
Apache Kafka 架構:初學者綜合指南 [2022]
已發表: 2021-12-23在我們深入研究 Apache Kafka 架構的細節之前,有必要先弄清楚為什麼 Kafka 會成為頭條新聞。 首先,Apache Kafka 主要用於實時流數據架構,以提供實時分析。 Kafka 的發布-訂閱消息系統持久、快速、可擴展和容錯,具有跟踪 IoT 傳感器數據或跟踪服務調用等用例。
LinkedIn、Netflix、Microsoft、Uber、Spotify、Goldman Sachs、Cisco、PayPal 等許多公司都使用 Apache Kafka 來處理實時流數據。 例如,Kafka 的起源地 LinkedIn 使用它來跟踪運營指標和活動數據。 同樣,對於 Netflix,Apache Kafka 是其消息傳遞、事件和流處理需求的事實標準。
從世界頂級大學學習在線軟件開發培訓。 獲得行政 PG 課程、高級證書課程或碩士課程,以加快您的職業生涯。
通過了解 Apache Kafka 架構及其底層組件,可以更好地了解 Apache Kafka 的實用性。 那麼,讓我們來探索一下 Kafka 架構的細節。
目錄
基本的 Kafka 架構概念
以下概念是理解 Apache Kafka 架構的基礎:
一、話題
Kafka 主題定義了數據流式傳輸的通道。 因此,生產者向主題發布消息,消費者從他們訂閱的主題中讀取消息。 Kafka 集群中創建的主題數量沒有限制,每個主題都有一個唯一的名稱標識。

2. 經紀人
Brokers 是 Kafka 集群中的服務器,它們作為容器工作並保存具有不同分區的多個主題。 唯一的整數 ID 標識 Kafka 集群中的代理,與這些代理中的任何一個連接意味著與整個集群連接。
3. 分區
Kafka 主題分為許多稱為分區的部分。 分區按順序分開,允許多個消費者並行讀取特定主題的數據。 一個主題的分區分佈在 Kafka 集群中的多個服務器上,每個服務器管理其大量分區的數據和請求。 消息到達代理和密鑰,密鑰確定特定消息將到達的分區。 因此,具有相同鍵的消息會進入同一個分區。 如果未指定密鑰,則按照循環方法確定分區。
4. 複製品
在 Kafka 中,副本就像分區備份,以確保在計劃關閉或故障的情況下不會丟失數據。 換句話說,副本是分區的副本。
5. 分區偏移
由於 Kafka 中的消息或記錄被分配給分區,因此每個記錄都提供了一個偏移量來指定其在分區中的位置。 因此,與記錄關聯的偏移值有助於在分區內輕鬆識別它。 分區偏移量僅在該特定分區內有意義,並且由於將記錄添加到分區末端,因此較舊的記錄將具有較低的偏移量值。
6. 生產者
Kafka 生產者向一個或多個主題發布消息,並將數據發送到 Kafka 集群。 一旦生產者向 Kafka 主題發布消息,代理就會收到消息並將其添加到特定分區。 然後,生產者可以選擇他們想要發布消息的分區。
7. 消費者和消費者群體
消費者從 Kafka 集群中讀取消息。 當消費者準備好接收消息時,將從代理中提取數據。 消費者屬於一個消費者組,特定組中的每個消費者負責讀取其訂閱的每個主題的分區子集。
8. 領導者和追隨者
每個 Kafka 分區都有一台服務器扮演領導者的角色。 領導者執行該特定分區的所有讀寫任務。 另一方面,追隨者的工作是複制領導者的數據。 當特定分區中的領導者出現故障時,其中一個跟隨者節點將承擔領導者的角色。 一個分區可以沒有或有很多追隨者。
下圖是上述 Apache Kafka 架構組件之間相互關係的簡化表示。
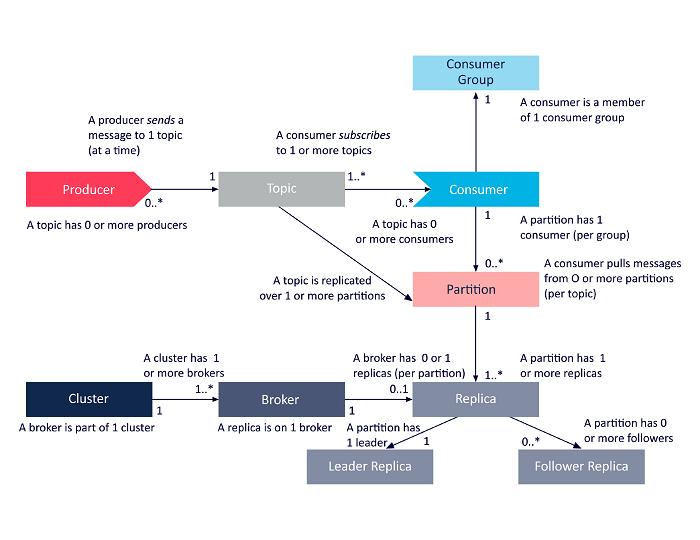

資源
Apache Kafka 集群架構
以下是 Kafka 主要架構組件的詳細介紹:
1. 卡夫卡經紀人
Kafka 集群通常包含多個稱為代理的節點。 代理保持負載平衡。 每個 Kafka 代理每秒可以處理成百上千的讀寫操作。 代理充當一個特定分區的領導者。 領導者有一個或多個追隨者,領導者上的數據在該特定分區的追隨者之間複製。
追隨者需要隨時了解領導者的數據。 反過來,領導者會跟踪與其同步的追隨者。 如果追隨者沒有趕上領導者或不再活動,則將其從與特定領導者關聯的同步副本列表中刪除。 領導者死亡後,從追隨者中選出新的領導者,並由 ZooKeeper 監督選舉。 由於代理是無狀態的,ZooKeeper 維護其集群狀態。 集群中的節點向 ZooKeeper 發送心跳消息,通知後者它們還活著。
2. 卡夫卡生產者
Kafka 生產者直接將數據發送到充當特定分區領導者角色的代理。 Kafka 集群的代理或節點幫助生產者發送直接消息。 他們通過回答對哪些服務器處於活動狀態的元數據請求以及主題的分區領導者的活動狀態的請求來做到這一點,從而使生產者能夠相應地指導其請求。 生產者決定它想要發布消息的分區。 Kafka 中的消息是分批發送的,稱為記錄批。 生產者在內存中收集消息,並在經過固定時間或累積一定數量的消息後分批發送。
3. 卡夫卡消費者
Kafka 消費者向代理髮出請求,表示它想要使用的分區。 消費者在其請求中指定分區偏移量,並從代理接收一條日誌(從偏移位置開始)。 日誌包含可配置期間(稱為保留期)的記錄。
只要日誌包含數據,消費者也可以重新消費數據。 Kafka 消費者採用基於拉取的方法,這意味著代理不會立即將數據推送給消費者。 相反,首先,消費者向代理髮送請求,表明他們已準備好使用數據。 因此,基於拉取的系統確保消費者不會被消息淹沒,並且在他們落後時能夠趕上。
以下是簡化的 Apache Kafka 架構圖:
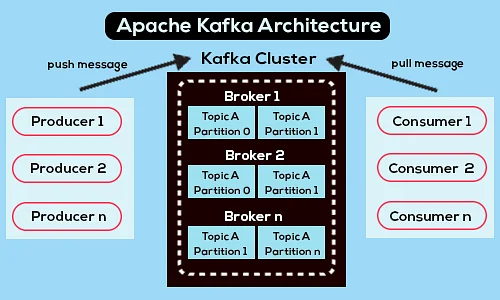
資源
了解有關 Apache Kafka 的更多信息。
Apache Kafka API 架構
Apache Kafka 有四個關鍵 API——Streams API、Connector API、Producer API 和 Consumer API。 讓我們看看每個人在增強 Apache Kafka 的功能方面都扮演了什麼角色:
1. 流 API
Kafka 的 Streams API 允許應用程序使用流處理算法來處理數據。 使用 Streams API,應用程序可以使用來自一個或多個主題的輸入流,使用流操作處理它們,生成輸出流,並最終將它們發送到一個或多個主題。 因此,Streams API 有助於將輸入流轉換為輸出流。
2. 連接器 API
Kafka 的連接器 API 有助於構建、運行和管理將 Kafka 主題連接到現有數據系統或應用程序的可重用生產者和消費者。 例如,關係數據庫的連接器可以捕獲所有更新,並確保更改在 Kafka 主題中可用。

3.生產者API
Kafka 的 Producer API 允許應用程序將記錄流發佈到 Kafka 主題。
4.消費者API
Kafka 的 Consumer API 允許應用訂閱 Kafka 主題。 它還使應用程序能夠處理為這些 Kafka 主題生成的記錄流。
前進之路
Apache Kafka 架構只是軟件開發人員處理的大量工具和語言的一小部分。 假設您是一名初出茅廬的軟件開發人員,傾向於大數據。 在這種情況下,您可以通過upGrad 的軟件開發執行 PG 計劃——大數據專業化邁出實現目標的第一步。
以下是該計劃的概述,其中包含一些關鍵亮點:
- 來自 IIIT Bangalore 的執行 PGP,擁有數據科學和雲基礎設施方面的認證
- 內容超過 400 小時的在線課程和現場講座
- 7+ 案例研究和項目
- 14+ 種編程語言和工具
- 360 度的職業支持
- 同行和行業網絡
註冊以獲取更多詳細信息 關於課程!
卡夫卡是乾什麼用的?
Apache Kafka 主要用於構建實時流數據管道和適應這些數據流的應用程序。 它允許通過消息傳遞、存儲和流處理的組合來存儲和分析實時和歷史數據。
卡夫卡是一個框架嗎?
Apache Kafka 是一個開源軟件,它提供了一個用於存儲、讀取和分析流數據的框架。 由於它是開源的,因此許多開發人員和用戶可以免費使用 Kafka,為新功能、更新和對新用戶的支持做出貢獻。
為什麼我們需要 Kafka 流?
Kafka Streams 是一個客戶端庫,用於構建微服務和流應用程序,其中輸入數據和輸出數據存儲在 Apache Kafka 集群中。 一方面,它提供了 Apache Kafka 的服務器端集群技術的優勢。 另一方面,它簡化了在客戶端編寫和部署標準 Scala 和 Java 應用程序。