
語音助手的替代語音 UI
已發表: 2022-03-10對於大多數人來說,在考慮語音用戶界面時,首先想到的是語音助手,例如 Siri、Amazon Alexa 或 Google Assistant。 事實上,助手是大多數人使用語音與計算機系統交互的唯一環境。
雖然語音助手將語音用戶界面帶入了主流,但助手範式並不是使用、設計和創建語音用戶界面的唯一方式,甚至也不是最好的方式。
在本文中,我將討論語音助手所面臨的問題,並介紹一種用於語音用戶界面的新方法,我稱之為直接語音交互。
語音助手是基於語音的聊天機器人
語音助手是一種使用自然語言而不是圖標和菜單作為其用戶界面的軟件。 助手通常會回答問題並經常主動嘗試幫助用戶。
助手不是直接的交易和命令,而是模仿人類對話並雙向使用自然語言作為交互方式,這意味著它既可以接受用戶的輸入,也可以使用自然語言回答用戶。
第一個助手是基於對話的問答系統。 一個早期的例子是微軟的 Clippy,它臭名昭著地試圖幫助微軟 Office 的用戶,根據它認為用戶試圖完成的事情給他們指示。 如今,助手範式的典型用例是聊天機器人,通常用於聊天討論中的客戶支持。
另一方面,語音助手是使用語音而不是打字和文本的聊天機器人。 用戶輸入不是選擇或文本,而是語音,系統的響應也是大聲說出來的。 這些助手可以是通用助手,例如可以以合理方式回答大量問題的 Google Assistant 或 Alexa,也可以是為快餐訂購等特殊目的而構建的自定義助手。
儘管用戶的輸入通常只是一兩個詞,並且可以作為選擇而不是實際文本呈現,但隨著技術的發展,對話將更加開放和復雜。 聊天機器人和助手的第一個定義特徵是使用自然語言和對話風格,而不是定義典型移動應用程序或網站用戶體驗的圖標、菜單和事務風格。
推薦閱讀:使用 Web Speech API 和 Node.js 構建簡單的 AI 聊天機器人
源自自然語言反應的第二個定義特徵是角色的錯覺。 系統使用的語氣、質量和語言定義了助理體驗、同理心的錯覺和對服務的敏感性,以及它的角色。 一個好的助手體驗的想法就像是和一個真實的人訂婚。
由於語音是我們最自然的交流方式,這聽起來可能很棒,但使用自然語言響應存在兩個主要問題。 其中一個問題,與計算機如何模仿人類有關,未來可能會隨著對話式人工智能技術的發展而得到解決,但人腦如何處理信息的問題是人類的問題,在可預見的未來無法解決。 接下來讓我們看看這些問題。
自然語言反應的兩個問題
語音用戶界面當然是使用語音作為一種形式的用戶界面。 但是語音模態可以用於兩個方向:用於輸入來自用戶的信息和將信息從系統輸出回給用戶。 例如,一些電梯在用戶按下按鈕後使用語音合成來確認用戶選擇。 我們稍後將討論僅使用語音輸入信息並使用傳統圖形用戶界面將信息顯示給用戶的語音用戶界面。
另一方面,語音助手使用語音進行輸入和輸出。 這種方法有兩個主要問題:
問題#1:模仿人類失敗
作為人類,我們天生傾向於將類似人類的特徵歸因於非人類物體。 我們看到雲中飄過的人的特徵,或者看著三明治,它似乎在對我們咧嘴笑。 這叫做擬人化。

這種現像也適用於助手,它是由他們的自然語言反應觸發的。 雖然圖形用戶界面可以構建得有些中性,但人類不可能不開始思考某人的聲音是屬於年輕人還是老年人,或者是男性還是女性。 正因為如此,用戶幾乎開始認為助手確實是人。
但是,我們人類非常擅長檢測假貨。 奇怪的是,越接近人類的東西,越是微小的偏差開始乾擾我們。 對於試圖變得像人類但並不完全符合它的東西,會有一種令人毛骨悚然的感覺。 在機器人技術和計算機動畫中,這被稱為“恐怖谷”。

我們試圖讓助手變得更好、更人性化,當出現問題時,用戶體驗就會變得更加令人毛骨悚然和令人失望。 每個嘗試過助手的人都可能偶然發現用一些感覺愚蠢甚至粗魯的東西來回應的問題。
語音助手的恐怖谷帶來了難以克服的助手用戶體驗質量問題。 事實上,圖靈測試(以著名數學家艾倫·圖靈命名)是通過當人類評估者展示兩個智能體之間的對話時,無法區分它們中的哪一個是機器,哪一個是人類。 到目前為止,它從未被通過。
這意味著助手範式承諾提供永遠無法實現的類人服務體驗,用戶必然會感到失望。 當用戶開始信任他們的類人助手時,成功的體驗只會增加最終的失望。
問題 2:順序和緩慢的交互
語音助手的第二個問題是自然語言響應的回合製特性會導致交互延遲。 這是由於我們的大腦如何處理信息。
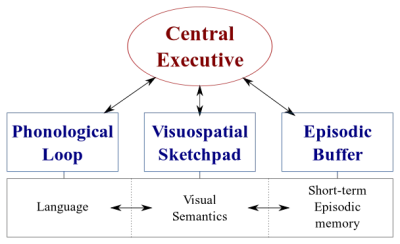
我們的大腦中有兩種類型的數據處理系統:
- 處理語音的語言系統;
- 專門處理視覺和空間信息的視覺空間系統。
這兩個系統可以並行運行,但兩個系統一次只處理一件事。 這就是為什麼你可以同時說話和開車,但你不能發短信和開車,因為這兩種活動都會發生在視覺空間系統中。

同樣,當您與語音助手交談時,助手需要保持安靜,反之亦然。 這將創建一個基於回合的對話,其中另一部分始終是完全被動的。
但是,考慮一個您想與朋友討論的困難話題。 你可能會面對面而不是通過電話討論,對吧? 這是因為在面對面的對話中,我們使用非語言交流向我們的對話夥伴提供實時視覺反饋。 這創建了一個雙向信息交換循環,並使雙方能夠同時積極參與對話。

助手不會提供實時視覺反饋。 他們依靠一種稱為端點的技術來決定用戶何時停止說話並在此之後才回复。 當他們回复時,他們不會同時接受用戶的任何輸入。 體驗是完全單向和回合製的。
在雙向和實時的面對面對話中,雙方可以立即對視覺和語言信號做出反應。 這利用了人腦的不同信息處理系統,使對話變得更加順暢和高效。
語音助手陷入單向模式,因為它們使用自然語言作為輸入和輸出通道。 雖然語音輸入的速度比打字快四倍,但消化速度卻比閱讀慢得多。 因為信息需要按順序處理,這種方法只適用於不需要太多助手輸出的簡單命令,例如“關燈”。
早些時候,我承諾討論語音用戶界面,該界面僅使用語音來輸入來自用戶的數據。 這種語音用戶界面受益於語音用戶界面的最佳部分——自然性、速度和易用性——但不會受到不好的部分——恐怖谷和順序交互的影響
讓我們考慮這個替代方案。
語音助手的更好選擇
克服語音助手中這些問題的解決方案是放棄自然語言響應,並用實時視覺反饋取而代之。 將反饋切換到視覺將使用戶能夠同時給出和獲得反饋。 這將使應用程序能夠在不中斷用戶的情況下做出反應並啟用雙向信息流。 因為信息流是雙向的,所以它的吞吐量更大。
目前,語音助手的主要用例是設置鬧鐘、播放音樂、查看天氣和提出簡單問題。 所有這些都是低風險的任務,在失敗時不會讓用戶太沮喪。
正如《華爾街日報》的大衛·皮爾斯曾經寫道:
“我無法想像通過語音助手預訂航班或管理我的預算,或者通過對著我的揚聲器喊配料來跟踪我的飲食。”
——《華爾街日報》的大衛·皮爾斯
這些都是信息量大的任務,需要正確進行。
然而,最終,語音用戶界面將失敗。 關鍵是要盡快解決這個問題。 在鍵盤上打字甚至在面對面的對話中都會發生很多錯誤。 但是,這並不令人沮喪,因為用戶只需單擊退格鍵並重試或要求澄清即可恢復。
這種從錯誤中快速恢復的方式使用戶能夠提高效率,並且不會強迫他們與助手進行奇怪的對話。
直接語音交互
在大多數應用程序中,通過操縱屏幕上的圖形元素、戳或滑動(在觸摸屏上)、單擊鼠標和/或按下鍵盤上的按鈕來執行操作。 可以添加語音輸入作為操作這些圖形元素的附加選項或方式。 這種交互方式可以稱為直接語音交互。
直接語音交互和助手之間的區別在於,用戶不是要求化身(助手)執行任務,而是直接用語音操作圖形用戶界面。
“這不是語義嗎?”,你可能會問。 如果您要與計算機交談,是直接與計算機交談還是通過虛擬角色交談真的很重要嗎? 在這兩種情況下,您只是在與計算機交談!
是的,區別很微妙,但很關鍵。 當單擊GUI (圖形用戶界面)中的按鈕或菜單項時,很明顯我們正在操作一台機器。 沒有人的錯覺。 通過用語音命令代替點擊,我們正在改進人機交互。 另一方面,借助助手範式,我們正在創建人與人之間交互的惡化版本,因此進入了恐怖谷。
將語音功能融合到圖形用戶界面中還提供了利用不同模式力量的潛力。 雖然用戶可以使用語音來操作應用程序,但他們也可以使用傳統的圖形界面。 這使用戶能夠在觸摸和語音之間無縫切換,並根據他們的上下文和任務選擇最佳選項。
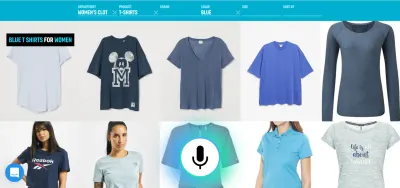
例如,語音是一種非常有效的輸入豐富信息的方法。 在幾個有效的替代方案之間進行選擇,觸摸或單擊可能會更好。 然後,用戶可以通過說“給我看看明天從倫敦到紐約起飛的航班”之類的話來代替打字和瀏覽,並使用觸摸從列表中選擇最佳選項。
現在你可能會問:“好吧,這看起來很棒,那麼為什麼我們以前沒有看到過這種語音用戶界面的例子呢? 為什麼大型科技公司不為這樣的事情創造工具?” 嗯,可能有很多原因。 一個原因是當前的語音助手範式可能是他們利用從最終用戶那裡獲得的數據的最佳方式。 另一個原因與他們的語音技術的構建方式有關。
一個運行良好的語音用戶界面需要兩個不同的部分:
- 將語音轉換為文本的語音識別;
- 從文本中提取含義的自然語言理解組件。
第二部分是將“關掉客廳的燈”和“請關掉客廳的燈”變成相同動作的魔法。
推薦閱讀:如何使用 API.AI 為 Google Home 構建自己的操作
如果您曾經使用過帶顯示屏的助手(例如 Siri 或 Google 助手),您可能已經註意到您確實可以近乎實時地獲得成績單,但是在您停止講話後,系統需要幾秒鐘實際執行您請求的操作。 這是由於語音識別和自然語言理解都是順序發生的。
讓我們看看如何改變它。
實時口語理解:更高效語音命令的秘訣
應用程序對用戶輸入的反應速度是應用程序整體用戶體驗的主要因素。 初代 iPhone 最重要的創新是反應靈敏且反應靈敏的觸摸屏。 語音用戶界面對語音輸入做出即時反應的能力同樣重要。
為了在用戶和 UI 之間建立快速的雙向信息交換循環,啟用語音的 GUI 應該能夠在用戶說出可操作的內容時立即做出反應——即使是在句子中間。 這需要一種稱為流式口語理解的技術。
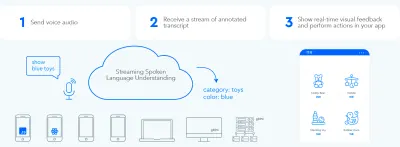
與在處理用戶請求之前等待用戶停止說話的傳統回合製語音助手系統相反,使用流式口語理解的系統從用戶開始說話的那一刻起就積極嘗試理解用戶意圖。 只要用戶說出可操作的內容,UI 就會立即對其做出反應。
即時響應立即驗證系統正在理解用戶並鼓勵用戶繼續。 這類似於人與人交流中的點頭或簡短的“啊哈”。 這導致支持更長和更複雜的話語。 分別,如果系統不理解用戶或用戶說錯話,即時反饋可以快速恢復。 用戶可以立即糾正並繼續,甚至口頭糾正自己:“我想要這個,不,我的意思是,我想要那個。” 您可以在我們的語音搜索演示中親自嘗試這種應用程序。
正如您在演示中看到的那樣,實時視覺反饋使用戶能夠自然地糾正自己並鼓勵他們繼續語音體驗。 由於他們不會被虛擬角色所迷惑,因此他們可以以與拼寫錯誤類似的方式將可能的錯誤聯繫起來——而不是個人侮辱。 體驗更快、更自然,因為提供給用戶的信息不受每分鐘約 150 個單詞的典型語速的限制。
推薦閱讀: Lyndon Cerejo 設計的語音體驗
結論
雖然到目前為止語音助手是語音用戶界面最常見的用途,但自然語言響應的使用使它們效率低下且不自然。 語音是一種很好的信息輸入方式,但聽機器說話並不是很有啟發性。 這是語音助手的大問題。
因此,語音的未來不應該是與計算機的對話,而是用最自然的交流方式代替繁瑣的用戶任務:語音。 直接語音交互可用於改善 Web 或移動應用程序中的表單填寫體驗,創建更好的搜索體驗,並啟用更有效的方式來控製或導航應用程序。
設計師和應用程序開發人員一直在尋找減少應用程序或網站摩擦的方法。 使用語音模式增強當前的圖形用戶界面將使用戶交互速度提高數倍,尤其是在某些情況下,例如當最終用戶在移動設備上、在旅途中且打字困難時。 事實上,即使在使用台式計算機時,語音搜索的速度也比傳統的搜索過濾用戶界面快五倍。
下一次,當您考慮如何使應用程序中的某個用戶任務更易於使用、使用更愉快,或者您對增加轉化感興趣時,請考慮是否可以用自然語言準確描述該用戶任務。 如果是,請使用語音模式補充您的用戶界面,但不要強迫您的用戶與計算機對話。
資源
- “語音優先與未來的多模式用戶界面,” UXmatters 的 Joan Palmiter Bajorek
- “創建高效語音應用程序的指南”,Hannes Heikinheimo,Speechly
- “觸摸屏應用程序應具備語音功能的 6 個原因”,Ottomatias Peura,UXmatters
- 混合有形和無形:使用 Adobe XD 設計多模式界面,Nick Babich,Smashing Magazine
( Adobe XD 可用於製作類似的原型) - “音速下的效率:語音操作的承諾”,Eric Turkington,RAIN
- 在電子商務語音搜索過濾中展示實時視覺反饋的演示(視頻版)
- Speechly 為此類用戶界面提供開發者工具
- 開源替代品:voice2json