
用示例解釋貝葉斯定理 – 完整指南
已發表: 2021-06-14目錄
介紹
什麼是貝葉斯定理?
貝葉斯定理用於計算直覺經常失敗的條件概率。 儘管在概率中被廣泛使用,但該定理也被應用於機器學習領域。 它在機器學習中的使用包括將模型擬合到訓練數據集和開發分類模型。
什麼是條件概率?
條件概率通常定義為在給定另一事件發生的情況下一個事件的概率。
- 如果 A 和 B 是兩個事件,則條件概率 me 被指定為 P(A given B) 或 P(A|B)。
- 條件概率可以由聯合概率(A | B) = P(A, B) / P(B) 計算
- 條件概率不對稱; 例如 P(A | B) != P(B | A)
計算條件概率的其他方法包括使用其他條件概率,即
P(A|B) = P(B|A) * P(A) / P(B)
也使用反向
P(B|A) = P(A|B) * P(B) / P(A)

當難以計算聯合概率時,這種計算方式很有用。 否則,當反向條件概率可用時,通過它進行計算變得容易。
這種條件概率的替代計算稱為貝葉斯規則或貝葉斯定理。 它以第一個描述它的人的名字命名,“托馬斯·貝葉斯牧師”。
貝葉斯定理公式
貝葉斯定理是一種在聯合概率不可用時計算條件概率的方法。 有時,不能直接訪問分母。 在這種情況下,另一種計算方法如下:
P(B) = P(B|A) * P(A) + P(B|非 A) * P(非 A)
這是貝葉斯定理的公式,它顯示了 P(B) 的替代計算。
P(A|B) = P(B|A) * P(A) / P(B|A) * P(A) + P(B|非 A) * P(非 A)
上面的公式可以用分母括起來的括號來描述
P(A|B) = P(B|A) * P(A) / (P(B|A) * P(A) + P(B|非 A) * P(非 A))
此外,如果我們有 P(A),那麼 P(not A) 可以計算為
P(不是 A) = 1 – P(A)
類似地,如果我們有 P(not B|not A),那麼 P(B|not A) 可以計算為
P(B|非 A) = 1 – P(非 B|非 A)
條件概率的貝葉斯定理
貝葉斯定理由幾個術語組成,其名稱是根據其在方程中的應用上下文給出的。
後驗概率是指P(A|B)的結果,先驗概率是指P(A)的結果。
- P(A|B):後驗概率。
- P(A):先驗概率。
類似地,P(B|A) 和 P(B) 被稱為可能性和證據。
- P(B|A):可能性。
- P(B):證據。
因此,條件概率的貝葉斯定理可以重新表述為:
後驗=可能性*先驗/證據
如果我們必須在有煙的情況下計算發生火災的概率,那麼將使用以下等式:
P(火|煙) = P(煙|火) * P(火) / P(煙)
其中,P(Fire) 是先驗,P(Smoke|Fire) 是可能性,P(Smoke) 是證據。
貝葉斯定理的說明
描述了貝葉斯定理示例以說明貝葉斯定理在問題中的使用。
問題
存在三個標記為 A、B 和 C 的框。 盒子的詳細信息是:
- 盒子 A 包含 2 個紅球和 3 個黑球
- 盒子 B 包含 3 個紅球和 1 個黑球
- 盒子 C 包含 1 個紅球和 4 個黑球
所有三個盒子都是相同的,被拾取的概率相等。 因此,從盒子 A 中撿到紅球的概率是多少?
解決方案
令 E 表示撿起紅球的事件,而 A、B 和 C 表示從各自的盒子中撿起球。 因此,條件概率將是需要計算的 P(A|E)。
現有概率 P(A) = P(B) = P (C) = 1 / 3,因為所有盒子被選中的概率相等。
P(E|A) = 盒子 A 中的紅球數 / 盒子 A 中的球總數 = 2 / 5
同樣,P(E|B) = 3 / 4 和 P(E|C) = 1 / 5
那麼證據 P(E) = P(E|A)*P(A) + P(E|B)*P(B) + P(E|C)*P(C)
= (2/5) * (1/3) + (3/4) * (1/3) + (1/5) * (1/3) = 0.45
因此,P(A|E) = P(E|A) * P(A) / P(E) = (2/5) * (1/3) / 0.45 = 0.296
貝葉斯定理的例子
貝葉斯定理給出了“事件”與“測試”的給定信息的概率。
- “事件”和“測試”是有區別的。 例如,有一項針對肝病的測試,這與實際患有肝病不同,即一個事件。
- 罕見事件可能具有更高的誤報率。
示例 1
如果患者酗酒,患肝病的概率是多少?
在這裡,“酗酒”是肝病的“測試”(試金石的類型)。
- A是事件,即“患者患有肝病”。
根據該診所早期的記錄,它指出進入診所的患者中有10%患有肝病。
因此,P(A)=0.10
- B 是“患者是酒鬼”的試金石。
該診所早前的記錄顯示,進入診所的患者中有 5% 是酗酒者。
因此,P(B)=0.05
- 此外,在被診斷患有肝病的患者中,有 7% 是酗酒者。 這定義了 B|A:考慮到患者患有肝病,患者酗酒的概率為 7%。
根據貝葉斯定理公式,
P(A|B) = (0.07 * 0.1)/0.05 = 0.14
因此,對於酗酒的患者,患肝病的機率為 0.14 (14%)。
示例 2
- 危險火災很少見(1%)
- 但由於燒烤,煙霧相當普遍(10%),
- 90% 的危險火災會產生煙霧
有煙霧時發生危險火災的概率是多少?
計算
P(火|煙) =P(火) P(煙|火)/P(煙)

= 1% x 90%/10%
= 9%
示例 3
白天下雨的可能性有多大? 其中,Rain 表示白天下雨,Cloud 表示多雲的早晨。
給定 Cloud 下雨的機會寫成 P(Rain|Cloud)
P(雨|雲) = P(雨) P(雲|雨)/P(雲)
P(Rain) 是下雨的概率 = 10%
P(Cloud|Rain) 是雲的概率,假設下雨發生 = 50%
P(Cloud) 是 Cloud 的概率 = 40%
P(雨|雲)= 0.1 x 0.5/0.4 = .125
因此,有 12.5% 的機率下雨。
應用
貝葉斯定理的幾種應用存在於現實世界中。 該定理的幾個主要應用是:
1. 建模假設
貝葉斯定理在應用機器學習中得到了廣泛的應用,並建立了數據和模型之間的關係。 應用機器學習使用對給定數據集的不同假設進行測試和分析的過程。
為了描述數據和模型之間的關係,貝葉斯定理提供了一個概率模型。
P(h|D) = P(D|h) * P(h) / P(D)
在哪裡,
P(h|D):假設的後驗概率
P(h):假設的先驗概率。
P(D) 的增加會降低 P(h|D)。 相反,如果 P(h) 和給定假設觀察數據的概率增加,則 P(h|D) 的概率增加。
2.貝葉斯分類定理
分類方法涉及給定數據的標記。 它可以定義為給定數據樣本的類標籤的條件概率的計算。
P(類|數據) = (P(數據|類) * P(類)) / P(數據)
其中 P(class|data) 是給定數據的類別概率。
可以對每一類進行計算。 可以將具有最大概率的類分配給輸入數據。
在樣本數量較少的情況下,條件概率的計算是不可行的。 因此,貝葉斯定理的直接應用是不可行的。 分類模型的解決方案在於簡化計算。
樸素貝葉斯分類器
貝葉斯定理認為輸入變量依賴於其他變量,導致計算複雜。 因此,假設被刪除,每個輸入變量都被視為一個自變量。 結果,模型從依賴條件概率模型變為獨立條件概率模型。 它最終降低了複雜性。
貝葉斯定理的這種簡化稱為樸素貝葉斯。 它廣泛用於分類和預測模型。
貝葉斯最優分類器
這是一種概率模型,涉及在給定訓練數據集的情況下預測新示例。 貝葉斯最優分類器的一個例子是“給定訓練數據,新實例最可能的分類是什麼?”
在給定訓練數據的情況下計算新實例的條件概率可以通過以下等式完成
P(vj | D) = sum {h in H} P(vj | hi) * P(hi | D)
其中 vj 是要分類的新實例,
H 是用於對實例進行分類的假設集,
hi 是一個給定的假設,
P(vj | hi) 是給定假設 hi 的 vi 的後驗概率,並且
P(hi | D) 是給定數據 D 的假設 hi 的後驗概率。
3. 貝葉斯定理在機器學習中的應用
貝葉斯定理在機器學習中最常見的應用是分類問題的發展。 其他應用而不是分類包括優化和臨時模型。
貝葉斯優化
找到導致給定目標函數的最小或最大成本的輸入始終是一項具有挑戰性的任務。 貝葉斯優化基於貝葉斯定理,為搜索全局優化問題提供了一個方面。 該方法包括建立一個概率模型(代理函數),通過一個採集函數進行搜索,以及選擇用於評估真實目標函數的候選樣本。
在應用機器學習中,貝葉斯優化用於調整性能良好的模型的超參數。
貝葉斯信念網絡
變量之間的關係可以通過使用概率模型來定義。 它們也用於概率的計算。 由於大量數據,完全條件概率模型可能無法計算概率。 樸素貝葉斯簡化了計算方法。 還存在另一種方法,其中基於隨機變量之間的已知條件依賴性和其他情況下的條件獨立性開發模型。 貝葉斯網絡通過有向邊的概率圖模型展示了這種依賴性和獨立性。 已知的條件相關性顯示為有向邊,缺失的連接表示模型中的條件獨立性。
4.貝葉斯垃圾郵件過濾
垃圾郵件過濾是貝葉斯定理的另一個應用。 存在兩個事件:
- 事件 A:郵件是垃圾郵件。
- 測試 X:消息包含某些單詞 (X)
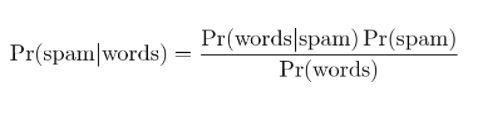
通過應用貝葉斯定理,可以根據“測試結果”來預測郵件是否為垃圾郵件。 分析郵件中的單詞可以計算成為垃圾郵件的機會。 通過使用重複消息訓練過濾器,它更新了消息中包含某些單詞的概率是垃圾郵件的事實。
貝葉斯定理的應用舉例
催化劑生產商生產一種用於測試某種電催化劑 (EC) 缺陷的裝置。 這家催化劑生產商聲稱,如果 EC 有缺陷,則該測試的可靠性為 97%,如果無缺陷,則該測試的可靠性為 99%。 但是,預計 4% 的上述 EC 在交付時會出現缺陷。 應用貝葉斯規則來確定設備的真實可靠性。 基本事件集是
A:EC有缺陷; A':EC完美無瑕; B:EC檢測有缺陷; B':EC經測試無瑕疵。
概率是
B/A:EC 是(已知)有缺陷的,並且測試有缺陷,P(B/A) = 0.97,
B'/A:EC(已知)有缺陷,但測試無缺陷,P(B'/A)=1-P(B/A)=0.03,
B/A':EC(已知)有缺陷,但經測試有缺陷,P(B/A') = 1- P(B'/A')=0.01
B'/A: = EC (已知)完美無瑕,經測試完美無瑕 P(B'/A') = 0.99
貝葉斯定理計算的概率為:

計算的概率表明,拒絕無缺陷 EC 的可能性很高(約 20%),而識別有缺陷的 EC 的可能性很低(約 80%)。
結論
貝葉斯定理最顯著的特點之一是,從幾個概率比中,可以獲得大量的信息。 通過似然法,先驗事件的概率可以轉換為後驗概率。 貝葉斯定理的方法可以應用於統計、認識論和歸納邏輯領域。
如果您有興趣了解有關貝葉斯定理、人工智能和機器學習的更多信息,請查看 IIIT-B 和 upGrad 的機器學習和人工智能執行 PG 計劃,該計劃專為工作專業人士設計,提供 450 多個小時的嚴格培訓,30 多個案例學習和作業、IIIT-B 校友身份、5 個以上實用的實踐頂點項目和頂級公司的工作協助。
機器學習的假設是什麼?
從最廣泛的意義上說,假設是要測試的任何想法或命題。 假設是一種猜測。 機器學習是一門理解數據的科學,尤其是對人類來說過於復雜且通常具有看似隨機的特徵的數據。 當使用機器學習時,假設是機器用來分析特定數據集並尋找可以幫助我們做出預測或決策的模式的一組指令。 使用機器學習,我們能夠在算法的幫助下做出預測或決策。
機器學習中最普遍的假設是什麼?
機器學習中最普遍的假設是沒有對數據的理解。 符號和模型只是該數據的表示,而該數據是一個複雜的系統。 因此,不可能對數據有一個完整和一般的了解。 了解有關數據的任何信息的唯一方法是使用它並查看預測如何隨數據變化。 一般假設是,模型僅在它們被創建用於工作的領域中有用,並且對現實世界的現像沒有普遍的應用。 一般假設是數據是唯一的,並且每個問題的學習過程都是唯一的。
為什麼假設必須是可測量的?
當一個數字可以分配給定性或定量變量時,假設是可測量的。 這可以通過觀察或進行實驗來完成。 例如,如果推銷員試圖銷售產品,則假設是將產品銷售給客戶。 如果銷售數量是在一天或一周內衡量的,那麼這個假設是可衡量的。