
什麼是 Python 中的探索性數據分析? 從頭開始學習
已發表: 2021-03-04簡而言之,探索性數據分析或 EDA 佔數據科學項目的近 70%。 EDA 是通過使用各種分析工具從數據中獲取推斷統計數據來探索數據的過程。 這些探索要么通過查看普通數字,要么通過繪製不同類型的圖形和圖表來完成。
每個圖表或圖表描繪了不同的故事和對相同數據的角度。 對於大部分數據分析和清理部分,Pandas 是最常用的工具。 對於可視化和繪製圖形/圖表,使用了 Matplotlib、Seaborn 和 Plotly 等繪圖庫。
EDA是非常有必要進行的,因為它讓數據向你坦白。 一個做得很好 EDA 的數據科學家對數據有很多了解,因此他們將建立的模型將自動比沒有做好 EDA 的數據科學家更好。
在本教程結束時,您將了解以下內容:
- 檢查數據的基本概述
- 檢查數據的描述性統計
- 操作列名和數據類型
- 處理缺失值和重複行
- 雙變量分析
目錄
數據基本概述
我們將在本教程中使用汽車數據集,該數據集可以從 Kaggle下載。 幾乎所有數據集的第一步都是導入它並檢查它的基本概述——它的形狀、列、列類型、前 5 行等。這一步讓您快速了解您將使用的數據。 讓我們看看如何在 Python 中做到這一點。
| # 導入需要的庫 將熊貓導入為pd 將numpy導入為np 將seaborn導入為sns #visualisation 將matplotlib.pyplot導入為plt #visualisation %matplotlib 內聯 sns.set(color_codes=真) |
數據頭尾
| 數據 = pd.read_csv( “路徑/數據集.csv” ) # 檢查數據框的前 5 行 數據頭() |
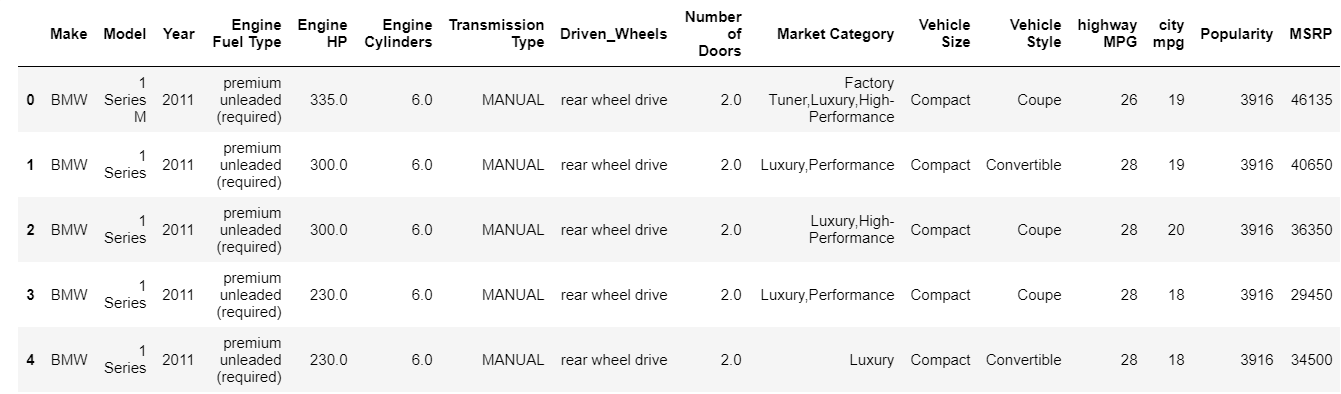
head 函數默認打印數據幀的前 5 個索引。 您還可以指定繞過該值到頭部需要查看多少個頂級索引。 立即打印頭部可以讓我們快速查看我們擁有的數據類型、存在的特徵類型以及它們包含的值。 當然,這並不能說明數據的全部內容,但它確實讓您快速瀏覽了數據。 您可以使用 tail 函數類似地打印數據框的底部。
| # 打印數據框的最後 10 行 數據尾( 10 ) |
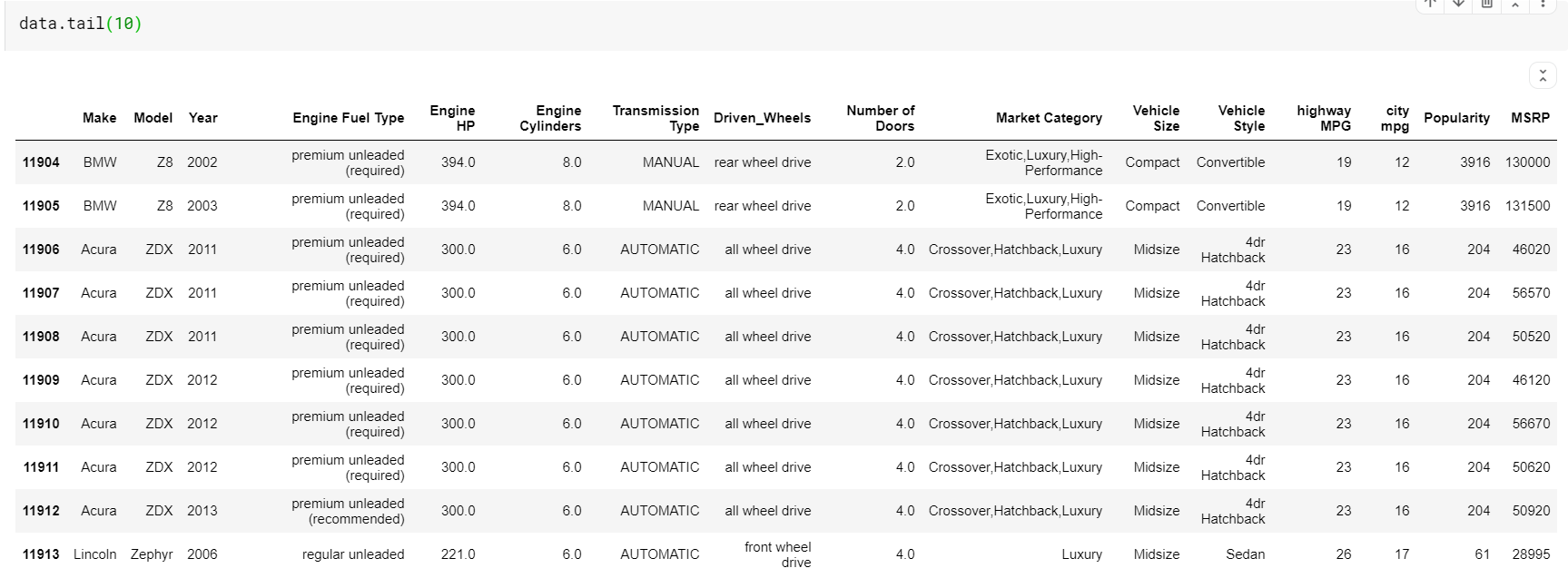
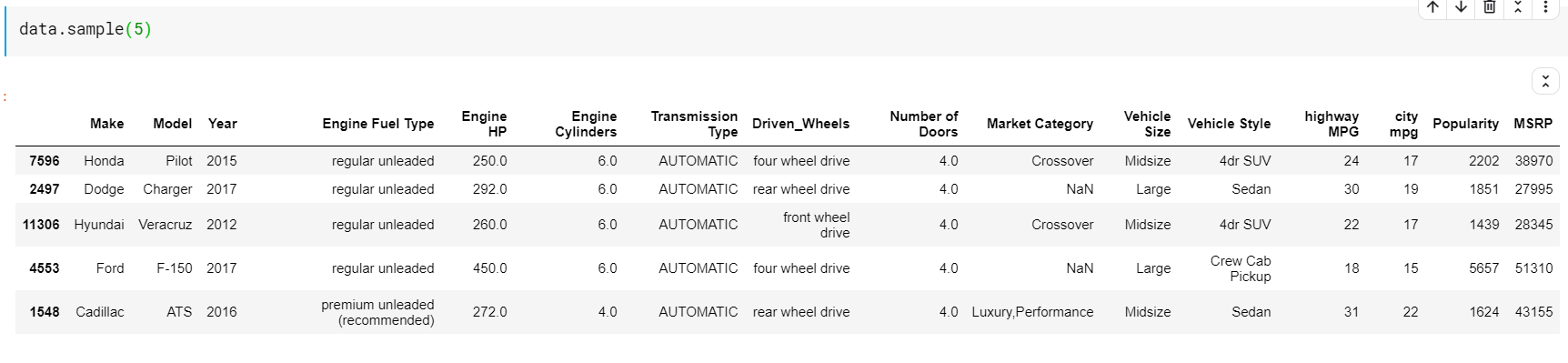
這裡要注意的一件事是函數頭和尾都為我們提供了頂部或底部索引。 但頂行或底行並不總是數據的良好預覽。 因此,您還可以使用 sample() 函數打印從數據集中隨機採樣的任意數量的行。
| # 隨機打印 5 行 數據樣本( 5 ) |
描述性統計
接下來,讓我們看看數據集的描述性統計數據。 描述性統計數據包含“描述”數據集的所有內容。 我們檢查數據框的形狀,所有列都存在,所有數字和分類特徵都有哪些。 我們還將看到如何在簡單的函數中完成所有這些工作。
形狀
| # 檢查數據框形狀 (mxn) # m=行數 # n=列數 數據形狀 |

如我們所見,這個數據框包含 11914 行和 16 列。
列
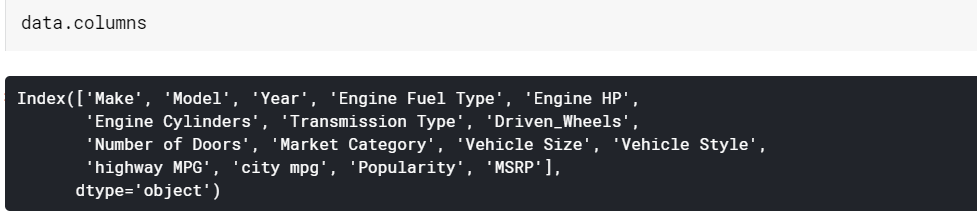
| # 打印列名 數據列 |
數據框信息
| # 打印列數據類型和非缺失值個數 數據信息() |
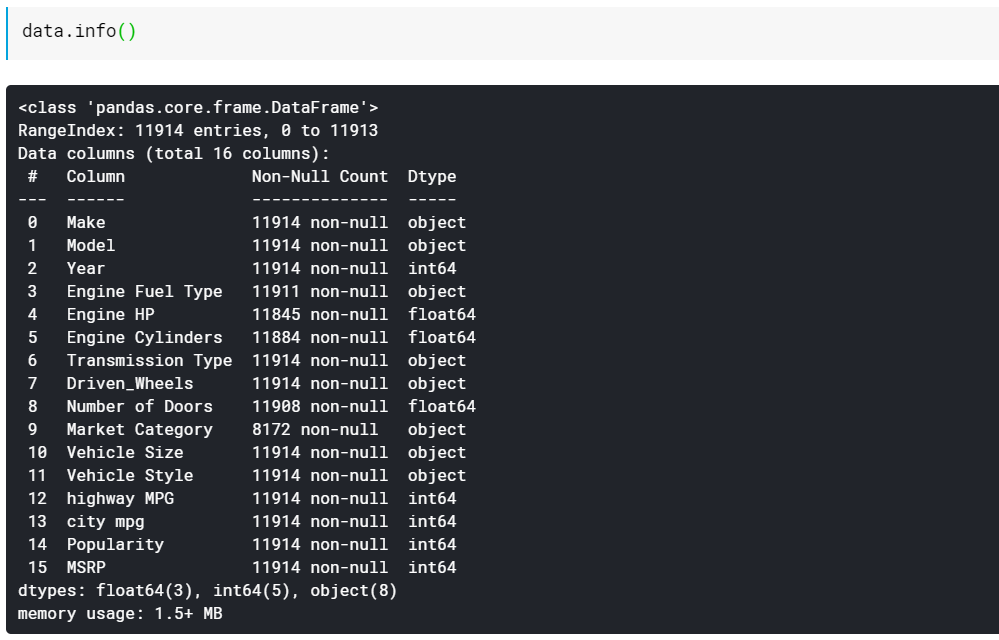
如您所見,info() 函數為我們提供了所有列,這些列中有多少非空或非缺失值,最後是這些列的數據類型。 這是查看所有特徵都是數字的以及所有特徵都是基於分類/文本的一種很好的快速方法。 此外,我們現在有關於所有列有哪些缺失值的信息。 稍後我們將研究如何處理缺失值。
操作列名和數據類型
仔細檢查和操作每一列在 EDA 中非常重要。 我們需要查看列/特徵包含的所有類型的內容以及 pandas 讀取其數據類型的內容。 數值數據類型主要是 int64 或 float64。 基於文本或分類的特徵被分配了“對象”數據類型。
分配基於日期時間的特徵 有時 Pandas 不理解特徵的數據類型。 在這種情況下,它只是懶惰地為其分配“對象”數據類型。 我們可以在使用 read_csv 讀取數據時明確指定列數據類型。
選擇分類和數值列
| # 將所有分類和數字列添加到單獨的列表中 分類 = data.select_dtypes( 'object' ).columns 數值 = data.select_dtypes( 'number' ).columns |


在這裡,我們作為“數字”傳遞的類型選擇所有具有任何數字類型的數據類型的列 - 無論是 int64 還是 float64。
重命名列
| # 重命名列名 data = data.rename(columns={ “引擎 HP” : “HP” , “發動機氣缸” : “氣缸” , “傳輸類型” : “傳輸” , “Driven_Wheels” : “驅動模式” , “高速公路 MPG” : “MPG-H” , “廠商建議零售價” : “價格” }) 數據頭( 5 ) |

rename 函數只接受一個字典,其中包含要重命名的列名及其新名稱。
處理缺失值和重複行
缺失值是任何現實生活數據集中最常見的問題/差異之一。 處理缺失值本身就是一個很大的話題,因為有多種方法可以做到這一點。 有些方法是更通用的方法,有些方法更具體到一個可能正在處理的數據集。
檢查缺失值
| # 檢查缺失值 data.isnull().sum() |
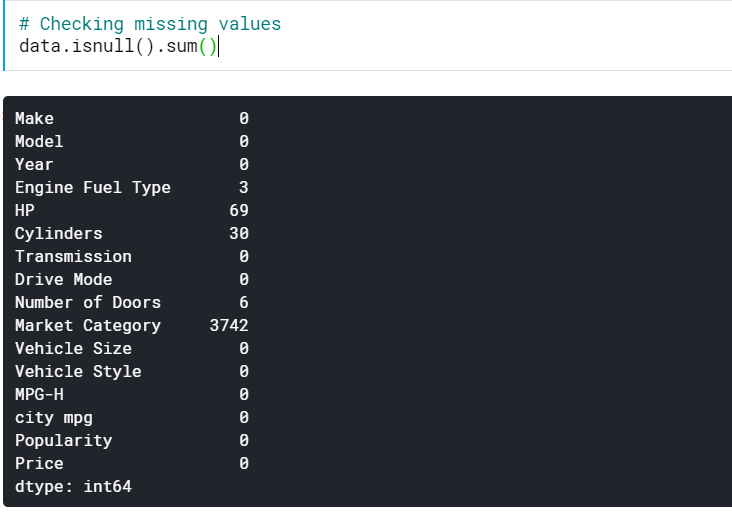
這為我們提供了所有列中缺少的值的數量。 我們還可以看到缺失值的百分比。
| # 缺失值的百分比 數據.isnull().mean()* 100 |
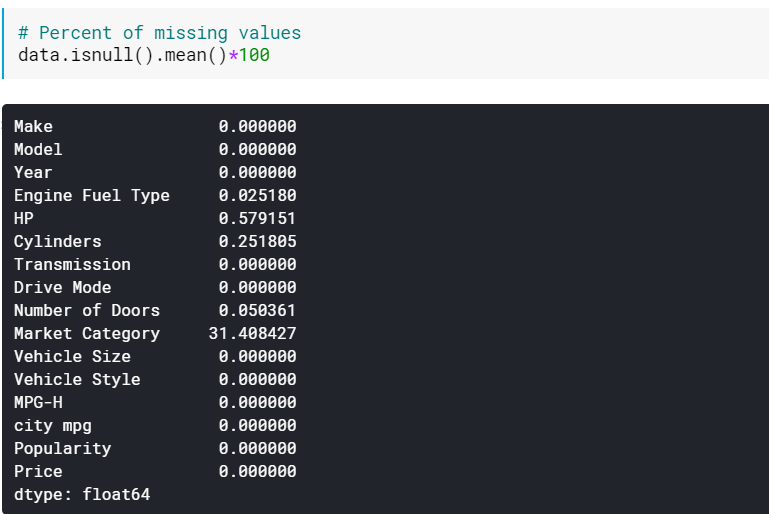
當有很多列缺失值時,檢查百分比可能很有用。 在這種情況下,可以刪除具有大量缺失值(例如,>60% 缺失)的列。
插補缺失值
| #按均值估算數值列的缺失值 數據[數值] = 數據[數值].fillna(數據[數值].mean().iloc[ 0 ]) #按模式估算分類列的缺失值 數據[分類] = 數據[分類].fillna(數據[分類].mode().iloc[ 0 ]) |
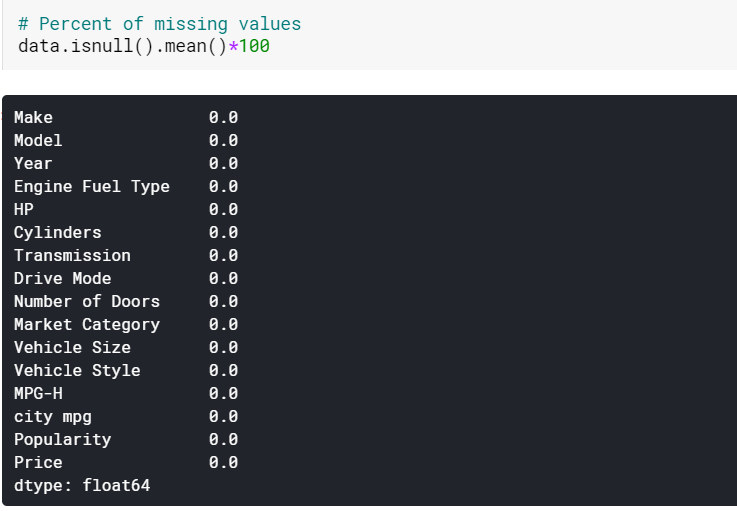
在這裡,我們簡單地通過它們各自的方式來估算數字列中的缺失值,並通過它們的模式來估算分類列中的缺失值。 正如我們所看到的,現在沒有缺失值。
請注意,這是估算值的最原始方法,在開發更複雜方法(例如插值、KNN 等)的實際案例中不起作用。
處理重複行
| # 刪除重複行 data.drop_duplicates(就地=真) |
這只會刪除重複的行。
結帳: Python 項目的想法和主題
雙變量分析
現在讓我們看看如何通過雙變量分析獲得更多見解。 雙變量是指由 2 個變量或特徵組成的分析。 有不同類型的繪圖可用於不同類型的功能。
對於數值 - 數值
- 散點圖
- 線圖
- 相關性的熱圖
對於分類數值
- 條形圖
- 小提琴情節
- 群體圖
對於分類-分類
- 條形圖
- 點圖
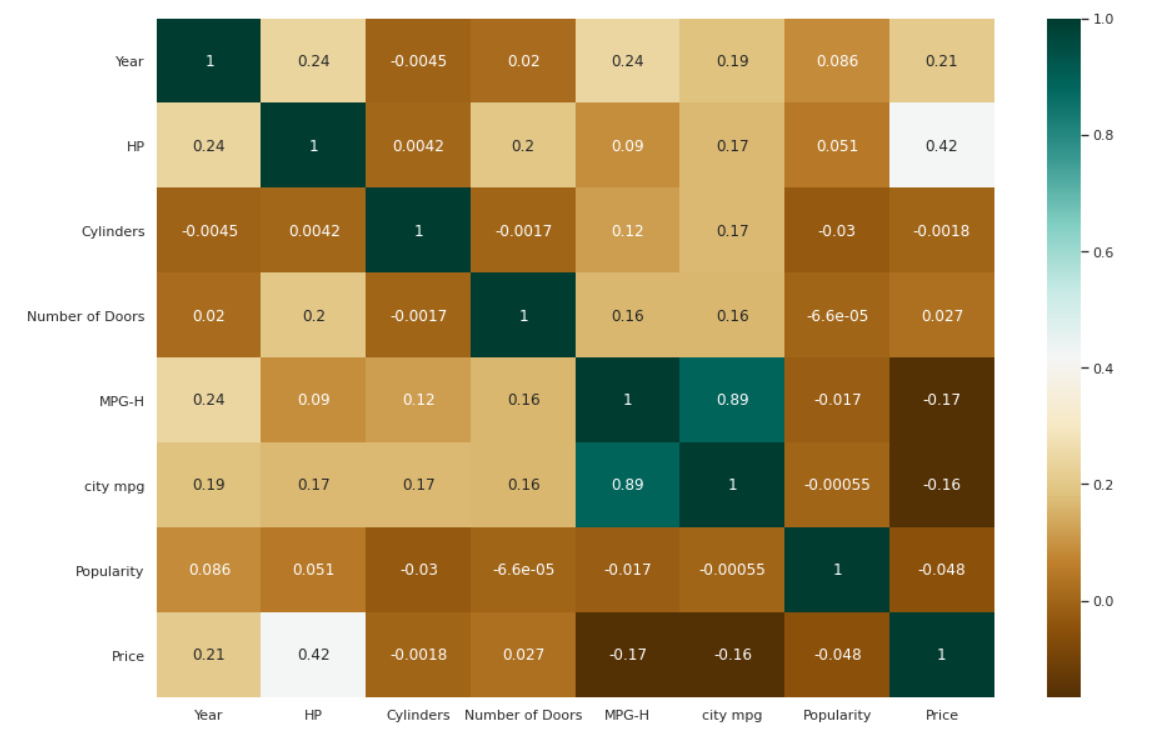
相關性的熱圖
| # 檢查變量之間的相關性。 plt.figure(figsize=( 15 , 10 )) c=data.corr() sns.heatmap(c,cmap= “BrBG” ,annot= True ) |
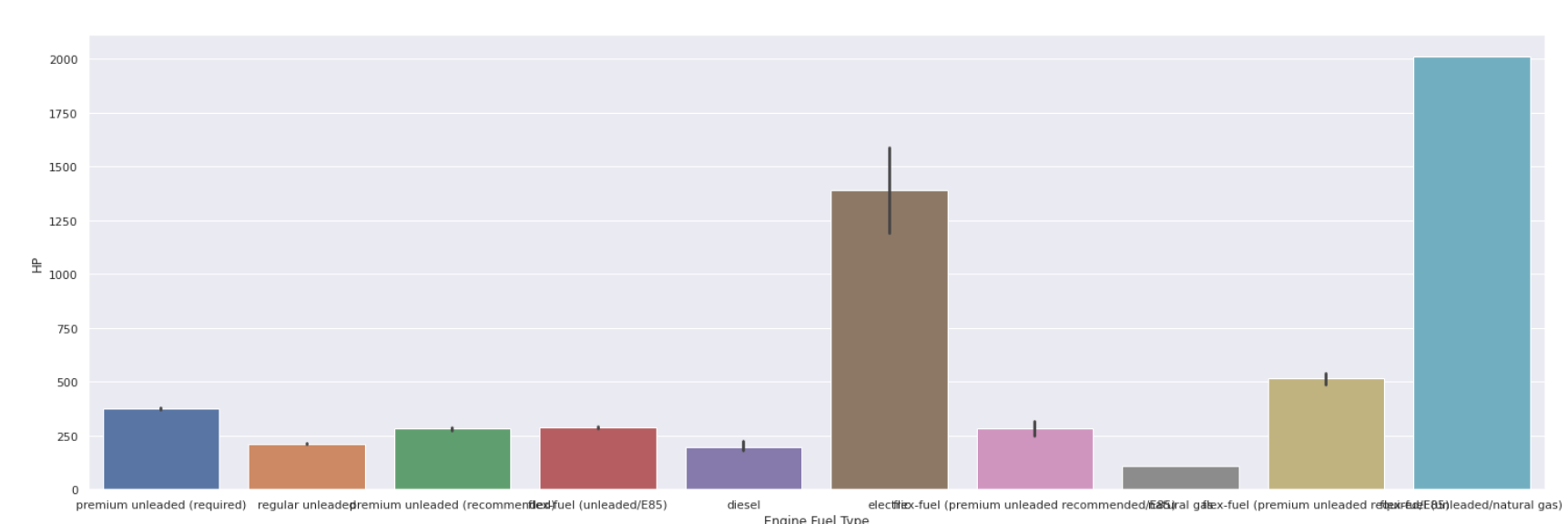
條形圖
| sns.barplot(數據[ '發動機燃料類型' ],數據[ 'HP' ]) |
獲得世界頂尖大學的數據科學認證。 學習行政 PG 課程、高級證書課程或碩士課程,以加快您的職業生涯。
結論
正如我們所看到的,在探索數據集時需要涵蓋很多步驟。 我們在本教程中只介紹了少數幾個方面,但這會給您提供的不僅僅是良好 EDA 的基本知識。
如果您想了解 Python 以及有關數據科學的所有知識,請查看 IIIT-B 和 upGrad 的數據科學 PG 文憑,該文憑專為在職專業人士而設,提供 10 多個案例研究和項目、實用的實踐研討會、行業指導專家,與行業導師一對一,400 多個小時的學習和頂級公司的工作協助。
探索性數據分析的步驟是什麼?
進行探索性數據分析所需執行的主要步驟是 -
必須識別變量和數據類型。
分析基本指標
單變量非圖形分析
單變量圖形分析
雙變量數據分析
可變的變換
缺失值處理
異常值的處理
相關性分析
降維
探索性數據分析的目的是什麼?
EDA 的主要目標是在做出任何假設之前協助分析數據。 它可以幫助檢測明顯的錯誤,更好地理解數據模式,檢測異常值或異常事件,以及發現變量之間的有趣關係。
數據科學家可以使用探索性分析來保證他們創建的結果準確且適合任何有針對性的業務成果和目標。 EDA 還通過確保他們解決適當的問題來幫助利益相關者。 標準偏差、分類數據和置信區間都可以用 EDA 來回答。 在完成 EDA 並提取見解後,其功能可應用於更高級的數據分析或建模,包括機器學習。
探索性數據分析有哪些不同類型?
有兩種 EDA 技術:圖形和定量(非圖形)。 另一方面,定量方法需要匯總統計數據,而圖形方法需要以圖表或可視方式收集數據。 單變量和多變量方法是這兩種方法的子集。
為了研究關係,單變量方法一次查看一個變量(數據列),而多變量方法一次查看兩個或多個變量。 單變量和多變量圖形和非圖形是 EDA 的四種形式。 定量程序更客觀,而圖像方法更主觀。