
機器學習中的假新聞檢測[用編碼示例解釋]
已發表: 2021-02-08假新聞是當前互聯網和社交媒體時代的最大問題之一。 雖然新聞在幾個小時內從世界的一個角落傳到另一個角落是一件幸事,但看到許多人和團體散佈假新聞也很痛苦。
使用自然語言處理和深度學習的機器學習技術可以在一定程度上解決這個問題。 在本教程中,我們將使用機器學習構建一個假新聞檢測模型。
在本文結束時,您將了解以下內容:
- 處理文本數據
- NLP處理技術
- 計數向量化和 TF-IDF
- 進行預測和分類新聞文本
加入來自世界頂級大學的AI 和 ML在線課程 - 碩士、高級管理人員研究生課程和 ML 和 AI 高級證書課程,以加快您的職業生涯。
目錄
數據與問題
我們將使用 Kaggle 假新聞挑戰數據來製作分類器。 數據集由 4 個特徵和 1 個二進制目標組成。 4個特點如下:
- id :新聞文章的唯一 ID
- title :新聞文章的標題
- author : 新聞文章的作者
- text :文章的正文; 可能不完整
目標是包含二進制值 0 和 1 的“標籤”。 其中 0 表示它是可靠的新聞來源,或者換句話說,Not Fake。 1 表示它是一條潛在的假新聞並且不可靠。 我們的數據集由 20800 個實例組成。 讓我們潛入水中。

數據預處理和清洗
| 將熊貓導入為pd df=pd.read_csv( 'fake-news/train.csv' ) df.head() |
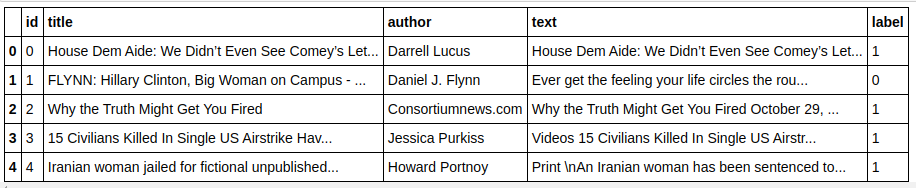
| X=df.drop( 'label' ,axis= 1 ) # 特徵 y=df[ 'label' ] # 目標 |
我們現在需要刪除缺少數據的實例。
| df=df.dropna() |
![]()
正如我們所看到的,它刪除了所有缺少數據的實例。
| 消息=df.copy() messages.reset_index(就地=真) 消息頭( 10 ) |
讓我們看一次數據。
| 消息['文本'][6] |

如我們所見,需要執行以下步驟:
- 刪除停用詞:無論數據如何,有很多詞對任何文本都沒有任何價值。 例如,“I”、“a”、“am”等。這些詞沒有信息價值,因此可以刪除以減少我們的語料庫的大小,這樣我們就可以只關注具有實際價值的詞/標記.
- 詞幹提取:詞幹提取和詞形還原是將詞還原為詞乾或詞根的技術。 這一步的主要優點是減少了詞彙量。 例如,Play、Playing、Played 等詞將簡化為“Play”。 詞幹只是將單詞截斷為最短的單詞,而不考慮文本的語法方面。 另一方面,詞形還原也考慮了語法,因此產生了更好的結果。 然而,詞根化通常比詞乾化要慢,因為它需要參考字典並考慮語法方面。
- 刪除除字母值之外的所有內容:非字母值在這裡沒有多大用處,因此可以刪除它們。 但是,您可以進一步探索以查看數字或其他類型數據的存在是否對目標有任何影響。
- 小寫單詞:小寫單詞以減少詞彙量。
- 標記句子:從句子生成標記。
| 從 sklearn.feature_extraction.text 導入 CountVectorizer、TfidfVectorizer、HashingVectorizer 從 nltk.corpus 導入停用詞 從 nltk.stem.porter 導入 PorterStemmer 重新進口 ps = PorterStemmer() corpus = [] for i in range(0, len(messages)): review = re.sub('[^a-zA-Z]', ' ', messages['text'][i]) 評論 = 評論.lower() 評論 = 評論.split() review = [ps.stem(word) for the word in review if not in stopwords.words('english')] review = ' '.join(review) corpus.append(評論) |
現在讓我們看看我們的語料庫。
| 語料庫[ 3 ] |
![]()
正如我們所看到的,這些詞現在被提取為詞根。
TF-IDF 矢量化器
現在我們需要將單詞向量化為數字數據,這也稱為向量化。 最簡單的矢量化方法是使用詞袋。 但是詞袋創建了一個稀疏矩陣,因此需要大量的處理內存。 此外,BoW 沒有考慮詞的頻率,這使其成為一種糟糕的算法。
TF-IDF(詞頻 - 逆文檔頻率)是另一種考慮詞頻的詞向量化方法。 例如,“我們”、“我們的”、“該”等常用詞出現在每個文檔/實例中,因此 BoW 值會太高,從而產生誤導。 這將導致一個糟糕的模型。 TF-IDF 是詞頻和逆文檔頻率的乘積。
詞頻考慮了文檔中單詞的頻率,而逆文檔頻率考慮了整個語料庫中出現的單詞。 出現在整個語料庫中的單詞的重要性降低了,因為 IDF 值要低得多。 特定出現在一個文檔中的單詞具有較高的 IDF 值,這使得總 TF-IDF 值很高。
| ## TFi df 矢量化器 從sklearn.feature_extraction.text導入TfidfVectorizer tfidf_v = TfidfVectorizer(max_features= 5000 ,ngram_range=( 1 , 3 )) X=tfidf_v.fit_transform(corpus).toarray() y=messages[ 'label' ] |
在上面的代碼中,我們從 Sklearn 的特徵提取模塊中導入了 TF-IDF Vectorizer。 我們通過將 max_features 作為 5000 並將 ngram_range 作為 (1,3) 來製作它的對象。 參數 max_features 定義了我們想要創建的特徵向量的最大數量,而 ngram_range 參數定義了我們想要包含的 ngram 組合。 在我們的例子中,我們將得到 1 個單詞、2 個單詞和 3 個單詞的 3 種組合。 讓我們看一下創建的一些功能。
| tfidf_v.get_feature_names()[: 20 ] |


正如我們所看到的,形成了多種類型的組合。 有 1 個標記、2 個標記和 3 個標記的特徵名稱。
製作數據框
| ##將數據集分為訓練和測試 從sklearn.model_selection導入train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.33 , random_state= 0 ) count_df = pd.DataFrame(X_train, columns=tfidf_v.get_feature_names()) count_df.head() |
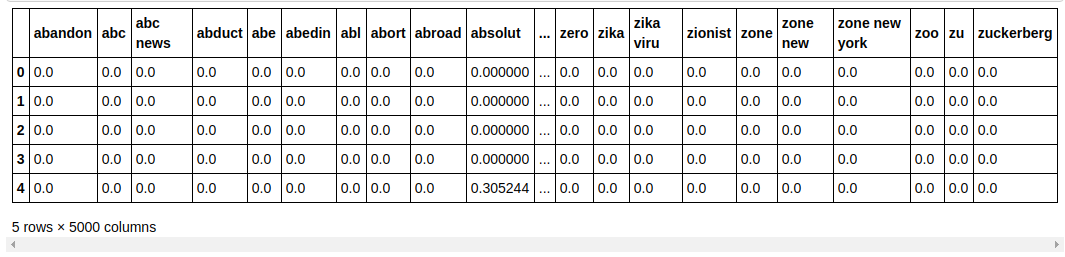
我們將數據集拆分為訓練和測試,以便我們可以測試模型在未見數據上的性能。 然後我們創建一個新的 Dataframe,其中包含新的特徵向量。
建模與調優
多項式NB算法
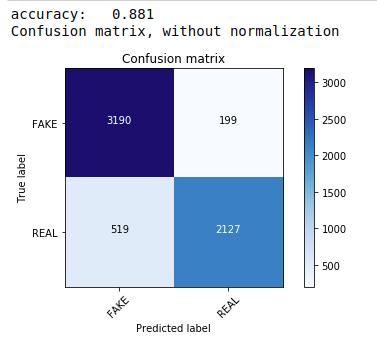
首先,我們使用多項樸素貝葉斯定理,這是文本數據分類中最常用和最簡單的算法。 我們擬合訓練數據並預測測試數據。 後來我們計算並繪製了混淆矩陣,得到了 88.1% 的準確率。
| 從sklearn.naive_bayes導入MultinomialNB 從sklearn導入指標 將numpy導入為np 導入迭代工具 從sklearn.metrics導入plot_confusion_matrix 分類器=多項式NB() 分類器.fit(X_train, y_train) pred = classifier.predict(X_test) score = metrics.accuracy_score(y_test, pred) 打印( “準確度:%0.3f” % 分數) cm = metrics.confusion_matrix(y_test, pred) plot_confusion_matrix(cm,classes=[ 'FAKE' , 'REAL' ]) |
具有超參數調整的多項分類器
MultinomialNB 有一個可以進一步調整的參數 alpha。 因此,我們運行一個循環來嘗試多個具有不同 alpha 值的 MultinomialNB 分類器並檢查它們的準確度分數。 我們檢查當前分數是否高於之前的分數。 如果是,那麼我們將分類器設置為當前分類器。
| 以前的分數= 0 對於np.arange( 0 , 1 , 0.1 )中的alpha : sub_classifier=多項式NB(alpha=alpha) sub_classifier.fit(X_train,y_train) y_pred=sub_classifier.predict(X_test) score = metrics.accuracy_score(y_test, y_pred) 如果分數>previous_score: 分類器=子分類器 打印( “阿爾法:{},分數:{}” .format(阿爾法,分數)) |
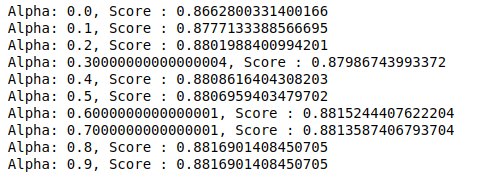
因此,我們可以看到 0.9 或 0.8 的 alpha 值給出了最高的準確度分數。
解釋結果
現在讓我們看看這些分類器係數值的含義。 我們首先將所有特徵名稱保存在另一個變量中。
| ## G et F特徵名稱 feature_names = cv.get_feature_names() |
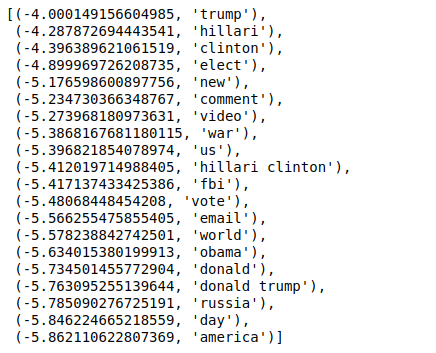
現在,當我們以相反的順序對值進行排序時,我們得到最小值為 -4 的值。 這些表示最真實或最不假的詞。
| ###最真實 排序(zip(分類器.coef_ [ 0 ],特徵名稱),反向=真)[: 20 ] |
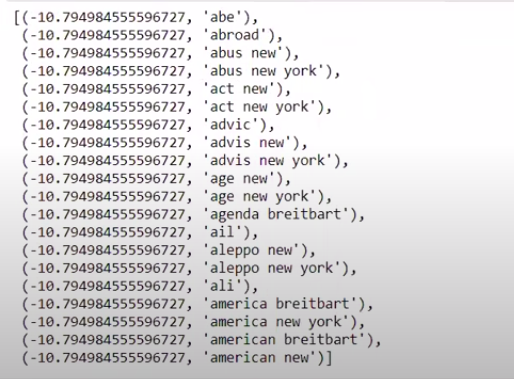
當我們以非逆序對值進行排序時,我們得到最小值為 -10 的值。 這些表示最不真實或最虛假的詞。
| ###最真實 排序(zip(classifier.coef_[ 0 ],feature_names))[: 20 ] |
結論
在本教程中,我們僅使用了 ML 算法,但您也使用了其他神經網絡方法。 此外,為了對文本數據進行矢量化,我們使用了 TF-IDF 矢量化器。 還有更多的矢量化器,如 Count Vectorizer、Hashing Vectorizer 等,它們可以更好地完成這項工作。 嘗試並嘗試其他算法和技術,看看是否可以產生更好的結果。
如果您有興趣了解有關機器學習的更多信息,請查看 IIIT-B 和 upGrad 的機器學習和 AI 執行 PG 計劃,該計劃專為工作專業人士設計,提供 450 多個小時的嚴格培訓、30 多個案例研究和作業、IIIT -B 校友身份,5 個以上實用的實踐頂點項目和頂級公司的工作協助。
為什麼需要檢測假新聞?
在目前的情況下,社交媒體平台非常強大和有價值,因為它們允許用戶討論和交流想法以及辯論民主、教育和健康等主題。 然而,某些實體嚴重利用此類平台,在某些情況下獲取金錢利益,並產生偏見觀點、改變思維方式以及在其他情況下傳播諷刺或荒謬。 假新聞是這種現象的術語。 不符合現實的在線發布項目的激增導致了政治、體育、健康、科學和其他領域的一系列問題。
哪些公司主要使用假新聞檢測?
假新聞檢測用於社交媒體和新聞網站等平台。 Facebook、Instagram 和 Twitter 等社交媒體巨頭很容易受到假新聞的影響,因為大多數用戶都依賴它們作為日常新聞來源來獲取最新信息。 媒體公司也使用虛假檢測技術來確定他們所擁有信息的真實性。 電子郵件是個人可以接收新聞的另一種媒介,因此很難識別和驗證其真實性。 惡作劇、垃圾郵件和垃圾郵件以通過電子郵件傳輸而聞名。 因此,大多數電子郵件平台採用虛假新聞檢測來識別垃圾郵件和垃圾郵件。