
为 Google Assistant 和 Amazon Alexa 创建语音技能
已发表: 2022-03-10在过去的十年中,对话界面发生了翻天覆地的变化。 随着人们达到“峰值屏幕”,甚至开始缩减他们的设备使用量,大多数操作系统中都包含了数字健康功能。
为了对抗屏幕疲劳,语音助手已经进入市场,成为快速检索信息的首选。 一个重复的统计数据表明,到 2020 年,50% 的搜索将通过语音完成。此外,随着采用率的提高,开发人员可以在他们的工具带中添加“对话界面”和“语音助手”。
设计隐形
对于许多人来说,开始语音 UI (VUI) 项目可能有点像进入未知领域。 详细了解 William Merrill 在语音设计中的经验教训。 阅读相关文章 →
什么是会话界面?
会话界面(有时缩写为 CUI,是人类语言的任何界面。它被认为是比前端开发人员习惯构建的图形用户界面 GUI 更自然的界面。GUI 需要人类了解其特定的界面语法(想想按钮、滑块和下拉菜单)。
使用人类语言的这一关键区别使 CUI 对人们来说更加自然; 它需要的知识很少,并且将理解的负担放在了设备上。
通常 CUI 有两种形式:聊天机器人和语音助手。 由于自然语言处理 (NLP) 的进步,在过去十年中,两者都出现了大幅增长。
了解语音术语

| 关键词 | 意义 |
|---|---|
| 技能/动作 | 一个语音应用,可以实现一系列意图 |
| 意图 | 技能实现的预期操作,用户希望技能做什么以响应他们所说的内容。 |
| 发声 | 用户说或说出的句子。 |
| 唤醒词 | 用于启动语音助手收听的单词或短语,例如“Hey google”、“Alexa”或“Hey Siri” |
| 语境 | 话语中有助于技能实现意图的上下文信息片段,例如“今天”、“现在”、“当我到家时”。 |
什么是语音助手?
语音助手是一款能够进行 NLP(自然语言处理)的软件。 它接收语音命令并以音频格式返回答案。 近年来,与助手互动的范围正在扩大和发展,但技术的关键是自然语言输入、大量计算、自然语言输出。
对于那些寻找更多细节的人:
- 该软件接收来自用户的音频请求,将声音处理成音素,即语言的组成部分。
- 通过 AI(特别是 Speech-To-Text)的魔力,这些音素被转换为近似请求的字符串,保存在 JSON 文件中,该文件还包含有关用户、请求和会话的额外信息。
- 然后处理 JSON(通常在云中)以计算出请求的上下文和意图。
- 根据意图,再次在更大的 JSON 响应中返回响应,以字符串或 SSML 的形式(稍后会详细介绍)
- 使用 AI(自然是反向 - Text-To-Speech)处理响应,然后将其返回给用户。
那里发生了很多事情,其中大部分都不需要再三考虑。 但是每个平台都以不同的方式执行此操作,并且需要更多了解的是平台的细微差别。

支持语音的设备
设备能够内置语音助手的要求非常低。 它们需要麦克风、互联网连接和扬声器。 Nest Mini 和 Echo Dot 等智能扬声器提供了这种低保真语音控制。
排在第二位的是语音+屏幕,这被称为“多模式”设备(稍后会详细介绍),并且是 Nest Hub 和 Echo Show 等设备。 由于智能手机具有此功能,因此它们也可以被视为一种支持多模式语音的设备。
语音技巧
首先,每个平台的“语音技能”都有不同的名称,亚马逊使用技能,我将坚持作为一个普遍理解的术语。 谷歌选择“行动”,三星选择“胶囊”。
每个平台都有自己的内置技能,比如询问时间、天气和体育比赛。 开发人员制造的(第三方)技能可以使用特定的短语来调用,或者,如果平台喜欢它,可以隐式调用,而无需关键短语。
显式调用:“Hey Google,与 <app name> 交谈。”
明确说明了要求的技能:
隐式调用:“嘿 Google,今天天气怎么样?”
请求的上下文暗示了用户想要什么服务。
有哪些语音助手?
在西方市场,语音助手更像是一场三马赛跑。 苹果、谷歌和亚马逊对他们的助手有非常不同的方法,因此吸引了不同类型的开发者和客户。
苹果的 Siri
设备名称:“Siri”
唤醒短语:“嘿 Siri”
Siri 拥有超过 3.75 亿活跃用户,但为了简洁起见,我不会对 Siri 进行太多详细介绍。 虽然它可能在全球范围内得到很好的采用,并融入了大多数 Apple 设备,但它要求开发人员已经在 Apple 的一个平台上拥有一个应用程序,并且是用 swift 编写的(而其他的可以用每个人都喜欢的:Javascript 编写)。 除非您是想要扩展其应用程序产品的应用程序开发人员,否则您目前可以跳过苹果,直到他们打开他们的平台。
谷歌助理
设备名称:“Google Home、Nest”
唤醒短语:“嘿谷歌”
谷歌拥有三巨头中最多的设备,全球超过 10 亿台,这主要是由于大量 Android 设备内置了谷歌助手,就其专用的智能扬声器而言,数量略小一些。 谷歌助手的总体使命是取悦用户,他们一直非常擅长提供轻巧直观的界面。
他们在平台上的主要目标是利用时间——希望成为客户日常生活的一部分。 因此,他们主要关注实用性、家庭乐趣和令人愉快的体验。
为 Google 打造的技能在参与作品和游戏时是最好的,主要关注家庭友好的乐趣。 他们最近为游戏添加的画布就是这种方法的证明。 谷歌平台对技能的提交要严格得多,因此他们的目录要小得多。
亚马逊亚历克斯
设备名称:“Amazon Fire、Amazon Echo”
唤醒短语:“Alexa”
亚马逊在 2019 年的设备数量已超过 1 亿台,这主要来自其智能扬声器和智能显示器的销售,以及他们的“火”系列或平板电脑和流媒体设备。
为亚马逊打造的技能往往针对技能购买。 如果您正在寻找一个平台来扩展您的电子商务/服务或提供订阅服务,那么亚马逊就是您的不二之选。 话虽这么说,ISP 不是 Alexa Skills 的要求,它们支持各种用途,并且对提交更加开放。
其他
还有更多的语音助手,例如三星的 Bixby、微软的 Cortana 和流行的开源语音助手 Mycroft。 这三者都有合理的追随者,但与亚马逊、谷歌和苹果这三巨头相比,仍然是少数。
建立在亚马逊 Alexa 上
亚马逊语音生态系统已经发展到允许开发人员在 Alexa 控制台内构建他们的所有技能,所以作为一个简单的例子,我将使用它的内置功能。
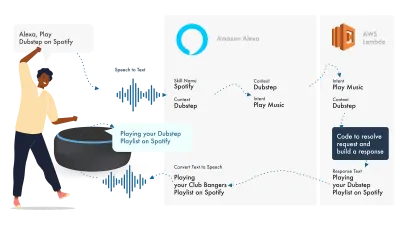
Alexa 处理自然语言处理,然后找到合适的 Intent,将其传递给我们的 Lambda 函数来处理逻辑。 这会将一些对话位(SSML、文本、卡片等)返回给 Alexa,Alexa 会将这些位转换为音频和视频以显示在设备上。
在亚马逊上工作相对简单,因为它们允许您在 Alexa 开发人员控制台中创建您的所有技能部分。 使用 AWS 或 HTTPS 端点具有灵活性,但对于简单的技能,在开发控制台中运行所有内容就足够了。
让我们建立一个简单的 Alexa 技能
前往 Amazon Alexa 控制台,如果您没有帐户,请创建一个帐户,然后登录,
点击Create Skill然后给它一个名字,
选择custom作为您的模型,
并为您的后端资源选择Alexa-Hosted (Node.js) 。
完成配置后,您将拥有基本的 Alexa 技能,它将为您构建您的意图,以及一些帮助您入门的后端代码。
如果您单击 Intents 中的HelloWorldIntent ,您将看到一些已经为您设置的示例话语,让我们在顶部添加一个新示例。 我们的技能称为 hello world,因此添加 Hello World 作为示例话语。 这个想法是捕捉用户可能会说的任何内容来触发这个意图。 这可能是“Hi World”、“Howdy World”等。
Fulfillment JS 中发生了什么?
那么代码在做什么呢? 这是默认代码:
const HelloWorldIntentHandler = { canHandle(handlerInput) { return Alexa.getRequestType(handlerInput.requestEnvelope) === 'IntentRequest' && Alexa.getIntentName(handlerInput.requestEnvelope) === 'HelloWorldIntent'; }, handle(handlerInput) { const speakOutput = 'Hello World!'; return handlerInput.responseBuilder .speak(speakOutput) .getResponse(); } }; 这是利用ask-sdk-core ,本质上是为我们构建 JSON。 canHandle让 ask 知道它可以处理意图,特别是“HelloWorldIntent”。 handle接受输入,并构建响应。 这生成的内容如下所示:
{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }
我们可以在我们的 json 中看到speak输出 ssml,这是用户将听到的 Alexa 所说的内容。

为 Google 助理构建
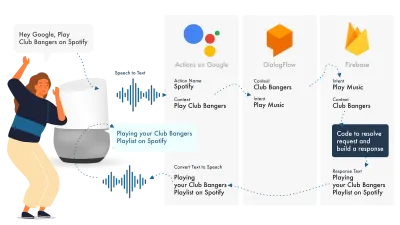
在 Google 上构建 Actions 的最简单方法是将其 AoG 控制台与 Dialogflow 结合使用,您可以使用 firebase 扩展您的技能,但与 Amazon Alexa 教程一样,让我们保持简单。
Google Assistant 使用三个主要部分,AoG 处理 NLP,Dialogflow 处理你的意图,Firebase 满足请求并产生将发送回 AoG 的响应。
与 Alexa 一样,Dialogflow 允许您直接在平台内构建函数。
让我们在 Google 上建立行动
Google 的解决方案可以同时使用三个平台,它们可以通过三个不同的控制台访问,所以请注意!
设置对话流
让我们从登录 Dialogflow 控制台开始。 登录后,从 Dialogflow 徽标正下方的下拉列表中创建一个新代理。
为您的代理命名,并添加“Google Project Dropdown”,同时选择“Create a new Google project”。
点击创建按钮,让它发挥它的魔力,设置代理需要一点时间,所以请耐心等待。
设置 Firebase 函数
好了,现在我们可以开始插入 Fulfillment 逻辑了。
前往履行选项卡。 勾选启用内联编辑器,并使用下面的 JS 片段:
index.js
'use strict'; // So that you have access to the dialogflow and conversation object const { dialogflow } = require('actions-on-google'); // So you have access to the request response stuff >> functions.https.onRequest(app) const functions = require('firebase-functions'); // Create an instance of dialogflow for your app const app = dialogflow({debug: true}); // Build an intent to be fulfilled by firebase, // the name is the name of the intent that dialogflow passes over app.intent('Default Welcome Intent', (conv) => { // Any extra logic goes here for the intent, before returning a response for firebase to deal with return conv.ask(`Welcome to a firebase fulfillment`); }); // Finally we export as dialogflowFirebaseFulfillment so the inline editor knows to use it exports.dialogflowFirebaseFulfillment = functions.https.onRequest(app);包.json
{ "name": "functions", "description": "Cloud Functions for Firebase", "scripts": { "lint": "eslint .", "serve": "firebase serve --only functions", "shell": "firebase functions:shell", "start": "npm run shell", "deploy": "firebase deploy --only functions", "logs": "firebase functions:log" }, "engines": { "node": "10" }, "dependencies": { "actions-on-google": "^2.12.0", "firebase-admin": "~7.0.0", "firebase-functions": "^3.3.0" }, "devDependencies": { "eslint": "^5.12.0", "eslint-plugin-promise": "^4.0.1", "firebase-functions-test": "^0.1.6" }, "private": true }现在回到您的意图,转到默认欢迎意图,然后向下滚动到实现,确保选中“为此意图启用 webhook 调用”以查看您希望使用 javascript 实现的任何意图。 点击保存。
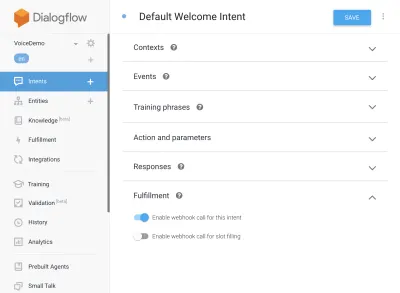
设置 AoG
我们现在正在接近终点线。 转到集成选项卡,然后单击顶部 Google 助理选项中的集成设置。 这将打开一个模式,所以让我们点击测试,这将使您的 Dialogflow 与 Google 集成,并在 Google 上的 Actions 上打开一个测试窗口。
在测试窗口上,我们可以单击与我的测试应用程序交谈(我们将在一秒钟内更改它),瞧,我们的 javascript 消息显示在谷歌助手测试中。
我们可以在顶部的“开发”选项卡中更改助手的名称。
那么在 Fulfillment JS 中发生了什么?
首先,我们使用了两个 npm 包,actions-on-google,它提供了 AoG 和 Dialogflow 所需的所有功能,其次是 firebase-functions,你猜对了,它包含 firebase 的帮助程序。
然后我们创建“app”,它是一个包含我们所有意图的对象。
创建的每个意图都传递了“conv”,它是 Google 上的 Actions 发送的对话对象。 我们可以使用 conv 的内容来检测有关先前与用户交互的信息(例如他们的 ID 和有关他们与我们的会话的信息)。
我们返回一个“conv.ask 对象”,其中包含我们给用户的返回消息,准备好让他们以另一个意图进行响应。 如果我们想在那里结束对话,我们可以使用“conv.close”来结束对话。
最后,我们将所有内容封装在一个 firebase HTTPS 函数中,该函数为我们处理服务器端请求-响应逻辑。
同样,如果我们查看生成的响应:
{ "payload": { "google": { "expectUserResponse": true, "richResponse": { "items": [ { "simpleResponse": { "textToSpeech": "Welcome to a firebase fulfillment" } } ] } } } } 我们可以看到conv.ask已将其文本注入到textToSpeech区域。 如果我们选择了conv.close , expectUserResponse将设置为false ,并且在消息传递后对话将关闭。
第三方语音生成器
就像应用程序行业一样,随着语音越来越受欢迎,第 3 方工具已经开始出现,试图减轻开发人员的负担,允许他们构建一次部署两次。
Jovo 和 Voiceflow 是目前最受欢迎的两个,尤其是在 PullString 被 Apple 收购之后。 每个平台都提供了不同级别的抽象,所以这真的取决于你对界面的简化程度。
扩展你的技能
现在您已经开始了解如何构建基本的“Hello World”技能,可以为您的技能添加大量的花里胡哨。 这些是语音助手蛋糕上的樱桃,将为您的用户带来很多额外价值,从而带来重复定制和潜在的商业机会。
SSML
SSML 代表语音合成标记语言,使用与 HTML 类似的语法运行,主要区别在于您正在构建语音响应,而不是网页上的内容。
'SSML' 作为一个术语有点误导,它可以做的不仅仅是语音合成! 你可以让声音并行,你可以包括环境噪音、speechcons(值得一听,想想著名短语的表情符号)和音乐。
什么时候应该使用 SSML?
SSML 很棒; 它为用户提供了更具吸引力的体验,但同时也降低了音频输出的灵活性。 我建议将它用于更静态的语音区域。 您可以将其中的变量用于名称等,但除非您打算构建 SSML 生成器,否则大多数 SSML 将是相当静态的。
从您的技能中的简单演讲开始,一旦完成,使用 SSML 增强更静态的区域,但在继续花里胡哨之前先让您的核心正确。 话虽如此,最近的一份报告称 71% 的用户更喜欢人类(真实)声音而不是合成声音,所以如果你有能力这样做,那就去做吧!

在技能购买中
技能内购买(或 ISP)类似于应用内购买的概念。 技能往往是免费的,但有些技能允许在应用程序内购买“高级”内容/订阅,这些可以增强用户体验、解锁游戏新关卡或允许访问付费内容。
多式联运
多模式响应所涵盖的范围远不止语音,这就是语音助手可以在支持它们的设备上以互补的视觉效果真正闪耀的地方。 多模式体验的定义要广泛得多,本质上意味着多种输入(键盘、鼠标、触摸屏、语音等)。
多模式技能旨在补充核心语音体验,提供额外的补充信息以提升用户体验。 在构建多模式体验时,请记住语音是信息的主要载体。 许多设备没有屏幕,因此您的技能仍然需要在没有屏幕的情况下发挥作用,因此请确保使用多种设备类型进行测试; 无论是真实的还是在模拟器中。

多种语言
多语言技能是可以使用多种语言并将您的技能打开到多个市场的技能。
使你的技能多语言的复杂性取决于你的反应有多动态。 具有相对静态响应的技能,例如每次返回相同的短语,或者只使用一小部分短语,比庞大的动态技能更容易制作多语言。
多语种的诀窍是拥有一个值得信赖的翻译合作伙伴,无论是通过代理商还是 Fiverr 上的翻译。 您需要能够信任所提供的翻译,特别是如果您不理解被翻译成的语言。 谷歌翻译不会在这里减少芥末!
结论
如果有时间进入语音行业,那就是现在。 无论是处于鼎盛时期还是处于起步阶段,以及九大巨头,都在投入数十亿美元来发展它,并将语音助手带入每个人的家中和日常生活中。
选择要使用的平台可能很棘手,但根据您打算构建的内容,要使用的平台应该大放异彩,否则,使用第三方工具来对冲您的赌注并在多个平台上构建,特别是如果您的技能运动部件更少,复杂度更低。
一方面,我对语音无处不在的未来感到兴奋。 屏幕依赖将减少,客户将能够与他们的助手自然互动。 但首先,我们要培养人们希望从助手那里获得的技能。