
為語義網開發
已發表: 2022-03-107 月,維基媒體基金會宣布了抽象維基百科,這是一種對與語言無關的知識進行標記的嘗試。 在許多方面,這是幾十年積累的高潮,在此期間,語義網的夢想從未完全起飛,但也從未完全消失。
事實上,語義網正在發展,隨著它更新其使命,我們都將從將語義標記納入我們的網站中獲益,無論是個人博客還是社交媒體巨頭。 無論您關心複雜的網絡體驗、搜索引擎優化,還是抵禦網絡壟斷的暴政,語義網都值得我們關注。
為語義網開發的好處並不總是立竿見影或可見的,但每一個確實加強了開放、透明、去中心化互聯網的基礎的網站。
語義網
語義網到底是什麼? 它是一個機器可讀的網絡,通過元數據提供“一個允許數據在應用程序、企業和社區邊界之間共享和重用的通用框架”。
這個想法與萬維網本身一樣古老。 年紀大了,其實。 這是蒂姆·伯納斯-李 1989 年提案的重點。 正如他概述的那樣,不僅文檔應該形成網絡,而且其中的數據也應該:
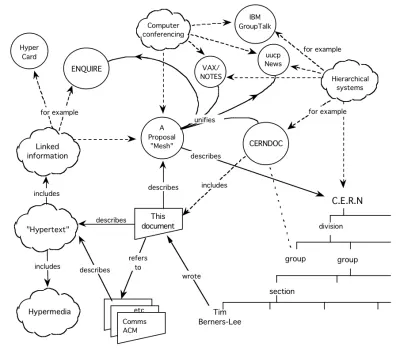
從那以後的幾十年裡,語義網的道路崎嶇不平。 自千年之交以來,它已經演變成多個概念——開放數據、知識圖譜——所有這些實際上都意味著同一個東西:數據網絡。
正如 W3C 總結的那樣,它是“當前網絡的擴展,其中信息被賦予了明確定義的含義,使計算機和人們能夠更好地合作工作。”

這個想法得到了相當多的擁護者。 互聯網黑客活動家 Aaron Swartz 寫了一本關於語義 Web 的書手稿,名為A Programmable Web 。 他在其中寫道:
“文檔無法真正實現合併、整合和查詢; 它們主要用作要查看和審查的孤立實例。 但數據是多變的,能夠轉變為最適合您需求的任何形式。”
由於各種原因,語義網雖然正在迎頭趕上,但並沒有像 Web 那樣起飛。 多年來,一些標記試圖佔據主導地位——RDFa、OWL 和 Schema 僅舉幾例——儘管沒有一個標記成為標準,例如 HTML 或 CSS。 進入門檻太高了。
然而,語義網的夢想一直在持續,隨著越來越多的網站將它融入他們的設計中,加入這個派對的理由也越來越多。 加入的網站越多,語義網就越強大。
延伸閱讀
- 數據智能
- 語義網,2001 年由 Tim Berners-Lee、James Hensley 和 Ora Lassila 撰寫的文章
- W3C 的可信網絡社區組
知識無國界
在深入了解如何為語義 Web 進行設計之前,有必要深入挖掘一下為什麼。 數據是否連接有什麼關係? 關聯的文檔還不夠嗎?
語義網繼續受到那些關心免費和開放互聯網的人的推動有幾個原因。 了解這些原因對於實施過程至關重要。 這不應該是“吃你的蔬菜,使用語義標記”的情況。 語義網是值得信賴和參與的。
語義網的好處包括:
- 更豐富、更複雜的網絡體驗
- 繞過內容孤島和互聯網壟斷
- 提高搜索引擎的可讀性和排名
- 信息民主化
其中大部分可以追溯到語義網的核心原則:數據的通用語言。 儘管互聯網已經為國際交流創造了奇蹟,但無法迴避的事實是,有些國家的互聯網比其他國家好得多。 以網絡上使用的語言與現實世界中使用的語言為例。 你們中的鷹眼也許能夠在下面的數據中發現輕微的不平衡……
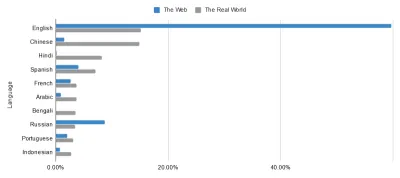
網絡的無邊界烏托邦並不像我們這些處於英語泡沫中的人所想的那樣接近。 這是為了懲罰任何人嗎? 不一定,但這是要面對的事情。 這樣做突出了彌合這些差距的標記的重要性。 通過豐富網絡數據,我們減輕了其語言的壓力。
這是最近宣布的抽象維基百科的癥結所在,它將試圖將文章與它們所使用的語言分離。維基媒體執行董事凱瑟琳馬赫寫道:“使用代碼,志願者將能夠將這些抽象的‘文章’翻譯成他們自己的語言。 如果成功,這最終可以讓每個人都以自己的語言閱讀維基數據中的任何主題。”
摘要 Wikipedia 的創建者 Denny Vrandecic 多年來一直是語義網的倡導者,他認識到它具有釋放在線未開發潛力的潛力。 打破國家壁壘對於這一進程至關重要。
“無論你用什麼語言發布你的內容,你都會錯過包括世界上絕大多數人的機會。 網絡為我們提供了一個獲得全球影響力的絕好機會——但依靠一種語言或一小部分語言,我們正在浪費這個機會。 雖然最重要的目標是首先創建好的內容,但您可以通過獨立於語言來邀請更多的人參與到更好的內容的開發中。 它可以幫助您降低貢獻和消費的門檻,並讓更多的人從這項努力中受益。”
— Denny Vrandecic,抽象維基百科創建者
COVID-19 大流行期間的數據可視化就是一個及時的例子。 該病毒在全球範圍內造成了難以形容的破壞,但它也是開放數據網絡的一個閃光時刻,它允許出色的網絡應用程序、報告等在網絡上普遍存在。
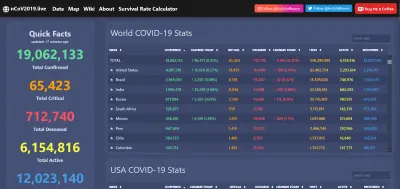
當然,當數據透明且易於訪問時,就更容易識別異常……或直接欺騙。 即使在 20 年前,公眾對上述信息的廣泛訪問也是不可想像的。 現在我們期待它,並在它拒絕我們時聞到老鼠的味道。 數據是強大的,如果我們願意,可以永遠使用它。
同樣,將自己排除在內容孤島之外——現代網絡體驗的一個標誌——會從谷歌、Facebook 和 Twitter 等網絡壟斷企業手中奪走權力。 我們已經習慣了第三方平台解密和呈現信息,以至於我們忘記了它們並不是絕對必要的。
“如果我們有共享格式、共享協議,我們最終可能仍會讓某些提供商在某些市場發揮重要作用——想想 Gmail 的電子郵件——但每個人都可以自由地轉移到另一個提供商,市場仍然具有競爭力。”
— Denny Vrandecic,抽象維基百科創建者
語義網是無孤島的; 它是免費的、開放的和抽象的,可以實現不同語言和平台之間的通信,否則會更加困難。
數據化在線內容
語義網設計歸結為數據化在線內容——查看您的內容並了解可以(並且應該)抽象的內容。 除了模糊地同意這是一件值得做的事情之外,這實際上意味著什麼? 這取決於:
- 如果從頭開始一個項目,請將語義 Web 考慮因素納入您的工作中。 隨著網站的形成,將語義標記編織到其 DNA 中。
- 如果更新或重建一個項目,請評估可以融入語義網但目前還沒有的東西,然後實施。
這兩種情況基本上都相當於數據內容。 在本節中,我們將介紹一些數據抽象的示例,以及它如何使內容更好、更智能和更廣泛地可用。
抽象信息
為語義網設計和開發意味著帶著你的數據查看在線內容。 我們大多數人將網絡視為一系列相互連接的文檔或頁面。 你想用語義網做的是連接信息。 這意味著評估您的數據點內容,然後根據您的發現調整設計。
語義網倡導者 James Hendler 用他的 DIVE 精神很好地概述了這個過程。 (深入研究數據,嗯?嗯?)。 它分解如下:
- 發現
查找數據集和/或內容(包括在您自己的組織之外)。 - 整合
使用有意義的標籤鏈接關係。 - 證實
為建模和仿真係統提供輸入。 - 探索
開發將數據轉化為可操作知識的方法。
為語義網開發主要是要對您所做的事物進行鳥瞰,以及它如何潛在地為無限豐富的網絡體驗提供服務。 正如 Hendler 所說,可操作的知識是目標。
這實際上可以應用於幾乎任何類型的網絡內容,但讓我們從一個常見的例子開始:食譜。 假設您經營一個烹飪博客,每週四都有新食譜。 如果您是法國人,並且在您的個人博客上以純文本的形式發布了一個非常棒的蛋奶酥食譜,那麼它只對那些能夠閱讀法語的人有用。
但是,通過實現語義標記,可以將博客轉換為機器可讀的食譜數據集。 存在用於抽象烹飪術語的語法。 例如,Schema 可以與 Microdata、RDFa 或 JSON-LD 一起使用,其標記包括:
- 準備時間
- 烹飪時間
- 配方產量
- 食譜成分
- 估計成本
- 營養,分解成卡路里和脂肪含量
- 適合飲食。
我可以繼續。 可以在 Schema.org 上閱讀所有選項以及示例。 將它們添加到帖子格式中,配方的格式根本不需要改變——您只需將信息放在計算機可以理解的術語中。
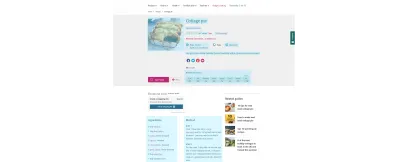
例如,上面 BBC 食譜中以藍色突出顯示的所有內容也都被賦予了語義標記——從烹飪時間到營養成分。 您可以通過將配方 URL 輸入到 Google 的豐富結果測試中來查看幕後情況。 請注意“添加到購物清單”功能,這是通過語義 Web 實現實現的連接示例。 好的內容變成可用的數據。

我們大多數人都通過搜索結果遇到過這種複雜性的道路,但應用範圍遠不止於此。 食譜的語義標記使家庭助理更容易找到和使用網站。 所列食材可從當地超市訂購。 食譜可以通過各種方式進行過濾——飲食、過敏、宗教、成本等等。 或者假設你家裡的原料數量有限。 使用數據庫,您可以輸入這些成分並查看符合要求的食譜。
可能性的範圍確實是無限的。 正如 Swartz 所說,數據是多變的。 一旦擁有它,您就可以以各種奇怪而奇妙的方式使用它。 這篇文章不是關於那些奇怪而美妙的方式,而是關於使它們成為可能。 為語義網設計使後續的設計無限豐富。
這是一個更個人的例子來說明我的意思。 我和幾個朋友經營一個小小的音樂網絡雜誌作為一種愛好。 雖然我們發表了奇怪的文章或採訪,但“主要事件”是我們每週的專輯評論,我們三個人每人都會分配一個分數,選擇最喜歡的曲目,然後寫總結。 我們已經進行了五年多,這意味著我們有接近 250 條評論,這意味著大量的潛在數據。 直到我們開始重新設計網站,我們才意識到有多少。
我在一篇關於將結構化數據烘焙到設計過程中的文章中談到了這一點。 在剖析我們的評論時,我們意識到它們充滿了可以給予語義標記的信息。 藝術家、專輯名稱、藝術作品、發行日期、個人樂譜、總樂譜、發行類型等。 更重要的是——這才是真正令人興奮的地方——我們意識到我們可以連接到現有的數據庫:MusicBrainz。
這種雙向方法是語義網的關鍵。 當我們的音樂網站重新啟動時,它將成為擁有數千個獨特數據點的自己的開放數據源。 連接到現有的音樂數據庫將為我們自己的數據提供更多背景和潛力。 數千個數據點變成數万個數據點,甚至更多。
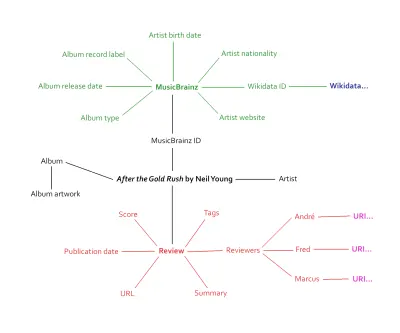
上圖僅涉及將多少信息連接到評論頁面的表面。 內容和以前一樣,只是現在它被插入到元數據生態系統中——正如 Berners-Lee 曾經所說的 Giant Global Graph。
為語義網開發意味著識別您自己的數據,標記它,然後弄清楚它如何連接到其他數據。 因為確實如此。 它總是這樣。 這個過程就是這樣……
……時間變成了這個……
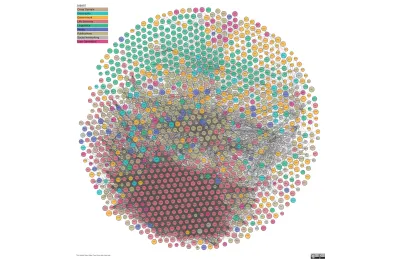
第二張圖片是 The Linked Open Data Cloud,這是一個不斷更新的網絡連接數據的可視化。 那個紅色的聯繫蜂巢是科學; 其餘的還有一段路要走。 這就是我們進來的地方。
有用的語義網資源
- w3schools.com 上的 RDF
- W3C 的 RDF 驗證器
- W3C 的“The Semantic Web Made Easy”
- “語義網發生了什麼?” 通過兩位歷史
- JSON-LD 生成器
- Google 的結構化數據標記助手
插入
語義網的理想是連接。 製作數據、共享數據、需求數據。 成為信息生態系統的一部分。 當您創建原始數據時,非常棒。 分享它。 當數據已經存在並且您想使用它時,將其拉入。
這裡只是一些數據資源:
- 百度百科
- 音樂腦
- 世界貓
- ISBN數據庫
事實上,在存在這樣的數據庫的地方,我什至會說正確的做法是在它們缺乏信息的地方更新它們。 為什麼要留給自己? 成為貢獻者,語義網倡導者。
執行
就在您的網站中構建 Semantic Webness 而言,我當然不提倡手動、逐個文檔標記。 誰有時間做這個? 解決方案通常是標準化格式並為其模板化的情況。
模板是這裡的大好機會。 有多少人真正有時間手動標記所有這些信息? 但是,如果您有自定義輸入,則可以兩全其美。 內容可以充滿對人友好的信息,並且信息作為數據存在,隨時可以服務於想到的任何目的。
舉個例子,像 Eleventy 這樣的靜態站點生成器,它最近受到了開發社區的喜愛。 你寫了一篇文章,通過一個模板運行它,你就是金子。 那麼為什麼不將語義標記合併到模板本身呢?
與 Eleventy 一樣,我們的音樂網站的新版本使用 Markdown 發布帖子。 雖然我們有與往常一樣的舊文本帖子,但現在每條評論還包括以下元數據輸入,然後將其拉入模板:
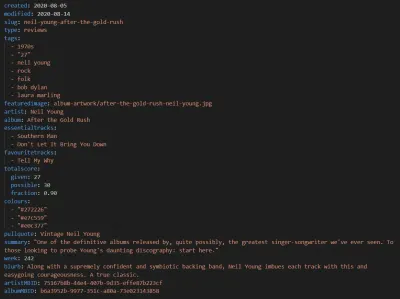
連同帖子正文中的作者詳細信息和一些通用網站信息,這將轉化為以下語義標記:
<script type="application/ld+json"> { "@context": "https://schema.org/", "@type": "Review", "reviewBody": "One of the definitive albums released by, quite possibly, the greatest singer-songwriter we've ever seen. To those looking to probe Young's daunting discography: start here.", "datePublished": "2020-08-14", "author": [{ "@type": "Person", "name": "Andre Dack" }, { "@type": "Person", "name": "Frederick O'Brien" }, { "@type": "Person", "name": "Marcus Lawrence" }], "itemReviewed": { "@type": "MusicAlbum", "name": "After the Gold Rush", "@id": "https://musicbrainz.org/release-group/b6a3952b-9977-351c-a80a-73e023143858", "image": "https://audioxide.com/images/album-artwork/after-the-gold-rush-neil-young.jpg", "albumProductionType": "https://schema.org/StudioAlbum", "albumReleaseType": "https://schema.org/AlbumRelease", "byArtist": { "@type": "MusicGroup", "name": "Neil Young", "@id": "https://musicbrainz.org/artist/75167b8b-44e4-407b-9d35-effe87b223cf" } }, "reviewRating": { "@type": "Rating", "ratingValue": 27, "worstRating": 0, "bestRating": 30 }, "publisher": { "@type": "Organization", "name": "Audioxide", "description": "Independent music webzine founded in 2015. Publishes reviews, articles, interviews, and other oddities.", "url": "https://audioxide.com", "logo": "https://audioxide.com/logo-location.jpg", "sameAs" : [ "https://facebook.com/audioxide", "https://twitter.com/audioxide", "https://instagram.com/audioxidecom" ] } } </script>以前只有文字,現在在每個評論頁面上,讀者在訪問網站時看到的內容也將有機器可讀的版本。 文字還在那裡,內容幾乎沒有改變——只是被數據化了。 從豐富的搜索結果到交互式評論統計頁面,這極大地增加了可能性。 前面的路是寬闊的。 它也讓我們在 MusicBrainz 的未來中佔有一席之地。 通過將他們的數據連接到我們自己的數據,我們反過來希望看到它做得好,並將盡我們所能確保它做得好。
適當的語義標記取決於網站的性質,但它存在的可能性很大。 從明顯的輸入(日期、作者、內容類型等)開始,然後逐步進入內容的雜草。 第一步可以像您個人網站的 hCard(一種數字身份證)一樣簡單。 打印頁面截圖並開始註釋。 您會驚訝於有多少內容可以被數據化。
超乎想像
為語義網設計和開發是一種可以追溯到互聯網創始理想的實踐。 無論您重視美觀、信息豐富的數據可視化,想要更複雜的搜索結果,希望消除網絡壟斷的力量,還是僅僅相信自由和開放的信息,語義網都是您的盟友。
Aaron Swartz 以希望的呼喚結束了他的手稿:
“語義網是基於賭注的,賭注是為世界提供輕鬆協作和交流的工具將帶來如此美妙的可能性,我們現在幾乎無法想像它們。”
摘要 Wikipedia Denny Vrandecic 今天回應了這些觀點,他說:
“需要一個網絡基礎設施來促進服務之間的互操作性,這需要一套通用的數據表示標準和跨提供商的通用協議。”
語義網已經跛足了很長時間,以至於很明顯銀彈語言不太可能出現,但現在有足夠的和平共處讓伯納斯-李的創始夢想成為大多數網絡的現實。 我們每個人都可以成為我們自己社區的倡導者。
變得更好,要求更好
正如 Tim Berners-Lee 所說,語義 Web 既是一種文化,也是一種技術障礙。 在 2009 年的 TED 演講中,他很好地總結了這一點:製作關聯數據,需求關聯數據。 現在比以往任何時候都更真實。 萬維網只有我們強迫它成為開放、連接和良好的狀態。 每當你在網上做某事時,問問自己,“這怎麼能插入語義網?” 答案將為我們創造的事物增添新的維度,並在未來幾年創造難以想像的美妙新可能性。