
使用 FaunaDB、Netlify 和 11ty 創建書籤應用程序
已發表: 2022-03-10JAMstack(JavaScript、API 和標記)革命正在如火如荼地進行。 靜態站點是安全、快速、可靠且有趣的。 JAMstack 的核心是將數據存儲為平面文件的靜態站點生成器 (SSG):Markdown、YAML、JSON、HTML 等。 有時,以這種方式管理數據可能過於復雜。 有時,我們仍然需要一個數據庫。
考慮到這一點,Netlify(靜態站點主機)和 FaunaDB(無服務器雲數據庫)合作使這兩個系統的組合更容易。
為什麼是書籤網站?
JAMstack 非常適合許多專業用途,但我最喜歡這套技術的一個方面是它對個人工具和項目的進入門檻低。
對於我能想到的大多數應用程序,市場上有很多好的產品,但沒有一個適合我。 沒有人能讓我完全控制我的內容。 沒有成本(金錢或信息)。
考慮到這一點,我們可以使用 JAMstack 方法創建自己的迷你服務。 在這種情況下,我們將創建一個站點來存儲和發布我在日常技術閱讀中遇到的任何有趣的文章。
我花了很多時間閱讀在 Twitter 上分享的文章。 當我喜歡一個時,我會點擊“心”圖標。 然後,在幾天之內,隨著新寵的湧入,幾乎不可能找到。 我想建立一些接近“心”的輕鬆,但我擁有和控制的東西。
我們將如何做到這一點? 我很高興你問。
有興趣獲取代碼嗎? 您可以在 Github 上獲取它,或者直接從該存儲庫部署到 Netlify! 在這裡看看成品。
我們的技術
託管和無服務器功能:Netlify
對於託管和無服務器功能,我們將使用 Netlify。 作為額外的獎勵,通過上述新的合作,Netlify 的 CLI——“Netlify Dev”——將自動連接到 FaunaDB 並將我們的 API 密鑰存儲為環境變量。
數據庫:動物數據庫
FaunaDB 是一個“無服務器”NoSQL 數據庫。 我們將使用它來存儲我們的書籤數據。
靜態站點生成器:11ty
我是 HTML 的忠實信徒。 因此,本教程不會使用前端 JavaScript 來呈現我們的書籤。 相反,我們將使用 11ty 作為靜態站點生成器。 11ty 具有內置的數據功能,使從 API 獲取數據就像編寫幾個簡短的 JavaScript 函數一樣簡單。
iOS 快捷方式
我們需要一種簡單的方法將數據發佈到我們的數據庫中。 在這種情況下,我們將使用 iOS 的快捷方式應用程序。 這也可以轉換為 Android 或桌面 JavaScript 書籤。
通過 Netlify Dev 設置 FaunaDB
無論您已經註冊了 FaunaDB 還是需要創建一個新帳戶,在 FaunaDB 和 Netlify 之間建立鏈接的最簡單方法是通過 Netlify 的 CLI:Netlify Dev。 您可以在此處找到來自 FaunaDB 的完整說明或按照以下說明進行操作。
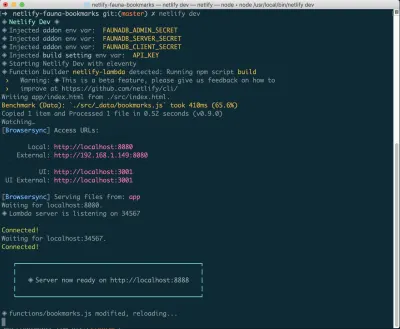
如果您還沒有安裝它,您可以在終端中運行以下命令:
npm install netlify-cli -g在您的項目目錄中,運行以下命令:
netlify init // This will connect your project to a Netlify project netlify addons:create fauna // This will install the FaunaDB "addon" netlify addons:auth fauna // This command will run you through connecting your account or setting up an account 一旦這一切都連接起來,你可以在你的項目中運行netlify dev 。 這將運行我們設置的任何構建腳本,但也會連接到 Netlify 和 FaunaDB 服務並獲取任何必要的環境變量。 便利!
創建我們的第一個數據
從這裡,我們將登錄 FaunaDB 並創建我們的第一個數據集。 我們將從創建一個名為“書籤”的新數據庫開始。 在數據庫中,我們有集合、文檔和索引。
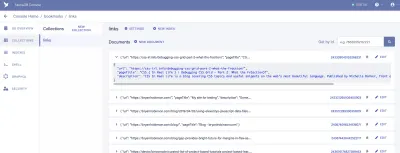
集合是分類的數據組。 每條數據都採用文檔的形式。 根據 Fauna 的文檔,文檔是“FaunaDB 數據庫中的單個、可更改的記錄”。 您可以將 Collections 視為傳統的數據庫表,將 Document 視為一行。
對於我們的應用程序,我們需要一個集合,我們將其稱為“鏈接”。 “鏈接”集合中的每個文檔都是一個簡單的 JSON 對象,具有三個屬性。 首先,我們將添加一個新文檔,我們將使用它來構建我們的第一個數據獲取。
{ "url": "https://css-irl.info/debugging-css-grid-part-2-what-the-fraction/", "pageTitle": "CSS { In Real Life } | Debugging CSS Grid – Part 2: What the Fr(action)?", "description": "CSS In Real Life is a blog covering CSS topics and useful snippets on the web's most beautiful language. Published by Michelle Barker, front end developer at Ordoo and CSS superfan." }這為我們需要從書籤中提取的信息奠定了基礎,並為我們提供了第一組數據以提取到我們的模板中。
如果你和我一樣,你想馬上看到你的勞動成果。 讓我們在頁面上獲取一些東西!
安裝 11ty 並將數據拉入模板
由於我們希望書籤以 HTML 格式呈現,而不是由瀏覽器獲取,因此我們需要一些東西來進行呈現。 有很多很棒的方法,但為了方便和強大,我喜歡使用 11ty 靜態站點生成器。
由於 11ty 是一個 JavaScript 靜態站點生成器,我們可以通過 NPM 安裝它。
npm install --save @11ty/eleventy 從那個安裝開始,我們可以在我們的項目中運行 11 或eleventy --serve eleventy啟動和運行。
Netlify Dev 通常會檢測到 11ty 作為需求並為我們運行命令。 為了完成這項工作 - 並確保我們已準備好部署,我們還可以在package.json中創建“serve”和“build”命令。
"scripts": { "build": "npx eleventy", "serve": "npx eleventy --serve" }11ty的數據文件
大多數靜態站點生成器都有內置“數據文件”的想法。 通常,這些文件是 JSON 或 YAML 文件,允許您向站點添加額外信息。
在 11ty 中,您可以使用 JSON 數據文件或 JavaScript 數據文件。 通過使用 JavaScript 文件,我們實際上可以進行 API 調用並將數據直接返回到模板中。
默認情況下,11ty 希望數據文件存儲在_data目錄中。 然後,您可以通過將文件名用作模板中的變量來訪問數據。 在我們的例子中,我們將在_data/bookmarks.js創建一個文件,並通過{{ bookmarks }}變量名訪問它。
如果您想更深入地研究數據文件配置,可以閱讀 11ty 文檔中的示例或查看本教程,了解如何使用 Meetup API 使用 11ty 數據文件。
該文件將是一個 JavaScript 模塊。 因此,為了讓任何事情發揮作用,我們需要導出我們的數據或函數。 在我們的例子中,我們將導出一個函數。
module.exports = async function() { const data = mapBookmarks(await getBookmarks()); return data.reverse() } 讓我們分解一下。 我們有兩個函數在這裡做我們的主要工作: mapBookmarks()和getBookmarks() 。
getBookmarks()函數將從我們的 FaunaDB 數據庫中獲取我們的數據,而mapBookmarks()將獲取一組書籤並對其進行重組以更好地為我們的模板工作。
讓我們深入研究getBookmarks() 。
getBookmarks()
首先,我們需要安裝並初始化 FaunaDB JavaScript 驅動程序的一個實例。
npm install --save faunadb現在我們已經安裝了它,讓我們將它添加到數據文件的頂部。 此代碼直接來自 Fauna 的文檔。
// Requires the Fauna module and sets up the query module, which we can use to create custom queries. const faunadb = require('faunadb'), q = faunadb.query; // Once required, we need a new instance with our secret var adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET }); 之後,我們就可以創建我們的函數了。 我們將從使用驅動程序的內置方法構建第一個查詢開始。 第一段代碼將返回數據庫引用,我們可以使用它來獲取所有帶書籤的鏈接的完整數據。 如果我們決定在將數據交給 11ty 之前對數據進行分頁,我們使用Paginate方法作為管理游標狀態的助手。 在我們的例子中,我們將只返回所有引用。
在此示例中,我假設您通過 Netlify Dev CLI 安裝並連接了 FaunaDB。 使用此過程,您可以獲得 FaunaDB 機密的本地環境變量。 如果您沒有以這種方式安裝它或者沒有在您的項目中運行netlify dev ,您將需要一個像dotenv這樣的包來創建環境變量。 您還需要將環境變量添加到您的 Netlify 站點配置中,以便稍後進行部署。
adminClient.query(q.Paginate( q.Match( // Match the reference below q.Ref("indexes/all_links") // Reference to match, in this case, our all_links index ) )) .then( response => { ... })此代碼將以引用形式返回我們所有鏈接的數組。 我們現在可以構建一個查詢列表以發送到我們的數據庫。
adminClient.query(...) .then((response) => { const linkRefs = response.data; // Get just the references for the links from the response const getAllLinksDataQuery = linkRefs.map((ref) => { return q.Get(ref) // Return a Get query based on the reference passed in }) return adminClient.query(getAllLinksDataQuery).then(ret => { return ret // Return an array of all the links with full data }) }).catch(...) 從這裡,我們只需要清理返回的數據。 這就是mapBookmarks()的用武之地!
mapBookmarks()
在這個函數中,我們處理數據的兩個方面。
首先,我們在 FaunaDB 中獲得了一個免費的 dateTime。 對於創建的任何數據,都有一個時間戳 ( ts ) 屬性。 它的格式沒有讓 Liquid 的默認日期過濾器滿意,所以讓我們修復它。
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); ... }) } 有了這個,我們可以為我們的數據構建一個新對象。 在這種情況下,它將有一個time屬性,我們將使用 Spread 運算符來解構我們的data對象,以使它們都生活在一個層次上。
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); return { time: dateTime, ...bookmark.data } }) }這是我們函數之前的數據:
{ ref: Ref(Collection("links"), "244778237839802888"), ts: 1569697568650000, data: { url: 'https://sample.com', pageTitle: 'Sample title', description: 'An escaped description goes here' } }這是我們函數後的數據:
{ time: 1569697568650, url: 'https://sample.com', pageTitle: 'Sample title' description: 'An escaped description goes here' }現在,我們已經為我們的模板準備了格式良好的數據!
讓我們寫一個簡單的模板。 我們將遍歷我們的書籤並驗證每個書籤都有一個pageTitle和一個url ,這樣我們就不會看起來很傻。

<div class="bookmarks"> {% for link in bookmarks %} {% if link.url and link.pageTitle %} // confirms there's both title AND url for safety <div class="bookmark"> <h2><a href="{{ link.url }}">{{ link.pageTitle }}</a></h2> <p>Saved on {{ link.time | date: "%b %d, %Y" }}</p> {% if link.description != "" %} <p>{{ link.description }}</p> {% endif %} </div> {% endif %} {% endfor %} </div>我們現在正在攝取和顯示來自 FaunaDB 的數據。 讓我們花點時間想一想,這渲染出純 HTML 並且無需在客戶端獲取數據是多麼美妙!
但這還不足以使它成為對我們有用的應用程序。 讓我們找出比在 FaunaDB 控制台中添加書籤更好的方法。
輸入 Netlify 函數
Netlify 的 Functions 插件是部署 AWS lambda 函數的更簡單方法之一。 由於沒有配置步驟,因此非常適合您只想編寫代碼的 DIY 項目。
該函數將位於您項目中的 URL 中,如下所示: https://myproject.com/.netlify/functions/bookmarks ://myproject.com/.netlify/functions/bookmarks 假設我們在函數文件夾中創建的文件是bookmarks.js 。
基本流程
- 將 URL 作為查詢參數傳遞給我們的函數 URL。
- 使用該函數加載 URL 並抓取頁面的標題和描述(如果可用)。
- 格式化 FaunaDB 的詳細信息。
- 將詳細信息推送到我們的 FaunaDB 集合。
- 重建網站。
要求
在構建它時,我們需要一些包。 我們將使用 netlify-lambda CLI 在本地構建我們的函數。 request-promise是我們將用於發出請求的包。 Cheerio.js 是我們用來從我們請求的頁面中抓取特定項目的包(想想 jQuery for Node)。 最後,我們需要 FaunaDb(應該已經安裝好了。
npm install --save netlify-lambda request-promise cheerio安裝完成後,讓我們配置我們的項目以在本地構建和提供功能。
我們將在package.json中修改“build”和“serve”腳本,如下所示:
"scripts": { "build": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy", "serve": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy --serve" } 警告:當使用 Netlify 的 Functions 構建的 Webpack 編譯時,Fauna 的 NodeJS 驅動程序出錯。 為了解決這個問題,我們需要為 Webpack 定義一個配置文件。 您可以將以下代碼保存到新的或現有的webpack.config.js中。
const webpack = require('webpack'); module.exports = { plugins: [ new webpack.DefinePlugin({ "global.GENTLY": false }) ] }; 一旦這個文件存在,當我們使用netlify-lambda命令時,我們需要告訴它從這個配置運行。 這就是我們的“服務”和“構建腳本”使用該命令的--config值的原因。
功能管家
為了使我們的主函數文件盡可能乾淨,我們將在一個單獨的bookmarks目錄中創建我們的函數並將它們導入到我們的主函數文件中。
import { getDetails, saveBookmark } from "./bookmarks/create"; getDetails(url)
getDetails()函數將獲取一個 URL,從我們導出的處理程序傳入。 從那裡,我們將通過該 URL 訪問該站點並獲取頁面的相關部分以存儲為我們書籤的數據。
我們首先需要我們需要的 NPM 包:
const rp = require('request-promise'); const cheerio = require('cheerio'); 然後,我們將使用request-promise模塊為所請求的頁面返回一個 HTML 字符串,並將其傳遞給cheerio ,從而為我們提供一個非常 jQuery 式的界面。
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); ... }從這裡,我們需要獲取頁面標題和元描述。 為此,我們將像在 jQuery 中一樣使用選擇器。
注意:在這段代碼中,我們使用'head > title'作為選擇器來獲取頁面的標題。 如果您不指定這一點,您最終可能會在頁面上的所有 SVG 中獲得<title>標籤,這不太理想。
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); const title = $('head > title').text(); // Get the text inside the tag const description = $('meta[name="description"]').attr('content'); // Get the text of the content attribute // Return out the data in the structure we expect return { pageTitle: title, description: description }; }); return data //return to our main function }有了數據,是時候將我們的書籤發送到我們在 FaunaDB 中的集合了!
saveBookmark(details)
對於我們的保存函數,我們希望將從getDetails獲取的詳細信息以及 URL 作為單個對像傳遞。 Spread 運算符再次來襲!
const savedResponse = await saveBookmark({url, ...details}); 在我們的create.js文件中,我們還需要要求並設置我們的 FaunaDB 驅動程序。 這在我們的 11ty 數據文件中應該看起來很熟悉。
const faunadb = require('faunadb'), q = faunadb.query; const adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET });一旦我們解決了這個問題,我們就可以編碼了。
首先,我們需要將我們的詳細信息格式化為 Fauna 期望我們查詢的數據結構。 Fauna 需要一個具有數據屬性的對象,該屬性包含我們希望存儲的數據。
const saveBookmark = async function(details) { const data = { data: details }; ... }然後我們將打開一個新查詢以添加到我們的集合中。 在這種情況下,我們將使用查詢助手並使用 Create 方法。 Create() 接受兩個參數。 第一個是我們要存儲數據的集合,第二個是數據本身。
保存後,我們將成功或失敗返回給我們的處理程序。
const saveBookmark = async function(details) { const data = { data: details }; return adminClient.query(q.Create(q.Collection("links"), data)) .then((response) => { /* Success! return the response with statusCode 200 */ return { statusCode: 200, body: JSON.stringify(response) } }).catch((error) => { /* Error! return the error with statusCode 400 */ return { statusCode: 400, body: JSON.stringify(error) } }) }讓我們看一下完整的函數文件。
import { getDetails, saveBookmark } from "./bookmarks/create"; import { rebuildSite } from "./utilities/rebuild"; // For rebuilding the site (more on that in a minute) exports.handler = async function(event, context) { try { const url = event.queryStringParameters.url; // Grab the URL const details = await getDetails(url); // Get the details of the page const savedResponse = await saveBookmark({url, ...details}); //Save the URL and the details to Fauna if (savedResponse.statusCode === 200) { // If successful, return success and trigger a Netlify build await rebuildSite(); return { statusCode: 200, body: savedResponse.body } } else { return savedResponse //or else return the error } } catch (err) { return { statusCode: 500, body: `Error: ${err}` }; } }; rebuildSite()
明眼人會注意到我們在處理程序中又導入了一個函數: rebuildSite() 。 每次我們提交一個新的——成功的——書籤保存時,這個函數將使用 Netlify 的 Deploy Hook 功能從新數據重建我們的站點。
在 Netlify 的站點設置中,您可以訪問 Build & Deploy 設置並創建一個新的“Build Hook”。 Hooks 的名稱顯示在 Deploy 部分,如果您願意,可以選擇部署非 master 分支。 在我們的例子中,我們將其命名為“new_link”並部署我們的主分支。
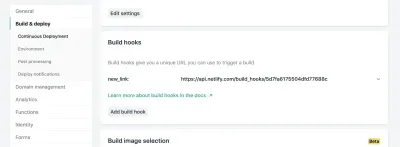
從那裡,我們只需要向提供的 URL 發送一個 POST 請求。
我們需要一種發出請求的方式,並且由於我們已經安裝了request-promise ,我們將通過在文件頂部要求它來繼續使用該包。
const rp = require('request-promise'); const rebuildSite = async function() { var options = { method: 'POST', uri: 'https://api.netlify.com/build_hooks/5d7fa6175504dfd43377688c', body: {}, json: true }; const returned = await rp(options).then(function(res) { console.log('Successfully hit webhook', res); }).catch(function(err) { console.log('Error:', err); }); return returned } 設置 iOS 快捷方式
所以,我們有一個數據庫,一個顯示數據的方法和一個添加數據的函數,但我們仍然不是很友好。
Netlify 為我們的 Lambda 函數提供 URL,但在移動設備中輸入它們並不有趣。 我們還必須將 URL 作為查詢參數傳遞給它。 這是一個很大的努力。 我們怎樣才能盡可能少地做這件事呢?
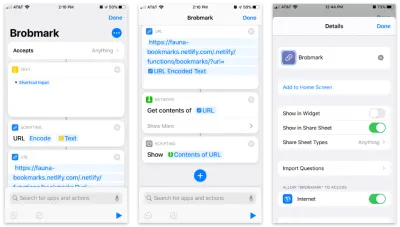
Apple 的 Shortcuts 應用程序允許將自定義項目構建到您的共享表中。 在這些快捷方式中,我們可以發送各種類型的共享過程中收集的數據請求。
這是一步一步的快捷方式:
- 接受任何項目並將該項目存儲在“文本”塊中。
- 將該文本傳遞到“腳本”塊中以進行 URL 編碼(以防萬一)。
- 使用我們的 Netlify 函數的 URL 和
url的查詢參數將該字符串傳遞到 URL 塊中。 - 從“網絡”使用“獲取內容”塊將 JSON POST 到我們的 URL。
- 可選:從“腳本”“顯示”最後一步的內容(以確認我們發送的數據)。
要從共享菜單訪問它,我們打開此快捷方式的設置並切換“在共享表中顯示”選項。
從 iOS13 開始,這些共享“動作”可以被收藏並移動到對話框中的較高位置。
我們現在有了一個可以在多個平台上共享書籤的工作“應用程序”!
多走一英里!
如果您受到啟發自己嘗試這個,還有很多其他的可能性來添加功能。 DIY 網絡的樂趣在於您可以讓這些類型的應用程序為您工作。 這裡有一些想法:
- 使用虛假的“API 密鑰”進行快速身份驗證,這樣其他用戶就不會發佈到您的網站(我的使用 API 密鑰,所以不要嘗試發佈到它!)。
- 添加標籤功能來組織書籤。
- 為您的站點添加 RSS 提要,以便其他人可以訂閱。
- 以編程方式為您添加的鏈接發送每週摘要電子郵件。
真的,天空是極限,所以開始嘗試吧!