
使用 Scikit 進行線性回歸的指南 [附示例]
已發表: 2021-06-18監督學習算法通常有兩種類型:回歸和分類,預測連續和離散輸出。
下面的文章將討論線性回歸及其使用最流行的 Python 機器學習庫之一 Scikit-learn 庫的實現。 Python 庫中提供了機器學習和統計模型工具,用於分類、回歸、聚類和降維。 該庫以 Python 編程語言編寫,建立在 NumPy、SciPy 和 Matplotlib Python 庫之上。
目錄
線性回歸
線性回歸在監督學習方法下執行回歸任務。 基於自變量,預測目標值。 該方法主要用於預測和識別變量之間的關係。
在代數中,術語線性是指變量之間的線性關係。 在二維空間中的變量之間推導出一條直線。
如果一條線是 X 軸上的自變量和 Y 軸上的因變量之間的圖,則通過最適合數據點的線性回歸獲得一條直線。
直線方程的形式為

Y = mx + b
其中,b = 截距
m = 線的斜率
因此,通過線性回歸,
- 截距和斜率的最佳值是在二維中確定的。
- x 和 y 變量沒有變化,因為它們是數據特徵,因此保持不變。
- 只能控制截距和斜率值。
- 可能存在基於斜率和截距值的多條直線,但是通過線性回歸算法在數據點上擬合多條直線,並返回誤差最小的直線。
使用 Python 進行線性回歸
為了在 python 中實現線性回歸,需要應用適當的包以及它的函數和類。 Python 中的 NumPy 包是開源的,允許對數組進行多項操作,包括單維數組和多維數組。
python中另一個廣泛使用的庫是用於機器學習問題的Scikit-learn。
Scikit-learn
Scikit-learn 庫為開發人員提供了基於監督和無監督學習的算法。 python的開源庫專為機器學習任務而設計。
數據科學家可以通過使用 scikit-learn 導入數據、對其進行預處理、繪製和預測數據。
David Cournapeau 於 2007 年首次開發 scikit-learn,該庫幾十年來一直在增長。
scikit-learn 提供的工具有:
- 回歸:包括邏輯回歸和線性回歸
- 分類:包括 K-Nearest Neighbors 方法
- 型號選擇
- 聚類:包括 K-Means++ 和 K-Means
- 預處理
圖書館的優點是:
- 圖書館的學習和實施很容易。
- 它是一個開源庫,因此是免費的。
- 機器學習方面可以被掩蓋,包括深度學習。
- 它是一個功能強大且用途廣泛的軟件包。
- 該庫有詳細的文檔。
- 機器學習最常用的工具包之一。
導入 scikit-learn
scikit-learn 必須首先通過 pip 或 conda 安裝。
- 要求:python 3 的 64 位版本,已安裝庫 NumPy 和 Scipy。 同樣對於數據圖的可視化,matplotlib 是必需的。
安裝命令:pip install -U scikit-learn
然後驗證是否安裝完成
安裝 Numpy、Scipy 和 matplotlib
可以通過以下方式確認安裝:
資源
通過 Scikit-learn 進行線性回歸
通過 scikit-learn 包實現線性回歸涉及以下步驟。
- 需要導入包和類。
- 需要使用數據並進行適當的轉換。
- 將創建一個回歸模型並與現有數據進行擬合。
- 檢查模型擬合數據以分析創建的模型是否令人滿意。
- 將通過應用模型進行預測。
NumPy 包和 LinearRegression 類將從 sklearn.linear_model 導入。

資源
sklearn 線性回歸所需的功能都存在於最終實現線性回歸。 sklearn.linear_model.LinearRegression 類用於執行回歸分析(線性和多項式)並進行預測。
對於任何機器學習算法和scikit 學習線性回歸,都必須先導入數據集。 Scikit-learn 提供了三個選項來獲取數據:

- 虹膜分類或波士頓房價回歸集等數據集。
- 現實世界的數據集可以通過 Scikit-learn 預定義函數直接從互聯網上下載。
- 可以通過 Scikit-learn 數據生成器隨機生成數據集以匹配特定模式。
無論選擇什麼選項,都必須導入模塊數據集。
將 sklearn.datasets導入為數據集
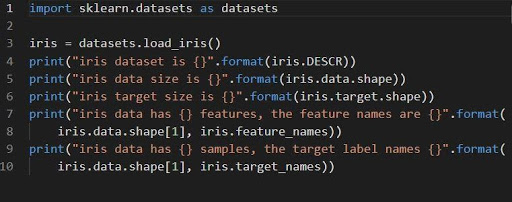
1. 鳶尾花的分類集
iris = datasets.load_iris()
數據集 iris 存儲為 n_samples * n_features 的二維數組數據字段。 它的輸入是作為字典的對象執行的。 它包含所有必要的數據以及元數據。
函數 DESCR、shape 和 _names 可用於獲取數據的描述和格式。 打印函數結果將顯示在處理 iris 數據集時可能需要的數據集信息。
以下代碼將加載 iris 數據集的信息。
資源
2. 回歸數據的生成
如果不需要內置數據,則可以通過可以選擇的分佈生成數據。
使用一組 1 個信息特徵和 1 個特徵生成回歸數據。
X , Y = datasets.make_regression(n_features=1, n_informative=1)
生成的數據保存在具有對象 x 和 y 的 2D 數據集中。 生成數據的特徵可以通過改變函數make_regression的參數來改變。
在此示例中,信息特徵和特徵的參數從默認值 10 更改為 1。
考慮的其他參數是樣本和目標,其中控制了跟踪的目標和样本變量的數量。
- 為機器學習算法提供有用信息的特徵被稱為信息特徵,而那些無用的特徵被稱為信息特徵。
3. 繪製數據
使用 matplotlib 庫繪製數據。 首先,必須導入 matplotlib。
將 matplotlib.pyplot 導入為 plt
上圖是通過matplotlib通過代碼繪製的
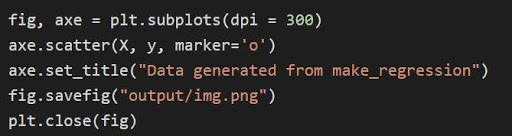
資源
在上面的代碼中:
- 元組變量被解包並保存為代碼第 1 行中的單獨變量。 因此,可以操作和保存單獨的屬性。
- 數據集 x, y 用於通過第 2 行生成散點圖。利用 matplotlib 中可用的標記參數,通過用點 (o) 標記數據點來增強視覺效果。
- 生成圖的標題通過第 3 行設置。
- 可以將圖形保存為 .png 圖像文件,然後關閉當前圖形。
通過上述代碼生成的回歸圖為
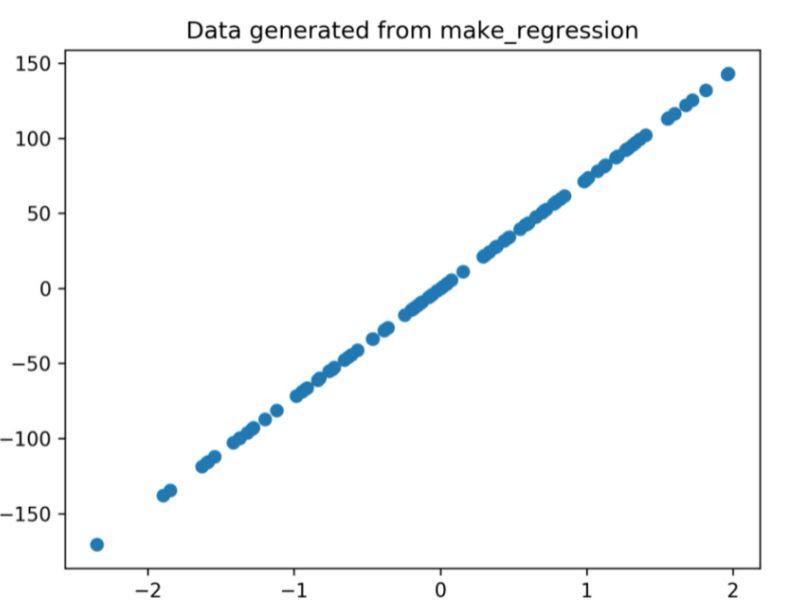
圖 1:從上面的代碼生成的回歸圖。
4. 線性回歸的實現算法
使用波士頓房價的樣本數據,在下面的例子中實現了Scikit-learn 線性回歸的算法。 與其他 ML 算法一樣,數據集被導入,然後使用以前的數據進行訓練。
企業使用線性回歸方法,因為它是一種預測模型,用於預測數值及其變量與輸出值之間的關係,具有現實意義。
當存在早期數據的日誌時,可以最好地應用該模型,因為如果該模式繼續存在,它可以預測未來將發生的事情的未來結果。
在數學上,可以擬合數據以最小化數據點與預測值之間存在的所有殘差之和。
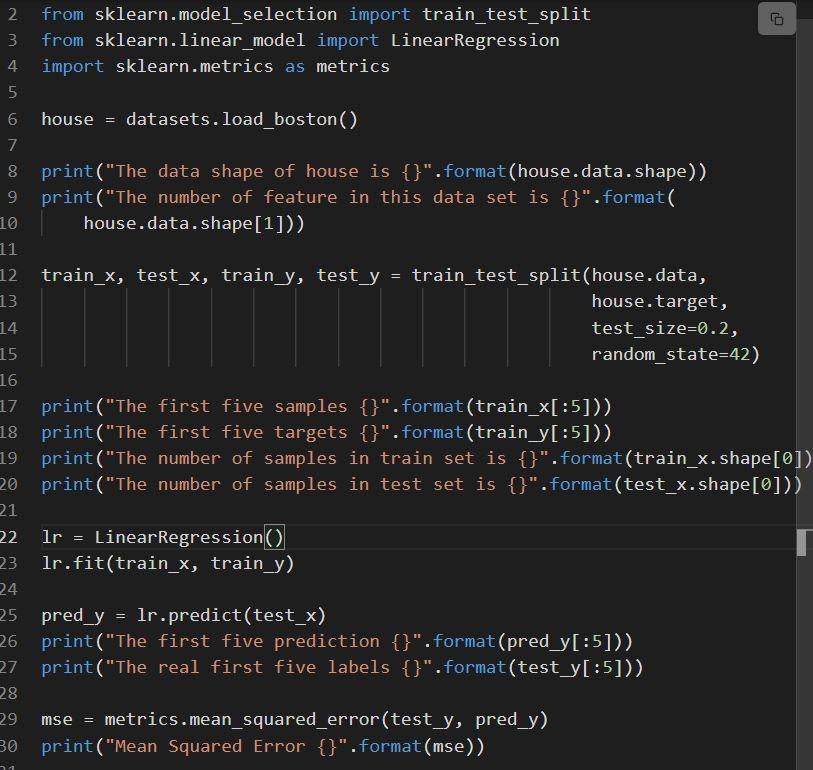
以下片段顯示了sklearn 線性回歸的實現。
資源
代碼解釋如下:
- 第 6 行加載名為 load_boston 的數據集。
- 數據集在第 12 行拆分,即 80% 數據的訓練集和 20% 數據的測試集。
- 在第 23 行創建線性回歸模型,然後在第 23 行進行訓練。
- 通過調用 mean_squared_error 在亞麻 29 處評估模型的性能。
sklearn線性回歸圖如下所示:
波士頓房價樣本數據的線性回歸模型
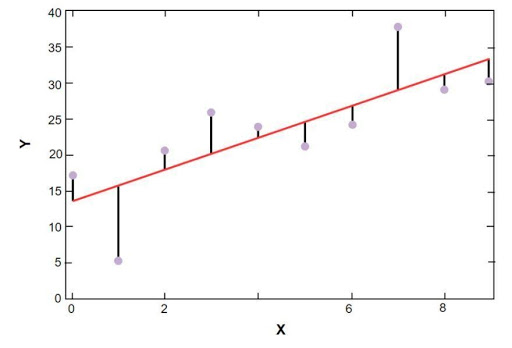
資源
上圖中,紅線代表波士頓房價樣本數據已經求解的線性模型。 藍點代表原始數據,紅線和藍點之間的距離代表殘差之和。 scikit-learn 線性回歸模型的目標是減少殘差之和。
結論
本文討論了線性回歸及其通過使用名為 scikit-learn 的開源 python 包的實現。 至此,您已經可以通過這個包了解如何實現線性回歸了。 值得學習如何使用該庫進行數據分析。
如果您有興趣進一步探索該主題,例如 Python 包在機器學習和 AI 相關問題中的實現,您可以查看upGrad提供的機器學習與 AI 科學碩士課程。 該課程針對 21 至 45 歲的入門級專業人士,旨在通過 650 多個小時的在線培訓、25 多個案例研究和作業來培訓學生的機器學習。 LJMU認證,課程提供完美的指導和就業幫助。 如果您有任何問題或疑問,請給我們留言,我們將很樂意與您聯繫。