
通過 PoP 向 WordPress 網站添加代碼拆分功能
已發表: 2022-03-10速度是當今任何網站的首要任務之一。 使網站加載速度更快的一種方法是代碼拆分:將應用程序拆分為可以按需加載的塊 - 僅加載所需的 JavaScript,而不加載其他任何內容。 基於 JavaScript 框架的網站可以通過流行的 JavaScript 捆綁器 Webpack 立即實現代碼拆分。 但是,對於 WordPress 網站來說,這並不容易。 首先,Webpack 並不是有意為與 WordPress 一起工作而構建的,因此設置它需要相當多的變通方法; 其次,似乎沒有任何工具可以為 WordPress 提供本地按需資產加載功能。
鑑於 WordPress 缺乏合適的解決方案,我決定為 PoP 實現我自己的代碼拆分版本,這是一個用於構建我創建的 WordPress 網站的開源框架。 安裝了 PoP 的 WordPress 網站將具有原生的代碼拆分功能,因此它不需要依賴 Webpack 或任何其他捆綁器。 在本文中,我將向您展示它是如何完成的,並解釋基於框架架構的各個方面做出的決策。 最後,我將分析使用和不使用代碼拆分的網站的性能,以及使用自定義實現相對於外部捆綁程序的優缺點。 我希望你喜歡這個旅程!
定義策略
代碼拆分大致可以分為以下兩個步驟:
- 計算每條路線必須加載哪些資產,
- 按需動態加載這些資產。
為了解決第一步,我們需要生成一個資產依賴圖,包括我們應用程序中的所有資產。 資產必須遞歸地添加到這個映射中——還必須添加依賴項的依賴項,直到不需要更多資產。 然後,我們可以通過遍歷資產依賴映射來計算特定路由所需的所有依賴關係,從路由的入口點(即開始執行的文件或代碼段)一直到最後一級。
為了解決第二步,我們可以在服務器端計算請求的 URL 需要哪些資產,然後在響應中發送所需資產的列表,應用程序需要加載它們,或者直接 HTTP/ 2 將資源與響應一起推送。
然而,這些解決方案並不是最優的。 在第一種情況下,應用程序必須在響應返回後請求所有資產,因此會有一系列額外的往返請求來獲取資產,並且在所有資產加載之前無法生成視圖,導致用戶必須等待(通過服務工作者預先緩存所有資產可以緩解此問題,因此減少了等待時間,但我們無法避免僅在響應返回後才解析資產)。 在第二種情況下,我們可能會重複推送相同的資產(除非我們添加一些額外的邏輯,例如通過 cookie 指示我們已經加載了哪些資源,但這確實增加了不希望的複雜性並阻止了響應被緩存),並且我們無法從 CDN 提供資產。
因此,我決定在客戶端處理這個邏輯。 客戶端上的應用程序可以使用每個路由需要哪些資產的列表,因此它已經知道請求的 URL 需要哪些資產。 這解決了上述問題:
- 資產可以立即加載,無需等待服務器響應。 (當我們將它與服務工作者結合起來時,我們可以非常確定,在響應返回時,所有資源都已被加載和解析,因此沒有額外的等待時間。)
- 應用程序知道哪些資產已經加載; 因此,它不會請求該路線所需的所有資產,而只會請求那些尚未加載的資產。
將此列表傳遞到前端的不利方面是它可能會變得很重,這取決於網站的大小(例如它提供了多少可用路由)。 我們需要找到一種在不增加應用程序感知加載時間的情況下加載它的方法。 稍後再談。
做出這些決定後,我們可以繼續設計,然後在應用程序中實現代碼拆分。 為了便於理解,該過程分為以下幾個步驟:
- 了解應用程序的架構,
- 映射資產依賴關係,
- 列出所有申請路線,
- 生成一個列表,定義每條路線需要哪些資產,
- 動態加載資產,
- 應用優化。
讓我們開始吧!
0. 了解應用程序的架構
我們需要映射所有資產的相互關係。 讓我們回顧一下 PoP 架構的特殊性,以便設計出最合適的解決方案來實現這一目標。
PoP 是圍繞 WordPress 的一層,使我們能夠將 WordPress 用作為應用程序提供動力的 CMS,同時提供自定義 JavaScript 框架來在客戶端呈現內容以構建動態網站。 它重新定義了網頁的構建組件:而 WordPress 目前基於生成 HTML 的分層模板的概念(例如single.php 、 home.php和archive.php ),而 PoP 基於“模塊、 ”,它們要么是原子功能,要么是其他模塊的組合。 構建 PoP 應用程序類似於玩樂高積木——將模塊堆疊在一起或相互包裝,最終創建一個更複雜的結構。 它也可以被認為是 Brad Frost 原子設計的實現,它看起來像這樣:
模塊可以分組為更高階的實體,即:blocks、blockGroups、pageSections 和 topLevels。 這些實體也是模塊,只是具有額外的屬性和職責,並且它們按照嚴格的自上而下的架構相互包含,其中每個模塊都可以查看和更改其所有內部模塊的屬性。 模塊之間的關係是這樣的:
- 1 個 topLevel 包含 N 個 pageSections,
- 1 pageSection 包含 N 個塊或塊組,
- 1個blockGroup包含N個blocks或blockGroups,
- 1塊包含N個模塊,
- 1 個模塊包含 N 個模塊,無窮無盡。
在 PoP 中執行 JavaScript 代碼
PoP 動態創建 HTML,從 pageSection 級別開始,遍歷所有模塊,通過模塊的預定義 Handlebars 模板渲染每個模塊,最後將模塊對應的新創建元素添加到 DOM 中。 完成此操作後,它會在它們上執行 JavaScript 函數,這些函數是逐個模塊預定義的。
PoP 與 JavaScript 框架(例如 React 和 AngularJS)的不同之處在於應用程序的流程並非源自客戶端,但它仍然在後端配置,在模塊的配置內部(編碼在 PHP 對像中)。 受 WordPress 動作掛鉤的影響,PoP 實現了發布-訂閱模式:
- 每個模塊都定義了必須在其對應的新創建的 DOM 元素上執行哪些 JavaScript 函數,而不必事先知道將執行此代碼的內容或代碼的來源。
- JavaScript 對象必須註冊它們實現的 JavaScript 函數。
- 最後,在運行時,PoP 計算哪些 JavaScript 對象必須執行哪些 JavaScript 函數,並適當地調用它們。
例如,通過其對應的 PHP 對象,日曆模塊指示它需要在其 DOM 元素上執行calendar函數,如下所示:
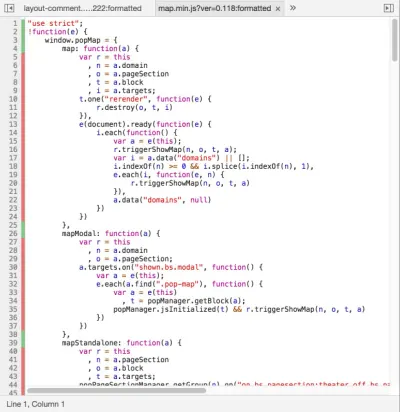
class CalendarModule { function get_jsmethods() { $methods = parent::get_jsmethods(); $this->add_jsmethod($methods, 'calendar'); return $methods; } ... } 然後,一個 JavaScript 對象(在本例中為popFullCalendar )宣布它已實現calendar功能。 這是通過調用popJSLibraryManager.register來完成的:
window.popFullCalendar = { calendar : function(elements) { ... } }; popJSLibraryManager.register(popFullCalendar, ['calendar', ...]); 最後, popJSLibraryManager對執行什麼代碼進行匹配。 它允許 JavaScript 對象註冊它們實現的功能,並提供一種方法來從所有訂閱的 JavaScript 對像中執行特定功能:
window.popJSLibraryManager = { libraries: [], methods: {}, register : function(library, methods) { this.libraries.push(library); for (var i = 0; i < methods.length; i++) { var method = methods[i]; this.methods[method] = this.methods[method] || []; this.methods[method].push(library); } }, execute : function(method, elements) { var libraries = this.methods[method] || []; for (var i = 0; i < libraries.length; i++) { var library = libraries[i]; library[method](elements); } } } 在將 ID 為calendar-293的新日曆元素添加到 DOM 後,PoP 將簡單地執行以下函數:
popJSLibraryManager.execute("calendar", document.getElementById("calendar-293"));入口點
對於 PoP,執行 JavaScript 代碼的入口點是 HTML 輸出末尾的這一行:
<script type="text/javascript">popManager.init();</script> popManager.init()首先初始化前端框架,然後執行所有渲染模塊定義的JavaScript函數,如上所述。 下面是這個函數的一個非常簡化的形式(原始代碼在 GitHub 上)。 通過調用popJSLibraryManager.execute('pageSectionInitialized', pageSection)和popJSLibraryManager.execute('documentInitialized') ,所有實現這些函數( pageSectionInitialized和documentInitialized )的 JavaScript 對像都將執行它們。
(function($){ window.popManager = { // The configuration for all the modules (including pageSections and blocks) in the application configuration : {...}, init : function() { var that = this; $.each(this.configuration, function(pageSectionId, configuration) { // Obtain the pageSection element in the DOM from the ID var pageSection = $('#'+pageSectionId); // Run all required JavaScript methods on it this.runJSMethods(pageSection, configuration); // Trigger an event marking the block as initialized popJSLibraryManager.execute('pageSectionInitialized', pageSection); }); // Trigger an event marking the document as initialized popJSLibraryManager.execute('documentInitialized'); }, ... }; })(jQuery); runJSMethods函數執行為每個模塊定義的 JavaScript 方法,從最頂層的模塊 pageSection 開始,然後是其所有內部塊及其內部模塊:
(function($){ window.popManager = { ... runJSMethods : function(pageSection, configuration) { // Initialize the heap with "modules", starting from the top one, and recursively iterate over its inner modules var heap = [pageSection.data('module')], i; while (heap.length > 0) { // Get the first element of the heap var module = heap.pop(); // The configuration for that module contains which JavaScript methods to execute, and which are the module's inner modules var moduleConfiguration = configuration[module]; // The list of all JavaScript functions that must be executed on the module's newly created DOM elements var jsMethods = moduleConfiguration['js-methods']; // Get all of the elements added to the DOM for that module, which have been stored in JavaScript object `popJSRuntimeManager` upon creation var elements = popJSRuntimeManager.getDOMElements(module); // Iterate through all of the JavaScript methods and execute them, passing the elements as argument for (i = 0; i < jsMethods.length; i++) { popJSLibraryManager.execute(jsMethods[i], elements); } // Finally, add the inner-modules to the heap heap = heap.concat(moduleConfiguration['inner-modules']); } }, }; })(jQuery);總之,PoP 中的 JavaScript 執行是松耦合的:我們沒有硬固定的依賴關係,而是通過任何 JavaScript 對像都可以訂閱的鉤子來執行 JavaScript 函數。
網頁和 API
PoP 網站是一個自用的 API。 在 PoP 中,網頁和 API 沒有區別:每個 URL 默認返回網頁,只需添加參數output=json ,它就會返回其 API(例如 getpop.org/en/ 是網頁,getpop.org/en/?output=json 是它的 API)。 該 API 用於在 PoP 中動態呈現內容; 因此,當單擊指向另一個頁面的鏈接時,會請求 API,因為屆時網站的框架將已加載(例如頂部和側面導航) - 然後 API 模式所需的資源集將是網頁中的一個子集。 在計算路由的依賴關係時,我們需要考慮到這一點:在首次加載網站時加載路由或通過單擊某個鏈接動態加載它會產生不同的所需資產集。
這些是 PoP 最重要的方面,將定義代碼拆分的設計和實現。 讓我們繼續下一步。
1. 映射資產依賴
我們可以為每個 JavaScript 文件添加一個配置文件,詳細說明它們的顯式依賴關係。 但是,這會重複代碼並且難以保持一致。 更簡潔的解決方案是將 JavaScript 文件作為唯一的真實來源,從其中提取代碼,然後分析此代碼以重新創建依賴關係。
為了能夠重新創建映射,我們在 JavaScript 源文件中尋找的元數據如下:
- 內部方法調用,例如
this.runJSMethods(...); - 外部方法調用,例如
popJSRuntimeManager.getDOMElements(...); - 所有出現的
popJSLibraryManager.execute(...),它在所有實現它的對像中執行 JavaScript 函數; - 所有出現的
popJSLibraryManager.register(...),以獲取哪些 JavaScript 對象實現了哪些 JavaScript 方法。
我們將使用 jParser 和 jTokenizer 在 PHP 中標記我們的 JavaScript 源文件並提取元數據,如下所示:
- 找到以下序列時會推斷出內部方法調用(例如
this.runJSMethods):標記this或that+.+ 其他一些標記,它是內部方法的名稱(runJSMethods)。 - 外部方法調用(例如
popJSRuntimeManager.getDOMElements)在找到以下序列時被推導出:包含在我們應用程序中所有 JavaScript 對象列表中的標記(我們將提前需要此列表;在這種情況下,它將包含對象popJSRuntimeManager) +.+ 其他一些標記,它是外部方法的名稱(getDOMElements)。 - 每當我們發現
popJSLibraryManager.execute("someFunctionName")我們推斷 Javascript 方法是someFunctionName。 - 每當我們找到
popJSLibraryManager.register(someJSObject, ["someFunctionName1", "someFunctionName2"])我們推導出 Javascript 對象someJSObject來實現方法someFunctionName1,someFunctionName2。
我已經實現了腳本,但不會在這裡描述它。 (它太長並沒有增加多少價值,但可以在 PoP 的存儲庫中找到)。 該腳本在請求網站開發服務器上的內部頁面時運行(我在之前關於服務工作者的文章中已經寫過該方法),它將生成映射文件並將其存儲在服務器上。 我準備了一個生成映射文件的示例。 它是一個簡單的 JSON 文件,包含以下屬性:
-
internalMethodCalls
對於每個 JavaScript 對象,列出它們之間內部函數的依賴關係。 -
externalMethodCalls
對於每個 JavaScript 對象,列出從內部函數到來自其他 JavaScript 對象的函數的依賴關係。 -
publicMethods
列出所有已註冊的方法,以及對於每個方法,哪些 JavaScript 對象實現了它。 -
methodExecutions
對於每個 JavaScript 對象和每個內部函數,列出通過popJSLibraryManager.execute('someMethodName')執行的所有方法。
請注意,結果還不是資產依賴映射,而是 JavaScript 對象依賴映射。 從這個映射中,我們可以確定,每當執行某個對象的函數時,還需要哪些其他對象。 我們仍然需要配置每個資產中包含哪些 JavaScript 對象,對於所有資產(在 jTokenizer 腳本中,JavaScript 對像是我們正在尋找的用於識別外部方法調用的標記,因此這些信息是腳本的輸入,可以'不能從源文件本身獲得)。 這是通過ResourceLoaderProcessor PHP 對象完成的,例如 resourceloader-processor.php。
最後,通過結合地圖和配置,我們將能夠計算應用程序中每條路線所需的所有資產。
2. 列出所有申請路線
我們需要識別應用程序中可用的所有路由。 對於 WordPress 網站,此列表將從每個模板層次結構的 URL 開始。 為 PoP 實現的那些是:
- 主頁:https://getpop.org/en/
- 作者:https://getpop.org/en/u/leo/
- 單:https://getpop.org/en/blog/new-feature-code-splitting/
- 標籤:https://getpop.org/en/tags/internet/
- 頁面:https://getpop.org/en/philosophy/
- 類別:https://getpop.org/en/blog/(類別實際上是作為一個頁面實現的,從URL路徑中刪除
category/) - 404:https://getpop.org/en/this-page-does-not-exist/
對於這些層次結構中的每一個,我們必須獲得產生獨特配置的所有路由(即,這將需要一組獨特的資產)。 在 PoP 的情況下,我們有以下內容:
- 主頁和404是唯一的。
- 任何標籤的標籤頁始終具有相同的配置。 因此,任何標籤的單個 URL 就足夠了。
- 單個帖子取決於帖子類型(如“事件”或“帖子”)和帖子的主要類別(如“博客”或“文章”)的組合。 然後,我們需要每個組合的 URL。
- 類別頁面的配置取決於類別。 因此,我們需要每個帖子類別的 URL。
- 作者頁面取決於作者的角色(“個人”、“組織”或“社區”)。 因此,我們需要三個作者的 URL,每個作者都具有這些角色之一。
- 每個頁面都可以有自己的配置(“登錄”、“聯繫我們”、“我們的使命”等)。 因此,必須將所有頁面 URL 添加到列表中。
正如我們所看到的,這個列表已經很長了。 此外,我們的應用程序可能會向 URL 添加參數來更改配置,可能還會更改所需的資產。 例如,PoP 提供添加以下 URL 參數:
- 選項卡(
?tab=…),顯示相關信息:https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors; - 格式(
?format=…),更改數據的顯示方式:https://getpop.org/en/blog/?format=list; - target (
?target=…),在不同的 pageSection 中打開頁面:https://getpop.org/en/add-post/?target=addons。
一些初始路由可以具有上述參數中的一個、兩個甚至三個,從而創建多種組合:
- 單個帖子:https://getpop.org/en/blog/new-feature-code-splitting/
- 單個帖子的作者:https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors
- 單個帖子的作者列表:https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors&format=list
- 單個帖子的作者作為模式窗口中的列表:https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors&format=list&target=modals
綜上所述,對於PoP來說,所有可能的路由都是以下幾項的組合:
- 所有初始模板層次結構路由;
- 層次結構將產生不同配置的所有不同值;
- 每個層次結構的所有可能選項卡(不同的層次結構可能具有不同的選項卡值:單個帖子可以具有選項卡“作者”和“響應”,而作者可以具有選項卡“帖子”和“關注者”);
- 每個選項卡的所有可能格式(不同的選項卡可能應用不同的格式:“作者”選項卡可能具有“地圖”格式,但“響應”選項卡可能沒有);
- 所有可能的目標,指示每個路線可能顯示的 pageSections(雖然可以在主要部分或浮動窗口中創建帖子,但可以將“與您的朋友分享”頁面設置為在模式窗口中打開)。
因此,對於稍微複雜的應用程序,無法手動生成包含所有路由的列表。 然後,我們必須創建一個腳本來從數據庫中提取這些信息,對其進行操作,最後以所需的格式輸出。 此腳本將獲取所有帖子類別,從中我們可以生成所有不同類別頁面 URL 的列表,然後,對於每個類別,查詢數據庫中相同的任何帖子,這將生成單個 URL在每個類別下發布,依此類推。 完整的腳本是可用的,從function get_resources()開始,它公開了要由每個層次結構案例實現的鉤子。
3. 生成定義每個路由所需資產的列表
到目前為止,我們已經有了資產依賴映射和應用程序中所有路由的列表。 現在是時候將這兩者結合起來,並生成一個列表,為每條路線指明需要哪些資產。
要創建此列表,我們應用以下過程:
- 生成一個列表,其中包含要為每個路由執行的所有 JavaScript 方法:
計算路由的模塊,然後獲取每個模塊的配置,然後從配置中提取模塊需要執行哪些JavaScript函數,並將它們加在一起。 - 接下來,遍歷每個 JavaScript 函數的資產依賴關係圖,收集其所有必需依賴項的列表,並將它們全部添加在一起。
- 最後,添加渲染該路由內的每個模塊所需的 Handlebars 模板。
另外,如前所述,每個 URL 都有網頁和 API 模式,所以我們需要將上面的過程運行兩次,每個模式一次(即在 URL 中添加一次參數output=json ,表示 API 模式的路由,並且一旦在網頁模式下保持 URL 不變)。 然後我們將生成兩個列表,它們將有不同的用途:
- 初始加載網站時將使用網頁模式列表,以便該路由的相應腳本包含在初始 HTML 響應中。 該列表將存儲在服務器上。
- 在網站上動態加載頁面時將使用 API 模式列表。 此列表將加載到客戶端上,以使應用程序能夠計算在單擊鏈接時按需加載哪些額外資產。
大部分邏輯已從function add_resources_from_settingsprocessors($fetching_json, ...)開始實現,(您可以在存儲庫中找到它)。 參數$fetching_json區分網頁 ( false ) 和 API ( true ) 模式。
網頁模式的腳本運行時,會輸出resourceloader-bundle-mapping.json,這是一個JSON對象,具有以下屬性:
-
bundle-ids
這是最多四個資源的集合(它們的名稱已針對生產環境進行了修改:eq=>handlebars、er=>handlebars-helpers等),分組在一個捆綁 ID 下。 -
bundlegroup-ids
這是bundle-ids的集合。 每個 bundleGroup 代表一組獨特的資源。 -
key-ids
這是路由(由它們的哈希表示,它標識使路由唯一的所有屬性的集合)與其對應的 bundleGroup 之間的映射。
可以看出,路由與其資源之間的映射不是直截了當的。 它不是將key-ids映射到資源列表,而是將它們映射到一個唯一的 bundleGroup,它本身就是一個bundles列表,並且只有每個 bundle 是一個resources列表(每個 bundle 最多四個元素)。 為什麼會這樣? 這有兩個目的:
- 它使我們能夠識別唯一 bundleGroup 下的所有資源。 因此,我們可以在 HTML 響應中包含一個唯一的 JavaScript 資產,而不是包含所有資源,它是相應的 bundleGroup 文件,它捆綁在所有相應的資源中。 這在為仍然不支持 HTTP/2 的設備提供服務時很有用,並且還會增加加載時間,因為 Gzip 壓縮單個捆綁文件比單獨壓縮其組成文件然後將它們加在一起更有效。 或者,我們也可以加載一系列包而不是唯一的bundleGroup,這是資源和bundleGroups之間的折衷(加載bundles比bundleGroups慢,因為Gzip'ing,但如果經常發生失效,它的性能會更高,所以我們將僅下載更新的捆綁包而不是整個捆綁包組)。 在 filegenerator-bundles.php 和 filegenerator-bundlegroups.php 中可以找到將所有資源捆綁到 bundles 和 bundleGroups 的腳本。
- 將資源集劃分為包允許我們識別常見模式(例如,識別在許多路由之間共享的四個資源的集合),從而允許不同的路由鏈接到同一個包。 結果,生成的列表將具有較小的大小。 這可能對駐留在服務器上的網頁列表沒有多大用處,但對於將在客戶端加載的 API 列表很有用,我們稍後會看到。
當 API 模式的腳本運行時,它將輸出 resources.js 文件,具有以下屬性:
-
bundles和bundle-groups的作用與網頁模式中所述的相同 keys的作用也與網頁模式的key-ids相同。 但是,它不是將哈希作為表示路由的鍵,而是將所有使路由唯一的屬性串聯起來——在我們的例子中,格式 (f)、製表符 (t) 和目標 (r)。-
sources是每個資源的源文件。 -
types是每個資源的 CSS 或 JavaScript(儘管為了簡單起見,我們沒有在本文中介紹 JavaScript 資源也可以將 CSS 資源設置為依賴項,並且模塊可以加載自己的 CSS 資源,實現漸進式 CSS 加載策略)。 -
resources捕獲必須為每個層次結構加載哪些 bundleGroup。 -
ordered-load-resources包含必須按順序加載的資源,以防止腳本在其依賴的腳本之前加載(默認情況下,它們是異步的)。
我們將在下一節探討如何使用這個文件。
4.動態加載資產
如前所述,API 列表將加載到客戶端,以便我們可以在用戶單擊鏈接後立即開始加載路由所需的資產。
加載映射腳本
生成的帶有應用程序中所有路由資源列表的 JavaScript 文件並不簡單——在這種情況下,它達到了 85 KB(它本身已經過優化,修改了資源名稱並生成了包以識別跨路由的常見模式) . 解析時間不應該是一個很大的瓶頸,因為解析 JSON 比解析 JavaScript 對於相同的數據要快 10 倍。 但是,大小是網絡傳輸的問題,因此我們必須以不影響應用程序感知加載時間或讓用戶等待的方式加載此腳本。

我實現的解決方案是使用服務工作者預緩存此文件,使用defer加載它,以便在執行關鍵 JavaScript 方法時不會阻塞主線程,然後在用戶單擊鏈接時顯示回退通知消息在腳本加載之前:“網站仍在加載中,請稍候點擊鏈接。” 這是通過添加一個固定的 div 來實現的,在加載腳本時,在所有內容的頂部放置一個loadingscreen類,然後在 div 內添加通知消息和一個notificationmsg類,以及這幾行 CSS:
.loadingscreen > .notificationmsg { display: none; } .loadingscreen:focus > .notificationmsg, .loadingscreen:active > .notificationmsg { display: block; }另一種解決方案是將這個文件分成幾個文件並根據需要逐步加載它們(我已經編寫了一個策略)。 此外,這個 85 KB 的文件包含應用程序中所有可能的路徑,包括諸如“作者的公告,以縮略圖形式顯示,顯示在模態窗口中”之類的路徑,如果有的話,可能會在藍月亮中訪問一次。 最常訪問的路由很少(主頁、單頁、作者、標籤和所有頁面,所有這些都沒有額外的屬性),這應該會產生一個小得多的文件,大約 30 KB。
從請求的 URL 獲取路由
我們必須能夠從請求的 URL 中識別路由。 例如:
-
https://getpop.org/en/u/leo/映射到路由“作者”, -
https://getpop.org/en/u/leo/?tab=followers映射到“作者的追隨者”路線, -
https://getpop.org/en/tags/internet/映射到路由“tag”, -
https://getpop.org/en/tags/映射到路由“page/tags/”, - 等等。
為此,我們需要評估 URL,並從中推斷出使路由唯一的元素:層次結構和所有屬性(格式、選項卡和目標)。 識別屬性沒有問題,因為它們是 URL 中的參數。 唯一的挑戰是通過將 URL 與多個模式匹配來從 URL 推斷層次結構(主頁、作者、單個、頁面或標籤)。 例如,
- 以
https://getpop.org/en/u/開頭的任何內容都是作者。 - 任何以
https://getpop.org/en/tags/開頭但不完全是標籤的東西都是標籤。 如果它恰好是https://getpop.org/en/tags/,那麼它就是一個頁面。 - 等等。
下面的函數從 resourceloader.js 的第 321 行開始實現,必須為所有這些層次結構的模式提供配置。 它首先檢查 URL 中是否沒有子路徑——在這種情況下,它是“home”。 然後,它會逐一檢查以匹配“作者”、“標籤”和“單個”的層次結構。 如果其中任何一個都不成功,那麼它是默認情況,即“page”:
window.popResourceLoader = { // The config will be populated externally, using a config.js file, generated by a script config : {}, getPath : function(url) { var parser = document.createElement('a'); parser.href = url; return parser.pathname; }, getHierarchy : function(url) { var path = this.getPath(url); if (!path) { return 'home'; } var config = this.config; if (path.startsWith(config.paths.author) && path != config.paths.author) { return 'author'; } if (path.startsWith(config.paths.tag) && path != config.paths.tag) { return 'tag'; } // We must also check that this path is, itself, not a potential page (https://getpop.org/en/posts/articles/ is "page", but https://getpop.org/en/posts/this-is-a-post/ is "single") if (config.paths.single.indexOf(path) === -1 && config.paths.single.some(function(single_path) { return path.startsWith(single_path) && path != single_path;})) { return 'single'; } return 'page'; }, ... };因為所有需要的數據都已經在數據庫中(所有類別、所有頁面 slug 等),我們將執行一個腳本來在開發或登台環境中自動創建此配置文件。 The implemented script is resourceloader-config.php, which produces config.js with the URL patterns for the hierarchies “author”, “tag” and “single”, under the key “paths”:
popResourceLoader.config = { "paths": { "author": "u/", "tag": "tags/", "single": ["posts/articles/", "posts/announcements/", ...] }, ... };Loading Resources for the Route
Once we have identified the route, we can obtain the required assets from the generated JavaScript file under the key “resources”, which looks like this:
config.resources = { "home": { "1": [1, 110, ...], "2": [2, 111, ...], ... }, "author": { "7": [6, 114, ...], "8": [7, 114, ...], ... }, "tag": { "119": [66, 127, ...], "120": [66, 127, ...], ... }, "single": { "posts/": { "7": [190, 142, ...], "3": [190, 142, ...], ... }, "events/": { "7": [213, 389, ...], "3": [213, 389, ...], ... }, ... }, "page": { "log-in/": { "3": [233, 115, ...] }, "log-out/": { "3": [234, 115, ...] }, "add-post/": { "3": [239, 398, ...] }, "posts/": { "120": [268, 127, ...], "122": [268, 127, ...], ... }, ... } };At the first level, we have the hierarchy (home, author, tag, single or page). Hierarchies are divided into two groups: those that have only one set of resources (home, author and tag), and those that have a specific subpath (page permalink for the pages, custom post type or category for the single). Finally, at the last level, for each key ID (which represents a unique combination of the possible values of “format”, “tab” and “target”, stored under “keys”), we have an array of two elements: [JS bundleGroup ID, CSS bundleGroup ID], plus additional bundleGroup IDs if executing progressive booting (JS bundleGroups to be loaded as "async" or "defer" are bundled separately; this will be explained in the optimizations section below).
Please note: For the single hierarchy, we have different configurations depending on the custom post type. This can be reflected in the subpath indicated above (for example, events and posts ) because this information is in the URL (for example, https://getpop.org/en/posts/the-winners-of-climate-change-techno-fixes/ and https://getpop.org/en/events/debate-post-fork/ ), so that, when clicking on a link, we will know the corresponding post type and can thus infer the corresponding route. However, this is not the case with the author hierarchy. As indicated earlier, an author may have three different configurations, depending on the user role ( individual , organization or community ); however, in this file, we've defined only one configuration for the author hierarchy, not three. That is because we are not able to tell from the URL what is the role of the author: user leo (under https://getpop.org/en/u/leo/ ) is an individual, whereas user pop (under https://getpop.org/en/u/pop/ ) is a community; however, their URLs have the same pattern. If we could instead have the URLs https://getpop.org/en/u/individuals/leo/ and https://getpop.org/en/u/communities/pop/ , then we could add a configuration for each user role. However, I've found no way to achieve this in WordPress. As a consequence, only for the API mode, we must merge the three routes (individuals, organizations and communities) into one, which will have all of the resources for the three cases; and clicking on the link for user leo will also load the resources for organizations and communities, even if we don't need them.
Finally, when a URL is requested, we obtain its route, from which we obtain the bundleGroup IDs (for both JavaScript and CSS assets). From each bundleGroup, we find the corresponding bundles under bundlegroups . Then, for each bundle, we obtain all resources under the key bundles . Finally, we identify which assets have not yet been loaded, and we load them by getting their source, which is stored under the key sources . The whole logic is coded starting from line 472 in resourceloader.js.
And with that, we have implemented code-splitting for our application! From now on, we can get better loading times by applying optimizations. Let's tackle that next.
5. Applying Optimizations
The objective is to load as little code as possible, as delayed as possible, and to cache as much of it as possible. Let's explore how to do this.
Splitting Up the Code Into Smaller Units
A single JavaScript asset may implement several functions (by calling popJSLibraryManager.register ), yet maybe only one of those functions is actually needed by the route. Thus, it makes sense to split up the asset into several subassets, implementing a single function on each of them, and extracting all common code from all of the functions into yet another asset, depended upon by all of them.
For instance, in the past, there was a unique file, waypoints.js , that implemented the functions waypointsFetchMore , waypointsTheater and a few more. However, in most cases, only the function waypointsFetchMore was needed, so I was loading the code for the function waypointsTheater unnecessarily. Then, I split up waypoints.js into the following assets:
- waypoints.js, with all common code and implementing no public functions;
- waypoints-fetchmore.js, which implements just the public function
waypointsFetchMore; - waypoints-theater.js, which implements just the public function
waypointsTheater.
Evaluating how to split the files is a manual job. Luckily, there is a tool that greatly eases the task: Chrome Developer Tools' “Coverage” tab, which displays in red those portions of JavaScript code that have not been invoked:
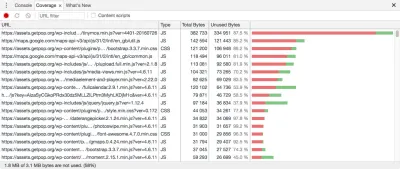
By using this tool, we can better understand how to split our JavaScript files into more granular units, thus reducing the amount of unneeded code that is loaded.
Integration With Service Workers
By precaching all of the resources using service workers, we can be pretty sure that, by the time the response is back from the server, all of the required assets will have been loaded and parsed. I wrote an article on Smashing Magazine on how to accomplish this.
Progressive Booting
PoP's architecture plays very nice with the concept of loading assets in different stages. When defining the JavaScript methods to execute on each module (by doing $this->add_jsmethod($methods, 'calendar') ), these can be set as either critical or non-critical . By default, all methods are set as non-critical, and critical methods must be explicitly defined by the developer, by adding an extra parameter: $this->add_jsmethod($methods, 'calendar', 'critical') . Then, we will be able to load scripts immediately for critical functions, and wait until the page is loaded to load non-critical functions, the JavaScript files of which are loaded using defer .
(function($){ window.popManager = { init : function() { var that = this; $.each(this.configuration, function(pageSectionId, configuration) { ... this.runJSMethods(pageSection, configuration, 'critical'); ... }); window.addEventListener('load', function() { $.each(this.configuration, function(pageSectionId, configuration) { ... this.runJSMethods(pageSection, configuration, 'non-critical'); ... }); }); ... }, ... }; })(jQuery);The gains from progressive booting are major: The JavaScript engine needs not spend time parsing non-critical JavaScript initially, when a quick response to the user is most important, and overall reduces the time to interactive.
Testing And Analizying Performance Gains
We can use https://getpop.org/en/, a PoP website, for testing purposes. When loading the home page, opening Chrome Developer Tools' “Elements” tab and searching for “defer”, it shows 4 occurrences. Thanks to progressive booting, that is 4 bundleGroup JavaScript files containing the contents of 57 Javascript files with non-critical methods that could wait until the website finished loading to be loaded:
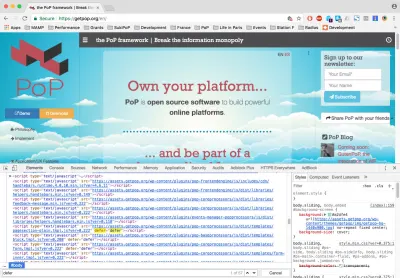
If we now switch to the “Network” tab and click on a link, we can see which assets get loaded. For instance, click on the link “Application/UX Features” on the left side. Filtering by JavaScript, we see it loaded 38 files, including JavaScript libraries and Handlebars templates. Filtering by CSS, we see it loaded 9 files. These 47 files have all been loaded on demand:
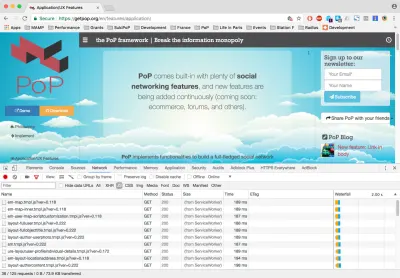
Let's check whether the loading time got boosted. We can use WebPagetest to measure the application with and without code-splitting, and calculate the difference.
- Without code-splitting: testing URL, WebPagetest results

- With code-splitting, loading resources: testing URL, WebPagetest Results

- With code-splitting, loading a bundleGroup: testing URL, WebPagetest Results

We can see that when loading the app bundle with all resources or when doing code-splitting and loading resources, there is not so much gain. However, when doing code-splitting and loading a bundleGroup, the gains are significant: 1.7 seconds in loading time, 500 milliseconds to the first meaningful paint, and 1 second to interactive.
Conclusion: Is It Worth It?
You might be thinking, Is it worth it all this trouble? Let's analyze the advantages and disadvantages of implementing our own code-splitting features.
缺點
- 我們必須維護它。
如果我們只使用 Webpack,我們可以依靠它的社區來使軟件保持最新,並可以從它的插件生態系統中受益。 - 腳本需要時間來運行。
PoP 網站 Agenda Urbana 擁有 304 條不同的路線,從中產生 422 套獨特的資源。 對於這個網站,使用 2012 年的 MacBook Pro 運行生成資產依賴關係圖的腳本大約需要 8 分鐘,運行生成包含所有資源的列表並創建 bundle 和 bundleGroup 文件的腳本需要 15 分鐘. 去喝杯咖啡的時間已經綽綽有餘了! - 它需要一個暫存環境。
如果我們需要等待大約 25 分鐘來運行腳本,那麼我們就無法在生產環境中運行它。 我們需要一個與生產系統配置完全相同的暫存環境。 - 額外的代碼被添加到網站,只是為了管理。
85 KB 的代碼本身沒有功能,只是用來管理其他代碼的代碼。 - 增加了複雜性。
如果我們想將資產分成更小的單位,這在任何情況下都是不可避免的。 Webpack 還會增加應用程序的複雜性。
優點
- 它適用於 WordPress。
Webpack 不適用於開箱即用的 WordPress,要使其正常工作需要相當多的解決方法。 這個解決方案確實適用於 WordPress(只要安裝了 PoP)。 - 它具有可擴展性和可擴展性。
應用程序的大小和復雜性可以無限增長,因為 JavaScript 文件是按需加載的。 - 它支持古騰堡(又名明天的 WordPress)。
因為它允許我們按需加載 JavaScript 框架,所以它將支持 Gutenberg 的塊(稱為 Gutenblocks),這些塊預計將在開發人員選擇的框架中編碼,同一應用程序需要不同框架的潛在結果。 - 這很方便。
構建工具負責生成配置文件。 除了等待,我們不需要額外的努力。 - 它使優化變得容易。
目前,如果一個 WordPress 插件想要選擇性地加載 JavaScript 資源,它會使用大量的條件來檢查頁面 ID 是否正確。 有了這個工具,就沒有必要了; 這個過程是自動的。 - 應用程序將更快地加載。
這就是我們編寫這個工具的全部原因。 - 它需要一個暫存環境。
一個積極的副作用是增加了可靠性:我們不會在生產環境中運行腳本,所以我們不會在那裡破壞任何東西; 部署過程不會因意外行為而失敗; 並且開發人員將被迫使用與生產中相同的配置來測試應用程序。 - 它是根據我們的應用程序定制的。
沒有開銷或解決方法。 根據我們正在使用的架構,我們得到的正是我們所需要的。
總之:是的,這是值得的,因為現在我們能夠在我們的 WordPress 網站上按需應用加載資產並使其加載速度更快。
更多資源
- Webpack,包括“代碼拆分”指南
- “更好的 Webpack 構建”(視頻),K. Adam White
Webpack 與 WordPress 的集成 - “古騰堡和明天的 WordPress,” WP Tavern 的 Morten Rand-Hendriksen
- “WordPress 探索了一種與 JavaScript 框架無關的方法來構建 Gutenberg 塊,” WP Tavern 的 Sarah Gooding