
Python 中的數據框:Python 深入教程 2022
已發表: 2021-01-09如果您是使用 Python 編程語言工作的開發人員或編碼人員,那麼您必須熟悉目前最令人驚嘆的數據管理庫之一——Pandas,它是目前最頂級的 Python 庫之一。 多年來,Pandas 已成為使用 Python 進行數據分析和管理的標準工具。 閱讀其他重要的 Python 工具。
Pandas 無疑是用於數據科學的最通用的 Python 包,這是正確的。 它提供了強大、富有表現力和靈活的數據結構,便於數據操作和分析,Python 中的 Data Frames 就是這些結構之一。
這正是我們在這篇文章中討論的主題——我們將向您介紹 Pandas 的基本數據格式,即 Pandas Data Frame。
目錄
什麼是數據框?
根據Pandas 庫文檔,數據框是“帶有標記軸(行和列)的二維、大小可變、潛在異構的表格數據結構”。 簡而言之,數據框是一種數據結構,其中數據以表格方式排列,即按行和列排列。
一個數據框通常具有以下特徵:
- 它可能有多個行和列。
- 雖然每一行代表一個數據樣本,但每一列都包含一個描述樣本(行)的不同變量。
- 每列中的數據通常是相同類型的數據(例如,數字、字符串、日期等)。
- 與 excel 數據集不同,它避免了缺失值,因此行或列之間沒有間隙或空值。
在 Pandas 數據框中,您還可以為數據框指定索引和列名。 索引表示行中的差異,而列名顯示列中的差異。
如何在 Python 中創建數據框(使用 Pandas)
創建數據框是 Python 中數據處理的第一步。 您可以使用以下輸入創建 Pandas 數據框:
- 字典
- 列表
- 系列
- 麻木的“ndarray”
- 另一個數據框
- CS等外部文件
- 創建一個空數據框
創建一個基本的數據框,也就是一個空數據框是很容易的。 這是一個例子:
輸入 -

輸出 -

- 從列表創建數據框
您可以使用單個列表或多個列表創建數據框。
輸入 -

輸出 -

- 從“ndarrays”或列表的字典創建數據框
要從 ndarrays 的字典創建數據框,所有 ndarrays 必須具有相同的長度。 此外,如果它被索引,索引的長度應該等於數組的長度。 但是,如果它沒有被索引,默認情況下索引將是 range(n),其中 'n' 表示數組長度。
輸入 -

輸出 -

這裡的值 0,1,2,3 是使用函數 range(n) 分配給每一行的默認索引。
什麼是基本的數據框操作?
現在我們已經了解了在 Python 中創建數據框的三種方法,是時候了解數據框內的不同操作了。
- 從 Pandas 數據框中選擇索引或列
在開始添加、刪除和重命名 DataFrame 中的組件之前,了解如何選擇索引或列非常重要。 假設這是您的數據框:

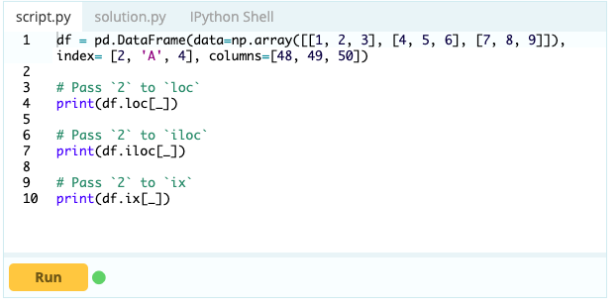
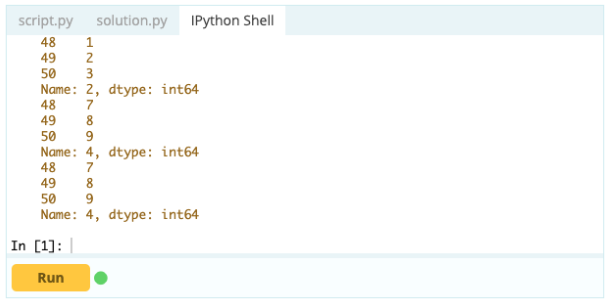
您想訪問“A”列中索引 0 下的值——該值為 1。訪問該值的方法有很多,但其中最重要的兩種是 .loc[] 和 .iloc[]。
輸入 -
輸出 -
因此,如您所見,您可以通過按標籤調用值或通過聲明它們在索引或列中的位置來訪問值。 雖然這是從數據框中選擇一個值,但如何從中選擇行和列?
這是如何:
輸入 -
輸出-
- 如何向 Pandas DataFrame 添加索引、行或列
一旦您學習瞭如何從數據框中訪問值和選擇列,您就可以學習在 Pandas 數據框中添加索引、行或列。
添加索引:
創建數據框時,您可以選擇將輸入添加到“索引”參數。 這確保您可以輕鬆訪問所需的索引。 如果不指定索引,默認情況下會添加一個從 0 開始並一直持續到 DataFrame 的最後一行的數值索引。 雖然,即使在默認情況下指定了索引後,您也可以通過調用 Data Frame 中的 set_index() 函數來使用列並將其轉換為索引。
添加一行:
您可以使用 append 函數將行添加到 DataFrame。

輸入 -

輸出 -

您還可以使用 .loc 在 DataFrame 中插入行,如下所示:
輸入 -
輸出 -
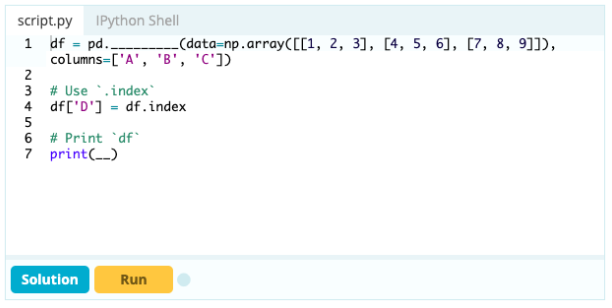
添加列
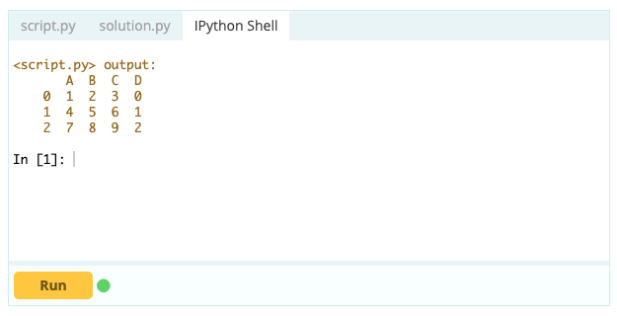
如果您想將索引作為數據框的一部分,您可以從數據框中獲取一列或引用尚未創建的列,並將其分配給 .index 屬性,如下所示:
輸入 -
輸出 -
要向數據框添加列,您還可以使用向數據框添加索引的相同方法,即可以使用 .loc[ ] 或 .iloc[ ] 函數。 例如:
輸入 -
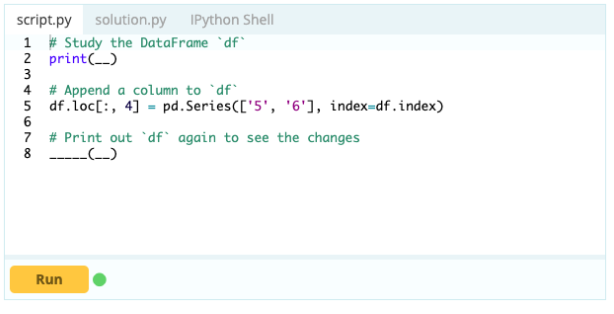
輸出
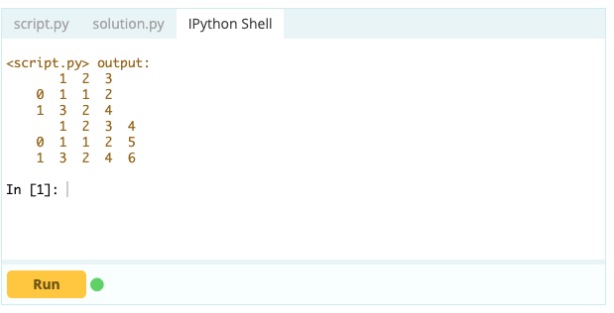
使用 .loc[ ],您可以將 Series 添加到現有 DataFrame。 由於 Series 對象與 Data Frame 的列非常相似,因此很容易將 Series 添加到現有 Data Frame 中。
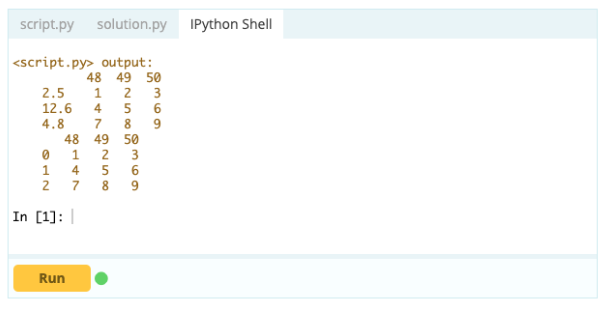
- 如何重置數據框的索引?
如果數據框的形狀不符合您的要求,您可以重置它的索引。 您可以使用 .reset_index() 函數來執行此操作。
輸入 -
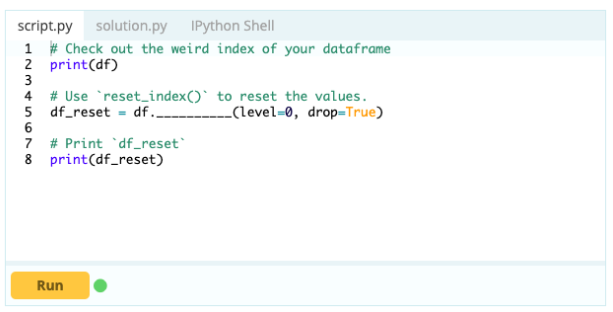
輸出 -
- 如何刪除 Pandas DataFrame 的索引、行或列
刪除索引
- 重置數據框的索引。
- 使用 del df.index.name 函數刪除索引名稱(如果有)。
- 刪除一個索引和一行。
- 通過重置索引刪除所有重複的索引值,刪除已添加到數據框中的索引列的重複項,並再次將新列(沒有重複索引)恢復為索引。
刪除列
要從數據框中刪除列,您可以使用 drop() 函數。
輸入 -
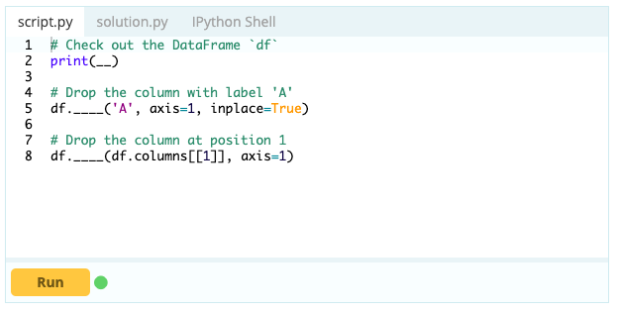
輸出 -
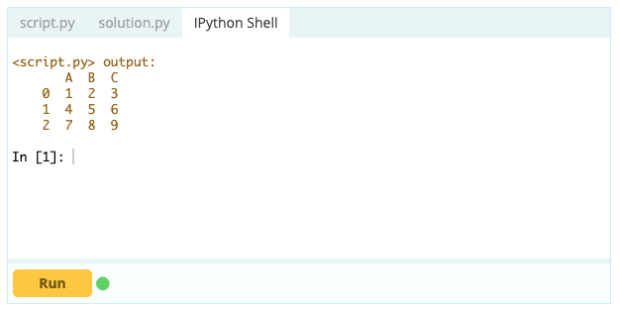
刪除一行
要從 DataFrame 中刪除一行,可以使用 drop() 函數,通過 index 屬性指定要從 DataFrame 中刪除的行的索引。
輸入 -
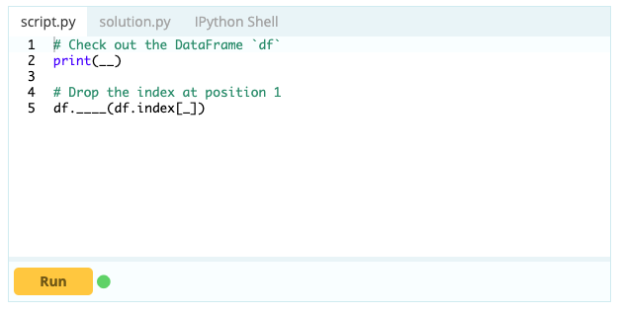
輸出 -
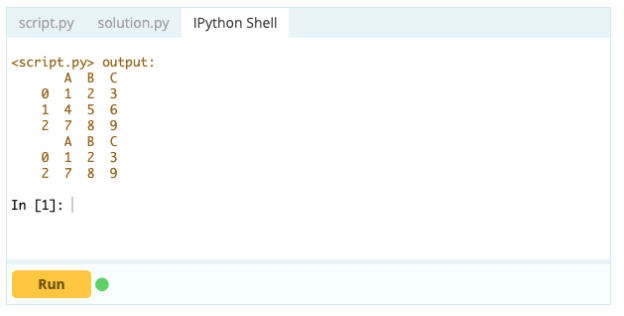
但是,要刪除重複行,您可以使用 df.drop_duplicates() 函數。
輸入 -
輸出 -
資料來源:教程點數據營
結論
因此,這裡有您使用 Pandas 在 Python 中使用 Data Frame 的基本教程。
如果您有興趣學習 Python、數據科學,請查看 IIIT-B 和 upGrad 的數據科學 PG 文憑,該文憑專為在職專業人士而設,提供 10 多個案例研究和項目、實用的實踐研討會、與行業專家的指導,與行業導師一對一,400 多個小時的學習和頂級公司的工作協助。
為什麼 Pandas 是在 Python 中創建數據幀的首選庫之一?
Pandas 庫被認為最適合創建數據框,因為它提供了各種功能,可以高效地創建數據框。 其中一些特性如下: Pandas 為我們提供了各種數據幀,這些數據幀不僅允許有效的數據表示,而且使我們能夠對其進行操作。 它提供有效的對齊和索引功能,提供標記和組織數據的智能方式。 Pandas 的一些特性使代碼更簡潔,增加了可讀性,從而提高了效率。 它還可以讀取多種文件格式。 JSON、CSV、HDF5 和 Excel 是 Pandas 支持的一些文件格式。 對於許多程序員來說,合併多個數據集是一個真正的挑戰。 Pandas 也克服了這一點,並且非常有效地合併了多個數據集。
補充 Pandas 庫的其他庫和工具是什麼?
Pandas 不僅可以作為創建數據框的中央庫,還可以與 Python 的其他庫和工具一起使用以提高效率。 Pandas 是基於 NumPy Python 包構建的,這表明大部分 Pandas 庫結構都是從 NumPy 包複製而來的。 Pandas 庫中數據的統計分析由 SciPy 操作,Matplotlib 上的繪圖函數和 Scikit-learn 中的機器學習算法。 Jupyter Notebook 是一個基於 Web 的交互式環境,可用作 IDE,並為 Pandas 提供良好的環境。
什麼是基本的數據幀操作?
在開始任何操作(如添加或刪除)之前選擇索引或列很重要。 一旦你學會瞭如何從數據框中訪問值和選擇列,你就可以學習在 Pandas 數據框中添加索引、行或列。 如果數據框中的索引不符合您的要求,您可以重置它。 要重置索引,您可以使用“reset_index()”函數。