
2022 年 15 大 Hadoop 面试问答
已发表: 2021-01-09随着数据分析的发展势头强劲,对擅长处理大数据的人的需求激增。 从数据分析师到数据科学家,大数据今天正在创建一系列工作档案。 您需要亲身体验的第一件事是 Hadoop。
无论何种工作角色/资料,您都可能以一种或另一种方式在 Hadoop 上工作。 因此,您总是可以期望面试官按照您的方式提出一些 Hadoop 问题。
为此,让我们看一下在您参加的任何面试中都可能出现的 15 个 Hadoop 面试问题。
什么是 Hadoop? Hadoop的主要组件是什么?
Hadoop 是一种基础设施,配备了处理和存储大数据所需的相关工具和服务。 准确地说,Hadoop 是所有大数据挑战的“解决方案”。 此外,Hadoop 框架还可以帮助组织分析大数据并做出更好的业务决策。
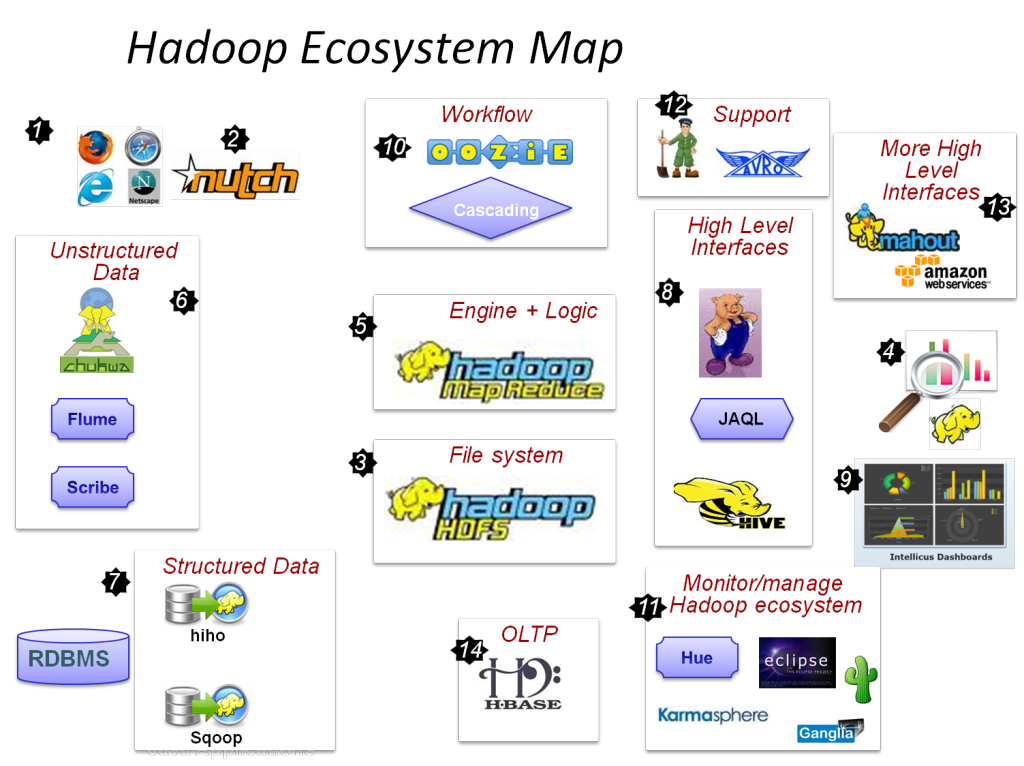
Hadoop的主要组件是:
- 高密度文件系统
- Hadoop MapReduce
- Hadoop 通用
- 纱
- PIG 和 HIVE – 数据访问组件。
- HBase – 用于数据存储
- Ambari、Oozie 和 ZooKeeper – 数据管理和监控组件
- Thrift 和 Avro – 数据序列化组件
- Apache Flume、Sqoop、Chukwa – 数据集成组件
- Apache Mahout 和 Drill – 数据智能组件
Hadoop框架的核心概念是什么?
Hadoop 基本上基于两个核心概念。 他们是:
- HDFS:HDFS 或 Hadoop 分布式文件系统是一种基于 Java 的可靠文件系统,用于以块格式存储大量数据集。 主从架构为其提供动力。
- MapReduce:MapReduce 是一种有助于处理大型数据集的编程结构。 该函数进一步分为两部分——“map”将数据集分离为元组,“reduce”使用映射元组并创建较小元组块的组合。
说出 Hadoop 中最常见的输入格式?
Hadoop中有三种常见的输入格式:
- 文本输入格式:这是 Hadoop 中的默认输入格式。
- 序列文件输入格式:此输入格式用于按顺序读取文件。
- Key Value Input Format:这个是用来读取纯文本文件的。
什么是纱线?
YARN 是 Yet Another Resource Negotiator 的缩写。 它是 Hadoop 的数据处理框架,用于管理数据资源并为成功处理创建环境。 
什么是“机架意识”?
“机架感知”是 NameNode 用来确定数据块及其副本存储在 Hadoop 集群中的模式的算法。 这是在机架定义的帮助下实现的,这些定义减少了同一机架中包含的数据节点之间的拥塞。

什么是主动和被动 NameNode?
一个高可用性 Hadoop 系统通常包含两个 NameNode——Active NameNode 和 Passive NameNode。
运行 Hadoop 集群的 NameNode 称为 Active NameNode,存储 Active NameNode 数据的备用 NameNode 称为 Passive NameNode。
拥有两个 NameNode 的目的是,如果 Active NameNode 崩溃,Passive NameNode 可以带头。 因此,NameNode 始终在集群中运行,系统永远不会出现故障。
Hadoop 框架中有哪些不同的调度程序?
Hadoop框架中有三种不同的调度器:
- COSHH – COSHH 通过审查集群和工作负载以及异构性来帮助安排决策。
- FIFO 调度程序 – FIFO 根据到达时间在队列中排列作业,不使用异质性。
- 公平共享——公平共享为单个用户创建了一个包含多个地图的池,并减少了资源上的插槽,他们可以使用这些资源执行特定的作业。
什么是投机执行?
通常在 Hadoop 框架中,某些节点的运行速度可能比其他节点慢。 这往往会限制整个程序。 为了克服这个问题,Hadoop 首先检测或“推测”某个任务的运行速度是否比平时慢,然后为该任务启动等效备份。 因此,在这个过程中,主节点同时执行这两个任务,并且首先完成的任务被接受,而另一个被杀死。 Hadoop 的这种备份功能称为推测执行。

命名 Apache HBase 的主要组件?
Apache HBase 由三个组件组成:
- Region Server:一张表被划分为多个Region后,这些Region的集群通过Region Server转发给客户端。
- HMaster:这是一个帮助管理和协调Region服务器的工具。
- ZooKeeper:ZooKeeper 是 HBase 分布式环境中的协调器。 它通过会话中的通信帮助维护集群内的服务器状态。
什么是“检查点”? 它有什么好处?
检查点是指将 FsImage 和 Edit log 组合以形成新 FsImage 的过程。 因此,NameNode 可以直接从 FsImage 加载最终的内存状态,而不是重播编辑日志。 辅助 NameNode 负责此过程。
Checkpointing 提供的好处是它最大限度地减少了 NameNode 的启动时间,从而使整个过程更加高效。
流行文化中的大数据应用
如何调试 Hadoop 代码?
要调试 Hadoop 代码,首先,您需要检查当前正在运行的 MapReduce 任务列表。 然后您需要检查是否有任何孤立任务同时运行。 如果是这样,您需要按照以下简单步骤查找资源管理器日志的位置:
运行“ps –ef | grep –I ResourceManager”,然后在显示的结果中,尝试查找是否存在与特定作业 id 相关的错误。
现在,确定用于执行任务的工作节点。 登录节点并运行“ps –ef | grep –iNodeManager。”
最后,仔细检查节点管理器日志。 大多数错误是从每个 map-reduce 作业的用户级别日志生成的。
Hadoop 中 RecordReader 的用途是什么?
Hadoop 将数据分解为块格式。 RecordReader 有助于将这些数据块集成到单个可读记录中。 例如,如果输入数据被分成两个块——
第 1 行 - 欢迎来到
第 2 行 - 升级
RecordReader 会将其读取为“欢迎来到 UpG rad”。
Hadoop 可以在哪些模式下运行?
Hadoop可以运行的模式有:
- 独立模式 – 这是 Hadoop 的默认模式,用于调试目的。 它不支持 HDFS。
- 伪分布式模式——该模式需要配置mapred-site.xml、core-site.xml和hdfs-site.xml文件。 这里的主节点和从节点都是一样的。
- 完全分布式模式——完全分布式模式是 Hadoop 的生产阶段,其中数据分布在 Hadoop 集群上的各个节点上。 这里,主节点和从节点是分开分配的。
列举一些 Hadoop 的实际应用。
以下是 Hadoop 发挥作用的一些真实实例:
- 管理街道交通
- 欺诈检测和预防
- 实时分析客户数据以改善客户服务
- 访问来自医生、HCP 等的非结构化医疗数据,以改善医疗保健服务。
可以提高大数据性能的重要 Hadoop 工具有哪些?
显着提高大数据性能的 Hadoop 工具是

• 蜂巢
• HDFS
• HBase
• SQL
• NoSQL
• Oozie
• 云
• Avro
• 水槽
• 动物园管理员
大数据工程师:神话与现实
结论
这些 Hadoop 面试问题应该对你下次面试有很大帮助。 虽然有时面试官倾向于扭曲一些 Hadoop 面试问题,但如果你已经整理好基础知识,这对你来说应该不是问题。
如果您有兴趣了解有关大数据的更多信息,请查看我们的 PG 大数据软件开发专业文凭课程,该课程专为在职专业人士设计,提供 7 多个案例研究和项目,涵盖 14 种编程语言和工具,实用的动手操作研讨会,超过 400 小时的严格学习和顶级公司的就业帮助。