = authorId => fetch(`${API_ROOT}/author/${postId}`); const getPostWithAuthor = post => { return getAuthor(post.author) .then(author => { return Object.assign({}, post, { author }) }) }; const getHomePageData = () => { return getPosts() .then(posts => { const postDetails = posts.map(getPostWithAuthor); return Promise.all(postDetails); }) };使用 GraphQL API
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);總之,我們使用 GraphQL 來:
- 減少九個請求(文章列表、四篇博客文章和每篇文章的作者)。
- 大幅減少發送的數據量。
- 使用令人難以置信的開發人員工具來構建我們的查詢。
- 在我們的客戶端中編寫更簡潔的代碼。
GraphQL 的缺陷
雖然我相信炒作是有道理的,但沒有靈丹妙藥,儘管 GraphQL 很棒,但它並非沒有缺陷。
數據的完整性
GraphQL 有時看起來像是專門為優質數據而構建的工具。 它通常最適合作為一種網關,將不同的服務或高度規範化的表拼接在一起。 如果從您使用的服務返回的數據是混亂且非結構化的,那麼在 GraphQL 下添加數據轉換管道可能是一個真正的挑戰。 GraphQL 解析函數的範圍只是它自己的數據和它的子數據。 如果編排任務需要訪問樹中同級或父級中的數據,則可能特別具有挑戰性。
複雜的錯誤處理
一個 GraphQL 請求可以運行任意數量的查詢,並且每個查詢可以訪問任意數量的服務。 如果請求的任何部分失敗,而不是整個請求失敗,GraphQL 默認返回部分數據。 從技術上講,部分數據可能是正確的選擇,而且它非常有用和高效。 缺點是錯誤處理不再像檢查 HTTP 狀態碼那樣簡單。 可以關閉此行為,但通常情況下,客戶端會遇到更複雜的錯誤情況。
緩存
儘管使用靜態 GraphQL 查詢通常是個好主意,但對於像 Github 這樣允許任意查詢的組織來說,使用 Varnish 或 Fastly 等標準工具進行網絡緩存將不再可能。
高 CPU 成本
解析、驗證和類型檢查查詢是一個 CPU 綁定的過程,這可能會導致 JavaScript 等單線程語言的性能問題。
這只是運行時查詢評估的問題。
結束的想法
GraphQL 的特性並不是一場革命——其中一些已經存在了近 30 年。 GraphQL 的強大之處在於其完善、集成和易用性的水平使其超過了各個部分的總和。
GraphQL 完成的許多事情可以通過努力和紀律使用 REST 或 RPC 來實現,但是 GraphQL 為可能沒有時間、資源或工具自行完成的大量項目帶來了最先進的 API。 GraphQL 確實不是靈丹妙藥,但它的缺陷往往很小且易於理解。 作為一個構建了相當複雜的 GraphQL 服務器的人,我可以很容易地說,收益很容易超過成本。
這篇文章幾乎完全集中在 GraphQL 存在的原因以及它解決的問題上。 如果這激起了您對更多地了解它的語義以及如何使用它的興趣,我鼓勵您以最適合您的方式學習,無論是博客、youtube 還是只是閱讀源代碼(How To GraphQL 特別好)。
如果你喜歡這篇文章(或者如果你討厭這篇文章)並且想給我反饋,請在 Twitter 上以@ebaerbaerbaer 的身份找到我,或者在 ericjbaer 的 LinkedIn 上找到我。