
机器学习背后的数学:你需要知道什么?
已发表: 2021-03-10机器学习是人工智能的一个部门,专注于通过准确处理可用数据来构建应用程序。 机器学习的主要目的是帮助计算机在没有人为干预的情况下处理计算。 这是通过允许机器通过有监督或无监督的学习方法来学习模仿人类智能来实现的。
机器学习是许多领域的组合,包括统计、概率、线性代数、微积分等,基于这些领域,机器学习模型可以创建或输入算法以根据人类智能进行即兴创作。 应用程序越复杂,其算法就越复杂。
从数字助理和智能设备到根据您的在线活动推荐您喜欢的产品的网站,以及通知您航班时刻表的手机,基于机器学习的产品和工具无处不在。 随着我们对智能设备和电器的依赖增加,对机器学习实施的需求也将增加。
为此,在本文中,我们将探讨编写机器学习算法并实现它们所需的数学概念。
目录
数学在机器学习中的意义是什么?
机器学习应用程序提供从可用数据中收集的分析和见解,这些数据有助于企业制定可行的决策。 由于机器学习围绕着研究和实施算法,所以加强你的数学技能很重要。 它有助于消除不确定性并准确预测涉及复杂数据参数和特征的数据值。 它还有助于我们更好地理解偏差-方差权衡。
掌握机器学习需要了解数学概念,如线性代数、向量微积分、解析几何、矩阵分解、概率和统计。 深入掌握这些有助于创建直观的机器学习应用程序。

线性代数
线性代数关注向量和矩阵,主要围绕计算展开。 它在机器学习和深度学习技术中起着不可或缺的作用。 根据 Skyler Speakman的说法,它是 21 世纪的数学。
ML 工程师和数据科学家或研究人员通常使用线性代数来构建线性算法、逻辑回归、决策树和支持向量机。
结石
微积分驱动机器学习算法。 如果不了解其概念,就不可能使用给定的数据集预测结果。 微积分有助于分析数量变化的速率,并关注机器学习算法的最佳性能。 积分、微分、极限和导数是一些有助于训练深度神经网络的微积分概念。
可能性
机器学习中的概率预测了一组结果,而统计数据将有利的结果推向了结论。 事件可以像扔硬币一样简单。 概率可以分为两类:条件概率和联合概率。 当事件彼此独立时发生联合概率,而当一个事件取代另一个事件时发生条件概率。
统计数据
统计侧重于算法的定量和定性方面。 它通过简洁地呈现它帮助我们确定目标并将收集的数据转换为精确的观察结果。 机器学习中的统计侧重于描述性统计和推论统计。
描述性统计涉及描述和总结模型正在处理的小型数据集。 这里使用的方法是平均值、中位数、众数、标准差和变异。 最终结果以图形表示。
推论统计处理在处理大型数据集时从给定样本中提取见解。 推理统计允许机器分析超出所提供信息范围的数据。 假设检验、抽样分布、方差分析是推论统计的某些方面。
除此之外,编码能力是机器学习的关键先决条件。 Python 和 Java 等语言的专业知识有助于更好地理解数据建模。 字符串格式化、定义函数、具有多个变量迭代器的循环、if 或 else 条件表达式是它的一些基本功能。
至于数据建模,它是我们估计数据集结构并检测可能的变化和模式的过程。 为了能够做出准确的预测,必须了解集体数据的各种属性。
你如何学习机器学习?
虽然机器学习是一个利润丰厚的领域,但它需要大量的练习和耐心。 鉴于其在当今几乎所有行业中的应用,机器学习工程师的需求量很大。
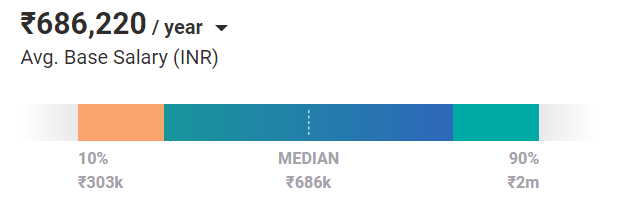
具有机器学习背景的入门级工程师的平均工资为 68.6 万卢比/年。 随着经验和技能的提高,获得更高薪水的潜力呈指数级增长。
有几门课程可供希望增强机器学习知识基础的人使用。 掌握这门学科至少需要 6 个月到 2 年的时间。
至少拥有学士学位和一年的工作经验,最好是数学或统计学学位,您可以在upGrad上修读以下任何一门课程,以增加您在该领域取得成功的机会。

- IIT班加罗尔机器学习和深度学习高级证书课程(6个月)
- IIT Bangalore机器学习和 NLP 高级证书课程(6 个月)
- 来自 IIT 班加罗尔的机器学习和人工智能执行 PG 计划(12 个月)
- IIT Madras机器学习和云高级认证(12 个月)
- LJMU 和 IIT Bangalore机器学习和人工智能理学硕士(18 个月)
所有这些课程都提供至少 240 多个小时的学习时间和至少 5 个案例研究,这将帮助您深入了解机器学习及其各种辅助领域。 您可以涵盖构成编码支柱的基本主题,如 Python、MySQL、Tensor、NLTK、statsmodels、excel 等。 以下是机器学习中各种upGrad 课程的详细介绍,因此您可以选择最适合您的课程。
加入来自世界顶级大学的在线人工智能课程- 硕士、高级管理人员研究生课程和 ML 和 AI 高级证书课程,以加快您的职业生涯。
机器学习的应用
机器学习在我们的日常生活中发挥着至关重要的作用,无论是在专业领域还是个人领域。 它的分析和直觉能力有可能极大地影响我们执行日常任务的方式。 事实证明,它在为组织节省金钱和时间方面足智多谋。
虽然机器学习是一个广泛的领域,几乎在每个行业都有应用,但这里有一些最突出的例子:
- 图像识别是最常用的应用程序之一,因为它有助于人脸检测,因此为每个人创建一个单独的数据库。 它也可以用来识别手写风格。
- 卫生部门的机器学习增强了卫生保健提供者的能力。 它可以用于更快的医疗诊断。 在许多情况下,人工智能有助于疾病的早期诊断,从而使医生能够提出有可能挽救生命的治疗和预防措施。
- 机器学习在涉及投资、并购的金融领域有重要应用。 它帮助银行和其他经济机构做出明智的选择。
- 它的有效性可能在客户关怀和服务行业最为明显,因为机器学习可以简化操作并快速、更有效地提供解决方案。
- 机器学习使原本必须由现场人员执行的任务自动化。 例如,如果我们要考虑虚拟助手,它可能是一项简单的任务,比如更改密码,或者晚上检查你的银行余额。 通过机器学习,现在可以将人力资源分配给需要复杂决策或人工操作才能完成的更紧迫的任务。
机器学习的未来范围
尽管机器学习已经存在了几十年,但它的应用在今天最为明显。 该行业尚未繁荣,即兴发挥,这意味着机器学习的未来是光明的。 大多数大型公司已经从机器学习中获益,并扩展其服务和产品以推动增长。
自然地,机器学习工程师的需求量很大,机器学习本身就是一个利润丰厚的职业。 它代表了企业所需的优势。 到目前为止,人工智能已经创造了大约 230 万个就业机会。 预计到 2022 年底,全球机器学习行业将以 42.2% 的复合年增长率增长,达到 90 亿美元。
以下是机器学习的几个主要趋势:
- 越来越多的算法正在学习无监督实现。 企业正在投资基于这些有可能改变机器学习的无监督算法的量子计算。 这些有助于分析和得出有意义的见解,从而帮助企业实现使用经典机器学习技术无法实现的更好结果。
- 人工智能驱动的机器人正在被部署来开展业务运营。 然而,这些技术还处于初期阶段,随着企业投资建立人工智能和机器学习的立足点,机器人将很快帮助成倍地提高生产力。 举个例子,我们在消费市场上将无人机伪装成强大的商业工具,用于完成商业运营和交付货物等简单任务。
- 机器学习算法支持增强的个性化。 这些算法调查潜在客户的在线行为并将信息发送回公司。 这些公司反过来向他们发送产品和服务建议。 这些机器学习技术有助于识别客户的好恶。 通过机器学习,公司可以为客户提供他们想要的东西,并在他们想要的时候提供,从而提高客户保留率并为组织吸引更多业务。 改进的个性化是机器学习的未来。
- 得益于增强的机器学习算法,移动和 Web 应用程序现在比以往任何时候都更加智能。 改进的认知服务允许开发人员根据视觉识别、他们的语音、声音、语音等为每个客户创建单独的数据库。
这将我们带到了文章的结尾。 我们希望这些信息对您有所帮助!
为什么线性回归需要同方差性?
同方差性描述了数据与平均值的相似程度或偏离程度。 这是一个重要的假设,因为参数统计测试对差异很敏感。 异方差性不会在系数估计中引起偏差,但会降低它们的精度。 精度越低,系数估计就越可能偏离正确的总体值。 为了避免这种情况,同方差性是断言的关键假设。
线性回归中多重共线性的两种类型是什么?
数据和结构多重共线性是多重共线性的两种基本类型。 当我们从其他项中创建一个模型项时,我们会得到结构多重共线性。 换句话说,它不是出现在数据本身中,而是我们提供的模型的结果。 虽然数据多重共线性不是我们模型的产物,但它存在于数据本身中。 数据多重共线性在观察性调查中更为常见。
使用 t 检验进行独立检验的缺点是什么?
使用配对样本 t 检验时,重复测量而不是组设计之间的差异存在问题,这会导致结转效应。 由于 I 类错误,t 检验不能用于多重比较。 在对一组样本进行配对 t 检验时,很难拒绝原假设。 获取样本数据的主题是研究过程中耗时且成本高昂的一个方面。