
每個數據科學家都應該擁有的終極數據科學備忘單
已發表: 2021-01-29對於所有正在考慮潛入蓬勃發展的數據科學世界的初露頭角的專業人士和新手,我們編制了一份快速備忘單,讓您了解強調該領域的基礎知識和方法論。
目錄
數據科學-基礎
在我們的世界中生成的數據是原始形式,即數字、代碼、單詞、句子等。數據科學利用這些非常原始的數據使用科學方法對其進行處理,將其轉換為有意義的形式,以獲得知識和見解.
數據
在深入探討數據科學的原則之前,讓我們先談談數據、它的類型和數據處理。
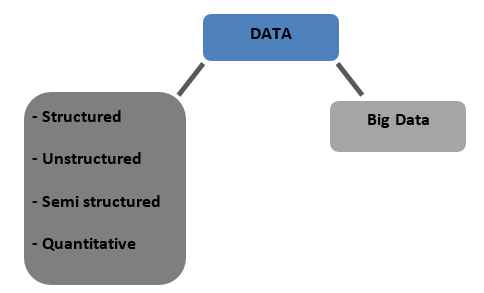
數據類型
結構化– 以表格格式存儲在數據庫中的數據。 它可以是數字或文本
非結構化數據——不能用任何明確的結構製成表格的數據稱為非結構化數據
半結構化——具有結構化和非結構化數據特徵的混合數據
定量的——具有可量化的明確數值的數據
大數據——存儲在跨越多台計算機或服務器場的巨大數據庫中的數據稱為大數據。 生物特徵數據、社交媒體數據等被視為大數據。 大數據的特點是 4 V
數據預處理
數據分類——這是將數據分類或標記為數字、文本或圖像、文本、視頻等類別的過程。
數據清理——它包括清除丟失/不一致/不兼容的數據或使用以下方法之一替換數據。
- 插值
- 啟發式
- 隨機分配
- 最近鄰
數據屏蔽– 隱藏或屏蔽機密數據以維護敏感信息的隱私,同時仍能對其進行處理。
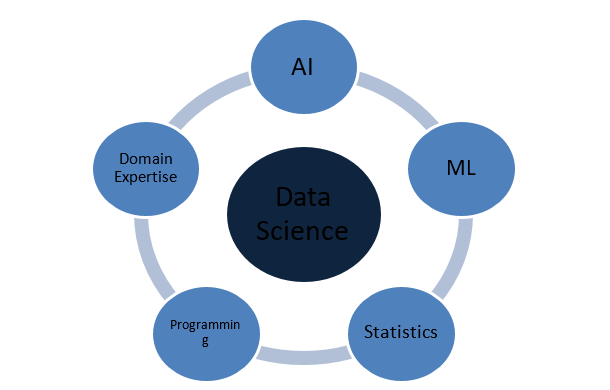
數據科學是由什麼組成的?
統計概念
回歸
線性回歸
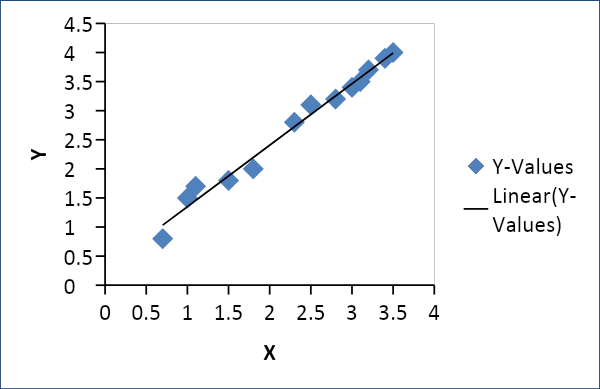
線性回歸用於建立供需、價格和消費等兩個變量之間的關係。它將一個變量 x 作為另一個變量 y 的線性函數,如下所示
Y = f(x) 或 Y =mx + c,其中 m = 係數
邏輯回歸
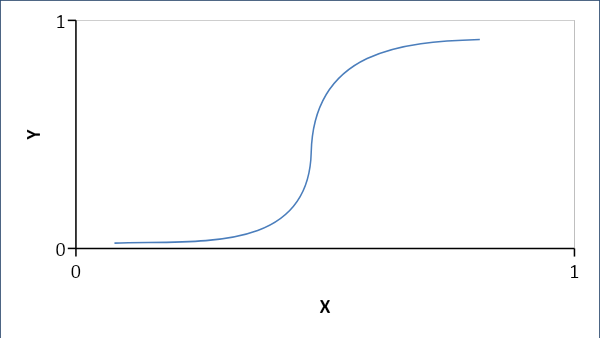
邏輯回歸建立了一種概率關係,而不是變量之間的線性關係。 結果答案是 0 或 1,我們尋找概率,曲線是 S 形曲線。
如果 p < 0.5,則為 0,否則為 1
公式:
Y = e^ (b0 + b1x) / (1 + e^ (b0 +b1x))
其中 b0 = 偏差和 b1 = 係數
可能性
概率有助於預測事件發生的可能性。 一些術語:
樣本:一組可能的結果
事件:它是樣本空間的子集
隨機變量:隨機變量有助於將可能的結果映射或量化為樣本空間中的數字或線條
概率分佈
離散分佈:以一組離散值(整數)的形式給出概率
P[X=x] = p(x)
 圖片來源
圖片來源
連續分佈:給出多個連續點或區間而不是離散值的概率。 公式:
P[a ≤ x ≤ b] = a∫bf(x) dx,其中 a, b 是點
圖片來源
相關性和協方差
標準偏差:給定數據集與其平均值的變化或偏差
σ = √ {(Σi=1N ( xi – x ) ) / (N -1)}
協方差
它定義了隨機變量 X 和 Y 與數據集的平均值的偏差程度。
Cov(X,Y) = σ2XY = E[(X−μX)(Y−μY)] = E[XY]−μXμY
相關性
相關性定義變量之間線性關係的程度及其方向,+ve 或 -ve
ρXY= σ2XY/ σX * *σY
人工智能
機器獲取知識並根據輸入做出決策的能力稱為人工智能或簡稱 AI。
類型
- 反應式機器:反應式機器人工智能通過縮小到最快和最好的選項來學習對預定義的場景做出反應。 它們缺乏內存,最適合具有定義的參數集的任務。 高度可靠和一致。
- 內存有限:這個人工智能有一些現實世界的觀察數據和遺留數據。 它可以根據給定的數據進行學習和決策,但無法獲得新的經驗。
- 心智理論:它是一種交互式人工智能,可以根據周圍實體的行為做出決策。
- 自我意識:這個人工智能意識到它的存在和遠離周圍環境的功能。 它可以發展認知能力,理解和評估自己的行為對周圍環境的影響。
人工智能術語
神經網絡

神經網絡是一組互連節點或網絡,它們在系統中中繼數據和信息。 神經網絡被建模為模仿我們大腦中的神經元,並且可以通過學習和預測來做出決定。
啟發式
啟發式方法是在可用信息不完整的情況下使用先前經驗快速基於近似值和估計進行預測的能力。 它很快但不准確或不精確。
基於案例的推理
從以前的問題解決案例中學習並在當前情況下應用它們以得出可接受的解決方案的能力
自然語言處理
這只是機器直接理解人類語音或文本並與之交互的能力。 例如,汽車中的語音命令
機器學習
機器學習只是人工智能的一種應用,它使用各種模型和算法來預測和解決問題。
類型
監督
此方法依賴於與輸出數據相關聯的輸入數據。 機器有一組目標變量 Y,它必須在優化算法的監督下通過一組輸入變量 X 到達目標變量。 監督學習的例子有神經網絡、隨機森林、深度學習、支持向量機等。
無監督
在這種方法中,輸入變量沒有標籤或關聯,算法致力於尋找模式和集群,從而產生新的知識和見解。
加強型
強化學習側重於即興創作技巧,以提高或完善學習行為。 這是一種基於獎勵的方法,機器逐漸改進其技術以贏得目標獎勵。
建模方法
回歸
回歸模型總是通過連續數據的插值或外推將數字作為輸出。
分類
分類模型將輸出作為類或標籤提出,並且更擅長預測離散結果,例如“什麼樣的”
回歸和分類都是監督模型。
聚類
聚類是一種基於特徵、屬性、特徵等識別聚類的無監督模型。
機器學習算法
決策樹
決策樹使用二元方法根據每個階段的連續問題得出解決方案,這樣結果就是“是”或“否”等兩個可能的問題之一。 決策樹易於實現和解釋。
隨機森林或套袋
隨機森林是一種高級的決策樹算法。 它使用了大量的決策樹,使得結構像森林一樣密集而復雜。 它產生多種結果,從而導致更準確的結果和性能。
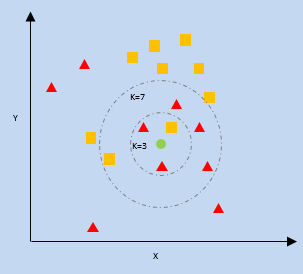
K-最近鄰(KNN)
kNN 利用繪圖上最近數據點相對於新數據點的接近度來預測它屬於哪個類別。新數據點被分配給具有更多鄰居數的類別。
k = 最近鄰居的數量
樸素貝葉斯
樸素貝葉斯在兩個支柱上工作,首先,數據點的每個特徵都是獨立的、彼此無關的,即唯一的,其次是基於條件或假設預測結果的貝葉斯定理。
貝葉斯定理:
P(X|Y) = {P(Y|X) * P(X)} / P(Y)
其中 P(X|Y) = 給定 Y 出現時 X 的條件概率
P(Y|X) = 給定 X 出現時 Y 的條件概率
P(X), P(Y) = X 和 Y 的概率
支持向量機
該算法嘗試根據可以是線或平面的邊界在空間中分離數據。 該邊界稱為“超平面”,由每個類的最近數據點定義,這些數據點又稱為“支持向量”。 兩邊支持向量之間的最大距離稱為邊距。
神經網絡
感知器
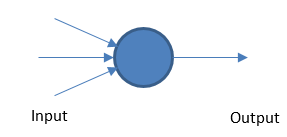
基本的神經網絡通過基於閾值的加權輸入和輸出來工作。
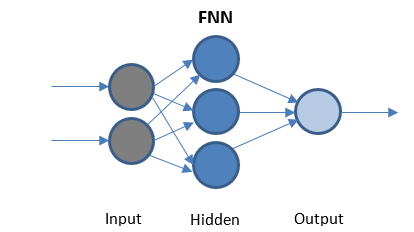
前饋神經網絡
FFN 是最簡單的網絡,僅在一個方向上傳輸數據。 可能有也可能沒有隱藏層。
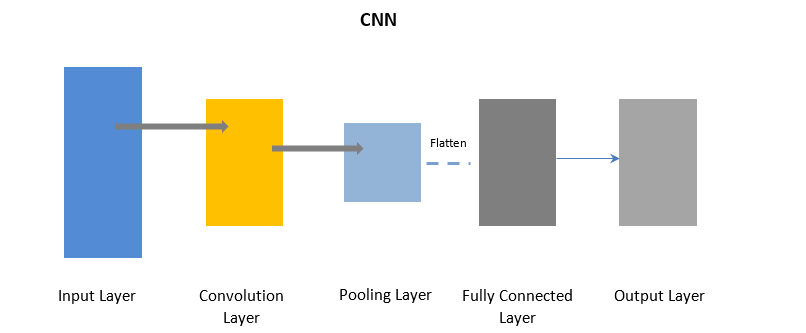
卷積神經網絡
CNN 使用卷積層批量處理輸入數據的某些部分,然後使用池化層完成輸出。
遞歸神經網絡
RNN 由 I/O 層之間的幾個循環層組成,可以存儲“歷史”數據。 數據流是雙向的,並被饋送到循環層以改進預測。
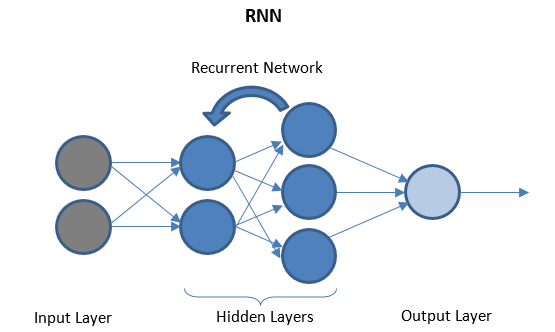
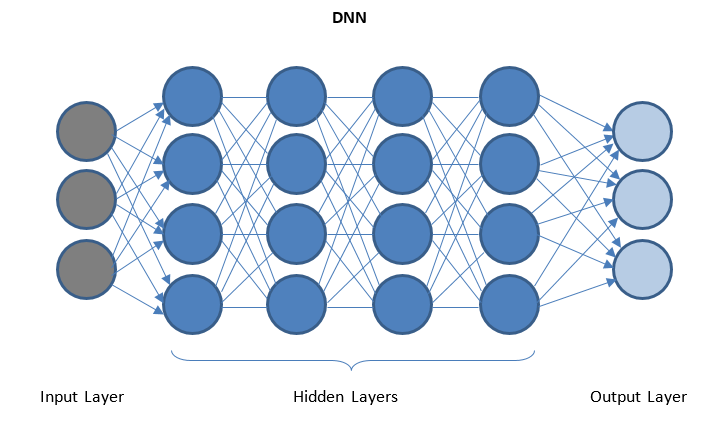
深度神經網絡和深度學習
DNN 是一個在 I/O 層之間具有多個隱藏層的網絡。 隱藏層在將數據發送到輸出層之前對數據進行連續轉換。
通過 DNN 促進“深度學習” ,由於具有多個隱藏層,因此可以處理大量複雜數據並實現高精度
獲得世界頂尖大學的數據科學認證。 學習行政 PG 課程、高級證書課程或碩士課程,以加快您的職業生涯。
結論
數據科學是一個廣闊的領域,它貫穿不同的流派,但對我們來說卻是一場革命和啟示。 數據科學正在蓬勃發展,並將改變我們系統在未來的工作方式和感覺。
如果您想了解數據科學,請查看 IIIT-B 和 upGrad 的數據科學 PG 文憑,該文憑專為在職專業人士而設,提供 10 多個案例研究和項目、實用的實踐研討會、與行業專家的指導、1-與行業導師面對面交流,400 多個小時的學習和頂級公司的工作協助。
哪種編程語言最適合數據科學,為什麼?
數據科學有幾十種編程語言,但大多數數據科學社區認為,如果你想在數據科學方面表現出色,那麼 Python 是正確的選擇。 以下是支持這一信念的一些原因:
1. Python 具有廣泛的模塊和庫,例如 TensorFlow 和 PyTorch,可以輕鬆處理數據科學概念。
2. 龐大的 Python 開發者社區不斷幫助新手進入數據科學之旅的下一階段。
3. 這種語言是迄今為止最方便、最容易編寫的語言之一,其語法簡潔,提高了可讀性。
使數據科學完整的概念是什麼?
數據科學是一個廣闊的領域,可以作為各種其他關鍵領域的保護傘。 以下是構成數據科學的最突出的概念:
統計數據
統計學是一個重要的概念,你必須精通才能在數據科學中取得進步。 它還有一些子主題:
1. 線性回歸
2.概率
3. 概率分佈
人工智能
為機器提供大腦並讓它們根據輸入做出自己的決定的科學被稱為人工智能。 反應性機器、有限記憶、心理理論和自我意識是人工智能的一些類型。
機器學習
機器學習是數據科學的另一個重要組成部分,它處理教學機器根據提供的數據預測未來結果。 機器學習具有三種突出的建模方法——聚類、回歸和分類。
描述機器學習的類型?
機器學習或簡單 ML 根據其工作方法分為三大類型。 這些類型如下:
1.監督學習
這是最原始的 ML 類型,其中輸入數據被標記。 該機器提供了一組較小的數據,可以讓機器深入了解問題並對其進行訓練。
2.無監督學習
這種類型的最大優點是這裡的數據沒有標記,人工幾乎可以忽略不計。 這為將更大的數據集引入模型打開了大門。
3.強化學習這是最先進的機器學習類型,它受到人類生活的啟發。 期望的輸出得到加強,而無用的輸出則被勸阻。