
了解 TypeScript 泛型
已发表: 2022-03-10在本文中,我们将学习 TypeScript 中泛型的概念,并研究如何使用泛型来编写模块化、解耦和可重用的代码。 在此过程中,我们将简要讨论它们如何适应更好的测试模式、错误处理方法和域/数据访问分离。
一个真实的例子
我不想通过解释它们是什么来进入泛型的世界,而是通过提供一个直观的例子来说明它们为什么有用。 假设您的任务是构建一个功能丰富的动态列表。 您可以将其称为数组、 ArrayList 、 List 、 std::vector或其他名称,具体取决于您的语言背景。 也许这个数据结构也必须有内置或可交换的缓冲区系统(如循环缓冲区插入选项)。 它将是普通 JavaScript 数组的包装器,以便我们可以使用我们的结构而不是普通数组。
您将遇到的直接问题是类型系统施加的约束。 在这一点上,你不能以一种干净利落的方式接受你想要的任何类型到函数或方法中(我们稍后会重新讨论这个语句)。
唯一明显的解决方案是为所有不同类型复制我们的数据结构:
const intList = IntegerList.create(); intList.add(4); const stringList = StringList.create(); stringList.add('hello'); const userList = UserList.create(); userList.add(new User('Jamie')); 这里的.create()语法可能看起来很随意,实际上, new SomethingList()会更直接,但稍后您会看到我们为什么使用这个静态工厂方法。 在内部, create方法调用构造函数。
这真糟糕。 我们在这个集合结构中有很多逻辑,我们公然复制它来支持不同的用例,在这个过程中完全打破了 DRY 原则。 当我们决定更改我们的实现时,我们将不得不在我们支持的所有结构和类型(包括用户定义的类型)中手动传播/反映这些更改,如上面的后一个示例所示。 假设集合结构本身有 100 行长——维护多个不同的实现,而它们之间的唯一区别是类型,这将是一场噩梦。
如果您愿意,可能会想到一个直接的解决方案,尤其是如果您有 OOP 思维方式,那就是考虑一个根“超类型”。 例如,在 C# 中,有一个名为object的类型,而object是System.Object类的别名。 在 C# 的类型系统中,所有类型,无论是预定义的还是用户定义的,无论是引用类型还是值类型,都直接或间接地从System.Object继承。 这意味着任何值都可以分配给object类型的变量(无需进入堆栈/堆和装箱/拆箱语义)。
在这种情况下,我们的问题似乎解决了。 我们可以只使用any这样的类型,这将允许我们在集合中存储我们想要的任何东西,而不必复制结构,事实上,这是非常正确的:
const intList = AnyList.create(); intList.add(4); const stringList = AnyList.create(); stringList.add('hello'); const userList = AnyList.create(); userList.add(new User('Jamie')); 让我们看看使用any的列表的实际实现:
class AnyList { private values: any[] = []; private constructor (values: any[]) { this.values = values; // Some more construction work. } public add(value: any): void { this.values.push(value); } public where(predicate: (value: any) => boolean): AnyList { return AnyList.from(this.values.filter(predicate)); } public select(selector: (value: any) => any): AnyList { return AnyList.from(this.values.map(selector)); } public toArray(): any[] { return this.values; } public static from(values: any[]): AnyList { // Perhaps we perform some logic here. // ... return new AnyList(values); } public static create(values?: any[]): AnyList { return new AnyList(values ?? []); } // Other collection functions. // ... }所有方法都比较简单,但我们将从构造函数开始。 它的可见性是私有的,因为我们假设我们的列表很复杂并且我们希望禁止任意构造。 我们也可能希望在构造之前执行逻辑,因此出于这些原因,并且为了保持构造函数的纯净,我们将这些问题委托给静态工厂/辅助方法,这被认为是一种很好的做法。
提供了from和create的静态方法。 from方法接受一个值数组,执行自定义逻辑,然后使用它们来构造列表。 如果我们想用初始数据为我们的列表播种, create静态方法采用一个可选的值数组。 “空值合并运算符”( ?? )用于在未提供空数组的情况下使用空数组构造列表。 如果操作数的左侧是null或undefined ,我们将退回到右侧,因为在这种情况下, values是可选的,因此可能是undefined 。 您可以在相关的 TypeScript 文档页面了解更多关于空值合并的信息。
我还添加了一个select和一个where方法。 这些方法只是分别包装了 JavaScript 的map和filter 。 select允许我们根据提供的选择器函数将元素数组投影到新形式中,并且where允许我们根据提供的谓词函数过滤掉某些元素。 toArray方法通过返回我们内部保存的数组引用简单地将列表转换为数组。
最后,假设User类包含一个getName方法,该方法返回一个名称并接受一个名称作为其第一个也是唯一的构造函数参数。
注意:一些读者会从 C# 的 LINQ 中识别Where和Select,但请记住,我试图保持简单,因此我不担心懒惰或延迟执行。 这些是可以而且应该在现实生活中进行的优化。
此外,作为一个有趣的注释,我想讨论“谓词”的含义。 在离散数学和命题逻辑中,我们有“命题”的概念。 命题是一些可以被认为是真或假的陈述,例如“四可被二整除”。 “谓词”是包含一个或多个变量的命题,因此命题的真实性取决于这些变量的真实性。 你可以把它想象成一个函数,比如P(x) = x is divisible by two,因为我们需要知道x的值来判断语句的真假。 您可以在此处了解有关谓词逻辑的更多信息。
使用any会出现一些问题。 TypeScript 编译器对列表/内部数组中的元素一无所知,因此它不会在where或select或添加元素时提供任何帮助:
// Providing seed data. const userList = AnyList.create([new User('Jamie')]); // This is fine and expected. userList.add(new User('Tom')); userList.add(new User('Alice')); // This is an acceptable input to the TS Compiler, // but it's not what we want. We'll definitely // be surprised later to find strings in a list // of users. userList.add('Hello, World!'); // Also acceptable. We have a large tuple // at this point rather than a homogeneous array. userList.add(0); // This compiles just fine despite the spelling mistake (extra 's'): // The type of `users` is any. const users = userList.where(user => user.getNames() === 'Jamie'); // Property `ssn` doesn't even exist on a `user`, yet it compiles. users.toArray()[0].ssn = '000000000'; // `usersWithId` is, again, just `any`. const usersWithId = userList.select(user => ({ id: newUuid(), name: user.getName() })); // Oops, it's "id" not "ID", but TS doesn't help us. // We compile just fine. console.log(usersWithId.toArray()[0].ID); 由于 TypeScript 只知道所有数组元素的类型是any ,因此它在编译时无法帮助我们处理不存在的属性或甚至不存在的getNames函数,因此此代码将导致多个意外的运行时错误.
老实说,事情开始看起来相当惨淡。 我们尝试为我们希望支持的每种具体类型实现我们的数据结构,但我们很快意识到这无论如何都无法维护。 然后,我们认为通过使用any可以到达某个地方,这类似于依赖于所有类型派生自的继承链中的根超类型,但我们得出结论,使用该方法我们失去了类型安全性。 那有什么解决办法?
事实证明,在文章的开头,我撒了谎(有点):
“在这一点上,你不能以一种干净利落的方式接受你想要的任何类型到函数或方法中。”
你实际上可以,这就是泛型的用武之地。注意我说的是“此时”,因为我假设我们在文章中的那个时候不知道泛型。
我将首先展示我们使用泛型的 List 结构的完整实现,然后我们将退后一步,讨论它们实际上是什么,并更正式地确定它们的语法。 我将其命名为TypedList以区别于我们之前的AnyList :
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T): void { this.values.push(value); } public where(predicate: (value: T) => boolean): TypedList<T> { return TypedList.from<T>(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U): TypedList<U> { return TypedList.from<U>(this.values.map(selector)); } public toArray(): T[] { return this.values; } public static from<U>(values: U[]): TypedList<U> { // Perhaps we perform some logic here. // ... return new TypedList<U>(values); } public static create<U>(values?: U[]): TypedList<U> { return new TypedList<U>(values ?? []); } // Other collection functions. // .. }让我们再次尝试犯与之前相同的错误:
// Here's the magic. `TypedList` will operate on objects // of type `User` due to the `<User>` syntax. const userList = TypedList.create<User>([new User('Jamie')]); // The compiler expects this. userList.add(new User('Tom')); userList.add(new User('Alice')); // Argument of type '0' is not assignable to parameter // of type 'User'. ts(2345) userList.add(0); // Property 'getNames' does not exist on type 'User'. // Did you mean 'getName'? ts(2551) // Note: TypeScript infers the type of `users` to be // `TypedList<User>` const users = userList.where(user => user.getNames() === 'Jamie'); // Property 'ssn' does not exist on type 'User'. ts(2339) users.toArray()[0].ssn = '000000000'; // TypeScript infers `usersWithId` to be of type // `TypedList<`{ id: string, name: string }> const usersWithId = userList.select(user => ({ id: newUuid(), name: user.getName() })); // Property 'ID' does not exist on type '{ id: string; name: string; }'. // Did you mean 'id'? ts(2551) console.log(usersWithId.toArray()[0].ID)如您所见,TypeScript 编译器正在积极地帮助我们实现类型安全。 所有这些注释都是我在尝试编译此代码时从编译器收到的错误。 泛型允许我们指定我们希望允许我们的列表对其进行操作的类型,并且从那里,TypeScript 可以告诉一切的类型,一直到数组中各个对象的属性。
我们提供的类型可以像我们希望的那样简单或复杂。 在这里,您可以看到我们可以传递原语和复杂接口。 我们还可以传递其他数组、类或任何东西:
const numberList = TypedList.create<number>(); numberList.add(4); const stringList = TypedList.create<string>(); stringList.add('Hello, World'); // Example of a complex type interface IAircraft { apuStatus: ApuStatus; inboardOneRPM: number; altimeter: number; tcasAlert: boolean; pushBackAndStart(): Promise<void>; ilsCaptureGlidescope(): boolean; getFuelStats(): IFuelStats; getTCASHistory(): ITCASHistory; } const aircraftList = TypedList.create<IAircraft>(); aircraftList.add(/* ... */); // Aggregate and generate report: const stats = aircraftList.select(a => ({ ...a.getFuelStats(), ...a.getTCASHistory() })); TypedList<T>实现中T和U以及<T>和<U>的特殊用途是泛型的实际应用示例。 在完成了构建类型安全集合结构的指令之后,我们暂时将这个示例抛在脑后,一旦我们了解泛型实际上是什么、它们如何工作以及它们的语法,我们将回到它。 当我学习一个新概念时,我总是喜欢先看一个正在使用的概念的复杂示例,这样当我开始学习基础知识时,我可以将基本主题与我现有的示例联系起来头。
什么是泛型?
理解泛型的一种简单方法是将它们视为相对类似于占位符或变量,但用于类型。 这并不是说您可以对泛型类型占位符执行与变量相同的操作,而是可以将泛型类型变量视为表示将来使用的具体类型的占位符。 也就是说,使用泛型是一种根据稍后指定的类型编写程序的方法。 这很有用的原因是因为它允许我们构建可在它们操作的不同类型(或与类型无关)上重用的数据结构。
这并不是最好的解释,所以用更简单的术语来说,正如我们所见,在编程中我们可能需要构建一个函数/类/数据结构来操作某种类型是很常见的,但是同样常见的是,这样的数据结构也需要在各种不同的类型上工作。 如果我们在设计数据结构时(在编译时)陷入必须静态声明数据结构将在其上运行的具体类型的位置,我们很快就会发现我们需要重建那些正如我们在上面的示例中所见,我们希望支持的每种类型都以几乎完全相同的方式构建结构。
泛型通过允许我们推迟对具体类型的需求直到它真正被知道来帮助我们解决这个问题。
TypeScript 中的泛型
对于泛型为什么有用,我们现在有了一些基本的想法,并且我们已经在实践中看到了一个稍微复杂的例子。 对于大多数人来说, TypedList<T>实现可能已经很有意义了,特别是如果你来自静态类型语言背景,但我记得当我第一次学习时很难理解这个概念,因此我想从简单的函数开始构建该示例。 众所周知,与软件中的抽象相关的概念很难内化,所以如果泛型的概念还没有完全流行,那完全没问题,希望在本文结束时,这个想法至少会有点直观。
为了能够理解该示例,让我们从简单的函数开始。 我们将从“身份函数”开始,这是大多数文章(包括 TypeScript 文档本身)都喜欢使用的。
在数学中,“恒等函数”是一个将其输入直接映射到其输出的函数,例如f(x) = x 。 你投入什么,你就会得到什么。 在 JavaScript 中,我们可以将其表示为:
function identity(input) { return input; }或者,更简洁:
const identity = input => input; 尝试将其移植到 TypeScript 会带来我们之前看到的相同类型系统问题。 解决方案是使用any键入,我们知道这很少是一个好主意,为每种类型复制/重载函数(破坏 DRY),或使用泛型。
使用后一种选项,我们可以将函数表示如下:
// ES5 Function function identity<T>(input: T): T { return input; } // Arrow Function const identity = <T>(input: T): T => input; console.log(identity<number>(5)); // 5 console.log(identity<string>('hello')); // hello 此处的<T>语法将此函数声明为 Generic。 就像函数允许我们将任意输入参数传递到其参数列表中一样,使用通用函数,我们也可以传递任意类型参数。
identity<T>(input: T): T和<T>(input: T): T的签名的<T>部分在这两种情况下都声明所讨论的函数将接受一个名为T的泛型类型参数。 就像变量可以是任何名称一样,我们的通用占位符也可以,但使用大写字母“T”(“T”表示“类型”)并根据需要向下移动字母表是一种惯例。 请记住, T是一种类型,因此我们还声明我们将接受一个类型为T的名称input的函数参数,并且我们的函数将返回类型T 。 这就是签名的全部内容。 尝试让T = string在你的脑海中 - 用这些签名中的string替换所有T 。 看到所有神奇的事情都没有发生吗? 看看它与您每天使用函数的非泛型方式有多相似?
请记住您对 TypeScript 和函数签名的了解。 我们所说的只是T是用户在调用函数时将提供的任意类型,就像input是用户在调用函数时将提供的任意值一样。 在这种情况下, input必须是将来调用函数时T的任何类型。
接下来,在“未来”中,在两个日志语句中,我们“传入”我们希望使用的具体类型,就像我们做一个变量一样。 注意这里的措辞开关——在<T> signature的初始形式中,当声明我们的函数时,它是泛型的——也就是说,它适用于泛型类型,或者稍后指定的类型。 那是因为当我们实际编写函数时,我们不知道调用者希望使用什么类型。 但是,当调用者调用该函数时,他/她确切地知道他们想要使用什么类型,在这种情况下是string和number 。
您可以想象在第三方库中以这种方式声明日志函数的想法——库作者不知道使用该库的开发人员会想要使用什么类型,所以他们使函数通用,本质上推迟了需求对于具体类型,直到它们真正为人所知。
我想强调的是,您应该以类似于将变量传递给函数的概念来考虑这个过程,以便获得更直观的理解。 我们现在所做的只是传递一个类型。
在我们使用number参数调用函数时,出于所有意图和目的,原始签名可以被认为是identity(input: number): number 。 而且,在我们使用string参数调用函数时,原始签名也可能是identity(input: string): string 。 您可以想象,在进行调用时,每个泛型T都会被您当时提供的具体类型替换。
探索通用语法
在 ES5 函数、箭头函数、类型别名、接口和类的上下文中指定泛型有不同的语法和语义。 我们将在本节中探讨这些差异。
探索通用语法——函数
到目前为止,您已经看到了一些泛型函数的示例,但重要的是要注意泛型函数可以接受多个泛型类型参数,就像它可以接受变量一样。 您可以选择要求一种、两种、三种或多种类型,全部用逗号分隔(同样,就像输入参数一样)。
此函数接受三种输入类型并随机返回其中一种:
function randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V { // This is a tuple if you're not familiar. const options: [T, U, V] = [ one, two, three ]; const rndNum = getRndNumInInclusiveRange(0, 2); return options[rndNum]; } // Calling the function. // `value` has type `string | number | IAircraft` const value = randomValue< string, number, IAircraft >( myString, myNumber, myAircraft );您还可以看到,根据我们使用的是 ES5 函数还是箭头函数,语法略有不同,但两者都在签名中声明了类型参数:
const randomValue = <T, U, V>( one: T, two: U, three: V ): T | U | V => { // This is a tuple if you're not familiar. const options: [T, U, V] = [ one, two, three ]; const rndNum = getRndNumInInclusiveRange(0, 2); return options[rndNum]; } 请记住,类型没有“唯一性约束”——您可以传入任何您希望的组合,例如两个string和一个number 。 此外,就像输入参数在函数体的“范围内”一样,泛型类型参数也是如此。 前一个示例表明我们可以从函数体内完全访问T 、 U和V ,并且我们使用它们来声明一个本地 3 元组。
您可以想象这些泛型在某个“上下文”或某个“生命周期”内运行,这取决于它们的声明位置。 函数的泛型在函数签名和主体(以及由嵌套函数创建的闭包)的范围内,而在类或接口或类型别名上声明的泛型在类或接口或类型别名的所有成员的范围内。
函数泛型的概念不仅限于“自由函数”或“浮动函数”(不附加到对象或类的函数,一个 C++ 术语),它们也可以用于附加到其他结构的函数。
我们可以将该randomValue放在一个类中,我们可以这样称呼它:
class Utils { public randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V { // ... } // Or, as an arrow function: public randomValue = <T, U, V>( one: T, two: U, three: V ): T | U | V => { // ... } }我们还可以在接口中放置一个定义:
interface IUtils { randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V; }或者在类型别名中:
type Utils = { randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V; }就像以前一样,这些泛型类型参数在特定函数的“范围内”——它们不是类、接口或类型别名范围的。 它们只存在于指定它们的特定功能中。 要在结构的所有成员之间共享泛型类型,您必须注释结构的名称本身,我们将在下面看到。
探索通用语法——类型别名
对于类型别名,通用语法用于别名的名称。
例如,一些接受值的“动作”函数可能会改变该值,但返回 void 可以写成:
type Action<T> = (val: T) => void;注意:了解 Action<T> 委托的 C# 开发人员应该熟悉这一点。
或者,可以这样声明一个同时接受错误和值的回调函数:
type CallbackFunction<T> = (err: Error, data: T) => void; const usersApi = { get(uri: string, cb: CallbackFunction<User>) { /// ... } }凭借我们对函数泛型的了解,我们可以更进一步,使 API 对象上的函数也泛型:
type CallbackFunction<T> = (err: Error, data: T) => void; const api = { // `T` is available for use within this function. get<T>(uri: string, cb: CallbackFunction<T>) { /// ... } } 现在,我们说get函数接受一些泛型类型参数,不管是什么, CallbackFunction都会接收它。 我们基本上已经“传递”了进入get的T作为CallbackFunction的T 如果我们更改名称,也许这会更有意义:
type CallbackFunction<TData> = (err: Error, data: TData) => void; const api = { get<TResponse>(uri: string, cb: CallbackFunction<TResponse>) { // ... } } 使用T前缀类型参数只是一种约定,就像使用I前缀接口或使用_成员变量一样。 您可以在此处看到CallbackFunction接受某种类型 ( TData ),该类型表示函数可用的数据负载,而get接受表示 HTTP 响应数据类型/形状 ( TResponse ) 的类型参数。 HTTP 客户端 ( api ) 与 Axios 类似,使用TResponse的任何内容作为CallbackFunction的TData 。 这允许 API 调用者选择他们将从 API 接收的数据类型(假设管道中的其他地方我们有将 JSON 解析为 DTO 的中间件)。
如果我们想更进一步,我们可以修改CallbackFunction上的泛型类型参数以接受自定义错误类型:
type CallbackFunction<TData, TError> = (err: TError, data: TData) => void;而且,就像您可以将函数参数设为可选一样,您也可以使用类型参数。 如果用户没有提供错误类型,我们将默认将其设置为错误构造函数:
type CallbackFunction<TData, TError = Error> = (err: TError, data: TData) => void;有了这个,我们现在可以通过多种方式指定回调函数类型:
const apiOne = { // `Error` is used by default for `CallbackFunction`. get<TResponse>(uri: string, cb: CallbackFunction<TResponse>) { // ... } }; apiOne.get<string>('uri', (err: Error, data: string) => { // ... }); const apiTwo = { // Override the default and use `HttpError` instead. get<TResponse>(uri: string, cb: CallbackFunction<TResponse, HttpError>) { // ... } }; apiTwo.get<string>('uri', (err: HttpError, data: string) => { // ... });这种默认参数的想法在函数、类、接口等中是可以接受的——它不仅限于类型别名。 在到目前为止我们看到的所有示例中,我们可以将任何我们想要的类型参数分配给默认值。 类型别名,就像函数一样,可以使用任意数量的泛型类型参数。
探索通用语法——接口
如您所见,可以将泛型类型参数提供给接口上的函数:
interface IUselessFunctions { // Not generic printHelloWorld(); // Generic identity<T>(t: T): T; } 在这种情况下, T只存在于作为其输入和返回类型的identity等函数。
我们还可以通过指定接口本身接受泛型来使接口的所有成员都可以使用类型参数,就像类和类型别名一样。 我们稍后会在讨论更复杂的泛型用例时讨论存储库模式,所以如果您从未听说过它也没关系。 存储库模式允许我们抽象出我们的数据存储,以使业务逻辑与持久性无关。 如果您希望创建一个对未知实体类型进行操作的通用存储库接口,我们可以将其键入如下:
interface IRepository<T> { add(entity: T): Promise<void>; findById(id: string): Promise<T>; updateById(id: string, updated: T): Promise<void>; removeById(id: string): Promise<void>; }注意:关于存储库有很多不同的想法,从 Martin Fowler 的定义到 DDD 聚合定义。 我只是试图展示泛型的用例,所以我不太关心在实现方面是否完全正确。 不使用通用存储库肯定有话要说,但我们稍后会讨论。
正如您在此处看到的, IRepository是一个接口,其中包含用于存储和检索数据的方法。 它对一些名为T的泛型类型参数进行操作,并将T作为add和updateById的输入,以及findById的 promise 解析结果。
请记住,在接口名称上接受泛型类型参数与允许每个函数本身接受泛型类型参数之间存在很大差异。 正如我们在这里所做的那样,前者确保接口中的每个函数都在相同的类型T上运行。 也就是说,对于IRepository<User> ,接口中使用T的每个方法现在都在处理User对象。 使用后一种方法,每个函数都可以使用它想要的任何类型。 例如,只能将User添加到 Repository 但能够接收回Policies或Orders将是非常特殊的,如果我们无法强制类型为在所有方法中统一。
给定的接口不仅可以包含共享类型,还可以包含其成员独有的类型。 例如,如果我们想模拟一个数组,我们可以输入这样的接口:
interface IArray<T> { forEach(func: (elem: T, index: number) => void): this; map<U>(func: (elem: T, index: number) => U): IArray<U>; } 在这种情况下, forEach和map都可以从接口名称访问T 如前所述,您可以想象T在接口的所有成员的范围内。 尽管如此,没有什么能阻止其中的各个函数也接受它们自己的类型参数。 map函数可以使用U 。 现在, map可以访问T和U 。 我们必须将参数命名为不同的字母,例如U ,因为T已经被采用,我们不希望命名冲突。 就像它的名字一样, map会将数组中T类型的元素“映射”到U类型的新元素。 它将T s 映射到U s。 这个函数的返回值是接口本身,现在在新类型U上运行,这样我们就可以在某种程度上模仿 JavaScript 流畅的数组链式语法。
当我们实现存储库模式并讨论依赖注入时,我们将很快看到泛型和接口的强大示例。 再一次,我们可以接受尽可能多的通用参数,也可以选择一个或多个堆叠在接口末尾的默认参数。
探索通用语法——类
就像我们可以将泛型类型参数传递给类型别名、函数或接口一样,我们也可以将一个或多个传递给类。 这样做后,该类的所有成员以及扩展的基类或实现的接口都可以访问该类型参数。
让我们再构建一个集合类,但比上面的TypedList简单一点,这样我们就可以看到泛型类型、接口和成员之间的互操作。 稍后我们将看到一个将类型传递给基类和接口继承的示例。
除了map和forEach方法之外,我们的集合将仅支持基本的 CRUD 功能。
class Collection<T> { private elements: T[] = []; constructor (elements: T[] = []) { this.elements = elements; } add(elem: T): void { this.elements.push(elem); } contains(elem: T): boolean { return this.elements.includes(elem); } remove(elem: T): void { this.elements = this.elements.filter(existing => existing !== elem); } forEach(func: (elem: T, index: number) => void): void { return this.elements.forEach(func); } map<U>(func: (elem: T, index: number) => U): Collection<U> { return new Collection<U>(this.elements.map(func)); } } const stringCollection = new Collection<string>(); stringCollection.add('Hello, World!'); const numberCollection = new Collection<number>(); numberCollection.add(3.14159); const aircraftCollection = new Collection<IAircraft>(); aircraftCollection.add(myAircraft); 让我们讨论一下这里发生了什么。 Collection类接受一个名为T的泛型类型参数。 类的所有成员都可以访问该类型。 我们用它来定义一个类型为T[]的私有数组,我们也可以用Array<T>的形式表示它(参见?泛型再次用于正常的 TS 数组类型)。 此外,大多数成员函数以某种方式利用该T ,例如通过控制添加和删除的类型或检查集合是否包含元素。
最后,正如我们之前看到的, map方法需要它自己的泛型类型参数。 我们需要在map的签名中定义某个类型T通过回调函数映射到某个类型U ,因此我们需要一个U 。 That U is unique to that function in particular, which means we could have another function in that class that also accepts some type named U , and that'd be fine, because those types are only “in scope” for their functions and not shared across them, thus there are no naming collisions. What we can't do is have another function that accepts a generic parameter named T , for that'd conflict with the T from the class signature.
You can see that when we call the constructor, we pass in the type we want to work with (that is, what type each element of the internal array will be). In the calling code at the bottom of the example, we work with string s, number s, and IAircraft s.
How could we make this work with an interface? What if we have different collection interfaces that we might want to swap out or inject into calling code? To get that level of reduced coupling (low coupling and high cohesion is what we should always aim for), we'll need to depend on an abstraction. Generally, that abstraction will be an interface, but it could also be an abstract class.
Our collection interface will need to be generic, so let's define it:
interface ICollection<T> { add(t: T): void; contains(t: T): boolean; remove(t: T): void; forEach(func: (elem: T, index: number) => void): void; map<U>(func: (elem: T, index: number) => U): ICollection<U>; }Now, let's suppose we have different kinds of collections. We could have an in-memory collection, one that stores data on disk, one that uses a database, and so on. By having an interface, the dependent code can depend upon the abstraction, permitting us to swap out different implementations without affecting the existing code. Here is the in-memory collection.
class InMemoryCollection<T> implements ICollection<T> { private elements: T[] = []; constructor (elements: T[] = []) { this.elements = elements; } add(elem: T): void { this.elements.push(elem); } contains(elem: T): boolean { return this.elements.includes(elem); } remove(elem: T): void { this.elements = this.elements.filter(existing => existing !== elem); } forEach(func: (elem: T, index: number) => void): void { return this.elements.forEach(func); } map<U>(func: (elem: T, index: number) => U): ICollection<U> { return new InMemoryCollection<U>(this.elements.map(func)); } } The interface describes the public-facing methods and properties that our class is required to implement, expecting you to pass in a concrete type that those methods will operate upon. However, at the time of defining the class, we still don't know what type the API caller will wish to use. Thus, we make the class generic too — that is, InMemoryCollection expects to receive some generic type T , and whatever it is, it's immediately passed to the interface, and the interface methods are implemented using that type.

Calling code can now depend on the interface:
// Using type annotation to be explicit for the purposes of the // tutorial. const userCollection: ICollection<User> = new InMemoryCollection<User>(); function manageUsers(userCollection: ICollection<User>) { userCollection.add(new User()); } With this, any kind of collection can be passed into the manageUsers function as long as it satisfies the interface. This is useful for testing scenarios — rather than dealing with over-the-top mocking libraries, in unit and integration test scenarios, I can replace my SqlServerCollection<T> (for example) with InMemoryCollection<T> instead and perform state-based assertions instead of interaction-based assertions. This setup makes my tests agnostic to implementation details, which means they are, in turn, less likely to break when refactoring the SUT.
At this point, we should have worked up to the point where we can understand that first TypedList<T> example. 这里又是:
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T): void { this.values.push(value); } public where(predicate: (value: T) => boolean): TypedList<T> { return TypedList.from<T>(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U): TypedList<U> { return TypedList.from<U>(this.values.map(selector)); } public toArray(): T[] { return this.values; } public static from<U>(values: U[]): TypedList<U> { // Perhaps we perform some logic here. // ... return new TypedList<U>(values); } public static create<U>(values?: U[]): TypedList<U> { return new TypedList<U>(values ?? []); } // Other collection functions. // .. } The class itself accepts a generic type parameter named T , and all members of the class are provided access to it. The instance method select and the two static methods from and create , which are factories, accept their own generic type parameter named U .
The create static method permits the construction of a list with optional seed data. It accepts some type named U to be the type of every element in the list as well as an optional array of U elements, typed as U[] . When it calls the list's constructor with new , it passes that type U as the generic parameter to TypedList . This creates a new list where the type of every element is U . It is exactly the same as how we could call the constructor of our collection class earlier with new Collection<SomeType>() . The only difference is that the generic type is now passing through the create method rather than being provided and used at the top-level.
I want to make sure this is really, really clear. I've stated a few times that we can think about passing around types in a similar way that we do variables. It should already be quite intuitive that we can pass a variable through as many layers of indirection as we please. Forget generics and types for a moment and think about an example of the form:
class MyClass { private constructor (t: number) {} public static create(u: number) { return new MyClass(u); } } const myClass = MyClass.create(2.17); This is very similar to what is happening with the more-involved example, the difference being that we're working on generic type parameters, not variables. Here, 2.17 becomes the u in create , which ultimately becomes the t in the private constructor.
In the case of generics:
class MyClass<T> { private constructor () {} public static create<U>() { return new MyClass<U>(); } } const myClass = MyClass.create<number>(); The U passed to create is ultimately passed in as the T for MyClass<T> . When calling create , we provided number as U , thus now U = number . We put that U (which, again, is just number ) into the T for MyClass<T> , so that MyClass<T> effectively becomes MyClass<number> . The benefit of generics is that we're opened up to be able to work with types in this abstract and high-level fashion, similar to how we can normal variables.
The from method constructs a new list that operates on an array of elements of type U . It uses that type U , just like create , to construct a new instance of the TypedList class, now passing in that type U for T .
The where instance method performs a filtering operation based upon a predicate function. There's no mapping happening, thus the types of all elements remain the same throughout. The filter method available on JavaScript's array returns a new array of values, which we pass into the from method. So, to be clear, after we filter out the values that don't satisfy the predicate function, we get an array back containing the elements that do. All those elements are still of type T , which is the original type that the caller passed to create when the list was first created. Those filtered elements get given to the from method, which in turn creates a new list containing all those values, still using that original type T . The reason why we return a new instance of the TypedList class is to be able to chain new method calls onto the return result. This adds an element of “immutability” to our list.
Hopefully, this all provides you with a more intuitive example of generics in practice, and their reason for existence. Next, we'll look at a few of the more advanced topics.
Generic Type Inference
Throughout this article, in all cases where we've used generics, we've explicitly defined the type we're operating on. It's important to note that in most cases, we do not have to explicitly define the type parameter we pass in, for TypeScript can infer the type based on usage.
If I have some function that returns a random number, and I pass the return result of that function to identity from earlier without specifying the type parameter, it will be inferred automatically as number :
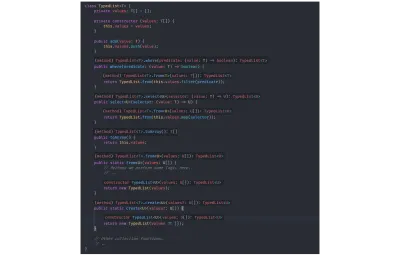
// `value` is inferred as type `number`. const value = identity(getRandomNumber()); 为了演示类型推断,我之前从TypedList结构中删除了所有技术上无关的类型注释,您可以从下面的图片中看到,TSC 仍然正确推断所有类型:
没有多余类型声明TypedList :
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T) { this.values.push(value); } public where(predicate: (value: T) => boolean) { return TypedList.from(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U) { return TypedList.from(this.values.map(selector)); } public toArray() { return this.values; } public static from<U>(values: U[]) { // Perhaps we perform some logic here. // ... return new TypedList(values); } public static create<U>(values?: U[]) { return new TypedList(values ?? []); } // Other collection functions. // .. } 基于函数返回值和传入from和构造函数的输入类型,TSC 了解所有类型信息。 在下图中,我将多个图像拼接在一起,显示了 Visual Studio 的 Code TypeScript 的语言扩展(以及编译器)推断所有类型:
通用约束
有时,我们想对泛型类型施加约束。 也许我们不能支持所有存在的类型,但我们可以支持其中的一个子集。 假设我们要构建一个返回某个集合长度的函数。 如上所示,我们可以有许多不同类型的数组/集合,从默认的 JavaScript Array到我们的自定义数组。 我们如何让我们的函数知道某个泛型类型附加了一个length属性? 同样,如何将我们传递给函数的具体类型限制为那些包含我们需要的数据的类型? 例如,像这样的一个例子是行不通的:
function getLength<T>(collection: T): number { // Error. TS does not know that a type T contains a `length` property. return collection.length; }答案是利用通用约束。 我们可以定义一个接口来描述我们需要的属性:
interface IHasLength { length: number; }现在,在定义我们的泛型函数时,我们可以将泛型类型限制为扩展该接口的类型:
function getLength<T extends IHasLength>(collection: T): number { // Restricting `collection` to be a type that contains // everything within the `IHasLength` interface. return collection.length; }真实世界的例子
在接下来的几节中,我们将讨论一些真实世界的泛型示例,它们可以创建更优雅、更易于推理的代码。 我们已经看到了很多琐碎的例子,但我想讨论一些错误处理、数据访问模式和前端 React 状态/道具的方法。
现实世界的例子——错误处理的方法
与大多数编程语言一样,JavaScript 包含一流的错误处理机制—— try / catch 。 尽管如此,我并不是很喜欢它在使用时的外观。 这并不是说我不使用该机制,我确实使用了,但我倾向于尽可能地隐藏它。 通过抽象try / catch away,我还可以在可能失败的操作中重用错误处理逻辑。
假设我们正在构建一些数据访问层。 这是应用程序的一层,它包装了用于处理数据存储方法的持久性逻辑。 如果我们正在执行数据库操作,并且如果跨网络使用该数据库,则可能会发生特定于 DB 的错误和暂时异常。 拥有专用数据访问层的部分原因是将数据库从业务逻辑中抽象出来。 因此,我们不能将此类特定于 DB 的错误抛出堆栈并从这一层抛出。 我们需要先包装它们。
让我们看一个使用try / catch的典型实现:
async function queryUser(userID: string): Promise<User> { try { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(dbUser); } catch (e) { switch (true) { case e instanceof DbErrorOne: return Promise.reject(new WrapperErrorOne()); case e instanceof DbErrorTwo: return Promise.reject(new WrapperErrorTwo()); case e instanceof NetworkError: return Promise.reject(new TransientException()); default: return Promise.reject(new UnknownError()); } } } 切换true只是一种能够将 switch case语句用于我的错误检查逻辑的方法,而不是必须声明 if/else if 链——这是我第一次从@Jeffijoe 那里听到的技巧。
如果我们有多个这样的函数,我们必须复制这个错误包装逻辑,这是一个非常糟糕的做法。 对于一个功能来说,它看起来相当不错,但对于许多人来说,这将是一场噩梦。 为了抽象出这个逻辑,我们可以将它包装在一个自定义的错误处理函数中,该函数将传递结果,但捕获并包装任何抛出的错误:
async function withErrorHandling<T>( dalOperation: () => Promise<T> ): Promise<T> { try { // This unwraps the promise and returns the type `T`. return await dalOperation(); } catch (e) { switch (true) { case e instanceof DbErrorOne: return Promise.reject(new WrapperErrorOne()); case e instanceof DbErrorTwo: return Promise.reject(new WrapperErrorTwo()); case e instanceof NetworkError: return Promise.reject(new TransientException()); default: return Promise.reject(new UnknownError()); } } } 为了确保这样做有意义,我们有一个名为withErrorHandling的函数,它接受一些泛型类型参数T 。 这个T表示我们期望从dalOperation回调函数返回的 promise 的成功解析值的类型。 通常,由于我们只是返回 async dalOperation函数的返回结果,因此我们不需要await它,因为这会将函数包装在第二个无关的 promise 中,我们可以将await留给调用代码。 在这种情况下,我们需要捕获任何错误,因此需要await 。
我们现在可以使用这个函数来包装我们之前的 DAL 操作:
async function queryUser(userID: string) { return withErrorHandling<User>(async () => { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(dbUser); }); }我们开始了。 我们有一个类型安全和错误安全的功能用户查询功能。
此外,如前所述,如果 TypeScript 编译器有足够的信息来隐式推断类型,则不必显式传递它们。 在这种情况下,TSC 知道函数的返回结果就是泛型类型。 因此,如果mapper.toDomain(user)返回了User类型,则根本不需要传入该类型:
async function queryUser(userID: string) { return withErrorHandling(async () => { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(user); }); } 我倾向于喜欢的另一种错误处理方法是 Monadic Types。 Either Monad 是Either<T, U>形式的代数数据类型,其中T可以表示错误类型, U可以表示失败类型。 使用 Monadic Types 听从函数式编程,一个主要的好处是错误变得类型安全——正常的函数签名不会告诉 API 调用者该函数可能抛出什么错误。 假设我们从queryUser内部抛出NotFound错误。 queryUser(userID: string): Promise<User>的签名并没有告诉我们任何相关信息。 但是,像queryUser(userID: string): Promise<Either<NotFound, User>>这样的签名绝对可以。 我不会在本文中解释像 Either Monad 这样的 monad 是如何工作的,因为它们可能非常复杂,并且必须将它们视为 monadic 的多种方法,例如映射/绑定。 如果您想了解更多关于它们的信息,我会推荐 Scott Wlaschin 的两次 NDC 演讲,这里和这里,以及 Daniel Chamber 的演讲这里。 该站点以及这些博客文章也可能很有用。
现实世界的例子——存储库模式
让我们看一下泛型可能有用的另一个用例。 大多数后端系统都需要以某种方式与数据库交互——这可能是像 PostgreSQL 这样的关系数据库,像 MongoDB 这样的文档数据库,甚至可能是像 Neo4j 这样的图形数据库。
由于作为开发人员,我们应该以低耦合和高内聚设计为目标,因此考虑迁移数据库系统可能产生的后果将是一个公平的论据。 考虑到不同的数据访问需求可能更喜欢不同的数据访问方法也是公平的(这开始有点进入 CQRS,这是一种分离读写的模式。如果你愿意,请参阅 Martin Fowler 的帖子和 MSDN 列表了解更多信息。Vaughn Vernon 的“实施领域驱动设计”和 Scott Millet 的“领域驱动设计的模式、原则和实践”这两本书也很不错)。 我们还应该考虑自动化测试。 大多数解释使用 Node.js 构建后端系统的教程都将数据访问代码与业务逻辑与路由混合在一起。 也就是说,他们倾向于将 MongoDB 与 Mongoose ODM 一起使用,采用 Active Record 方法,并且没有清晰地分离关注点。 这种技术在大型应用程序中是不受欢迎的。 当您决定要将一个数据库系统迁移到另一个数据库系统时,或者当您意识到您更喜欢不同的数据访问方法时,您必须删除旧的数据访问代码,用新代码替换它,并希望您在此过程中没有向路由和业务逻辑引入任何错误。
当然,您可能会争辩说单元测试和集成测试将防止回归,但如果这些测试发现自己耦合并依赖于它们应该不知道的实现细节,它们也可能会在过程中中断。
解决此问题的常用方法是存储库模式。 它说要调用代码,我们应该允许我们的数据访问层仅仅模仿对象或域实体的内存集合。 这样,我们可以让业务驱动设计而不是数据库(数据模型)。 对于大型应用程序,称为域驱动设计的架构模式变得有用。 在 Repository Pattern 中,Repositories 是组件,最常见的是类,它封装并保存内部所有访问数据源的逻辑。 有了这个,我们可以将数据访问代码集中到一层,使其易于测试和易于重用。 此外,我们可以在两者之间放置一个映射层,允许我们将与数据库无关的域模型映射到一系列一对一的表映射。 如果您愿意,存储库上可用的每个功能都可以选择使用不同的数据访问方法。
存储库、工作单元、跨表的数据库事务等有许多不同的方法和语义。 由于这是一篇关于泛型的文章,我不想过多地深入杂草,因此在这里我将举例说明一个简单的示例,但重要的是要注意不同的应用程序有不同的需求。 例如,DDD 聚合的存储库与我们在这里所做的完全不同。 我在这里描述存储库实现的方式并不是我在实际项目中实现它们的方式,因为有很多缺失的功能和不理想的架构实践在使用中。
假设我们将Users和Tasks作为域模型。 这些可能只是 POTO——普通的 TypeScript 对象。 它们中没有数据库的概念,因此,您不会像使用 Mongoose 那样调用User.save() 。 使用存储库模式,我们可能会保留一个用户或从我们的业务逻辑中删除一个任务,如下所示:
// Querying the DB for a User by their ID. const user: User = await userRepository.findById(userID); // Deleting a Task by its ID. await taskRepository.deleteById(taskID); // Deleting a Task by its owner's ID. await taskRepository.deleteByUserId(userID);很明显,您可以看到所有混乱和瞬态数据访问逻辑是如何隐藏在这个存储库外观/抽象背后的,从而使业务逻辑与持久性问题无关。
让我们从构建一些简单的领域模型开始。 这些是应用程序代码将与之交互的模型。 它们在这里是贫乏的,但会保持自己的逻辑来满足现实世界中的业务不变量,也就是说,它们不会仅仅是数据包。
interface IHasIdentity { id: string; } class User implements IHasIdentity { public constructor ( private readonly _id: string, private readonly _username: string ) {} public get id() { return this._id; } public get username() { return this._username; } } class Task implements IHasIdentity { public constructor ( private readonly _id: string, private readonly _title: string ) {} public get id() { return this._id; } public get title() { return this._title; } } 稍后您会看到为什么我们将身份输入信息提取到界面中。 这种定义域模型并通过构造函数传递所有内容的方法不是我在现实世界中的做法。 此外,依赖抽象域模型类比免费获取id实现的接口更可取。
对于存储库,因为在这种情况下,我们希望许多相同的持久性机制将在不同的域模型之间共享,我们可以将存储库方法抽象为通用接口:
interface IRepository<T> { add(entity: T): Promise<void>; findById(id: string): Promise<T>; updateById(id: string, updated: T): Promise<void>; deleteById(id: string): Promise<void>; existsById(id: string): Promise<boolean>; }我们还可以更进一步,创建一个通用存储库来减少重复。 为简洁起见,我不会在这里这样做,而且我应该注意,通用存储库接口,例如这个接口和通用存储库,一般来说,往往是不受欢迎的,因为你可能有某些实体是只读的,或者写-only,或无法删除的,或类似的。 这取决于应用程序。 此外,我们没有“工作单元”的概念来跨表共享事务,这是我将在现实世界中实现的功能,但是,由于这是一个小型演示,我没有想变得太技术化。
让我们从实现我们的UserRepository开始。 我将定义一个IUserRepository接口,该接口包含特定于用户的方法,因此当我们依赖注入具体实现时,允许调用代码依赖于该抽象:
interface IUserRepository extends IRepository<User> { existsByUsername(username: string): Promise<boolean>; } class UserRepository implements IUserRepository { // There are 6 methods to implement here all using the // concrete type of `User` - Five from IRepository<User> // and the one above. }任务存储库将类似,但会包含应用程序认为合适的不同方法。
在这里,我们定义了一个扩展通用接口的接口,因此我们必须传递我们正在处理的具体类型。 正如您从两个界面中看到的那样,我们的概念是发送这些 POTO 域模型,然后将它们取出。 调用代码不知道底层的持久性机制是什么,这就是重点。
下一个需要考虑的是,根据我们选择的数据访问方法,我们必须处理特定于数据库的错误。 例如,我们可以将 Mongoose 或 Knex Query Builder 放在这个存储库后面,在这种情况下,我们将不得不处理那些特定的错误——我们不希望它们冒泡到业务逻辑,因为那样会破坏关注点分离并引入更大程度的耦合。
让我们为我们希望使用的可以为我们处理错误的数据访问方法定义一个 Base Repository:
class BaseKnexRepository { // A constructor. /** * Wraps a likely to fail database operation within a function that handles errors by catching * them and wrapping them in a domain-safe error. * * @param dalOp The operation to perform upon the database. */ public async withErrorHandling<T>(dalOp: () => Promise<T>) { try { return await dalOp(); } catch (e) { // Use a proper logger: console.error(e); // Handle errors properly here. } } }现在,我们可以在存储库中扩展这个基类并访问该通用方法:
interface IUserRepository extends IRepository<User> { existsByUsername(username: string): Promise<boolean>; } class UserRepository extends BaseKnexRepository implements IUserRepository { private readonly dbContext: Knex | Knex.Transaction; public constructor (private knexInstance: Knex | Knex.Transaction) { super(); this.dbContext = knexInstance; } // Example `findById` implementation: public async findById(id: string): Promise<User> { return this.withErrorHandling<User>(async () => { const dbUser = await this.dbContext<DbUser>() .select() .where({ user_id: id }) .first(); // Maps type DbUser to User return mapper.toDomain(dbUser); }); } // There are 5 methods to implement here all using the // concrete type of `User`. } 请注意,我们的函数从数据库中检索DbUser并将其映射到User域模型,然后再返回它。 这是数据映射器模式,它对于保持关注点分离至关重要。 DbUser是到数据库表的一对一映射——它是存储库操作的数据模型——因此高度依赖于所使用的数据存储技术。 出于这个原因, DbUser永远不会离开存储库,并且会在返回之前映射到User域模型。 我没有展示DbUser实现,但它可能只是一个简单的类或接口。
到目前为止,使用由泛型提供支持的存储库模式,我们已经设法将数据访问问题抽象为小单元,并保持类型安全和可重用性。
最后,出于单元和集成测试的目的,假设我们将保留一个内存存储库实现,以便在测试环境中,我们可以注入该存储库,并在磁盘上执行基于状态的断言,而不是使用模拟框架。 这种方法迫使一切都依赖于面向公众的接口,而不是允许测试与实现细节耦合。 由于每个存储库之间的唯一区别是它们选择在ISomethingRepository接口下添加的方法,因此我们可以构建一个通用的内存存储库并在特定于类型的实现中扩展它:
class InMemoryRepository<T extends IHasIdentity> implements IRepository<T> { protected entities: T[] = []; public findById(id: string): Promise<T> { const entityOrNone = this.entities.find(entity => entity.id === id); return entityOrNone ? Promise.resolve(entityOrNone) : Promise.reject(new NotFound()); } // Implement the rest of the IRepository<T> methods here. } 这个基类的目的是执行处理内存存储的所有逻辑,这样我们就不必在内存测试存储库中复制它。 由于findById类的方法,此存储库必须了解实体包含一个id字段,这就是IHasIdentity接口上的通用约束是必要的原因。 我们之前看到过这个接口——这是我们的领域模型实现的。
有了这个,在构建内存用户或任务存储库时,我们可以扩展这个类并自动实现大部分方法:
class InMemoryUserRepository extends InMemoryRepository<User> { public async existsByUsername(username: string): Promise<boolean> { const userOrNone = this.entities.find(entity => entity.username === username); return Boolean(userOrNone); // or, return !!userOrNone; } // And that's it here. InMemoryRepository implements the rest. } 在这里,我们的InMemoryRepository需要知道实体具有id和username等字段,因此我们将User作为通用参数传递。 User已经实现IHasIdentity ,因此满足了通用约束,并且我们还声明我们也有一个username属性。
现在,当我们希望从业务逻辑层使用这些存储库时,非常简单:
class UserService { public constructor ( private readonly userRepository: IUserRepository, private readonly emailService: IEmailService ) {} public async createUser(dto: ICreateUserDTO) { // Validate the DTO: // ... // Create a User Domain Model from the DTO const user = userFactory(dto); // Persist the Entity await this.userRepository.add(user); // Send a welcome email await this.emailService.sendWelcomeEmail(user); } } (请注意,在实际应用程序中,我们可能会将对emailService的调用移至作业队列,以免增加请求的延迟,并希望能够在失败时执行幂等重试(——并不是说电子邮件发送特别重要)首先是幂等的)。此外,将整个用户对象传递给服务也是有问题的。另一个需要注意的问题是,我们可能会发现自己处于这样一个位置,即在用户被持久化之后但在电子邮件之前服务器崩溃有一些缓解模式可以防止这种情况发生,但出于实用主义的目的,人工干预和适当的日志记录可能会很好)。
我们开始了——使用具有泛型功能的存储库模式,我们已经将 DAL 与 BLL 完全分离,并设法以类型安全的方式与我们的存储库交互。 我们还开发了一种方法来快速构建同样类型安全的内存存储库,用于单元和集成测试,允许真正的黑盒和与实现无关的测试。 如果没有泛型类型,这一切都不可能实现。
作为免责声明,我想再次指出,这个 Repository 实现缺乏很多。 我想保持示例简单,因为重点是泛型的利用,这就是为什么我没有处理重复或担心事务的原因。 体面的存储库实现将需要一篇文章来完全正确地解释,并且实现细节会根据您是在做 N-Tier Architecture 还是 DDD 而发生变化。 这意味着,如果您希望使用存储库模式,则不应将我的实现视为最佳实践。
现实世界的例子——反应状态和道具
React 功能组件的 state、ref 和其他 hooks 也是通用的。 如果我有一个包含Task属性的接口,并且我想在 React 组件中保存它们的集合,我可以这样做:
import React, { useState } from 'react'; export const MyComponent: React.FC = () => { // An empty array of tasks as the initial state: const [tasks, setTasks] = useState<Task[]>([]); // A counter: // Notice, type of `number` is inferred automatically. const [counter, setCounter] = useState(0); return ( <div> <h3>Counter Value: {counter}</h3> <ul> { tasks.map(task => ( <li key={task.id}> <TaskItem {...task} /> </li> )) } </ul> </div> ); }; 此外,如果我们想将一系列 props 传递给我们的函数,我们可以使用通用React.FC<T>类型并访问props :
import React from 'react'; interface IProps { id: string; title: string; description: string; } export const TaskItem: React.FC<IProps> = (props) => { return ( <div> <h3>{props.title}</h3> <p>{props.description}</p> </div> ); }; TS 编译器会自动将props的类型推断为IProps 。
结论
在本文中,我们看到了泛型及其用例的许多不同示例,从简单的集合到错误处理方法,再到数据访问层隔离等等。 用最简单的术语来说,泛型允许我们构建数据结构,而无需知道它们在编译时运行的具体时间。 希望这有助于更多地打开主题,使泛型的概念更直观一点,并带来它们的真正力量。