
機器學習中的數據預處理:7 個簡單的步驟
已發表: 2021-07-15機器學習中的數據預處理是有助於提高數據質量以促進從數據中提取有意義的見解的關鍵步驟。 機器學習中的數據預處理是指準備(清理和組織)原始數據以使其適合構建和訓練機器學習模型的技術。 簡而言之,機器學習中的數據預處理是一種數據挖掘技術,可將原始數據轉換為可理解和可讀的格式。
目錄
為什麼要在機器學習中進行數據預處理?
在創建機器學習模型時,數據預處理是標誌著該過程開始的第一步。 通常,現實世界的數據不完整、不一致、不准確(包含錯誤或異常值),並且通常缺乏特定的屬性值/趨勢。 這是數據預處理進入場景的地方——它有助於清理、格式化和組織原始數據,從而使其為機器學習模型做好準備。 讓我們探索機器學習中數據預處理的各個步驟。
加入來自世界頂級大學的在線人工智能課程——碩士、高級管理人員研究生課程和 ML 和 AI 高級證書課程,以加快您的職業生涯。
機器學習中數據預處理的步驟
機器學習中的數據預處理有七個重要步驟:
1.獲取數據集
獲取數據集是機器學習中數據預處理的第一步。 要構建和開發機器學習模型,您必須首先獲取相關數據集。 該數據集將由從多個不同來源收集的數據組成,然後以適當的格式組合形成數據集。 數據集格式因用例而異。 例如,商業數據集將與醫療數據集完全不同。 雖然業務數據集將包含相關的行業和業務數據,但醫療數據集將包含與醫療保健相關的數據。
有幾個在線資源可以下載數據集,例如https://www.kaggle.com/uciml/datasets和https://archive.ics.uci.edu/ml/index.php 。 您還可以通過不同的 Python API 收集數據來創建數據集。 數據集準備好後,您必須將其放入 CSV、HTML 或 XLSX 文件格式。

2. 導入所有關鍵庫
由於 Python 是世界各地數據科學家使用最廣泛且最喜歡的庫,因此我們將向您展示如何導入 Python 庫以在機器學習中進行數據預處理。 在此處閱讀有關用於數據科學的 Python 庫的更多信息。 預定義的 Python 庫可以執行特定的數據預處理作業。 導入所有關鍵庫是機器學習中數據預處理的第二步。 機器學習中用於數據預處理的三個核心 Python 庫是:
- NumPy – NumPy 是 Python 中科學計算的基礎包。 因此,它用於在代碼中插入任何類型的數學運算。 使用 NumPy,您還可以在代碼中添加大型多維數組和矩陣。
- Pandas ——Pandas 是一個優秀的開源 Python 庫,用於數據操作和分析。 它廣泛用於導入和管理數據集。 它包含用於 Python 的高性能、易於使用的數據結構和數據分析工具。
- Matplotlib – Matplotlib 是一個 Python 2D 繪圖庫,用於在 Python 中繪製任何類型的圖表。 它可以跨平台(IPython shell、Jupyter notebook、Web 應用程序服務器等)以多種硬拷貝格式和交互式環境提供出版質量的圖形。
閱讀:面向初學者的機器學習項目創意
3. 導入數據集
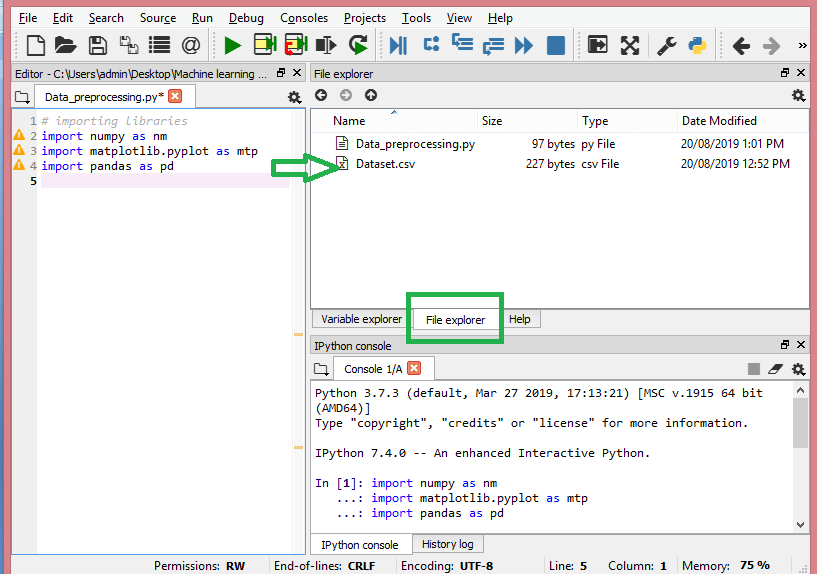
在此步驟中,您需要導入為手頭的 ML 項目收集的數據集。 導入數據集是機器學習中數據預處理的重要步驟之一。 但是,在導入 dataset/s 之前,您必須將當前目錄設置為工作目錄。 您可以通過三個簡單的步驟在 Spyder IDE 中設置工作目錄:
- 將 Python 文件保存在包含數據集的目錄中。
- 轉到 Spyder IDE 中的文件資源管理器選項並選擇所需的目錄。
- 現在,單擊 F5 按鈕或運行選項來執行文件。
資源
這就是工作目錄的外觀。
設置包含相關數據集的工作目錄後,您可以使用 Pandas 庫的“read_csv()”函數導入數據集。 此函數可以讀取 CSV 文件(本地或通過 URL)並對其執行各種操作。 read_csv() 寫為:
data_set= pd.read_csv('Dataset.csv')
在這行代碼中,“data_set”表示存儲數據集的變量的名稱。 該函數還包含數據集的名稱。 執行此代碼後,數據集將成功導入。
在數據集導入過程中,您必須做另一件重要的事情——提取因變量和自變量。 對於每個機器學習模型,有必要將數據集中的自變量(特徵矩陣)和因變量分開。
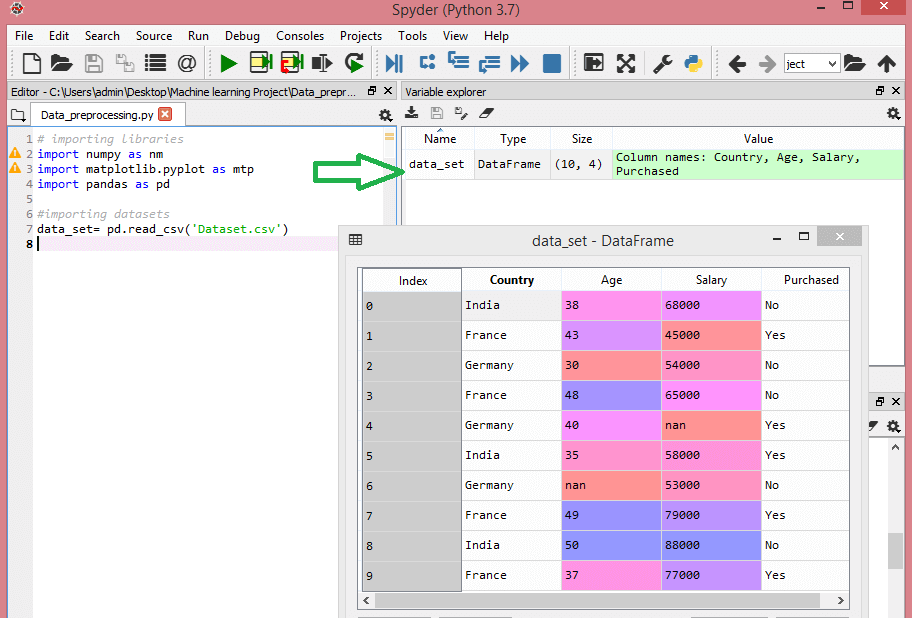
考慮這個數據集:
資源
該數據集包含三個自變量——國家、年齡和薪水,以及一個因變量——購買。
如何提取自變量?
要提取自變量,可以使用 Pandas 庫的“iloc[]”函數。 此函數可以從數據集中提取選定的行和列。
x= data_set.iloc[:,:-1].values
在上面的代碼行中,第一個冒號(:) 考慮所有行,第二個冒號(:) 考慮所有列。 該代碼包含“:-1”,因為您必須省略包含因變量的最後一列。 通過執行此代碼,您將獲得特徵矩陣,如下所示 -
[['印度'38.0 68000.0]
['法國' 43.0 45000.0]
['德國'30.0 54000.0]
['法國' 48.0 65000.0]
['德國' 40.0 nan]
['印度' 35.0 58000.0]
['德國'南 53000.0]
['法國' 49.0 79000.0]
['印度' 50.0 88000.0]
['法國' 37.0 77000.0]]
如何提取因變量?
您也可以使用“iloc[]”函數來提取因變量。 這是你寫它的方式:
y= data_set.iloc[:,3].values
這行代碼只考慮最後一列的所有行。 通過執行上述代碼,您將獲得因變量數組,如下所示 -
array(['No', 'Yes', 'No', 'No', 'Yes', 'Yes', 'No', 'Yes', 'No', 'Yes'],
數據類型=對象)
4. 識別和處理缺失值
在數據預處理中,識別和正確處理缺失值至關重要,如果不這樣做,您可能會從數據中得出不准確和錯誤的結論和推論。 不用說,這會妨礙您的 ML 項目。
基本上,有兩種方法可以處理丟失的數據:
- 刪除特定行- 在此方法中,您刪除具有空值的特定行,該行的特徵或特定列缺失超過 75% 的值。 但是,這種方法並不是 100% 有效的,建議您僅在數據集有足夠樣本的情況下使用它。 您必須確保在刪除數據後,不會再增加偏差。
- 計算平均值——此方法對於具有數字數據(如年齡、薪水、年份等)的特徵很有用。在這裡,您可以計算包含缺失值的特定特徵或列或行的平均值、中位數或眾數,並替換缺失值的結果。 這種方法可以為數據集增加方差,並且可以有效地否定任何數據丟失。 因此,與第一種方法(省略行/列)相比,它產生了更好的結果。 另一種近似方法是通過相鄰值的偏差。 但是,這對線性數據最有效。
閱讀:使用雲的機器學習應用程序的應用程序
5. 對分類數據進行編碼
分類數據是指在數據集中具有特定類別的信息。 在上面引用的數據集中,有兩個分類變量——國家和購買。
機器學習模型主要基於數學方程。 因此,您可以直觀地理解,將分類數據保留在方程式中會導致某些問題,因為您只需要方程式中的數字。
如何編碼國家變量?
從我們的數據集示例中可以看出,國家列會導致問題,因此您必須將其轉換為數值。 為此,您可以使用 sci-kit 學習庫中的 LabelEncoder() 類。 代碼如下——
#分類數據
#for 國家變量
從 sklearn.preprocessing 導入 LabelEncoder
label_encoder_x= 標籤編碼器()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
輸出將是 -
出[15]:
數組([[2, 38.0, 68000.0],
[0, 43.0, 45000.0],
[1, 30.0, 54000.0],
[0, 48.0, 65000.0],
[1, 40.0, 65222.22222222222],
[2, 35.0, 58000.0],
[1, 41.111111111111114, 53000.0],
[0, 49.0, 79000.0],
[2, 50.0, 88000.0],
[0, 37.0, 77000.0]], dtype=object)
在這裡我們可以看到 LabelEncoder 類已經成功地將變量編碼為數字。 但是,在上面顯示的輸出中,有一些國家變量被編碼為 0、1 和 2。 因此,ML 模型可能會假設三個變量之間存在某種相關性,從而產生錯誤的輸出。 為了消除這個問題,我們現在將使用虛擬編碼。
虛擬變量是那些取值 0 或 1 來表示不存在或存在可以改變結果的特定分類效應的變量。 在這種情況下,值 1 表示該變量存在於特定列中,而其他變量的值變為 0。在虛擬編碼中,列數等於類別數。
由於我們的數據集具有三個類別,因此它將生成具有值 0 和 1 的三列。對於虛擬編碼,我們將使用 scikit-learn 庫的 OneHotEncoder 類。 輸入代碼如下——
#for 國家變量
從 sklearn.preprocessing 導入 LabelEncoder,OneHotEncoder
label_encoder_x= 標籤編碼器()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
#虛擬變量的編碼
onehot_encoder= OneHotEncoder(categorical_features= [0])
x= onehot_encoder.fit_transform(x).toarray()
執行此代碼時,您將獲得以下輸出 -
數組([[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.80000000e+01,
6.80000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.30000000e+01,
4.50000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 3.00000000e+01,
5.40000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.80000000e+01,
6.50000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.00000000e+01,
6.52222222e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.50000000e+01,
5.80000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.11111111e+01,
5.30000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.90000000e+01,
7.90000000e+04],

[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 5.00000000e+01,
8.80000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 3.70000000e+01,
7.70000000e+04]])
在上面顯示的輸出中,所有變量都分為三列並編碼為值 0 和 1。
如何編碼購買的變量?
對於第二個分類變量,即購買的,可以使用 LableEncoder 類的“labelencoder”對象。 我們沒有使用 OneHotEncoder 類,因為購買的變量只有兩個類別是或否,這兩個類別都被編碼為 0 和 1。
此變量的輸入代碼將是 -
labelencoder_y= 標籤編碼器()
y= labelencoder_y.fit_transform(y)
輸出將是 -
出[17]:數組([0, 1, 0, 0, 1, 1, 0, 1, 0, 1])
6. 分割數據集
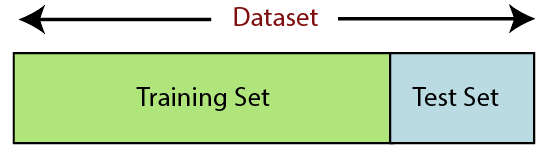
拆分數據集是機器學習中數據預處理的下一步。 機器學習模型的每個數據集都必須分成兩個獨立的集合——訓練集和測試集。
資源
訓練集表示用於訓練機器學習模型的數據集子集。 在這裡,您已經知道輸出。 另一方面,測試集是用於測試機器學習模型的數據集的子集。 ML 模型使用測試集來預測結果。
通常,數據集被分成 70:30 或 80:20 的比例。 這意味著您可以將 70% 或 80% 的數據用於訓練模型,而忽略其餘的 30% 或 20%。 拆分過程根據相關數據集的形狀和大小而有所不同。
要拆分數據集,您必須編寫以下代碼行 -
從 sklearn.model_selection 導入 train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
在這裡,第一行將數據集的數組拆分為隨機訓練和測試子集。 第二行代碼包括四個變量:
- x_train – 訓練數據的特徵
- x_test – 測試數據的特徵
- y_train – 訓練數據的因變量
- y_test – 測試數據的自變量
因此,train_test_split() 函數包括四個參數,其中前兩個用於數據數組。 test_size 函數指定測試集的大小。 test_size 可能是 .5、.3 或 .2——這指定了訓練集和測試集之間的劃分比率。 最後一個參數“random_state”為隨機生成器設置種子,以便輸出始終相同。
7. 特徵縮放
特徵縮放標誌著機器學習中數據預處理的結束。 它是一種在特定範圍內對數據集的自變量進行標準化的方法。 換句話說,特徵縮放限制了變量的範圍,以便您可以在共同的基礎上比較它們。
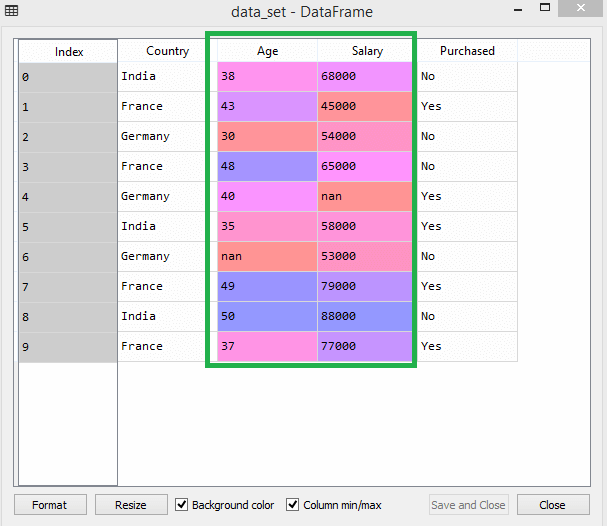
以這個數據集為例——
資源
在數據集中,您可以注意到年齡和薪水列的比例不同。 在這種情況下,如果您從年齡和薪水列中計算任意兩個值,薪水值將支配年齡值並提供不正確的結果。 因此,您必須通過執行機器學習的特徵縮放來消除此問題。
大多數 ML 模型基於歐幾里德距離,表示為:
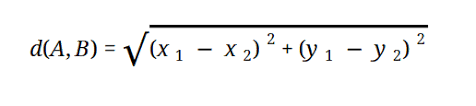
資源
您可以通過兩種方式在機器學習中執行特徵縮放:
標準化
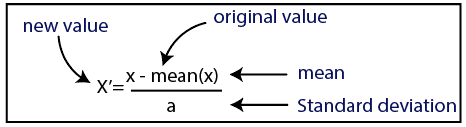
資源
正常化
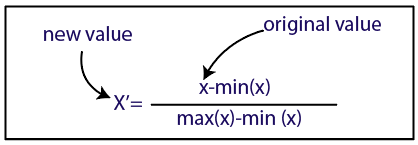
資源
對於我們的數據集,我們將使用標準化方法。 為此,我們將使用以下代碼行導入 sci-kit-learn 庫的 StandardScaler 類:
從 sklearn.preprocessing 導入 StandardScaler
下一步將是為自變量創建 StandardScaler 類的對象。 在此之後,您可以使用以下代碼擬合和轉換訓練數據集:
st_x=標準縮放器()
x_train=st_x.fit_transform(x_train)
對於測試數據集,你可以直接應用 transform() 函數(你不需要使用 fit_transform() 函數,因為它已經在訓練集中完成了)。 代碼如下——
x_test=st_x.transform(x_test)
測試數據集的輸出將顯示 x_train 和 x_test 的縮放值:
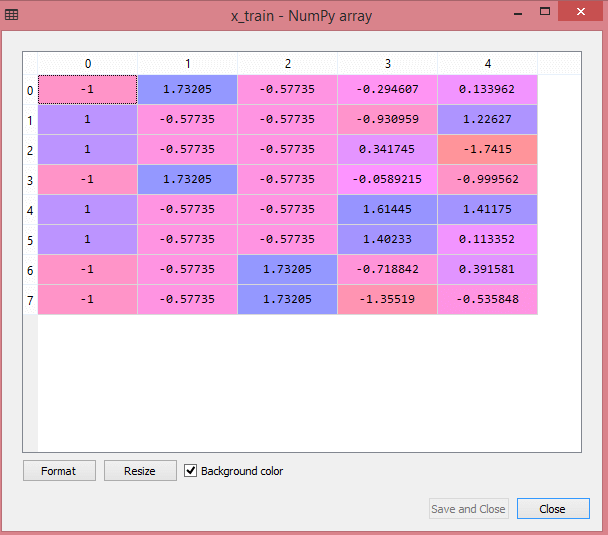
資源
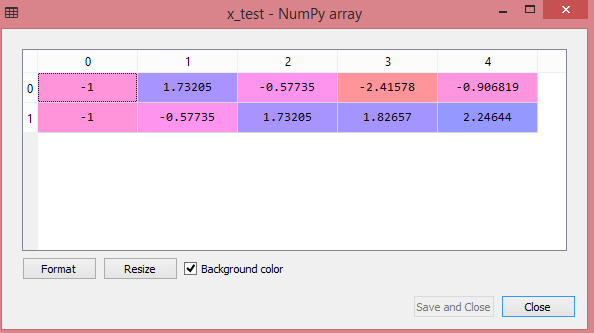
資源
輸出中的所有變量都在值 -1 和 1 之間縮放。
現在,結合我們迄今為止執行的所有步驟,您將獲得:
# 導入庫
將 numpy 導入為 nm
將 matplotlib.pyplot 導入為 mtp
將熊貓導入為 pd
#導入數據集
data_set= pd.read_csv('Dataset.csv')
#提取自變量
x= data_set.iloc[:, :-1].values
#提取因變量
y= data_set.iloc[:, 3].values
#處理缺失數據(用平均值替換缺失數據)
從 sklearn.preprocessing 導入 Imputer
imputer= Imputer(missing_values ='NaN', strategy='mean', axis = 0)
#將 imputer 對象擬合到自變量 x。
imputerimputer= imputer.fit(x[:, 1:3])
#用計算的平均值替換缺失數據
x[:, 1:3]= imputer.transform(x[:, 1:3])
#for 國家變量
從 sklearn.preprocessing 導入 LabelEncoder,OneHotEncoder
label_encoder_x= 標籤編碼器()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
#虛擬變量的編碼
onehot_encoder= OneHotEncoder(categorical_features= [0])
x= onehot_encoder.fit_transform(x).toarray()
#encoding 購買變量
labelencoder_y= 標籤編碼器()
y= labelencoder_y.fit_transform(y)
# 將數據集拆分為訓練集和測試集。
從 sklearn.model_selection 導入 train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
#數據集的特徵縮放
從 sklearn.preprocessing 導入 StandardScaler
st_x=標準縮放器()
x_train=st_x.fit_transform(x_train)
x_test=st_x.transform(x_test)
簡而言之,這就是機器學習中的數據處理!
您可以與upGrad一起查看IIT 德里的機器學習和人工智能執行 PG 計劃。 IIT德里是印度最負盛名的機構之一。 擁有超過 500 多名在主題方面最優秀的內部教職員工。
數據預處理的重要性是什麼?
由於錯誤、冗餘、缺失值和不一致都會危及數據集的完整性,因此您必須解決所有這些問題以獲得更準確的結果。 假設您使用有缺陷的數據集來訓練機器學習系統來處理客戶的購買。 系統很可能會產生偏差和偏差,從而導致糟糕的用戶體驗。 因此,在您將這些數據用於您的預期目的之前,它必須盡可能有條理且“乾淨”。 根據您要處理的困難類型,有多種選擇。
什麼是數據清洗?
您的數據集中幾乎肯定會有缺失和嘈雜的數據。 由於數據收集過程並不理想,您將獲得大量無用和缺失的信息。 數據清理是您應該採用的方式來處理這個問題。 這可以分為兩類。 第一個討論如何處理丟失的數據。 您可以選擇忽略數據集合的這一部分(稱為元組)中的缺失值。 第二種數據清洗方法是針對有噪聲的數據。 如果您希望整個過程順利運行,那麼擺脫系統無法讀取的無用數據至關重要。
數據轉換和縮減是什麼意思?
處理完問題後,數據預處理進入轉換階段。 您使用它將數據轉換為相關構象以進行分析。 規範化、屬性選擇、離散化和概念層次生成是可用於實現此目的的一些方法。 即使對於自動化方法,篩選大型數據集也可能需要很長時間。 這就是數據縮減階段如此重要的原因:它通過將數據集限制為最重要的信息來減少數據集的大小,提高存儲效率,同時降低使用它們的財務和時間費用。