
什么是数据挖掘中的决策树? 类型、真实世界的示例和应用
已发表: 2021-06-15目录
数据挖掘简介
数据通常以原始数据的形式出现,需要对其进行有效处理才能将其转换为有用的信息。 结果的预测通常依赖于在数据中发现模式、异常或相关性的过程。 该过程被称为“数据库中的知识发现”。
直到 1990 年代才创造了“数据挖掘”一词。 数据挖掘建立在三个学科之上:统计学、人工智能和机器学习。 自动化数据挖掘已将分析过程从繁琐的方法转变为更快的方法。 数据挖掘允许用户
- 删除所有嘈杂和混乱的数据
- 了解相关数据并将其用于预测有用信息。
- 预测明智决策的过程加快了。
数据挖掘也可以称为识别需要分类的隐藏信息模式的过程。 只有这样,数据才能转化为有用的数据。 有用的数据可以输入数据仓库、数据挖掘算法、数据分析以进行决策。
数据挖掘中的决策树
一种数据挖掘技术,数据挖掘中的决策树为数据的分类建立模型。 模型以树形结构的形式构建,因此属于有监督的学习形式。 除了分类模型之外,决策树还用于构建回归模型,以预测类标签或有助于决策过程的值。 决策树可以使用数字和分类数据,如性别、年龄等。
决策树的结构
决策树的结构由根节点、分支和叶节点组成。 分支节点是树的结果,内部节点表示对属性的测试。 叶节点代表一个类标签。
决策树的工作
1. 决策树在离散变量和连续变量的监督学习方法下工作。 根据数据集最重要的属性将数据集拆分为子集。 属性的识别和分割是通过算法完成的。
2.决策树的结构由根节点组成,它是重要的预测节点。 分裂过程从决策节点开始,决策节点是树的子节点。 没有进一步分裂的节点称为叶节点或终端节点。
3. 按照自上而下的方法将数据集划分为同质区域和非重叠区域。 顶层在一个地方提供观察,然后分裂成分支。 该过程被称为“贪婪方法”,因为它只关注当前节点而不是未来节点。
4. 除非达到停止标准,否则决策树将继续运行。
5. 随着决策树的建立,会产生大量的噪声和异常值。 为了去除这些异常值和噪声数据,应用了“树修剪”的方法。 因此,模型的准确性会提高。
6. 在由测试元组和类标签组成的测试集上检查模型的准确性。 一个准确的模型是根据模型的分类测试集元组和类的百分比来定义的。
图 1 :未修剪和修剪树的示例
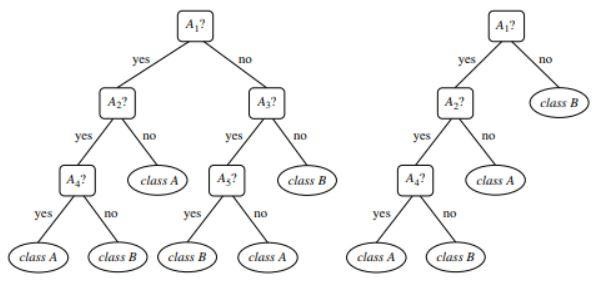
资源
决策树的类型
决策树导致基于树状结构的分类和回归模型的发展。 数据被分解成更小的子集。 决策树的结果是具有决策节点和叶节点的树。 下面解释两种类型的决策树:
一、分类
分类包括建立描述重要类别标签的模型。 它们应用于机器学习和模式识别领域。 机器学习中的决策树通过分类模型导致欺诈检测、医疗诊断等。分类模型的两个步骤过程包括:
- 学习:建立基于训练数据的分类模型。
- 分类:检查模型的准确性,然后用于新数据的分类。 类标签采用离散值的形式,如“是”或“否”等。
图 2 :分类模型示例。
资源
2.回归
回归模型用于数据的回归分析,即数值属性的预测。 这些也称为连续值。 因此,回归模型不是预测类别标签,而是预测连续值。
使用的算法列表
1980 年,机器研究员 J. Ross Quinlan 开发了一种称为“ID3”的决策树算法。 该算法被他开发的C4.5等其他算法所继承。 两种算法都应用了贪心方法。 算法 C4.5 不使用回溯,并且树以自上而下的递归分而治之的方式构建。 该算法使用带有类标签的训练数据集,随着树的构建,这些标签被分成更小的子集。
- 最初选择三个参数——属性列表、属性选择方法和数据分区。 训练集的属性在属性列表中描述。
- 属性选择方法包括选择用于区分元组的最佳属性的方法。
- 树结构取决于属性选择方法。
- 树的构建从单个节点开始。
- 当一个元组中表示不同的类标签时,就会发生元组的拆分。 这将导致树的分支形成。
- 拆分方法决定了应该为数据分区选择哪个属性。 基于这种方法,分支是根据测试结果从一个节点生长出来的。
- 递归地执行拆分和分区的方法,最终得到训练数据集元组的决策树。
- 树的形成过程一直持续到并且除非剩下的元组不能被进一步分割。
- 算法的复杂度表示为
n * |D| * 日志 |D|
其中,n 是训练数据集 D 中的属性数,|D| 是元组的数量。
资源
图 3:离散值拆分
决策树中使用的算法列表是:
ID3
在形成决策树时,将整个数据集 S 视为根节点。 然后对每个属性进行迭代并将数据拆分为片段。 该算法检查并获取那些在迭代之前未获取的属性。 在 ID3 算法中拆分数据非常耗时,并且不是理想的算法,因为它会过度拟合数据。
C4.5
它是一种高级形式的算法,因为数据被分类为样本。 与 ID3 不同,可以有效处理连续值和离散值。 存在修剪方法,可去除不需要的分支。
大车
该算法可以执行分类和回归任务。 与 ID3 和 C4.5 不同,决策点是通过考虑基尼指数来创建的。 一种贪心算法被应用于旨在降低成本函数的分裂方法。 在分类任务中,使用基尼指数作为代价函数来表示叶子节点的纯度。 在回归任务中,使用平方和误差作为成本函数来找到最佳预测。
柴德
顾名思义,它代表卡方自动交互检测器,一个处理任何类型变量的过程。 它们可能是名义变量、有序变量或连续变量。 回归树使用 F 检验,而分类模型中使用卡方检验。
火星
它代表多元自适应回归样条。 该算法专门在回归任务中实现,其中数据大多是非线性的。
贪婪递归二进制拆分
发生二进制拆分方法会导致两个分支。 元组的拆分是通过拆分成本函数的计算来执行的。 选择成本最低的拆分并递归执行该过程以计算其他元组的成本函数。
具有真实世界示例的决策树
根据给定数据预测贷款资格流程。
Step1:加载数据
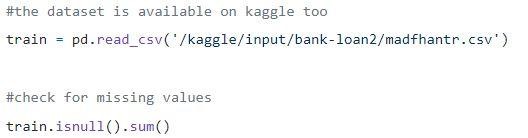
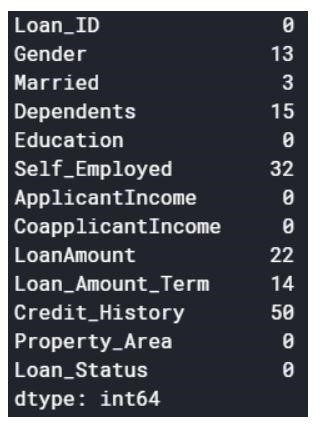

空值可以删除或填充一些值。 原始数据集的形状为(614,13),删除空值后的新数据集为(480,13)。
Step2:查看数据集。

Step3:将数据拆分为训练集和测试集。
第 4 步:构建模型并拟合训练集

在可视化之前,需要进行一些计算。
计算1:计算整个数据集的熵。

计算 2:求每一列的熵和增益。
- 性别栏
- 条件 1:包含所有男性的数据集,然后,
p = 278,n=116,p+n=489
熵(G=男性)= 0.87
- 条件 2:包含所有女性的数据集,然后,
p = 54 , n = 32 , p+n = 86
熵(G=女性)= 0.95
- 性别栏中的平均信息

- 已婚专栏
- 条件 1:已婚 = 是(1)
在此拆分整个数据集与已婚状态是
p = 227 , n = 84 , p+n = 311
E(已婚=是)= 0.84
- 条件 2:已婚 = 否(0)
在此拆分整个数据集,已婚状态为 no
p = 105 , n = 64 , p+n = 169
E(已婚 = 否)= 0.957
- 已婚列中的平均信息为
- 教育专栏
- 条件一:学历=研究生(1)
p = 271 , n = 112 , p+n = 383
E(教育=研究生)= 0.87
- 条件 2:教育 = 未毕业(0)
p = 61 , n = 36 , p+n = 97
E(教育=未毕业)= 0.95
- 教育栏的平均信息= 0.886
增益 = 0.01
4) 自雇专栏
- 条件 1:自雇 = 是(1)
p = 43 , n = 23 , p+n = 66
E(自雇=是)= 0.93
- 条件 2:自雇 = 否(0)
p = 289 , n = 125 , p+n = 414
E(自雇=否)= 0.88
- 自雇教育栏的平均信息 = 0.886
增益 = 0.01
- Credit Score 列:该列有 0 和 1 值。
- 条件 1:信用评分 = 1
p = 325 , n = 85 , p+n = 410
E(信用评分= 1)= 0.73
- 条件 2:信用评分 = 0
p = 63 , n = 7 , p+n = 70
E(信用分数 = 0) = 0.46
- 信用评分列中的平均信息 = 0.69
增益 = 0.2
比较所有增益值

信用评分的收益最高。 因此,它将被用作根节点。
第 5 步:可视化决策树

图 5:具有标准 Gini 的决策树
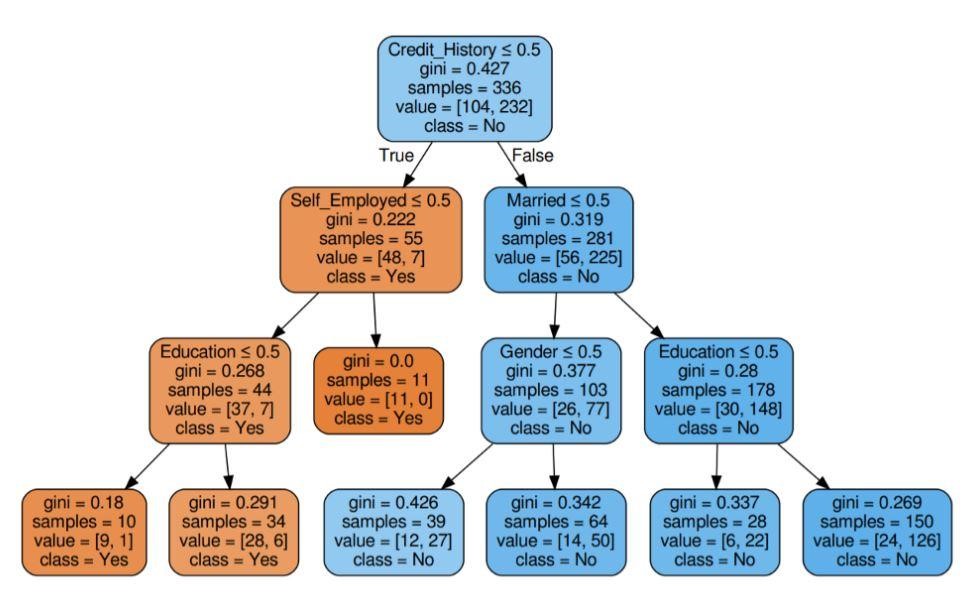 资源
资源
图 6:具有标准熵的决策树
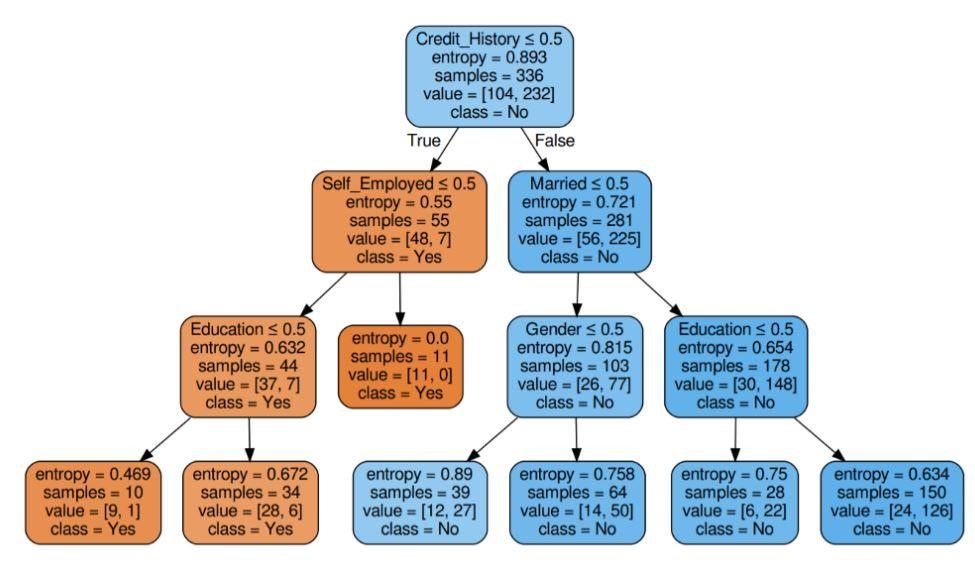
资源
第6步:检查模型的分数
几乎 80% 的准确率得分。
应用程序列表
决策树主要由信息专家用于进行分析调查。 它们可能被广泛用于商业目的,以分析或预测困难。 决策树的灵活性允许它们用于不同的领域:
1. 医疗保健
决策树允许预测患者是否患有具有年龄、体重、性别等条件的特定疾病。其他预测包括考虑成分、制造时间等因素来确定药物的效果。
2. 银行业
决策树有助于根据一个人的财务状况、工资、家庭成员等来预测一个人是否有资格获得贷款。它还可以识别信用卡欺诈、贷款违约等。
3. 教育部门
可以在决策树的帮助下根据学生的成绩、出勤率等来确定学生的入围名单。
优势一览
- 决策模型的可解释结果可以呈现给高级管理层和利益相关者。
- 在构建决策树模型时,不需要对数据进行预处理,即标准化、缩放等。
- 数据类型和分类数据都可以由决策树处理,该决策树显示出比其他算法更高的使用效率。
- 数据中的缺失值不会影响决策树的过程,从而使其成为一种灵活的算法。
接下来是什么?
如果您有兴趣获得数据挖掘方面的实践经验并接受专家的培训,您可以查看 upGrad 的数据科学执行 PG 计划。 该课程面向 21-45 岁之间的任何年龄组,最低资格标准为 50% 或同等毕业及格分数。 任何工作的专业人士都可以加入这个由 IIIT 班加罗尔认证的执行 PG 计划。
数据挖掘中的决策树能够处理非常复杂的数据。 所有的决策树都有三个重要的节点或部分。 让我们在下面讨论它们中的每一个。 现在我们已经了解了决策树的工作原理,让我们尝试看看在数据挖掘中使用决策树的一些优点什么是数据挖掘中的决策树?
决策树是在数据挖掘中构建模型的一种方式。 可以理解为倒置二叉树。 它包括一个根节点、一些分支和最后的叶节点。
决策树中的每个内部节点都表示对属性的研究。 每个部分都表示该特定研究或考试的结果。 最后,每个叶节点代表一个类标签。
构建决策树的主要目标是通过对先前数据使用判断程序来创建一个可用于预测特定类别的理想。
我们从根节点开始,与根变量建立一些关系,并进行符合这些值的划分。 基于基本选择,我们跳转到后续节点。 决策树中使用了哪些重要节点?
当我们连接所有这些节点时,我们就会得到分裂。 我们可以无限次地使用这些节点和划分来形成具有各种困难的树。 使用决策树有什么好处?
1.当我们将它们与其他方法进行比较时,决策树在预处理期间不需要太多的计算来训练数据。
2. 决策树不涉及信息的稳定化。
3. 此外,它们甚至不需要扩展信息。
4. 即使数据集中省略了一些值,也不会影响树的构建。
5. 这些模型是相同的本能。 它们的描述也没有压力。