
Python 中的數據可視化:基本圖解釋 [帶圖解]
已發表: 2021-02-08目錄
基本設計原則
對於任何有抱負或成功的數據科學家來說,能夠解釋你的研究和分析是一項非常重要且有用的技能。 這就是數據可視化出現的地方。 誠實地使用這個工具至關重要,因為觀眾很容易被錯誤的設計選擇誤導或欺騙。
作為數據科學家,我們在維護真實數據方面都有一定的義務。
首先是我們在清理和匯總數據時應該對自己完全誠實。 數據預處理對於任何機器學習算法來說都是一個非常關鍵的步驟,因此數據中的任何不誠實都會導致截然不同的結果。
另一個義務是對我們的目標受眾。 數據可視化中有多種技術可用於突出數據的特定部分並使其他一些數據不那麼突出。 因此,如果我們不夠仔細,讀者將無法正確地探索和判斷分析,從而導致懷疑和缺乏信任。
對於數據科學家來說,總是質疑自己是一個很好的特質。 我們應該始終考慮如何以一種易於理解且美觀的方式展示真正重要的內容,同時記住上下文很重要。
這正是阿爾貝托·開羅在他的教義中試圖描繪的。 他提到了大觀的五種品質:美麗、開悟、功能、洞察力和真實,值得牢記。
一些基本情節
現在我們對設計原則有了基本的了解,讓我們深入了解一些使用 python 中的matplotlib庫的基本可視化技術。
下面的所有代碼都可以在 Jupyter 筆記本中執行。
%matplotlib 筆記本
# 這提供了一個交互環境並設置了後端。 ( %matplotlib inline也可以使用,但它不是交互式的。這意味著對繪圖函數的任何進一步調用都不會自動更新我們的原始可視化。)
import matplotlib.pyplot as plt # 導入需要的庫模塊
點圖
繪製點的最簡單的matplotlib函數是plot() 。 參數表示 X 和 Y 坐標,然後是描述數據輸出應如何顯示的字符串值。
plt.figure()
plt.plot( 5, 6, '+' ) # + 號作為標記
散點圖
散點圖是二維圖。 scatter()函數還將 X 值作為第一個參數,將 Y 值作為第二個參數。 下圖是一條對角線, matplotlib會自動調整兩個軸的大小。 在這裡,散點圖不會將項目視為一個系列。 因此,我們還可以給出與每個點對應的所需顏色的列表。
將 numpy 導入為 np
x = np.array( [1, 2, 3, 4, 5, 6, 7, 8] )
y = x
plt.figure()
plt.scatter( x, y )
線圖
線圖是使用plot()函數創建的,並繪製了許多不同系列的數據點,如散點圖,但它將每個點系列與一條線連接起來。
將 numpy 導入為 np
線性數據 = np.array( [1, 2, 3, 4, 5, 6, 7, 8] )
平方數據 = 線性數據**2
plt.figure()
plt.plot(線性數據,“-o”,平方數據,“-o”)
為了使圖表更具可讀性,我們還可以添加一個圖例,它會告訴我們每條線代表什麼。 圖表和兩個軸的合適標題很重要。 此外,可以使用fill_between()函數對圖形的任何部分進行著色以突出顯示相關區域。
plt.xlabel('X 值')

plt.ylabel('Y 值')
plt.title('線圖')
plt.legend(['線性','平方'])
plt.gca().fill_between( range ( len ( linear_data ) ), linear_data, squared_data, facecolor = 'blue', alpha = 0.25)
這就是修改後的圖表的樣子——
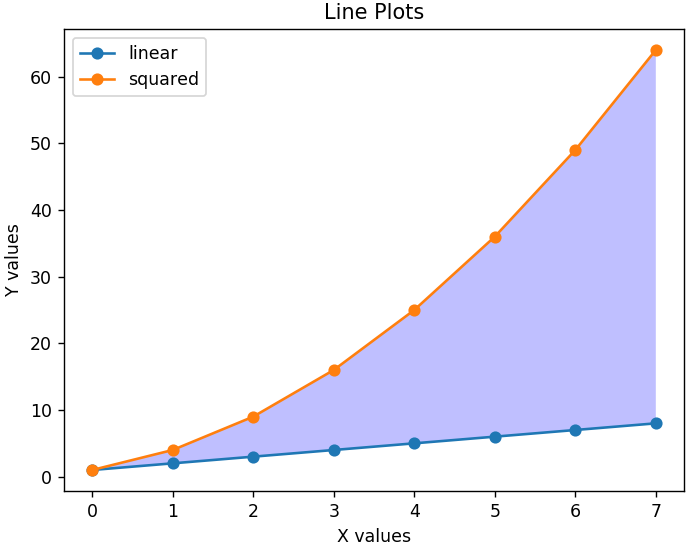
條形圖
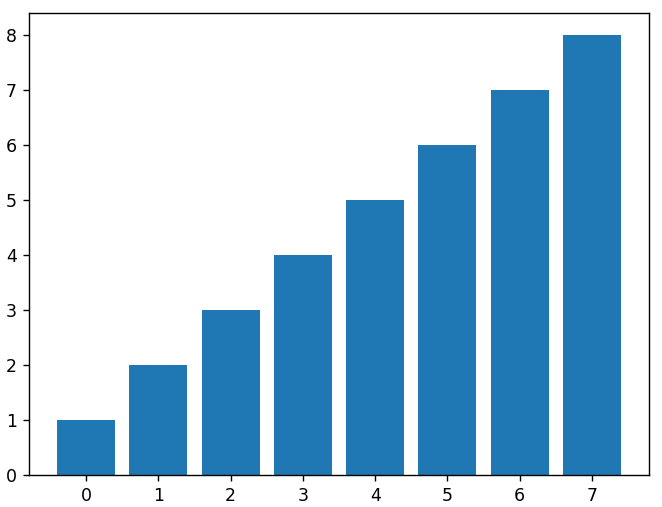
我們可以通過將 X 值和每個條的高度的參數發送到bar()函數來繪製條形圖。 下面是我們上面使用的相同線性數據數組的條形圖。
plt.figure()
x = 範圍(長度(線性數據))
plt.bar(x,線性數據)
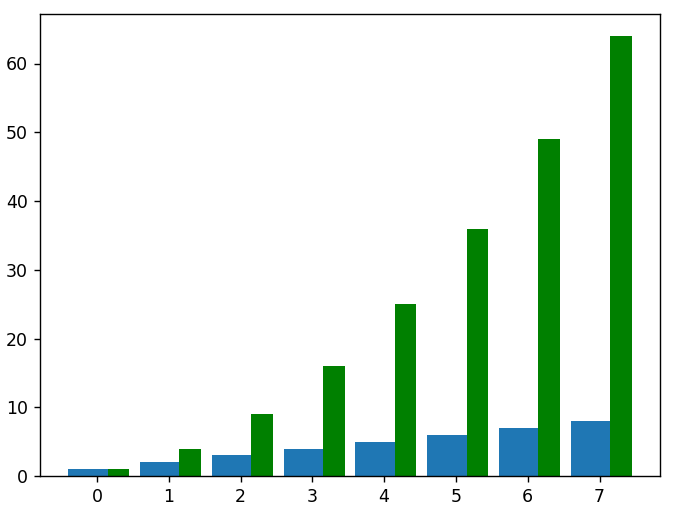
# 為了將平方數據繪製為同一圖表上的另一組條形圖,我們必須調整新的 x 值以彌補第一組條形圖
新_x = []
對於 x 中的數據:
new_x.append(數據+0.3)
plt.bar(new_x, squared_data, width = 0.3, color = 'green')
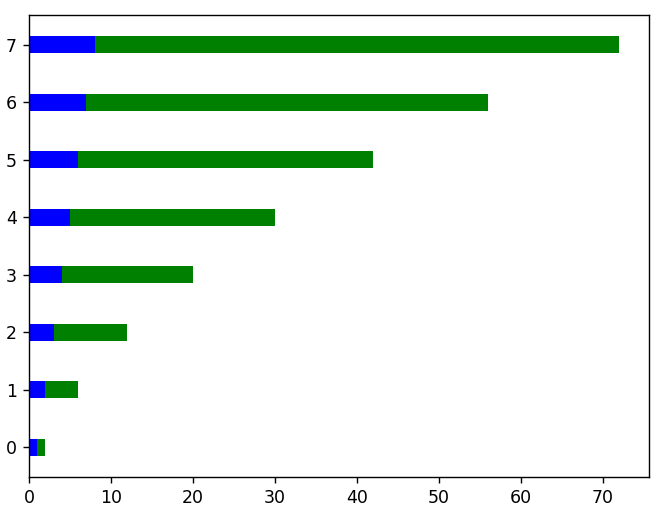
# 對於水平方向的圖,我們使用barh()函數
plt.figure()
x = 範圍(長度(線性數據))
plt.barh(x,線性數據,高度 = 0.3,顏色 = 'b')
plt.barh(x, squared_data, height = 0.3, left = linear_data, color = 'g')
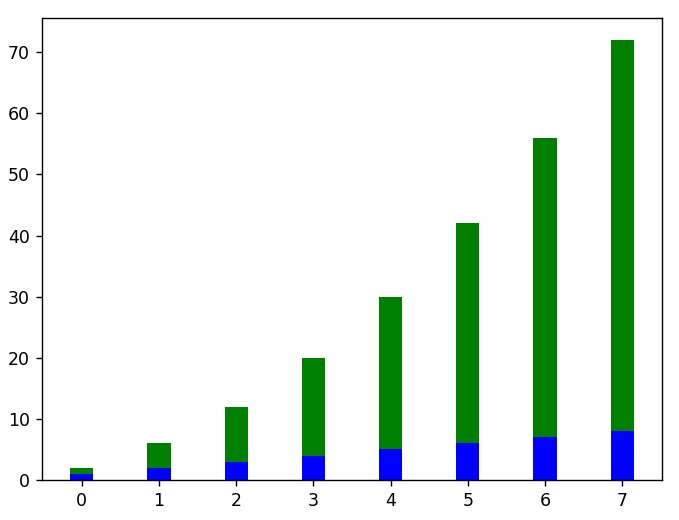
#這裡是一個垂直堆疊條形圖的例子
plt.figure()
x = 範圍(長度(線性數據))
plt.bar(x,線性數據,寬度 = 0.3,顏色 = 'b')
plt.bar(x,squared_data,寬度 = 0.3,底部 = 線性數據,顏色 = 'g')
學習世界頂尖大學的數據科學課程。 獲得行政 PG 課程、高級證書課程或碩士課程,以加快您的職業生涯。
結論
可視化類型不僅僅止於此。 Python 還有一個很棒的名為seaborn的庫,絕對值得探索。 適當的信息可視化極大地有助於增加我們數據的價值。 數據可視化將始終是獲得洞察力和識別各種趨勢和模式的更好選擇,而不是查看包含數百萬條記錄的無聊表格。
如果您想了解數據科學,請查看 IIIT-B 和 upGrad 的數據科學 PG 文憑,該文憑專為在職專業人士而設,提供 10 多個案例研究和項目、實用的實踐研討會、與行業專家的指導、1-與行業導師面對面交流,400 多個小時的學習和頂級公司的工作協助。
有哪些有用的 Python 數據可視化包?
Python 有一些用於數據可視化的驚人而有用的包。 下面提到了其中一些軟件包:
1. Matplotlib - Matplotlib 是一個流行的 Python 庫,用於以散點圖、條形圖、餅圖和折線圖等各種形式進行數據可視化。 它使用 Numpy 進行數學運算。
2. Seaborn - Seaborn 庫用於 Python 中的統計表示。 它是在 Matplotlib 之上開發的,並與 Pandas 數據結構集成。
3. Altair - Altair 是另一個流行的用於數據可視化的 Python 庫。 它是一個聲明性統計庫,可讓您以最少的編碼創建視覺效果。
4. Plotly - Plotly 是 Python 的交互式開源數據可視化庫。 這個基於瀏覽器的庫創建的視覺效果受到許多平台的支持,例如 Jupyter Notebook 和獨立的 HTML 文件。
你對點圖和散點圖了解多少?
點圖是數據可視化中最基本、最簡單的圖。 點圖以笛卡爾平面上的點的形式顯示數據。 “+”表示值的增加,而“-”表示值隨時間的減少。
另一方面,散點圖是優化的圖,其中數據在二維平面上可視化。 它是使用 scatter() 函數定義的,該函數將 x 軸值作為第一個參數,將 y 軸值作為第二個參數。
數據可視化有哪些優勢?
以下優勢展示了數據可視化如何成為組織發展的真正英雄:
1. 數據可視化使解釋原始數據和理解它以進行進一步分析變得更加容易。
2. 研究和分析數據後,可以使用有意義的可視化顯示結果。 這使得與觀眾聯繫和解釋結果變得更容易。
3. 該技術最重要的應用之一是分析模式和趨勢,以推斷預測和潛在的增長領域。
4. 它還允許您根據客戶偏好隔離數據。 您還可以確定需要更多關注的區域。