
什么是 Java 机器学习? 如何实施?
已发表: 2021-03-10目录
什么是机器学习?
机器学习是人工智能的一个部门,它从可用数据、示例和经验中学习,以模仿人类的行为和智能。 使用机器学习创建的程序可以自行构建逻辑,而无需人工手动编写代码。
这一切都始于 1950 年代初的图灵测试,当时艾伦·特宁得出结论,计算机要想拥有真正的智能,就需要操纵或说服人类它也是人类。 机器学习是一个相对古老的概念,但直到今天这个新兴领域才得以实现,因为计算机现在可以处理复杂的算法。 机器学习算法在过去十年中已经发展到包括复杂的计算技能,这反过来又增强了它们的模仿能力。
机器学习应用也以惊人的速度增长。 从医疗保健、金融、分析和教育,到制造、营销和政府运营,在实施机器学习技术后,每个行业的质量和效率都得到了显着提升。 世界各地都出现了广泛的质量改进,因此推动了对机器学习专业人员的需求。
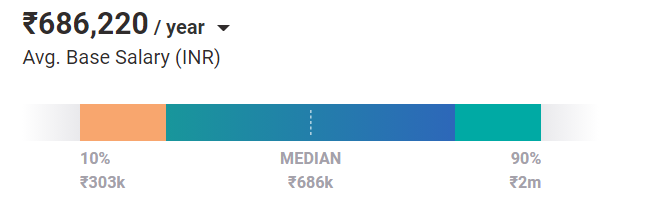
平均而言,机器学习工程师今天的薪水为 686,220 卢比/年。 这就是入门级职位的情况。 凭借经验和技能,他们可以在印度赚取高达 200 万卢比/年的收入。
机器学习算法的类型
机器学习算法分为三种类型:
1. 监督学习:在这种类型的学习中,训练数据集指导算法做出准确的预测或分析决策。 它利用从过去的训练数据集中学习来处理新数据。 以下是监督学习机器学习模型的一些示例:

- 线性回归
- 逻辑回归
- 决策树
2. 无监督学习:在这种类型的学习中,机器学习模型从未标记的信息中学习。 它通过对对象进行分组或理解它们之间的关系,或利用它们的统计特性来进行分析,从而采用数据聚类。 无监督学习算法的例子有:
- K-means 聚类
- 层次聚类
3.强化学习:这个过程是基于hit and trial。 它是通过与空间或环境互动来学习的。 RL 算法通过与环境交互并确定最佳行动方案来从过去的经验中学习。
如何用 Java 实现机器学习?
Java 是用于实现机器学习算法的顶级编程语言之一。 它的大部分库都是开源的,提供广泛的文档支持、易于维护、适销性和易读性。
根据受欢迎程度,以下是用于在 Java 中实现机器学习的前 10 个机器学习库。
1.亚当斯
高级数据挖掘和机器学习系统或 ADAMS 关注于构建新颖而灵活的工作流系统并管理复杂的现实世界流程。 ADAMS 采用树状架构来管理数据流,而不是进行手动输入输出连接。
它消除了对显式连接的任何需要。 它基于“少即是多”的原则,执行检索、可视化和数据驱动的可视化。 ADAMS 擅长数据处理、数据流、管理数据库、脚本和文档。
2.JavaML
JavaML 提供了多种为 Java 编写的 ML 和数据挖掘算法,以支持软件工程师、程序员、数据科学家和研究人员。 每个算法都有一个易于使用的通用界面,并且即使没有 GUI,也有广泛的文档支持。
与其他聚类算法相比,它的实现相当简单直接。 其核心功能包括数据操作、文档编制、数据库管理、数据分类、聚类、特征选择等。
加入来自世界顶级大学的在线机器学习课程——硕士、高管研究生课程和 ML 和 AI 高级证书课程,以加快您的职业生涯。
3.威卡
Weka 也是一个为 Java 编写的支持深度学习的开源机器学习库。 它提供了一套机器学习算法,并在数据挖掘、数据准备、数据聚类、数据可视化和回归等数据操作中得到广泛应用。
示例:我们将使用一个小型糖尿病数据集来演示这一点。
第 1 步:使用 Weka 加载数据
| 导入 weka.core.Instances; 导入 weka.core.converters.ConverterUtils.DataSource; 公共类主要{ 公共静态 void main(String[] args) 抛出异常 { // 指定数据源 数据源 dataSource = new DataSource(“data.arff”); // 加载数据集 实例 dataInstances = dataSource.getDataSet(); // 显示实例数 log.info(“加载的实例数为:” + dataInstances.numInstances()); log.info(“数据:” + dataInstances.toString()); } } |
第 2 步:数据集有 768 个实例。 我们需要访问属性的数量,即 9。
| log.info(“数据集中的属性(特征)个数:” + dataInstances.numAttributes()); |
第三步:我们需要在建立模型之前确定目标列并找到类的数量。
| // 识别标签索引 dataInstances.setClassIndex(dataInstances.numAttributes() - 1); // 获取数量 log.info(“类数:” + dataInstances.numClasses()); |
第 4 步:我们现在将使用简单的树分类器 J48 构建模型。
| // 创建决策树分类器 J48 treeClassifier = new J48(); treeClassifier.setOptions(new String[] { “-U” }); treeClassifier.buildClassifier(dataInstances); |
上面的代码重点介绍了如何创建由模型训练所需的数据实例组成的未修剪树。 在模型训练后打印树结构后,我们可以确定规则是如何在内部构建的。
| 等离子 <= 127 | 质量 <= 26.4 | | preg <= 7:tested_negative (117.0/1.0) | | 怀孕 > 7 | | | 质量 <= 0:tested_positive (2.0) | | | 质量 > 0:tested_negative (13.0) | 质量 > 26.4 | | 年龄 <= 28:tested_negative (180.0/22.0) | | 年龄 > 28 | | | plas <= 99:tested_negative (55.0/10.0) | | | 塑料 > 99 | | | | pedi <= 0.56:tested_negative (84.0/34.0) | | | | 足底 > 0.56 | | | | | 怀孕 <= 6 | | | | | | 年龄 <= 30:tested_positive (4.0) | | | | | | 年龄 > 30 | | | | | | | 年龄 <= 34:test_negative (7.0/1.0) | | | | | | | 年龄 > 34 | | | | | | | | 质量 <= 33.1:tested_positive (6.0) | | | | | | | | 质量 > 33.1:tested_negative (4.0/1.0) | | | | | preg > 6:tested_positive (13.0) 塑料 > 127 | 质量 <= 29.9 | | plas <= 145:tested_negative (41.0/6.0) | | 塑料 > 145 | | | 年龄 <= 25:test_negative (4.0) | | | 年龄 > 25 | | | | 年龄 <= 61 | | | | | 质量 <= 27.1:tested_positive (12.0/1.0) | | | | | 质量 > 27.1  | | | | | | 压力 <= 82 | | | | | | | pedi <= 0.396:tested_positive (8.0/1.0) | | | | | | | pedi > 0.396:test_negative (3.0) | | | | | | 压力 > 82: 测试阴性 (4.0) | | | | 年龄 > 61:test_negative (4.0) | 质量 > 29.9 | | 等离子 <= 157 | | | pres <= 61:tested_positive (15.0/1.0) | | | 压力 > 61 | | | | 年龄 <= 30:tested_negative (40.0/13.0) | | | | 年龄 > 30:test_positive (60.0/17.0) | | plas > 157:tested_positive (92.0/12.0) 叶数:22 树的大小:43 |
4. 阿帕奇马豪
Mahaut 是一组算法,可帮助使用 Java 实现机器学习。 它是一个可扩展的线性代数框架,开发人员可以使用它进行数学、统计学家分析。 数据科学家、研究工程师和分析专业人员通常使用它来构建企业级应用程序。 它的可扩展性和灵活性允许用户快速轻松地实施数据集群、推荐系统和创建高性能机器学习应用程序。
5. 深度学习4j
Deeplearning4j 是一个用 Java 编写的编程库,为深度学习提供广泛的支持。 它是一个开源框架,结合了深度神经网络和深度强化学习来服务于业务运营。 兼容Scala、Kotlin、Apache Spark、Hadoop等JVM语言和大数据计算框架。
它通常用于检测语音、语音和书面文本中的模式和情绪。 它作为一个 DIY 工具,可以发现交易中的差异,并处理多项任务。 它是一个商业级的分布式库,由于其开源特性,它具有详细的 API 文档。
这是一个如何使用 Deeplearning4j 实现机器学习的示例。
示例:使用 Deeplearning4j,我们将构建卷积神经网络 (CNN) 模型,借助 MNIST 库对手写数字进行分类。
第 1 步:加载数据集以显示其大小。
| DataSetIterator MNISTTrain = new MnistDataSetIterator(batchSize,true,seed); DataSetIterator MNISTTest = new MnistDataSetIterator(batchSize,false,seed); |
第 2 步:确保数据集为我们提供了十个唯一标签。
| log.info(“在训练数据集中找到的总标签数” + MNISTTrain.totalOutcomes()); log.info(“在测试数据集中找到的标签总数” + MNISTTest.totalOutcomes()); |
第 3 步:现在,我们将使用两个卷积层和一个展平层来配置模型架构以显示输出。
Deeplearning4j 中有一些选项允许您初始化权重方案。
| // 构建 CNN 模型 MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder() .seed(seed) // 随机种子 .l2(0.0005) // 正则化 .weightInit(WeightInit.XAVIER) // 初始化权重方案 .updater(new Adam(1e-3)) // 设置优化算法 。列表() .layer(new ConvolutionLayer.Builder(5, 5) //设置步幅、内核大小和激活函数。 .nIn(nChannels) .stride(1,1) .nOut(20) .activation(激活.IDENTITY) 。建造()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // 下采样卷积 .kernelSize(2,2) .stride(2,2) 。建造()) .layer(new ConvolutionLayer.Builder(5, 5) // 设置步幅、内核大小和激活函数。 .stride(1,1) .nOut(50) .activation(激活.IDENTITY) 。建造()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // 下采样卷积 .kernelSize(2,2) .stride(2,2) 。建造()) .layer(new DenseLayer.Builder().activation(Activation.RELU) .nOut(500).build()) .layer(new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD) .nOut(输出编号) .activation(激活.SOFTMAX) 。建造()) // 最终输出层为 28×28,深度为 1。 .setInputType(InputType.convolutionalFlat(28,28,1)) 。建造(); |
第 4 步:在我们配置好架构后,我们将初始化模式和训练数据集,并开始模型训练。
| 多层网络模型 = 新多层网络(conf); // 初始化模型权重。 模型.init(); log.info(“第二步:开始训练模型”); //每 10 次迭代设置一个监听器,并在每个 epoch 上评估测试集 model.setListeners(new ScoreIterationListener(10), new EvaluativeListener(MNISTTest, 1, InvocationType.EPOCH_END)); // 训练模型 model.fit(MNISTTrain, nEpochs); |
随着模型训练的开始,您将获得分类准确度的混淆矩阵。
这是十个训练周期后模型的准确度:
| ==========================混淆矩阵======================= == 0 1 2 3 4 5 6 7 8 9 —————————————————— 977 0 0 0 0 0 1 1 1 0 | 0 = 0 0 1131 0 1 0 1 2 0 0 0 | 1 = 1 1 2 1019 3 0 0 0 3 4 0 | 2 = 2 0 0 1 1004 0 1 0 1 3 0 | 3 = 3 0 0 0 0 977 0 2 0 1 2 | 4 = 4 1 0 0 9 0 879 1 0 1 1 | 5 = 5 4 2 0 0 1 1 949 0 1 0 | 6 = 6 0 4 2 1 1 0 0 1018 1 1 | 7 = 7 2 0 3 1 0 1 1 2 962 2 | 8 = 8 0 2 0 2 11 2 0 3 2 987 | 9 = 9 |
6. 埃尔基
由索引结构或 ELKI 支持的开发 KDD 应用程序的环境是用于数据挖掘的内置算法和程序的集合。 它是用 Java 编写的,是一个开源库,包含算法中高度可配置的参数。 它通常被研究科学家和学生用来深入了解数据集。 顾名思义,它为使用索引结构开发复杂的数据挖掘程序和数据库提供了环境。
7.日本SAT
Java Statistical Analysis Tool 或 JSAT 是一个 GPL3 库,它使用面向对象的框架来帮助用户使用 Java 实现机器学习。 它通常用于学生和开发人员的自我教育目的。 与其他 AI 实现库相比,JSAT 拥有最多的 ML 算法,并且是所有框架中最快的。 由于零外部依赖,它具有高度的灵活性和高效性,并提供高性能。
8. Encog 机器学习框架
Encog 是用 Java 和 C# 编写的,包含帮助实现机器学习算法的库。 它用于构建遗传算法、贝叶斯网络、隐马尔可夫模型等统计模型等。
9. 木槌
语言工具包或槌的机器学习用于自然语言处理 (NLP)。 与大多数其他 ML 实现框架一样,Mallet 也提供对数据建模、数据聚类、文档处理、文档分类等的支持。
10. Spark MLlib
企业使用 Spark MLlib 来提高工作流管理的效率和可扩展性。 它处理大量数据并支持重负载的 ML 算法。
结帐:机器学习项目的想法
结论
这将我们带到了文章的结尾。 有关机器学习概念的更多信息,请通过 upGrad 的机器学习和 AI 理学硕士课程与班加罗尔 IIIT 和利物浦约翰摩尔斯大学的顶尖教师取得联系。
为什么我们应该将 Java 与机器学习一起使用?
如果机器学习专业人士选择 Java 作为其项目的编程语言,他们会发现与当前代码存储库交互更容易。 由于易于使用、打包服务、更好的用户交互、快速调试和数据图形说明等特性,它是首选的机器学习语言。 Java 使机器学习开发人员可以轻松扩展他们的系统,使其成为从头开始构建大型、复杂的机器学习应用程序的绝佳选择。 Java 虚拟机 (JVM) 支持许多集成开发环境 (IDE),允许机器学习者快速设计新工具。
学习Java容易吗?
由于 Java 是一种高级语言,因此很容易掌握。 作为一名学习者,您不必深入了解细节,因为它是一种结构良好、面向对象的语言,对于新手来说足够简单。 因为有许多程序可以自动运行,您可以快速掌握它们。 您不必详细了解那里的事情是如何运作的。 Java 是一种独立于平台的编程语言。 它使程序员能够创建可在任何设备上使用的移动应用程序。 它是物联网的首选语言,也是开发企业级应用程序的最佳工具。
什么是 ADAMS,它对机器学习有何帮助?
高级数据挖掘和机器学习系统 (ADAMS) 是一个 GPLv3 许可的工作流引擎,用于快速创建和管理数据驱动的反应式工作流,这些工作流可以很容易地整合到业务流程中。 遵循少即是多原则的工作流引擎是 ADAMS 的核心。 ADAMS 采用树状结构,而不是允许用户在画布上安排操作员(或 ADAMS 行话中的演员),然后手动链接输入和输出。 不需要显式连接,因为这种结构和控制参与者决定了数据在流程中的流动方式。 运算符处理程序中的内部对象表示和子运算符嵌套导致树状结构。 ADAMS 为数据检索、处理、挖掘和显示提供了一组多样化的代理。