
在 Mac OS 上為物聯網設備構建房間探測器
已發表: 2022-03-10知道你在哪個房間可以啟用各種物聯網應用程序——從開燈到改變電視頻道。 那麼,我們如何檢測您和您的手機在廚房、臥室或客廳的那一刻呢? 使用今天的商品硬件,有無數種可能性:
一種解決方案是為每個房間配備藍牙設備。 一旦您的手機在藍牙設備的範圍內,您的手機就會根據藍牙設備知道它在哪個房間。 然而,維護一系列藍牙設備的開銷很大——從更換電池到更換功能失調的設備。 此外,靠近藍牙設備並不總是答案:如果你在客廳,靠近與廚房共用的牆壁,你的廚房電器不應該開始生產食物。
另一個雖然不切實際的解決方案是使用 GPS 。 但是,請記住 GPS 在室內效果不佳,其中大量牆壁、其他信號和其他障礙物對 GPS 的精度造成嚴重破壞。
相反,我們的方法是利用所有範圍內的 WiFi 網絡——即使是您的手機未連接的網絡。 方法如下:考慮廚房 WiFi A 的強度; 說是5。由於廚房和臥室之間有一堵牆,我們可以合理地預計臥室WiFi A的強度會有所不同; 假設是 2。我們可以利用這種差異來預測我們在哪個房間。更重要的是:來自我們鄰居的 WiFi 網絡 B 只能從客廳檢測到,但從廚房實際上是不可見的。 這使得預測更加容易。 總之,所有範圍內 WiFi 的列表為我們提供了豐富的信息。
這種方法具有以下明顯優點:
- 不需要更多硬件;
- 依靠WiFi等更穩定的信號;
- 在 GPS 等其他技術較弱的情況下運行良好。
牆越多越好,因為 WiFi 網絡強度越不同,房間就越容易分類。 您將構建一個簡單的桌面應用程序,用於收集數據、從數據中學習並預測您在任何給定時間所處的房間。
關於 SmashingMag 的進一步閱讀:
- 智能對話 UI 的興起
- 機器學習對設計師的應用
- 如何原型物聯網體驗:構建硬件
- 為情感物聯網設計
先決條件
對於本教程,您將需要 Mac OSX。 雖然代碼可以適用於任何平台,但我們只會提供 Mac 的依賴項安裝說明。
- Mac OSX
- Homebrew,Mac OSX 的包管理器。 要安裝,請複制並粘貼 brew.sh 中的命令
- 安裝 NodeJS 10.8.0+ 和 npm
- 安裝 Python 3.6+ 和 pip。 請參閱“如何安裝 virtualenv、使用 pip 安裝和管理包”的前 3 部分
步驟 0:設置工作環境
您的桌面應用程序將使用 NodeJS 編寫。 但是,為了利用更高效的計算庫(如numpy ),訓練和預測代碼將用 Python 編寫。 首先,我們將設置您的環境並安裝依賴項。 創建一個新目錄來存放您的項目。
mkdir ~/riot導航到目錄。
cd ~/riot使用 pip 安裝 Python 的默認虛擬環境管理器。
sudo pip install virtualenv 創建一個名為riot的 Python3.6 虛擬環境。
virtualenv riot --python=python3.6激活虛擬環境。
source riot/bin/activate 您的提示現在以(riot) 。 這表明我們已經成功進入虛擬環境。 使用pip安裝以下軟件包:
-
numpy: 一個高效的線性代數庫 scipy:實現流行機器學習模型的科學計算庫
pip install numpy==1.14.3 scipy ==1.1.0通過工作目錄設置,我們將從記錄範圍內所有 WiFi 網絡的桌面應用程序開始。 這些記錄將構成您的機器學習模型的訓練數據。 一旦我們手頭有數據,您將編寫一個最小二乘分類器,在之前收集的 WiFi 信號上進行訓練。 最後,我們將根據范圍內的 WiFi 網絡,使用最小二乘模型來預測您所在的房間。
第 1 步:初始桌面應用程序
在這一步中,我們將使用 Electron JS 創建一個新的桌面應用程序。 首先,我們將改為使用 Node 包管理器npm和下載實用程序wget 。
brew install npm wget首先,我們將創建一個新的 Node 項目。
npm init 這會提示您輸入包名稱,然後是版本號。 按ENTER接受默認名稱riot和默認版本1.0.0 。
package name: (riot) version: (1.0.0) 這會提示您輸入項目描述。 添加您想要的任何非空描述。 下面,描述的是room detector
description: room detector 這會提示您輸入入口點,或從中運行項目的主文件。 輸入app.js 。
entry point: (index.js) app.js 這會提示您輸入test command和git repository 。 點擊ENTER暫時跳過這些字段。
test command: git repository: 這會提示您輸入keywords和author 。 填寫您想要的任何值。 下面,我們使用iot , wifi作為關鍵字,使用John Doe作為作者。
keywords: iot,wifi author: John Doe 這會提示您輸入許可證。 按ENTER接受ISC的默認值。
license: (ISC) 此時, npm會提示您到目前為止的信息摘要。 您的輸出應類似於以下內容。
{ "name": "riot", "version": "1.0.0", "description": "room detector", "main": "app.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "keywords": [ "iot", "wifi" ], "author": "John Doe", "license": "ISC" } 按ENTER接受。 npm然後生成一個package.json 。 列出所有要仔細檢查的文件。
ls這將輸出此目錄中的唯一文件以及虛擬環境文件夾。
package.json riot為我們的項目安裝 NodeJS 依賴項。
npm install electron --global # makes electron binary accessible globally npm install node-wifi --save 從 Electron 快速入門中的main.js開始,通過下載文件,使用以下內容。 以下-O參數將main.js重命名為app.js 。
wget https://raw.githubusercontent.com/electron/electron-quick-start/master/main.js -O app.js 在nano或您喜歡的文本編輯器中打開app.js
nano app.js 在第 12 行,將index.html更改為static/index.html ,因為我們將創建一個目錄static來包含所有 HTML 模板。
function createWindow () { // Create the browser window. win = new BrowserWindow({width: 1200, height: 800}) // and load the index.html of the app. win.loadFile('static/index.html') // Open the DevTools. 保存更改並退出編輯器。 您的文件應與app.js文件的源代碼匹配。 現在創建一個新目錄來存放我們的 HTML 模板。
mkdir static下載為此項目創建的樣式表。
wget https://raw.githubusercontent.com/alvinwan/riot/master/static/style.css?token=AB-ObfDtD46ANlqrObDanckTQJ2Q1Pyuks5bf79PwA%3D%3D -O static/style.css 在nano或您喜歡的文本編輯器中打開static/index.html 。 從標準的 HTML 結構開始。
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Room Detector</title> </head> <body> <main> </main> </body> </html>在標題之後,鏈接由 Google 字體和样式錶鍊接的 Montserrat 字體。
<title>Riot | Room Detector</title> <!-- start new code --> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> <!-- end new code --> </head> 在main標籤之間,為預測的房間名稱添加一個槽。
<main> <!-- start new code --> <p class="text">I believe you're in the</p> <h1 class="title">(I dunno)</h1> <!-- end new code --> </main>您的腳本現在應該與以下內容完全匹配。 退出編輯器。
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Room Detector</title> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> </head> <body> <main> <p class="text">I believe you're in the</p> <h1 class="title">(I dunno)</h1> </main> </body> </html>現在,修改包文件以包含啟動命令。
nano package.json 在第 7 行之後,添加一個別名為electron .的start命令。 . 確保在上一行的末尾添加一個逗號。
"scripts": { "test": "echo \"Error: no test specified\" && exit 1", "start": "electron ." }, 保存並退出。 您現在已準備好在 Electron JS 中啟動您的桌面應用程序。 使用npm啟動您的應用程序。
npm start您的桌面應用程序應符合以下條件。

這樣就完成了您的啟動桌面應用程序。 要退出,請導航回您的終端並按 CTRL+C。 在下一步中,我們將記錄 wifi 網絡,並使記錄實用程序可通過桌面應用程序 UI 訪問。
第 2 步:記錄 WiFi 網絡
在這一步中,您將編寫一個 NodeJS 腳本來記錄所有範圍內 wifi 網絡的強度和頻率。 為您的腳本創建一個目錄。
mkdir scripts 在nano或您喜歡的文本編輯器中打開scripts/observe.js 。
nano scripts/observe.js導入 NodeJS wifi 實用程序和文件系統對象。
var wifi = require('node-wifi'); var fs = require('fs'); 定義一個接受完成處理程序的record函數。
/** * Uses a recursive function for repeated scans, since scans are asynchronous. */ function record(n, completion, hook) { } 在新函數中,初始化 wifi 實用程序。 將iface設置為 null 以初始化為隨機 wifi 接口,因為此值當前無關緊要。
function record(n, completion, hook) { wifi.init({ iface : null }); }定義一個數組來包含您的樣本。 樣本是我們將用於模型的訓練數據。 本特定教程中的示例是范圍內 wifi 網絡及其相關強度、頻率、名稱等的列表。
function record(n, completion, hook) { ... samples = [] } 定義一個遞歸函數startScan ,它將異步啟動 wifi 掃描。 完成後,異步 wifi 掃描將遞歸調用startScan 。
function record(n, completion, hook) { ... function startScan(i) { wifi.scan(function(err, networks) { }); } startScan(n); } 在wifi.scan回調中,檢查錯誤或網絡列表是否為空,如果是則重新開始掃描。
wifi.scan(function(err, networks) { if (err || networks.length == 0) { startScan(i); return } });添加遞歸函數的基本情況,它調用完成處理程序。
wifi.scan(function(err, networks) { ... if (i <= 0) { return completion({samples: samples}); } });輸出進度更新,附加到樣本列表,並進行遞歸調用。
wifi.scan(function(err, networks) { ... hook(n-i+1, networks); samples.push(networks); startScan(i-1); }); 在文件末尾,使用回調調用record函數,將樣本保存到磁盤上的文件中。
function record(completion) { ... } function cli() { record(1, function(data) { fs.writeFile('samples.json', JSON.stringify(data), 'utf8', function() {}); }, function(i, networks) { console.log(" * [INFO] Collected sample " + (21-i) + " with " + networks.length + " networks"); }) } cli();仔細檢查您的文件是否與以下內容匹配:
var wifi = require('node-wifi'); var fs = require('fs'); /** * Uses a recursive function for repeated scans, since scans are asynchronous. */ function record(n, completion, hook) { wifi.init({ iface : null // network interface, choose a random wifi interface if set to null }); samples = [] function startScan(i) { wifi.scan(function(err, networks) { if (err || networks.length == 0) { startScan(i); return } if (i <= 0) { return completion({samples: samples}); } hook(n-i+1, networks); samples.push(networks); startScan(i-1); }); } startScan(n); } function cli() { record(1, function(data) { fs.writeFile('samples.json', JSON.stringify(data), 'utf8', function() {}); }, function(i, networks) { console.log(" * [INFO] Collected sample " + i + " with " + networks.length + " networks"); }) } cli();保存並退出。 運行腳本。
node scripts/observe.js您的輸出將與以下內容匹配,具有可變數量的網絡。
* [INFO] Collected sample 1 with 39 networks 檢查剛剛收集的樣本。 管道到json_pp以漂亮地打印 JSON 並管道到 head 查看前 16 行。
cat samples.json | json_pp | head -16以下是 2.4 GHz 網絡的示例輸出。
{ "samples": [ [ { "mac": "64:0f:28:79:9a:29", "bssid": "64:0f:28:79:9a:29", "ssid": "SMASHINGMAGAZINEROCKS", "channel": 4, "frequency": 2427, "signal_level": "-91", "security": "WPA WPA2", "security_flags": [ "(PSK/AES,TKIP/TKIP)", "(PSK/AES,TKIP/TKIP)" ] },您的 NodeJS wifi 掃描腳本到此結束。 這使我們能夠查看所有範圍內的 WiFi 網絡。 在下一步中,您將使該腳本可從桌面應用程序訪問。
第 3 步:將掃描腳本連接到桌面應用程序
在此步驟中,您將首先向桌面應用程序添加一個按鈕來觸發腳本。 然後,您將使用腳本的進度更新桌面應用程序 UI。
打開static/index.html 。
nano static/index.html插入“添加”按鈕,如下圖所示。
<h1 class="title">(I dunno)</h1> <!-- start new code --> <div class="buttons"> <a href="add.html" class="button">Add new room</a> </div> <!-- end new code --> </main> 保存並退出。 打開static/add.html 。
nano static/add.html粘貼以下內容。
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Add New Room</title> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> </head> <body> <main> <h1 class="title">0</h1> <p class="subtitle">of <span>20</span> samples needed. Feel free to move around the room.</p> <input type="text" class="text-field" placeholder="(room name)"> <div class="buttons"> <a href="#" class="button">Start recording</a> <a href="index.html" class="button light">Cancel</a> </div> <p class="text"></p> </main> <script> require('../scripts/observe.js') </script> </body> </html> 保存並退出。 重新打開scripts/observe.js 。
nano scripts/observe.js 在cli函數下,定義一個新的ui函數。
function cli() { ... } // start new code function ui() { } // end new code cli();更新桌面應用程序狀態以指示該功能已開始運行。
function ui() { var room_name = document.querySelector('#add-room-name').value; var status = document.querySelector('#add-status'); var number = document.querySelector('#add-title'); status.style.display = "block" status.innerHTML = "Listening for wifi..." }將數據劃分為訓練和驗證數據集。
function ui() { ... function completion(data) { train_data = {samples: data['samples'].slice(0, 15)} test_data = {samples: data['samples'].slice(15)} var train_json = JSON.stringify(train_data); var test_json = JSON.stringify(test_data); } } 仍在completion回調中,將兩個數據集寫入磁盤。
function ui() { ... function completion(data) { ... fs.writeFile('data/' + room_name + '_train.json', train_json, 'utf8', function() {}); fs.writeFile('data/' + room_name + '_test.json', test_json, 'utf8', function() {}); console.log(" * [INFO] Done") status.innerHTML = "Done." } } 使用適當的回調調用record以記錄 20 個樣本並將樣本保存到磁盤。
function ui() { ... function completion(data) { ... } record(20, completion, function(i, networks) { number.innerHTML = i console.log(" * [INFO] Collected sample " + i + " with " + networks.length + " networks") }) } 最後,在適當的地方調用cli和ui函數。 首先刪除cli(); 在文件底部調用。
function ui() { ... } cli(); // remove me 檢查文檔對像是否可全局訪問。 如果不是,則腳本正在從命令行運行。 在這種情況下,調用cli函數。 如果是,則從桌面應用程序中加載腳本。 在這種情況下,將點擊監聽器綁定到ui函數。
if (typeof document == 'undefined') { cli(); } else { document.querySelector('#start-recording').addEventListener('click', ui) }保存並退出。 創建一個目錄來保存我們的數據。
mkdir data啟動桌面應用程序。
npm start您將看到以下主頁。 點擊“添加房間”。
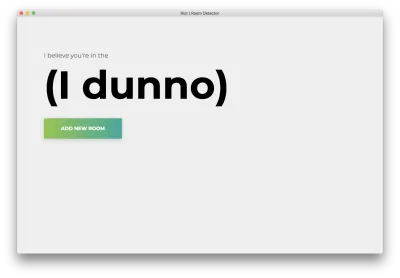
您將看到以下表格。 輸入房間的名稱。 記住這個名字,因為我們稍後會用到它。 我們的例子是bedroom 。
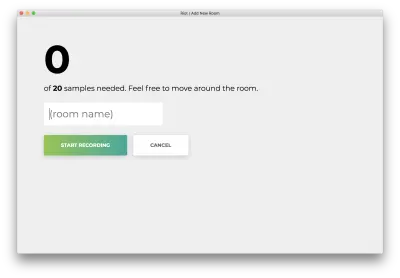
單擊“開始錄製”,您將看到以下狀態“正在偵聽 wifi...”。
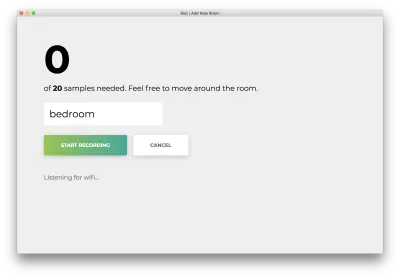
記錄所有 20 個樣本後,您的應用將匹配以下內容。 狀態將顯示為“完成”。
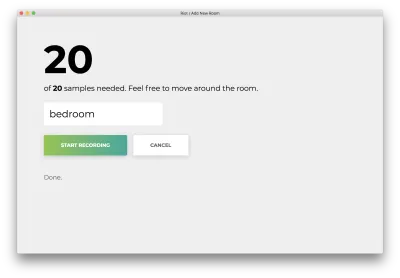
點擊誤命名的“取消”返回首頁,與以下內容相符。

我們現在可以從桌面 UI 掃描 wifi 網絡,這會將所有記錄的樣本保存到磁盤上的文件中。 接下來,我們將根據您收集的數據訓練一個開箱即用的機器學習算法——最小二乘。
第 4 步:編寫 Python 訓練腳本
在這一步中,我們將用 Python 編寫一個訓練腳本。 為您的訓練實用程序創建一個目錄。
mkdir model 打開model/train.py
nano model/train.py 在文件的頂部,導入numpy計算庫和scipy用於其最小二乘模型。
import numpy as np from scipy.linalg import lstsq import json import sys接下來的三個實用程序將處理從磁盤上的文件加載和設置數據。 首先添加一個扁平化嵌套列表的實用程序函數。 您將使用它來展平樣本列表。
import sys def flatten(list_of_lists): """Flatten a list of lists to make a list. >>> flatten([[1], [2], [3, 4]]) [1, 2, 3, 4] """ return sum(list_of_lists, []) 添加從指定文件加載樣本的第二個實用程序。 此方法抽像出樣本分佈在多個文件中的事實,只為所有樣本返回一個生成器。 對於每個樣本,標籤是文件的索引。 例如,如果您調用get_all_samples('a.json', 'b.json') , a.json中的所有樣本都將具有標籤 0,而b.json中的所有樣本將具有標籤 1。
def get_all_samples(paths): """Load all samples from JSON files.""" for label, path in enumerate(paths): with open(path) as f: for sample in json.load(f)['samples']: signal_levels = [ network['signal_level'].replace('RSSI', '') or 0 for network in sample] yield [network['mac'] for network in sample], signal_levels, label接下來,添加一個使用詞袋模型對樣本進行編碼的實用程序。 這是一個示例:假設我們收集了兩個樣本。
- wifi 網絡 A 強度為 10,wifi 網絡 B 強度為 15
- wifi 網絡 B 強度為 20,wifi 網絡 C 強度為 25。
此函數將為每個樣本生成一個包含三個數字的列表:第一個值是 wifi 網絡 A 的強度,第二個值是網絡 B,第三個值是 C。實際上,格式是 [A, B, C ]。
- [10, 15, 0]
- [0, 20, 25]
def bag_of_words(all_networks, all_strengths, ordering): """Apply bag-of-words encoding to categorical variables. >>> samples = bag_of_words( ... [['a', 'b'], ['b', 'c'], ['a', 'c']], ... [[1, 2], [2, 3], [1, 3]], ... ['a', 'b', 'c']) >>> next(samples) [1, 2, 0] >>> next(samples) [0, 2, 3] """ for networks, strengths in zip(all_networks, all_strengths): yield [strengths[networks.index(network)] if network in networks else 0 for network in ordering] 使用上述所有三個實用程序,我們合成了一組樣本及其標籤。 使用get_all_samples收集所有樣本和標籤。 定義一致的格式ordering以對所有樣本進行 one-hot 編碼,然後將one_hot編碼應用於樣本。 最後,分別構造數據和標籤矩陣X和Y
def create_dataset(classpaths, ordering=None): """Create dataset from a list of paths to JSON files.""" networks, strengths, labels = zip(*get_all_samples(classpaths)) if ordering is None: ordering = list(sorted(set(flatten(networks)))) X = np.array(list(bag_of_words(networks, strengths, ordering))).astype(np.float64) Y = np.array(list(labels)).astype(np.int) return X, Y, ordering這些功能完善了數據管道。 接下來,我們抽像出模型預測和評估。 首先定義預測方法。 第一個函數對我們的模型輸出進行歸一化,以便所有值的總和為 1,並且所有值都是非負的; 這確保了輸出是一個有效的概率分佈。 第二個評估模型。
def softmax(x): """Convert one-hotted outputs into probability distribution""" x = np.exp(x) return x / np.sum(x) def predict(X, w): """Predict using model parameters""" return np.argmax(softmax(X.dot(w)), axis=1)接下來,評估模型的準確性。 第一行使用模型運行預測。 第二個計算預測值和真實值一致的次數,然後按樣本總數進行歸一化。
def evaluate(X, Y, w): """Evaluate model w on samples X and labels Y.""" Y_pred = predict(X, w) accuracy = (Y == Y_pred).sum() / X.shape[0] return accuracy 我們的預測和評估實用程序到此結束。 在這些實用程序之後,定義一個將收集數據集、訓練和評估的main函數。 首先從命令行sys.argv讀取參數列表; 這些是包含在培訓中的房間。 然後從所有指定的房間創建一個大型數據集。
def main(): classes = sys.argv[1:] train_paths = sorted(['data/{}_train.json'.format(name) for name in classes]) test_paths = sorted(['data/{}_test.json'.format(name) for name in classes]) X_train, Y_train, ordering = create_dataset(train_paths) X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering)將 one-hot 編碼應用於標籤。 one-hot 編碼類似於上面的詞袋模型。 我們使用這種編碼來處理分類變量。 假設我們有 3 個可能的標籤。 我們沒有標記 1、2 或 3,而是用 [1, 0, 0]、[0, 1, 0] 或 [0, 0, 1] 標記數據。 對於本教程,我們將不解釋為什麼 one-hot 編碼很重要。 訓練模型,並在訓練集和驗證集上進行評估。
def main(): ... X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering) Y_train_oh = np.eye(len(classes))[Y_train] w, _, _, _ = lstsq(X_train, Y_train_oh) train_accuracy = evaluate(X_train, Y_train, w) test_accuracy = evaluate(X_test, Y_test, w)打印兩個精度,並將模型保存到磁盤。
def main(): ... print('Train accuracy ({}%), Validation accuracy ({}%)'.format(train_accuracy*100, test_accuracy*100)) np.save('w.npy', w) np.save('ordering.npy', np.array(ordering)) sys.stdout.flush() 在文件末尾,運行main函數。
if __name__ == '__main__': main()保存並退出。 仔細檢查您的文件是否與以下內容匹配:
import numpy as np from scipy.linalg import lstsq import json import sys def flatten(list_of_lists): """Flatten a list of lists to make a list. >>> flatten([[1], [2], [3, 4]]) [1, 2, 3, 4] """ return sum(list_of_lists, []) def get_all_samples(paths): """Load all samples from JSON files.""" for label, path in enumerate(paths): with open(path) as f: for sample in json.load(f)['samples']: signal_levels = [ network['signal_level'].replace('RSSI', '') or 0 for network in sample] yield [network['mac'] for network in sample], signal_levels, label def bag_of_words(all_networks, all_strengths, ordering): """Apply bag-of-words encoding to categorical variables. >>> samples = bag_of_words( ... [['a', 'b'], ['b', 'c'], ['a', 'c']], ... [[1, 2], [2, 3], [1, 3]], ... ['a', 'b', 'c']) >>> next(samples) [1, 2, 0] >>> next(samples) [0, 2, 3] """ for networks, strengths in zip(all_networks, all_strengths): yield [int(strengths[networks.index(network)]) if network in networks else 0 for network in ordering] def create_dataset(classpaths, ordering=None): """Create dataset from a list of paths to JSON files.""" networks, strengths, labels = zip(*get_all_samples(classpaths)) if ordering is None: ordering = list(sorted(set(flatten(networks)))) X = np.array(list(bag_of_words(networks, strengths, ordering))).astype(np.float64) Y = np.array(list(labels)).astype(np.int) return X, Y, ordering def softmax(x): """Convert one-hotted outputs into probability distribution""" x = np.exp(x) return x / np.sum(x) def predict(X, w): """Predict using model parameters""" return np.argmax(softmax(X.dot(w)), axis=1) def evaluate(X, Y, w): """Evaluate model w on samples X and labels Y.""" Y_pred = predict(X, w) accuracy = (Y == Y_pred).sum() / X.shape[0] return accuracy def main(): classes = sys.argv[1:] train_paths = sorted(['data/{}_train.json'.format(name) for name in classes]) test_paths = sorted(['data/{}_test.json'.format(name) for name in classes]) X_train, Y_train, ordering = create_dataset(train_paths) X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering) Y_train_oh = np.eye(len(classes))[Y_train] w, _, _, _ = lstsq(X_train, Y_train_oh) train_accuracy = evaluate(X_train, Y_train, w) validation_accuracy = evaluate(X_test, Y_test, w) print('Train accuracy ({}%), Validation accuracy ({}%)'.format(train_accuracy*100, validation_accuracy*100)) np.save('w.npy', w) np.save('ordering.npy', np.array(ordering)) sys.stdout.flush() if __name__ == '__main__': main() 保存並退出。 回憶一下上面記錄 20 個樣本時使用的房間名稱。 使用該名稱而不是下面的bedroom 。 我們的例子是bedroom 。 我們使用-W ignore忽略來自 LAPACK 錯誤的警告。
python -W ignore model/train.py bedroom由於我們只收集了一個房間的訓練樣本,您應該會看到 100% 的訓練和驗證準確度。
Train accuracy (100.0%), Validation accuracy (100.0%)接下來,我們將此訓練腳本鏈接到桌面應用程序。
第 5 步:鏈接訓練腳本
在這一步中,每當用戶收集到一批新樣本時,我們都會自動重新訓練模型。 打開scripts/observe.js 。
nano scripts/observe.js 在fs導入之後,立即導入子進程生成器和實用程序。
var fs = require('fs'); // start new code const spawn = require("child_process").spawn; var utils = require('./utils.js'); 在ui函數中,在完成處理程序的末尾添加以下調用以retrain 。
function ui() { ... function completion() { ... retrain((data) => { var status = document.querySelector('#add-status'); accuracies = data.toString().split('\n')[0]; status.innerHTML = "Retraining succeeded: " + accuracies }); } ... } 在ui函數之後,添加以下retrain函數。 這會產生一個將運行 python 腳本的子進程。 完成後,該過程調用完成處理程序。 失敗時,它將記錄錯誤消息。
function ui() { .. } function retrain(completion) { var filenames = utils.get_filenames() const pythonProcess = spawn('python', ["./model/train.py"].concat(filenames)); pythonProcess.stdout.on('data', completion); pythonProcess.stderr.on('data', (data) => { console.log(" * [ERROR] " + data.toString()) }) } 保存並退出。 打開scripts/utils.js 。
nano scripts/utils.js 添加以下實用程序以獲取data/中的所有數據集。
var fs = require('fs'); module.exports = { get_filenames: get_filenames } function get_filenames() { filenames = new Set([]); fs.readdirSync("data/").forEach(function(filename) { filenames.add(filename.replace('_train', '').replace('_test', '').replace('.json', '' )) }); filenames = Array.from(filenames.values()) filenames.sort(); filenames.splice(filenames.indexOf('.DS_Store'), 1) return filenames }保存並退出。 為了完成此步驟,請物理移動到新位置。 理想情況下,您的原始位置和新位置之間應該有一堵牆。 障礙越多,您的桌面應用程序就會越好。
再次運行您的桌面應用程序。
npm start和以前一樣,運行訓練腳本。 點擊“添加房間”。
輸入與您的第一個房間不同的房間名稱。 我們將使用living room 。
單擊“開始錄製”,您將看到以下狀態“正在偵聽 wifi...”。
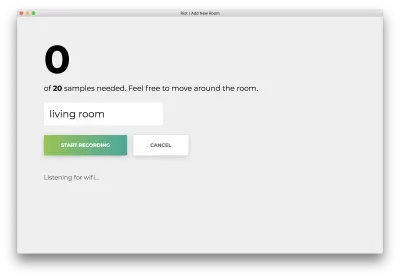
記錄所有 20 個樣本後,您的應用將匹配以下內容。 狀態將顯示為“完成。 再訓練模型……”
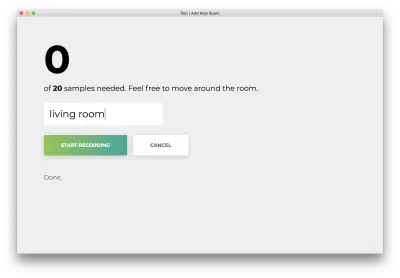
在下一步中,我們將使用這個重新訓練的模型來動態預測您所在的房間。
第 6 步:編寫 Python 評估腳本
在這一步中,我們將加載預訓練的模型參數,掃描 wifi 網絡,並根據掃描預測房間。
打開model/eval.py 。
nano model/eval.py導入我們上一個腳本中使用和定義的庫。
import numpy as np import sys import json import os import json from train import predict from train import softmax from train import create_dataset from train import evaluate 定義一個實用程序來提取所有數據集的名稱。 此函數假定所有數據集都以<dataset>_train.json和<dataset>_test.json的形式存儲在data/中。
from train import evaluate def get_datasets(): """Extract dataset names.""" return sorted(list({path.split('_')[0] for path in os.listdir('./data') if '.DS' not in path})) 定義main函數,並首先加載從訓練腳本中保存的參數。
def get_datasets(): ... def main(): w = np.load('w.npy') ordering = np.load('ordering.npy')創建數據集並進行預測。
def main(): ... classpaths = [sys.argv[1]] X, _, _ = create_dataset(classpaths, ordering) y = np.asscalar(predict(X, w))根據前兩個概率之間的差異計算置信度分數。
def main(): ... sorted_y = sorted(softmax(X.dot(w)).flatten()) confidence = 1 if len(sorted_y) > 1: confidence = round(sorted_y[-1] - sorted_y[-2], 2) 最後,提取類別並打印結果。 要結束腳本,請調用main函數。
def main() ... category = get_datasets()[y] print(json.dumps({"category": category, "confidence": confidence})) if __name__ == '__main__': main()保存並退出。 仔細檢查您的代碼是否與以下內容(源代碼)匹配:
import numpy as np import sys import json import os import json from train import predict from train import softmax from train import create_dataset from train import evaluate def get_datasets(): """Extract dataset names.""" return sorted(list({path.split('_')[0] for path in os.listdir('./data') if '.DS' not in path})) def main(): w = np.load('w.npy') ordering = np.load('ordering.npy') classpaths = [sys.argv[1]] X, _, _ = create_dataset(classpaths, ordering) y = np.asscalar(predict(X, w)) sorted_y = sorted(softmax(X.dot(w)).flatten()) confidence = 1 if len(sorted_y) > 1: confidence = round(sorted_y[-1] - sorted_y[-2], 2) category = get_datasets()[y] print(json.dumps({"category": category, "confidence": confidence})) if __name__ == '__main__': main()接下來,我們將此評估腳本連接到桌面應用程序。 桌面應用程序將持續運行 wifi 掃描並使用預測的房間更新 UI。
第 7 步:將評估連接到桌面應用程序
在這一步中,我們將使用“信心”顯示來更新 UI。 然後,相關的 NodeJS 腳本將持續運行掃描和預測,相應地更新 UI。
打開static/index.html 。
nano static/index.html在標題之後和按鈕之前添加一條信心線。
<h1 class="title">(I dunno)</h1> <!-- start new code --> <p class="subtitle">with <span>0%</span> confidence</p> <!-- end new code --> <div class="buttons"> 在main之後但在body結束之前,添加一個新腳本predict.js 。
</main> <!-- start new code --> <script> require('../scripts/predict.js') </script> <!-- end new code --> </body> 保存並退出。 打開scripts/predict.js 。
nano scripts/predict.js為文件系統、實用程序和子進程生成器導入所需的 NodeJS 實用程序。
var fs = require('fs'); var utils = require('./utils'); const spawn = require("child_process").spawn; 定義一個predict函數,它調用一個單獨的節點進程來檢測 wifi 網絡和一個單獨的 Python 進程來預測房間。
function predict(completion) { const nodeProcess = spawn('node', ["scripts/observe.js"]); const pythonProcess = spawn('python', ["-W", "ignore", "./model/eval.py", "samples.json"]); }在兩個進程都生成後,向 Python 進程添加成功和錯誤的回調。 成功回調記錄信息,調用完成回調,並使用預測和置信度更新 UI。 錯誤回調記錄錯誤。
function predict(completion) { ... pythonProcess.stdout.on('data', (data) => { information = JSON.parse(data.toString()); console.log(" * [INFO] Room '" + information.category + "' with confidence '" + information.confidence + "'") completion() if (typeof document != "undefined") { document.querySelector('#predicted-room-name').innerHTML = information.category document.querySelector('#predicted-confidence').innerHTML = information.confidence } }); pythonProcess.stderr.on('data', (data) => { console.log(data.toString()); }) } 定義一個 main 函數來遞歸地調用predict函數,永遠。
function main() { f = function() { predict(f) } predict(f) } main();最後一次,打開桌面應用程序以查看實時預測。
npm start大約每秒完成一次掃描,界面將更新為最新的置信度和預測空間。 恭喜; 您已經完成了一個基於所有範圍內 WiFi 網絡的簡單房間探測器。
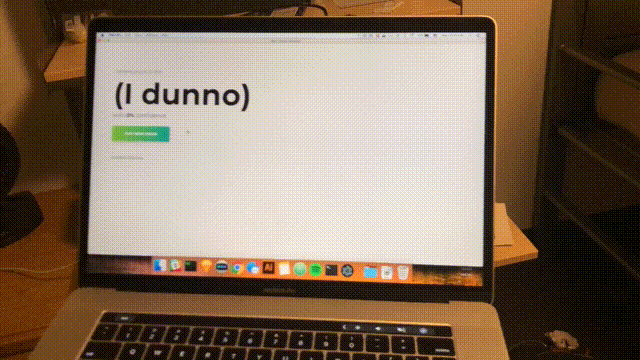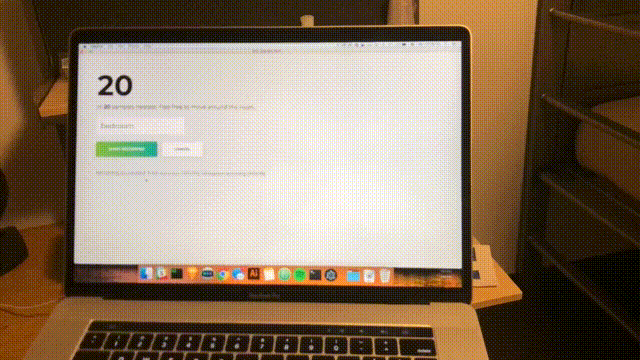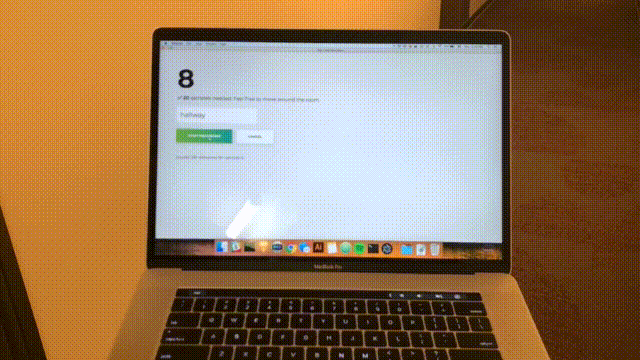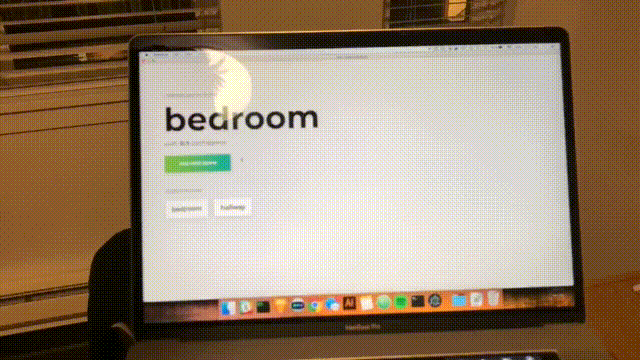
結論
在本教程中,我們創建了一個解決方案,僅使用您的桌面來檢測您在建築物中的位置。 我們使用 Electron JS 構建了一個簡單的桌面應用程序,並在所有範圍內的 WiFi 網絡上應用了一種簡單的機器學習方法。 這為物聯網應用鋪平了道路,無需維護成本高昂的設備陣列(成本不是金錢,而是時間和開發)。
注意:您可以在 Github 上查看完整的源代碼。
隨著時間的推移,您可能會發現這個最小二乘實際上並沒有表現出色。 嘗試在一個房間內找到兩個位置,或站在門口。 最小二乘將很大,無法區分邊緣情況。 我們能做得更好嗎? 事實證明,我們可以,並且在未來的課程中,我們將利用其他技術和機器學習的基礎知識來提高性能。 本教程可作為即將進行的實驗的快速測試平台。