
Apache Kafka:架構、概念、特性和應用
已發表: 2021-03-09Kafka 於 2011 年推出,這一切都歸功於 LinkedIn。 從那時起,它見證了令人難以置信的增長,以至於現在大多數財富 500 強企業都在使用它。 它是一種高度可擴展、耐用和高吞吐量的產品,可以處理大量流數據。 但這就是它如此受歡迎的唯一原因嗎? 嗯,不。 我們甚至還沒有開始了解它的功能、它產生的質量以及它為用戶提供的易用性。
我們稍後會深入探討。 我們先來了解一下Kafka是什麼,用在什麼地方。
目錄
什麼是阿帕奇卡夫卡?
Apache Kafka 是一種開源流處理軟件,旨在在管理實時數據的同時提供高吞吐量和低延遲。 Kafka 用 Java 和 Scala 編寫,通過內存中的微服務提供持久性,並在維護複雜事件流服務(也稱為 CEP 或自動化系統)的供應事件方面發揮著不可或缺的作用。
它是一個非常通用的、防故障的分佈式系統,使優步等公司能夠管理乘客和司機的匹配。 除了幫助 LinkedIn 跟踪多項實時服務外,它還為 British Gas 的智能家居產品提供實時數據和主動維護。
Kafka 經常用於實時流數據架構以提供實時分析,是一個快速、堅固、可擴展和發布-訂閱的消息傳遞系統。 Apache Kafka 可以用作傳統 MOM 的替代品,因為它具有出色的兼容性和靈活的架構,可以跟踪服務調用或 IoT 傳感器數據。
Kafka 與 Apache Flume/Flafka、Apache Spark Streaming、Apache Storm、HBase、Apache Flink 和 Apache Spark 完美配合,用於實時攝取、研究、分析和處理流數據。 Kafka 中介還促進了 Hadoop 或 Spark 中的低延遲後續報告。 Kafka 還有一個名為 Kafka Stream 的子項目,它是一種有效的實時分析工具。

Kafka 架構和組件
Kafka 用於將實時數據流式傳輸到多個接收系統。 Kafka 作為解耦實時數據管道的中心層。 它在直接計算中沒有多大用處。 它與基於實時或操作數據的快速通道進料系統最兼容,可以流式傳輸大量數據以進行批量數據分析。
Storm、Flink、Spark 和 CEP 框架是 Kafka 用來完成實時分析、創建備份、審計等的一些數據系統。 它還可以與大數據平台或數據庫系統(如 RDBMS、Cassandra、Spark 等)集成,用於數據科學處理、報告等。
下圖說明了 Kafka 生態系統:
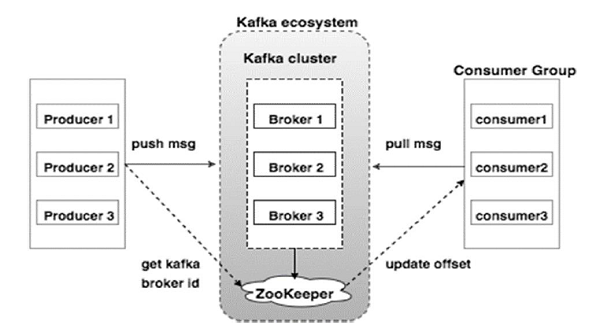
資源
以下是 Kafka 生態系統的各種組件,如 Kafka 架構圖所示:
1. 卡夫卡經紀人
Kafka 模擬一個包含多個服務器的集群,每個服務器都稱為“代理”。 客戶端和服務器之間的任何通信都遵循高性能 TCP 協議。 它包含一個以上的無狀態代理來處理繁重的負載。 單個 Kafka 代理能夠在不影響性能的情況下每秒管理數次讀取和寫入。 他們使用 ZooKeeper 來維護集群並選舉代理領導者。
2. 卡夫卡動物園管理員
如上所述,ZooKeeper 負責管理 Kafka 代理。 Kafka 生態系統中代理的任何新添加或故障都會通過 ZooKeeper 通知生產者或消費者。

3. 卡夫卡生產者
他們負責向經紀人發送數據。 生產者不依賴代理來確認收到消息。 相反,他們確定代理可以相應地處理和發送多少消息。
4. 卡夫卡消費者
Kafka 消費者有責任記錄分區偏移量消費的消息數量。 確認消息表示在消息被消費之前發送的消息。 為了確保代理有準備好發送給消費者的字節緩衝區,消費者發起一個異步拉取請求。 ZooKeeper 在維護跳過或倒帶消息的偏移值方面發揮著作用。
Kafka 的機制涉及在分佈式系統中的應用程序之間發送消息。 Kafka 使用提交日誌,當訂閱該日誌時,它會將存在的數據發佈到各種流應用程序。 發送者向 Kafka 發送消息,而接收者從 Kafka 分發的流中接收消息。
消息被組裝成主題——Kafka 的有效審議。 給定的主題表示基於特定類型或分類的有組織的數據流。 生產者根據主題編寫消息供消費者閱讀。
每個主題都有一個唯一的名稱。 發件人發送的來自給定主題的任何消息都會被所有正在收聽該主題的用戶接收。 一旦發布,主題中的數據將無法更新或修改。
卡夫卡的特點
- Kafka 包含一個永久提交日誌,允許您訂閱它,然後將數據發佈到多個系統或實時應用程序。
- 它使應用程序能夠在數據到來時對其進行控制。 Apache Kafka 中的 Streams API 是一個功能強大的輕量級庫,可促進動態批處理數據處理。
- 它是一個 Java 應用程序,可讓您調節工作流程並顯著減少任何維護需求。
- Kafka 充當“事實存儲”,通過支持通過多個數據系統進行數據部署,將數據分發到多個節點。
- Kafka 的提交日誌使其成為可靠的存儲系統。 Kafka 創建分區的副本/備份有助於防止數據丟失(正確的配置可以導致零數據丟失)。 這還可以防止服務器故障並增強 Kafka 的耐用性。
- Kafka 中的主題有數千個分區,使其能夠處理任意數量的數據和繁重的負載。
- Kafka 依靠操作系統內核快速移動數據。 這些信息集群是端到端加密的,生產者到文件系統再到最終消費者。
- Kafka 中的批處理提高了數據壓縮效率並降低了 I/O 延遲。
卡夫卡的應用
許多每天處理大量數據的公司都在使用 Kafka。

- LinkedIn 使用 Kafka 來跟踪用戶活動和性能指標。 Twitter 將它與 Storm 相結合,以啟用流處理框架。
- Square 使用 Kafka 來促進將所有系統事件轉移到其他 Square 數據中心。 這包括日誌、自定義事件和指標。
- 其他利用 Kafka 優勢的流行公司包括 Netflix、Spotify、Uber、Tumblr、CloudFlare 和 PayPal。
為什麼要學習 Apache Kafka?
Kafka 是一個出色的事件流平台,可以高效地處理、跟踪和監控實時數據。 其容錯和可擴展架構允許低延遲數據集成,從而實現高吞吐量的流事件。 Kafka 顯著縮短了數據的“價值實現時間”。
它通過消除圍繞數據的“日誌”作為向組織提供信息的基礎系統。 這使數據科學家和專家可以隨時輕鬆訪問信息。
由於這些原因,它是許多頂級公司的首選流媒體平台,因此,具有 Apache Kafka 資格的候選人備受追捧。
如果您有興趣了解有關 Kafka、大數據的更多信息,您應該查看 upGrad 的大數據軟件開發專業化 PG 文憑,該文憑提供 7 多個案例研究和項目以及來自世界級教師和行業專家的指導。 這個為期 13 個月的課程涵蓋 14 種編程語言,並教授數據處理、MapReduce、數據倉庫、實時處理、雲端大數據處理等技能。
在 upGrad 查看我們的其他軟件工程課程。