
Python中的探索性數據分析:你需要知道什麼?
已發表: 2021-03-12探索性數據分析 (EDA) 是所有數據科學家都遵循的一種非常普遍且重要的實踐。 這是從不同角度查看表格和數據表以完全理解它的過程。 對數據有很好的理解有助於我們對數據進行清理和總結,從而帶來原本不清楚的見解和趨勢。
例如,EDA 沒有像“數據分析”那樣需要遵循的核心規則集。 剛接觸該領域的人總是容易混淆這兩個術語,這兩個術語大多相似,但目的不同。 與 EDA 不同,數據分析更傾向於使用概率和統計方法來揭示不同變體之間的事實和關係。
回過頭來,執行 EDA 的方式沒有對錯之分。 它因人而異,但是,下面列出了一些通常遵循的主要準則。
- 處理缺失值:當收集期間所有數據可能不可用或未記錄時,可以看到空值。
- 刪除重複數據:重要的是要防止在使用重複數據記錄訓練機器學習算法期間產生任何過度擬合或偏差
- 處理異常值:異常值是與其餘數據截然不同且不遵循趨勢的記錄。 它可能由於數據收集過程中的某些異常或不准確而出現
- 縮放和標準化:這僅適用於數值數據變量。 大多數情況下,變量的範圍和規模差異很大,這使得很難比較它們並找到相關性。
- 單變量和雙變量分析:單變量分析通常通過查看一個變量如何影響目標變量來完成。 雙變量分析是在任何兩個變量之間進行的,它可以是數值的或分類的或兩者兼而有之。
我們將看看其中一些是如何使用 Kaggle 上非常著名的“Home Credit Default Risk”數據集實現的。 該數據包含有關貸款申請人在申請貸款時的信息。 它包含兩種類型的場景:
- 付款困難的客戶:他/她逾期付款超過X天
在我們樣本中的前 Y 期貸款中的至少一個,
- 所有其他情況:按時付款的所有其他情況。
為了本文的目的,我們將只處理應用程序數據文件。
相關:面向初學者的 Python 項目理念和主題
目錄
看數據
app_data = pd.read_csv('application_data.csv')
app_data.info()
讀取應用程序數據後,我們使用 info() 函數來簡要了解我們將要處理的數據。 下面的輸出告訴我們,我們有大約 300000 條貸款記錄,包含 122 個變量。 其中,有 16 個分類變量,其餘為數字變量。
<class 'pandas.core.frame.DataFrame'>
RangeIndex:307511 個條目,0 到 307510
列:122 個條目,SK_ID_CURR 到 AMT_REQ_CREDIT_BUREAU_YEAR
數據類型:float64(65)、int64(41)、object(16)
內存使用量:286.2+ MB
分開處理和分析數值數據和分類數據始終是一種很好的做法。
分類 = app_data.select_dtypes(include = object).columns
app_data[categorical].apply(pd.Series.nunique, 軸 = 0)
只看下面的分類特徵,我們發現它們中的大多數只有幾個類別,這使得它們更容易使用簡單的圖進行分析。
NAME_CONTRACT_TYPE 2
CODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
職業類型 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZATION_TYPE 58
FONDKAPREMONT_MODE 4
HOUSETYPE_MODE 3
WALLSMATERIAL_MODE 7
緊急狀態_模式 2
數據類型:int64
現在對於數值特徵,describe() 方法為我們提供了數據的統計信息:
數字= app_data.describe()
數字=數字.列
號碼
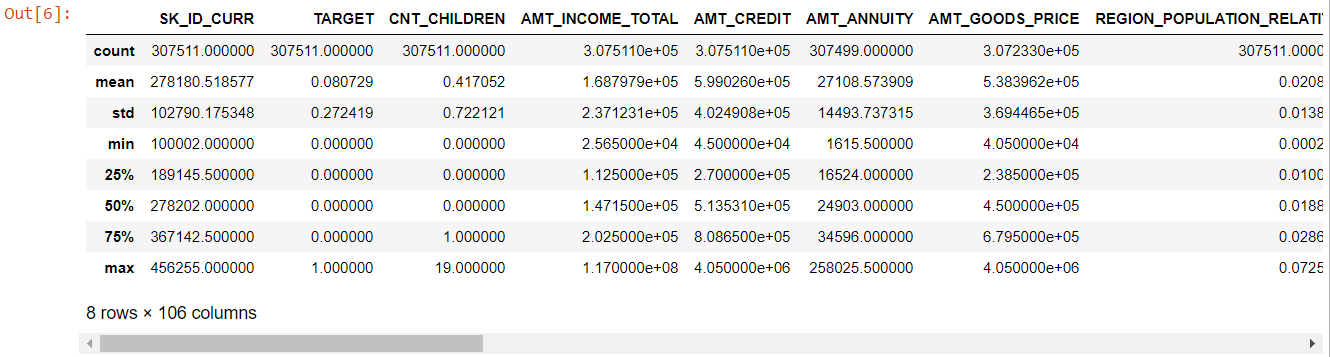
縱觀整個表格,很明顯:
- days_birth 為負數:申請人相對於申請日的年齡(以天為單位)
- days_employ 有異常值(最大值約為 100 年)(635243)
- amt_annuity- 均值遠小於最大值
所以現在我們知道哪些特徵需要進一步分析。
缺失數據
我們可以通過沿 Y 軸繪製缺失數據的百分比來繪製所有具有缺失值的特徵的點圖。

缺失 = pd.DataFrame((app_data.isnull().sum()) * 100 / app_data.shape[0]).reset_index()
plt.figure(figsize = (16,5))
ax = sns.pointplot('index', 0, data = missing)
plt.xticks(旋轉 = 90,字體大小 = 7)
plt.title(“缺失值的百分比”)
plt.ylabel(“百分比”)
plt.show()
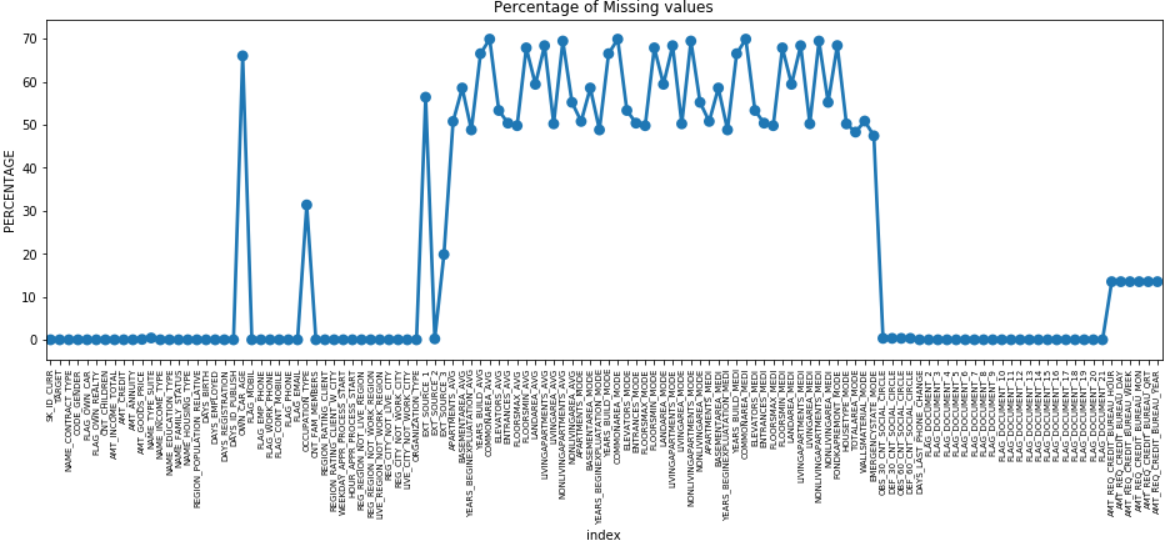
許多列有很多缺失數據 (30-70%),有些缺失數據很少 (13-19%),許多列也根本沒有缺失數據。 當您只需要執行 EDA 時,實際上並不需要修改數據集。 但是,繼續進行數據預處理,我們應該知道如何處理缺失值。
對於缺失值較少的特徵,我們可以使用回歸來預測缺失值或填充存在值的平均值,具體取決於特徵。 對於具有大量缺失值的特徵,最好刪除這些列,因為它們對分析的洞察力非常少。
數據不平衡
在這個數據集中,貸款違約者是使用二進制變量“目標”來識別的。
100 * app_data['TARGET'].value_counts() / len(app_data['TARGET'])
0 91.927118
1 8.072882
名稱:目標,數據類型:float64
我們看到數據高度不平衡,比例為 92:8。 大部分貸款按時償還(目標 = 0)。 因此,每當出現如此巨大的不平衡時,最好將特徵與目標變量進行比較(目標分析),以確定這些特徵中的哪些類別比其他類別更容易拖欠貸款。
下面只是一些可以使用seaborn python 庫和簡單的用戶定義函數製作的圖形示例。
性別
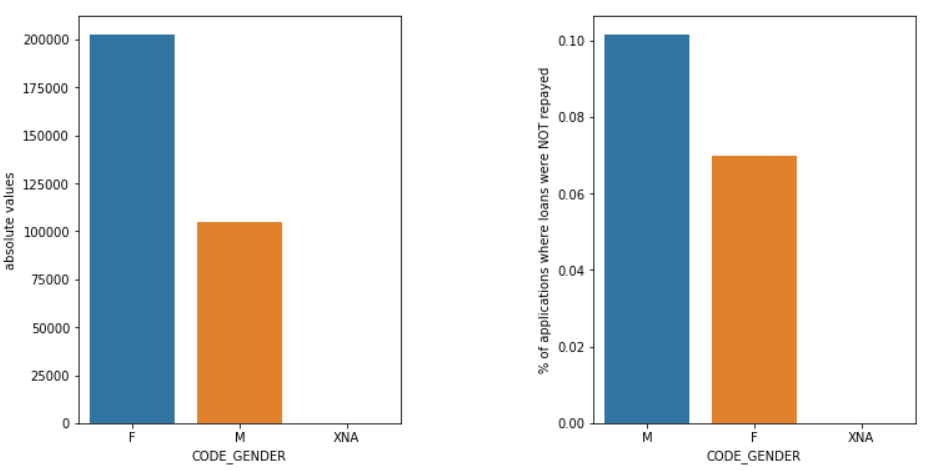
與女性 (F) 相比,男性 (M) 的違約機率更高,儘管女性申請人的數量幾乎是其兩倍。 所以女性在償還貸款方面比男性更可靠。
教育類型
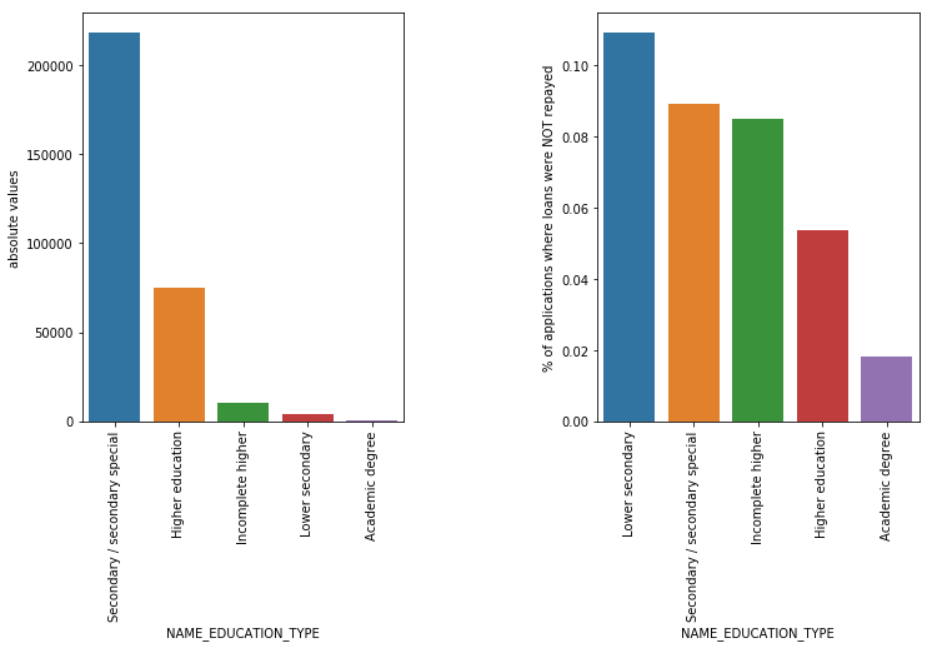
儘管大多數學生貸款用於他們的中學教育或高等教育,但對公司而言風險最大的是初中教育貸款,其次是中學。
另請閱讀:數據科學職業
結論
上面看到的這種分析在銀行和金融服務的風險分析中得到了廣泛的應用。 通過這種方式,可以使用數據存檔來最大程度地降低向客戶提供貸款時的損失風險。 EDA 在所有其他領域的範圍是無窮無盡的,應該廣泛使用。
如果您想了解數據科學,請查看 IIIT-B 和 upGrad 的數據科學執行 PG,它是為在職專業人士創建的,提供 10 多個案例研究和項目、實用的實踐研討會、與行業專家的指導、1-與行業導師面對面交流,400 多個小時的學習和頂級公司的工作協助。
當您開始對數據進行建模時,探索性數據分析被認為是初始級別。 這是一種非常有見地的技術,可以分析數據建模的最佳實踐。 您將能夠從數據中提取視覺圖、圖形和報告,以全面了解它。 異常值是指數據中的異常或細微差異。 它可能在數據收集期間發生。 有 4 種方法可以檢測數據集中的異常值。 這些方法如下: 與數據分析不同,EDA 沒有嚴格的規則和規定。 不能說這是執行 EDA 的正確方法或錯誤方法。 初學者經常被誤解並混淆 EDA 和數據分析。為什麼需要探索性數據分析 (EDA)?
EDA 涉及到完整分析數據的某些步驟,包括推導統計結果、查找缺失的數據值、處理錯誤的數據條目,最後推導出各種繪圖和圖形。
此分析的主要目的是確保您使用的數據集適合開始應用建模算法。 這就是為什麼這是您在進入建模階段之前應該對數據執行的第一步。 什麼是異常值以及如何處理它們?
1. Boxplot - Boxplot 是一種檢測異常值的方法,我們通過它們的四分位數分離數據。
2. 散點圖 - 散點圖以笛卡爾平面上標記的點集合的形式顯示 2 個變量的數據。 一個變量的值代表水平軸(x-ais),另一個變量的值代表垂直軸(y 軸)。
3. Z-score - 在計算 Z-score 時,我們尋找遠離中心的點並將它們視為異常值。
4. 四分位數間距 (IQR) - 四分位數間距或 IQR 是上四分位數和下四分位數或第 75 和第 25 個四分位數之間的差異,通常稱為統計離散度。 執行 EDA 的準則是什麼?
但是,有一些通常採用的準則:
1.處理缺失值
2.去除重複數據
3. 處理異常值
4. 縮放和規範化
5. 單變量和雙變量分析