
在代理商處選擇新的無服務器數據庫技術(案例研究)
已發表: 2022-03-10本文得到了 Fauna 親愛的朋友的大力支持,他們使每個軟件開發團隊都可以高效、可擴展且安全地處理運營數據。 謝謝!

對於擔任領導職務的技術人員來說,採用新技術是最艱難的決定之一。 無論您是為其他組織還是在您自己的組織內構建軟件,這通常是一個巨大且令人不安的風險領域。
在過去的 12 年裡,作為一名軟件工程師,我發現自己不得不以越來越高的頻率評估一項新技術。 這可能是下一個前端框架、一種新語言,甚至是像無服務器這樣的全新架構。
實驗階段通常是有趣和令人興奮的。 這是軟件工程師最在家的地方,在探索新概念的同時,擁抱“啊哈”時刻的新奇和興奮。 作為工程師,我們喜歡思考和修補,但有了足夠的經驗,每個工程師都知道,即使是最令人難以置信的技術也有其缺陷。 你只是還沒有找到它們。
現在,作為創意機構的聯合創始人,我和我的團隊經常處於使用新技術的獨特位置。 我們看到許多新建項目,這成為引入新事物的絕佳機會。 這些項目還與較大的組織存在一定程度的技術隔離,並且通常較少受到先前決策的負擔。
話雖如此,一位優秀的機構負責人受託照顧別人的大創意並將其傳遞給全世界。 我們必須比我們自己的項目更加小心地對待它。 每當我即將對一項新技術做出最後決定時,我經常會思考聯合創始人 Stack Overflow Joel Spolski 的這條智慧:
“在你真正知道它足夠好或意識到無論你怎麼努力你都不能......之前,你必須用一兩年的時間流汗和流血
這就是恐懼,這是任何技術主管都不想置身其中的地方。為現實世界的項目選擇新技術已經夠難了,但作為代理機構,你必須與其他人的項目、某人的項目一起做出這些決定別人的夢想,別人的錢。 在代理機構,您最不想要的就是在項目的最後期限附近找到其中一個瑕疵。 緊迫的時間表和預算使得在超過某個閾值後幾乎不可能逆轉,因此發現一項技術不能做一些關鍵的事情或在項目中太晚不可靠可能是災難性的。
在我作為軟件工程師的整個職業生涯中,我曾在 SaaS 公司和創意機構工作過。 在為項目採用新技術時,這兩種環境具有非常不同的標準。 標準有重疊,但總的來說,機構環境必須在嚴格的預算和嚴格的時間限制下工作。 雖然我們希望我們構建的產品隨著時間的推移而老化,但通常更難以對不太成熟的產品進行投資或採用具有更陡峭的學習曲線和粗糙邊緣的技術。
話雖如此,機構也有一些單一組織可能沒有的獨特限制。 我們必須偏向於效率和穩定性。 計費時間通常是項目完成後的最終計量單位。 我曾在 SaaS 公司工作過,在這些公司中花一兩天時間進行設置或構建管道沒什麼大不了的。
在代理機構,這種類型的時間成本會給關係帶來壓力,因為財務團隊看到利潤率正在縮小,幾乎沒有可見的結果。 我們還必須考慮項目的長期維護,反之,如果項目需要交還給客戶會發生什麼。 因此,我們必須偏向於我們選擇的技術的效率、學習曲線和穩定性。
在評估一項新技術時,我會關註三個總體領域:
- 技術
- 開發者體驗
- 這生意
在我開始真正深入研究代碼和進行實驗之前,這些領域中的每一個都有我喜歡滿足的一組標準。 在本文中,我們將看看這些標準,並使用為項目考慮新數據庫的示例,並在每個鏡頭下從高層次上對其進行審查。 做出這樣一個切實的決定將有助於展示我們如何在現實世界中應用這個框架。
技術
在評估一項新技術時,首先要看的是該解決方案是否可以解決它聲稱要解決的問題。 在深入研究一項技術如何幫助我們的流程和業務運營之前,首先確定它是否滿足我們的功能需求很重要。 這也是我想看看我們正在使用哪些現有解決方案以及這個新解決方案如何與它們相抗衡的地方。
我會問自己這樣的問題:
- 它至少能解決我現有解決方案的問題嗎?
- 這個解決方案在哪些方面更好?
- 在哪些方面更糟?
- 對於更糟糕的領域,如何克服這些缺點?
- 它會取代多種工具嗎?
- 技術有多穩定?
我們的為什麼?
在這一點上,我還想回顧一下我們為什麼要尋求另一種解決方案。 一個簡單的答案是我們遇到了現有解決方案無法解決的問題。 然而,這種情況通常很少發生。 多年來,我們利用我們今天擁有的所有技術解決了許多軟件問題。 通常發生的情況是,我們轉向一項新技術,使我們目前正在做的事情變得更容易、更穩定、更快或更便宜。
讓我們以 React 為例。 當 jQuery 或 Vanilla JavaScript 做這項工作時,為什麼我們決定採用 React? 在這種情況下,使用該框架強調了這是處理有狀態前端的更好方法。 通過使用數據結構而不是直接的 DOM 操作,我們可以更快地構建過濾和排序功能。 這節省了時間並提高了我們解決方案的穩定性。
Typescript是我們決定採用它的另一個例子,因為我們發現代碼的穩定性和可維護性有所提高。 在採用新技術時,我們通常不會尋求解決一個明確的問題,而只是希望保持最新狀態,然後發現比我們目前使用的更有效和更穩定的解決方案。
對於數據庫,我們特別考慮遷移到無服務器選項。 我們在無服務器應用程序和部署方面取得了很多成功,減少了我們作為一個組織的開銷。 我們認為缺乏這一點的一個領域是我們的數據層。 我們看到像 Amazon Aurora、Fauna、Cosmos 和 Firebase 這樣的服務正在將無服務器原則應用於數據庫,並想看看是否是時候自己邁出這一步了。 在這種情況下,我們希望降低運營開銷並提高開發速度和效率。
在您開始涉足新產品之前,了解您的原因很重要。 這可能是因為您正在解決一個新問題,但更多時候您希望提高自己解決已經解決的問題的能力。 在這種情況下,您需要盤點您去過的地方,以確定哪些內容可以為您的工作流程提供有意義的改進。 基於我們查看無服務器數據庫的示例,我們需要看看我們目前如何解決問題以及這些解決方案的不足之處。
我們去過的地方……
作為代理商,我們之前使用過的數據庫範圍很廣,包括但不限於 MySQL、PostgreSQL、MongoDB、DynamoDB、BigQuery 和 Firebase Cloud Storage。 不過,我們的絕大多數工作都圍繞三個核心數據庫:PostgreSQL、MongoDB 和 Firebase 實時數據庫。 事實上,它們中的每一個都具有半無服務器產品,但新產品的一些關鍵特性讓我們重新評估了之前的假設。 讓我們先來看看我們在這些方面的歷史經驗,以及為什麼我們首先要考慮替代方案。
我們通常為大型、長期項目選擇PostgreSQL ,因為這是幾乎所有事物都經過實戰考驗的黃金標準。 它支持經典事務、規範化數據,並且符合 ACID。 幾乎每種語言都有大量可用的工具和 ORM,它甚至可以用作具有 JSON 列支持的臨時 NoSQL 數據庫。 它與許多現有的框架、庫和編程語言很好地集成,使其成為真正的隨處可用的主力。 它也是開源的,因此不會讓我們鎖定任何一個供應商。 正如他們所說,沒有人會因為選擇 Postgres 而被解僱。
話雖如此,我們逐漸發現自己使用 PostgreSQL 的次數越來越少,因為我們變得更像是一個面向節點的商店。 我們發現 Node 的 ORM 乏善可陳,需要更多的自定義查詢(儘管現在這已變得不那麼成問題了),而在 JavaScript 或 TypeScript 運行時工作時,NoSQL 感覺更自然。 話雖如此,我們經常有一些項目可以通過電子商務工作流等經典關係模型快速完成。 然而,處理數據庫的本地設置、統一跨團隊的測試流程以及處理本地遷移是我們不喜歡的事情,並且很高興隨著 NoSQL、基於雲的數據庫變得越來越流行而放棄這些事情。
隨著我們採用 Node.js 作為首選後端, MongoDB越來越成為我們的首選數據庫。 使用 MongoDB Atlas 可以輕鬆快速地開發和測試我們團隊可以使用的數據庫。 有一段時間,MongoDB 不符合 ACID,不支持事務,並且不鼓勵太多類似內部連接的操作,因此對於電子商務應用程序,我們仍然最常使用 Postgres。 話雖如此,有大量的庫與之配套,Mongo 的查詢語言和一流的 JSON 支持為我們提供了關係數據庫所沒有的速度和效率。 MongoDB 最近增加了對 ACID 事務的支持,但長期以來,這是我們選擇 Postgres 的主要原因。
MongoDB 還向我們介紹了新的靈活性水平。 在代理項目的中間,需求必然會發生變化。 無論您多麼努力地防禦它,總會有最後一刻的數據要求。 一般來說,對於 NoSQL 數據庫,數據結構的靈活性使這些類型的更改不那麼苛刻。 我們最終沒有得到一個裝滿遷移文件的文件夾來管理添加和刪除以及在項目出現之前再次添加的列。
作為一項服務,Mongo Atlas 也非常接近我們在數據庫雲服務中所期望的。 我喜歡將 Atlas 視為一種半無服務器產品,因為您在管理它時仍有一些運營開銷。 您必須預先配置一定大小的數據庫並選擇一定數量的內存。 這些東西不會自動為您擴展,因此您需要監控它何時需要提供更多空間或內存。 在真正的無服務器數據庫中,這一切都將自動和按需發生。
我們還在幾個項目中使用了 Firebase 實時數據庫。 這確實是一種無服務器產品,其中數據庫可按需擴展和縮減,並且採用按需付費定價,這對於預先不知道規模且預算有限的應用程序是有意義的。 我們使用它而不是 MongoDB 來處理具有簡單數據需求的短期項目。
我們不喜歡 Firebase 的一件事是,它感覺與我們習慣的圍繞規範化數據構建的典型關係模型相去甚遠。 保持數據結構平坦意味著我們經常有更多的重複,隨著項目的增長,這可能會變得有點難看。 您最終不得不在多個位置更新相同的數據或嘗試將不同的引用連接在一起,從而導致多個查詢變得難以在代碼中進行推理。 雖然我們喜歡 Firebase,但我們從未真正愛上查詢語言,有時發現文檔乏善可陳。
一般來說,MongoDB 和 Firebase 都對非規範化數據有相似的關注,並且由於無法訪問高效的事務,我們經常發現許多工作流很容易在關係數據庫中建模,這導致應用層的代碼更加複雜,它們的NoSQL 對應物。 如果我們能夠獲得這些 NoSQL 產品的靈活性和易用性以及傳統 SQL 數據庫的健壯性和關係建模,我們真的會找到一個很好的匹配項。 我們認為 MongoDB 具有更好的 API 和功能,但 Firebase 在操作上擁有真正的無服務器模型。
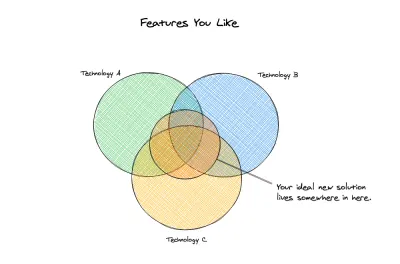
我們的理想
在這一點上,我們可以開始考慮我們將考慮哪些新選項。 我們已經清楚地定義了我們以前的解決方案,並且我們已經確定了對我們來說重要的事情,至少要在我們的新解決方案中擁有。 我們不僅有一個基線或最低要求集,而且我們還有一系列問題,我們希望新的解決方案能夠為我們緩解。 以下是我們的技術要求:
- 可按需擴展的無服務器操作
- 靈活建模(無模式)
- 不依賴遷移或 ORM
- 符合 ACID 的事務
- 支持關係和規範化數據
- 適用於無服務器和傳統後端
所以現在我們有了一份必備品清單,我們實際上可以評估一些選項。 新的解決方案在這裡釘住每一個目標可能並不重要。 可能只是它在現有解決方案不重疊的情況下達到了正確的功能組合。 例如,如果你想要無模式的靈活性,你必須放棄 ACID 事務。 (長期以來,數據庫就是這種情況。)
另一個領域的一個例子是,如果你想在模板渲染中進行打字稿驗證,你需要使用 TSX 和 React。 如果您使用 Svelte 或 Vue 之類的選項,您可以通過模板渲染獲得它——部分但不是全部。 因此,即使缺少其他功能,使用 React 和 TypeScript 的模板級別類型檢查為您提供 Svelte 的微小占用空間和速度的解決方案也足以被採用。 項目之間的平衡、需求和需求將發生變化。 由您決定價值將在哪裡,並決定如何勾選分析中最重要的點。
我們現在可以查看一個解決方案,看看它如何根據我們想要的解決方案進行評估。 Fauna是一種無服務器數據庫解決方案,擁有全球分佈的按需規模。 它是一個無模式數據庫,提供符合 ACID 的事務,並支持關係查詢和規範化數據作為一項功能。 Fauna 可用於無服務器應用程序以及更傳統的後端,並提供與最流行語言一起使用的庫。 Fauna 還提供身份驗證工作流程以及簡單高效的多租戶。 這些都是需要注意的可靠附加功能,因為當兩種技術在我們的評估中並駕齊驅時,它們可能是影響因素。
現在,在查看了所有這些優勢之後,我們必須評估劣勢。 其中之一是 Fauna 不是開源的。 這確實意味著存在供應商鎖定的風險,或者您無法控制的業務和定價變化。 開源可能很好,因為如果您願意或可能回饋項目,您可以經常將技術提供給另一個供應商。
在代理世界中,供應商鎖定是我們必須密切關注的事情,與其說是因為價格,不如說是因為基礎業務的可行性。 必須更改處於開發中期或幾年前的項目的數據庫對於代理機構來說都是災難性的。 通常,客戶必須為此買單,這不是一次愉快的談話。
我們關注的另一個弱點是對JAMstack的關注。 雖然我們喜歡 JAMstack,但我們發現自己構建各種傳統 Web 應用程序的頻率更高。 我們希望確保 Fauna 繼續支持這些用例。 過去,我們與一家託管服務提供商的經歷很糟糕,該提供商全力投入 JAMstack,我們最終不得不從該服務中遷移相當多的網站,因此我們希望對所有用例都將繼續看到充滿信心堅實的支持。 目前,情況似乎如此,Fauna 提供的無服務器工作流實際上可以很好地補充更傳統的應用程序。
在這一點上,我們已經完成了我們的功能研究,並且知道這個解決方案是否可行的唯一方法是開始編寫一些代碼。 在代理環境中,我們不能只花幾週的時間讓人們評估多種解決方案。 這是在代理機構與 SaaS 環境中工作的本質。 在後者中,您可能會構建一些原型來嘗試找到正確的解決方案。 在代理商中,您將有幾天的時間進行試驗,或者可能有機會做一個附帶項目,但總的來說,在這個階段我們確實必須將其縮小到一兩種技術,然後將手指放在鍵盤上。
開發者體驗
判斷新技術的體驗方面可能是三個領域中最困難的,因為它本質上是主觀的。 它也會因團隊而異。 例如,如果你問一個 Ruby 程序員、一個 Python 程序員和一個 Rust 程序員他們對不同語言特性的看法,你會得到相當多的回答。 因此,在您開始判斷體驗之前,您必須首先確定哪些特徵對您的團隊整體而言最重要。

對於代理商,我認為在開發人員體驗方面存在兩個主要瓶頸:
- 設置時間和配置
- 易學性
這兩者都以不同的方式影響新技術的長期可行性。 在代理機構中讓臨時的開發人員團隊保持同步可能是一件令人頭疼的事情。 眾所周知,具有大量前期設置成本和配置的工具很難讓代理商使用。 另一個是可學習性以及開發人員開發新技術的難易程度。 在開始評估開發人員體驗時,我們將更詳細地討論這些內容以及為什麼它們是我的基礎。

設置時間和配置
代理商往往沒有足夠的耐心和時間進行配置。 對我來說,我喜歡鋒利的工具,採用符合人體工程學的設計,讓我能夠快速解決手頭的業務問題。 幾年前,我曾在一家 SaaS 公司工作,該公司有一個複雜的本地設置,涉及許多配置,並且經常在設置過程中的隨機點失敗。 設置好之後,傳統觀念是不要碰任何東西,並希望你在公司的時間不夠長,以至於不得不在另一台機器上重新設置它。 我遇到過非常喜歡配置他們的 emacs 設置的每一小部分的開發人員,並且沒有想到會在一個破碎的本地環境中浪費幾個小時。
總的來說,我發現代理工程師在日常工作中對這些類型的事情不屑一顧。 在家裡,他們可能會修補這些類型的工具,但在截止日期前,沒有什麼能像工具一樣正常工作。 在代理機構,我們通常更願意學習一些效果良好、始終如一的新事物,而不是能夠根據每個人的個人品味來配置每項技術。
使用非開源雲平台的好處是他們完全擁有設置和配置。 雖然這樣做的缺點是供應商鎖定,但好處是這些類型的工具通常會做他們設置好的事情。 無需修補環境,無需本地設置,也無需部署管道。 我們要做的決定也更少。
這本質上就是無服務器的吸引力。 總的來說,無服務器對專有服務和工具的依賴程度更高。 我們交換託管和源代碼的靈活性,以便我們可以獲得更大的穩定性並專注於我們試圖解決的業務領域的問題。 我還要指出,當我在評估一項技術時,我覺得可能需要從平台遷移,這通常在一開始就不是一個好兆頭。
在數據庫的情況下,當與數據庫需求可能不明確的客戶合作時,設置即忘記設置是理想的。 我們的客戶不確定某個程序或應用程序的受歡迎程度。 我們有一些客戶在技術上沒有簽約以這種方式提供支持,但當他們需要我們擴展他們的數據庫或應用程序時,他們還是驚慌失措地打電話給我們。
過去,我們在製作 SOW 時總是必須考慮冗餘、數據複製和分片以擴展等因素。 試圖涵蓋每個場景,同時還準備在數據庫無法擴展的情況下移動一整本業務書,這是不可能準備的情況。 最後,無服務器數據庫使這些事情變得更容易。
您永遠不會丟失數據,您不必擔心跨網絡複製數據,也不必配置更大的數據庫和機器來運行它——這一切都可以正常工作。 我們只關注手頭的業務問題,技術架構和規模將始終得到管理。 對於我們的開發團隊來說,這是一個巨大的勝利; 我們的消防演習、監控和上下文切換更少。
易學性
有一個經典的用戶體驗衡量標準,我認為它適用於開發者體驗,那就是易學性。 在為某種用戶體驗進行設計時,我們不只是看第一次嘗試是否明顯或容易。 技術只是比大多數時候更複雜。 重要的是新用戶學習和掌握系統的難易程度。
談到技術工具,尤其是功能強大的工具時,要求零學習曲線是很重要的。 通常我們尋找的是最常見的用例有很好的文檔,並且在項目中可以輕鬆快速地構建這些知識。 浪費一點時間來學習第一個技術項目是可以的。 在那之後,我們應該看到每個後續項目的效率都會提高。
我在這里特別尋找的是我們如何利用我們已經知道的知識和模式來幫助縮短學習曲線。 例如,對於無服務器數據庫,在雲中設置和部署它們的學習曲線幾乎為零。 當談到使用數據庫時,我喜歡的一件事是當我們仍然可以利用多年來掌握關係數據庫並將這些學習應用到我們的新設置時。 在這種情況下,我們正在學習如何使用新工具,但這並沒有迫使我們從頭開始重新考慮我們的數據建模。

例如,在使用 Firebase、MongoDB 和 DynamoDB 時,我們發現它鼓勵非規範化數據,而不是嘗試加入不同的文檔。 這在對我們的數據進行建模時產生了很多認知摩擦,因為我們需要根據訪問模式而不是業務實體進行思考。 在這個動物群的另一邊,我們可以利用我們多年的關係知識以及我們在建模數據時對規範化數據的偏好。
我們必須習慣的部分是使用索引和新的查詢語言將這些部分組合在一起。 總的來說,我發現保留作為更大軟件設計範式一部分的概念可以使開發團隊在可學習性和採用方面更容易。
我們如何知道一個團隊正在採用和喜愛一項新技術? 我認為最好的跡像是當我們發現自己在問該工具是否與上述新技術集成時? 當一項新技術達到了團隊正在尋找將其納入更多項目的方法的渴望和享受的水平時,這是一個好兆頭,你有一個贏家。
這生意
在本節中,我們必須了解一項新技術如何滿足我們的業務需求。 這些問題包括:
- 它的定價和集成到我們的支持計劃中有多容易?
- 我們可以輕鬆地將其轉移給客戶嗎?
- 如果需要,客戶可以使用此工具嗎?
- 如果有的話,這個工具實際上可以節省多少時間?
無服務器作為一種範式的興起非常適合代理機構。 當我們談論數據庫和 DevOps 時,機構對這些領域專家的需求是有限的。 通常,當我們完成一個項目或以有限的能力長期支持它時,我們會移交一個項目。 我們傾向於偏向全棧工程師,因為這些需求在很大程度上超過了 DevOps 的需求。 如果我們聘請了 DevOps 工程師,他們可能會花費幾個小時來部署一個項目,並花費更多的時間等待著火。
在這方面,我們總是準備好一些DevOps 承包商,但不會全職為這些職位配備人員。 這意味著我們不能依賴 DevOps 工程師準備好應對意外問題。 對於我們來說,我們知道通過直接訪問 AWS 可以獲得更好的託管費率,但我們也知道通過使用 Heroku,我們可以依靠我們現有的員工來調試大多數問題。 除非我們有需要長期支持特定後端需求的客戶端,否則我們喜歡默認託管平台即服務。
數據庫也不例外。 我們喜歡依靠像 Mongo Atlas 或 Heroku Postgres 這樣的服務來使這個過程盡可能簡單。 隨著我們開始看到越來越多的堆棧轉向 Vercel、Netlify 或 AWS Lambda 等無服務器工具,我們的數據庫需求必須隨之發展。 Firebase、DynamoDB 和 Fauna 等無服務器數據庫非常棒,因為它們與無服務器應用程序集成得很好,而且還讓我們的業務完全免於配置和擴展。
這些解決方案也適用於更傳統的應用程序,我們沒有無服務器應用程序,但我們仍然可以在數據庫級別利用無服務器效率。 作為一家企業,我們學習一個可以同時適用於兩個世界的數據庫比上下文切換更有效率。 這類似於我們決定採用 Node 和同構 JavaScript(和 TypeScript)。
我們發現無服務器的缺點之一是為我們管理這些服務的客戶定價。 在更傳統的架構中,統一費率等級可以很容易地將這些費率轉換為客戶的費率,這些客戶在可預測的情況下會發生增加和超額。 當談到無服務器時,這可能是模棱兩可的。 財務人員通常不喜歡聽到我們每閱讀超過 100 萬次就收取 1/10 美分的費用,等等。
即使對於工程師來說,這也很難轉化為一個固定的數字,因為我們經常構建不確定用途的應用程序。 我們經常必須自己創建層,但是 lambda 成本計算中的許多變量可能很難讓您理解。 最終,對於 SaaS 產品來說,這些現收現付定價模型非常棒,但對於代理機構來說,會計師喜歡更具體和可預測的數字。
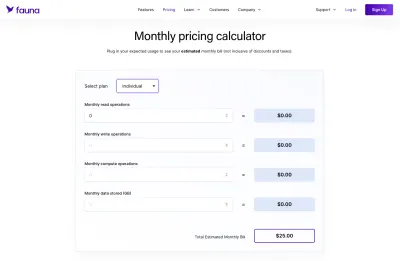
對於 Fauna,這肯定比說一個標準的 MySQL 數據庫更加模糊,該數據庫在一定數量的空間中具有固定費率的託管。 好處是 Fauna 提供了一個很好的計算器,我們可以用它來組合我們自己的定價方案。
無服務器的另一個困難方面可能是這些提供商中的許多都不允許輕鬆分解託管的每個應用程序。 例如,Heroku 平台通過創建新的管道和團隊使這變得非常容易。 如果他們不想使用我們的託管計劃,我們甚至可以為他們輸入客戶的信用卡。 這也可以在同一個儀表板中完成,因此我們不需要創建多個登錄。
當涉及到其他無服務器工具時,這要困難得多。 在評估無服務器數據庫時,Firebase 支持按項目拆分付款。 在 Fauna 或 DynamoDB 的情況下,這是不可能的,所以我們必須做一些工作來監控他們儀表板中的使用情況,如果客戶想離開我們的服務,我們必須將數據庫轉移到他們自己的帳戶。
最終,無服務器工具在成本節約、管理和流程效率方面提供了巨大的商機。 然而,在定價和賬戶管理方面,它們通常確實對代理商具有挑戰性。 這是我們必須利用成本計算器來創建我們自己的可預測定價層或使用自己的帳戶設置客戶以便他們可以直接付款的一個領域。
結論
作為代理機構採用新技術可能是一項艱鉅的任務。 雖然我們在與有新技術機會的新的、未開發的項目合作方面處於獨特的地位,但我們還必須考慮這些項目的長期投資。 他們將如何表現? 我們的員工會高效並喜歡使用它們嗎? 我們可以將它們納入我們的業務產品嗎?
You need to have a firm grasp of where you have been before you figure out where you want to go technologically. When evaluating a new tool or platform it's important to think of what you have tried in the past and figure out what is most important to you and your team. We took a look at the concept of a serverless database and passed it through our three lenses – the technology, the experience, and the business. We were left with some pros and cons and had to strike the right balance.
After we evaluated serverless databases, we decided to adopt Fauna over the alternatives. We felt the technology was robust and ticked all of our boxes for our technology filter. When it came to the experience, virtually zero configuration and being able to leverage our existing knowledge of relational data modeling made this a winner with the development team. On the business side serverless provides clear wins to efficiency and productivity , however on the pricing side and account management there are still some difficulties. We decided the benefits in the other areas outweighed the pricing difficulties.
Overall, we highly recommend giving Fauna a shot on one of your next projects. It has become one of our favorite tools and our go-to database of choice for smaller serverless projects and even more traditional large backend applications. The community is very helpful, the learning curve is gentle, and we believe you'll find levels of productivity you hadn't realized before with existing databases.
When we first use a new technology on a project, we start with something either internal or on the smaller side. We try to mitigate the risk by wading into the water rather than leaping into the deep end by trying it on a large and complex project. As the team builds understanding of the technology, we start using it for larger projects but only after we feel comfortable that it has handled similar use cases well for us in the past.
In general, it can take up to a year for a technology to become a ubiquitous part of most projects so it is important to be patient. Agencies have a lot of flexibility but also are required to ensure stability in the products they produce, we don't get a second chance. Always be experimenting and pushing your agency to adopt new technologies, but do so carefully and you will reap the benefits.
延伸閱讀
- Serverless Database Wishlist - What's Missing Today
- Relational NoSQL: Yes, that is an option
- Concerning toolkits - A great piece about the merits of zero configuration on developer experience