
将结构化数据烘焙到设计过程中
已发表: 2022-03-10搜索引擎优化 (SEO) 对几乎所有类型的网站都是必不可少的,但其更精细的点仍然是一种专长。 即使在今天,搜索引擎优化也经常被视为事后可以附加的东西。 它可以达到一定程度,但实际上不应该如此。 搜索引擎每天都变得更智能,网站也有办法变得更智能。
SEO 的基础与以往一样:明确标记的出色内容迟早会赢得胜利——无论有多少人试图玩弄这个系统。 问题是,这些标签比以前复杂得多。 元标题、图像替代文本和反向链接很重要,但在 2020 年,它们也相当原始。 还有另一层元数据,目前只有一小部分网站在使用:结构化数据。
所有搜索引擎都有相同的目的:组织网络内容并为搜索查询提供最相关、最有用的结果。 自 Lycos 和 Ask Jeeves 时代以来,他们实现这一目标的方式发生了巨大变化。 仅谷歌就使用了 200 多个排名因素,而这些只是我们所知道的。
SEO 现在是一个巨大的领域,我告诉你,结构化数据是未来几年理解和实施的一个非常非常重要的因素。 它不仅可以提高您在相关查询中获得高排名的机会。 更重要的是,它有助于让您的网站变得更好——向各种有用的网络体验开放。
推荐阅读: SEO在您的网页设计过程中属于哪里?
什么是结构化数据?
结构化数据是一种在网页上标记内容的方式。 使用来自 Schema.org 的词汇,它消除了 SEO 中的大部分歧义。 与其相信谷歌、必应、百度和 DuckDuckGo 之类的公司来计算你的内容是什么,你告诉他们。 这是搜索引擎猜测页面内容与确定了解之间的区别。
正如 Schema.org 所说:
通过在网页的 HTML 中添加额外的标签(例如“嘿,搜索引擎,此信息描述了这个特定的电影、地点、人物或视频”的标签),您可以帮助搜索引擎和其他应用程序更好地理解您的内容并以有用的、相关的方式显示它。
Schema.org 于 2011 年推出,是由 Google、Microsoft、Yahoo 和 Yandex 共享的项目。 换句话说,这是一个“两党”的努力——如果你愿意的话。 标记超越任何一个搜索引擎。 用 Schema.org 自己的话说,
“共享词汇表使网站管理员和开发人员更容易决定模式并从他们的努力中获得最大收益。”
在许多方面,它是微格式(2005 年左右推出)的更广泛的表亲,将语义和结构化数据嵌入 HTML,主要是为了搜索引擎和聚合器的利益。 尽管目前仍支持微格式,但 Schema.org 库的“官方”性质使其成为长寿的更安全选择。
关联数据的 JSON (JSON-LD) 已成为结构化数据的主要基础标准,尽管微数据和 RDFa 也受支持并用于相同目的。 Schema.org 根据您最熟悉的内容为每种类型提供示例。
例如,假设 Joe Bloggs 撰写了 Joseph Heller 1961 年小说Catch-22的评论并将其发布在他的博客上。 可悲的是,博客的品味很差,给了五颗星中的两颗。 对于查看页面的人来说,这些信息会不假思索地理解,但计算机程序必须连接几个点才能得出相同的结论。
对于结构化数据,可以将以下标记添加到页面的<head>代码中。 (这是一种 JSON-LD 方法。微数据和 RDFa 可用于将相同的信息编织到<body>内容中):
<script type="application/ld+json"> { "@context" : "https://schema.org", "@type" : "Book", "name" : "Catch-22", "author" : { "@type" : "Person", "name" : "Joseph Heller" }, "datePublished" : "1961-11-10", "review" : { "@type" : "Review", "author" : { "@type" : "Person", "name" : "Joe Bloggs" }, "reviewRating" : { "@type" : "Rating", "ratingValue" : "2", "worstRating" : "0", "bestRating" : "5" }, "reviewBody" : "A disaster. The worst book I've ever read, and I've read The Da Vinci Code." } } </script>这确定了该页面是关于Catch-22的,这是 Joseph Heller 于 1961 年 11 月 10 日出版的小说。审稿人已确定,评分系统的参数也已确定。 不同的模式可以组合(或分层)来描述不同的事物。 例如,通过此类标记,您可以明确页面是露天电影放映的事件列表,而有问题的电影是 Wes Anderson与 Steve Zissou 合作的 The Life Aquatic 。
推荐阅读:更好的研究、更好的设计、更好的结果
为什么这有关系?
好的,太好了。 我可以将我的网站标记为它的眼球,它看起来完全一样,但有什么好处? 在我看来,在网站中包含结构化数据有两个主要好处:
- 它使搜索引擎的工作变得更加容易。
他们可以更准确地索引内容,这反过来意味着他们可以更丰富地呈现内容。 - 它有助于使 Web 内容更加全面和有用。
结构化数据为您提供内容的“计算机视角”。 优质的内容非常棒。 彻底标记的优质内容是梦想的东西。
您知道何时看到包含星级的时髦搜索结果吗? 那是结构化数据。 丰富的影评片段? 结构化数据。 当一系列食谱出现时,配料、准备时间等等? 你猜对了。 深入研究任何这些页面的代码,您就会在某处找到标记。 搜索引擎使用结构化数据奖励网站,因为它准确地告诉他们他们正在处理什么。
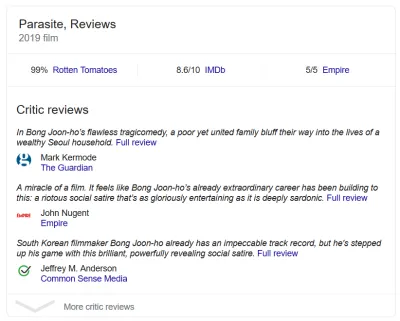
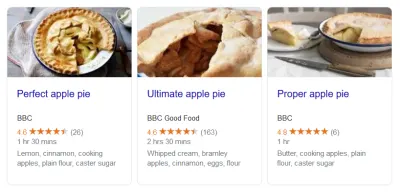
要清楚,这也不仅仅是搜索。 这是其中很大一部分,但不是全部。 结构化数据主要是关于标记和组织内容。 丰富的搜索结果只是使用所述内容的一种方式。 例如,Google 数据集搜索使用 Schema.org/Dataset 标记。
以下是一些有用的结构化数据示例:
- 食谱
- 评论
- 常见问题
- 语音查询
- 活动列表
- 内容操作。
还有数千人。 就像,从字面上看。 Schema.org 最近甚至加快了 Covid-19 标记的发布。 这是一个不断发展的图书馆。
在许多方面,结构化数据是语义网的一个分支,它致力于实现完全机器可读的互联网。 它为您提供了一个机器可读的 Web 内容视角(如果实施得当),可以为人们提供更丰富的功能。
因此,几乎任何拥有网站的人都会从了解什么是结构化数据及其工作原理中受益。 根据 W3Techs 的数据,只有 29.6% 的网站使用 JSON-LD,而 43.2% 的网站根本不使用任何结构化数据格式。 当然,没有义务。 不是每个人都关心 SEO 或机器可读性。 另一方面,对于那些这样做的人来说,目前有很大的机会与竞争对手的网站一较高下。
就像 HTML 迫使您思考内容的组织方式一样,结构化数据让您思考内容。 它让你更彻底。 无论您的网站是关于什么的,如果您梳理相关的架构文档,您几乎肯定会发现您事先没有想到包含的细节。
作为人类,很容易将信息之间的联系视为理所当然。 搜索引擎和计算机程序很聪明,但没有那么聪明。 还没有。 结构化数据将内容翻译成他们可以理解的术语。 这反过来又使他们能够提供更丰富的体验。
资源和进一步阅读
- “SEO结构化数据初学者指南:两部分系列”,Moz的Bridget Randolph
- “什么是模式标记以及为什么它对 SEO 很重要,” Chuck Price,搜索引擎杂志
- “什么是架构? 结构化数据初学者指南,”Luke Harsel,SEMrush
- “JSON-LD:构建有意义的数据 API”,Benjamin Young,推出博客
- “了解结构化数据的工作原理”,面向开发人员的 Google 搜索
- “使用结构化数据标记您的网站”,必应
将结构化数据融入网站设计
将结构化数据编入网站并不像更改元标题那样简单。 它是您网络内容的数据 DNA。 如果你想正确地实施它,那么你需要愿意进入杂草——至少一点点。 以下是开发人员可以采取的几个简单步骤,将结构化数据编织到设计过程中。

注意:我个人赞同整体设计方法,设计和实质齐头并进。 杂耍一堆学科对于网页设计来说并不是什么新鲜事,这只是另一个,如果它融合得很好,它可以加强它周围的其他元素。 将其视为对您网站引擎的增强。 这辆车看起来可能没什么不同,但它的操控性要好得多。
从一个概念开始
我将以我自己为例。 五年来,我和两个朋友每周都在回顾一张专辑作为一种爱好(其他人不时介入)。 我们冷嘲热讽、令人难以忍受的散文目前存放在一个 WordPress 网站中,在我善意但完全无知的关心下,它已经成长为科学怪人的插件怪物。
我们正在重新设计网站,其中(除其他外)需要将结构化数据引入核心设计。 在这里,与任何其他项目一样,首先要做的是确定您的内容是关于什么的。 这个问题你回答得越好,接下来的事情就会越简单。
在我们的例子中,这些是必需品:
- 我们审查音乐专辑;
- 每篇评论都有三名评论者,他们每人通过选择最多三个最喜欢的曲目并在十个中分配个人分数来撰写摘要;
- 这三个分数合并为 30 分的最终分数;
- 从这三个摘要中,我们选择了一段作为我们所有想法的“一目了然”的总结。
其中一些可能听起来有点具体,甚至有点武断(因为确实如此),但您会惊讶地发现其中有多少可以使用结构化数据编织在一起。
下面是修改后的评论页面的样机,以及可以转换为模式标记的信息:
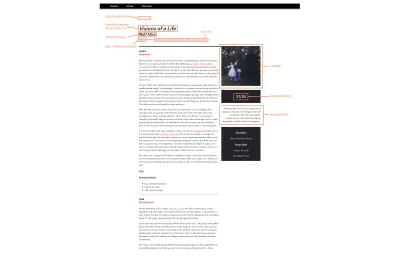
这个过程没有技巧。 我知道内容是关于什么的,所以我知道在哪里查看文档。 在这种情况下,我去 Schema.org/MusicAlbum 并遇到了各种潜在的属性,包括:
-
albumReleaseType -
byArtist -
genre -
producer -
datePublished -
recordedAt
有几十个; 有些是 MusicAlbum 独有的,有些则属于 CreativeWork 的更大范围。 深入研究文档,我发现标记可以连接到音乐元数据百科全书 MusicBrainz。 当我转到 Review 文档时,会展开相同的过程。
从这个简单的页面中,可以收集和组织以下信息:
<script type="application/ld+json"> { "@context": "https://schema.org/", "@type": "Review", "reviewBody": "Whereas My Love is Cool was guilty of trying too hard no such thing can be said of Visions. The riffs roar and the melodies soar, with the band playing beautifully to Ellie Rowsell's strengths.", "datePublished": "October 4, 2017", "author": [{ "@type": "Person", "name": "Andre Dack" }, { "@type": "Person", "name": "Frederick O'Brien" }, { "@type": "Person", "name": "Marcus Lawrence" }], "itemReviewed": { "@type": "MusicAlbum", "@id": "https://musicbrainz.org/release-group/7f231c61-20b2-49d6-ac66-1cacc4cc775f", "byArtist": { "@type": "MusicGroup", "name": "Wolf Alice", "@id": "https://musicbrainz.org/artist/3547f34a-db02-4ab7-b4a0-380e1ef951a9" }, "image": "https://lesoreillescurieuses.files.wordpress.com/2017/10/a1320370042_10.jpg", "albumProductionType": "https://schema.org/StudioAlbum", "albumReleaseType": "https://schema.org/AlbumRelease", "name": "Visions of a Life", "numTracks": "12", "datePublished": "September 29, 2017" }, "reviewRating": { "@type": "Rating", "ratingValue": 27, "worstRating": 0, "bestRating": 30 } } </script>老实说,我可能还会添加更多内容。 最初,我发现了评论页面结构中已经包含的内容(即艺术家、专辑名称、总分),但随后新的问题开始出现。 还有什么更清楚的? 我能补充什么?
这显然应该通过什么是不必要的问题来抵消。 仅仅因为您可以做某事并不意味着您应该做某事。 有“信息太多”之类的东西。 尽管如此,有时更多的细节确实可以使页面更上一层楼。
熟悉架构
没有办法解决它; 让球滚动的最好方法是让自己沉浸在文档中。 有一些工具可以为您实现它(更多内容见下文),但如果您对它的工作原理有适当的了解,您将从标记中获得更多收益。
浏览 Schema.org 文档。 无论您是谁,无论您的网站是为了什么,都有可能有很多相关的模式。 该站点的示例非常好,因此不必停留在理论上。
当然,除此之外的步骤是找到您想要模拟的丰富搜索结果,访问页面,并使用浏览器开发工具查看他们在做什么。 它们通常是了解其内容的优秀网站示例。 您还可以将代码片段或 URL 输入 Google 的结构化数据标记助手,然后生成适当的架构。
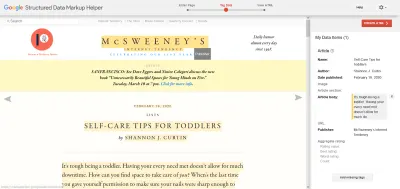
基本原理其实很简单。 一旦您了解它们,就会发现需要花时间去探索和玩弄的选项的广度。 您不希望成为完成设计过程、查看模式选项并开始事后猜测已完成的所有事情的人。
提出正确的问题
既然您已经掌握了丰富的结构化数据知识,那么您就可以更好地为强大的网站奠定基础。 结构化数据有一条相当独特的路线。 在直接意义上,它存在于“引擎盖下”并且是为了计算机的利益而存在的。 同时,它可以为用户带来更丰富的体验。
因此,从技术和用户的角度来看结构化数据是值得的。 结构化数据如何帮助我更好地理解我的网站? 还有哪些其他资源、在线数据库或硬件(例如智能扬声器)可能对您正在做的事情感兴趣? 文档中出现了哪些我没有考虑到的选项? 我要添加它们吗?
识别重复出现的内容类型尤为重要。 可以肯定地说,随着时间的推移,博客可以期待大量的博客文章,因此将结构化数据整合到文章模板中会产生最多的结果。 我上面给出的例子本身就很好,但是标记过程没有理由不能自动化。 这就是我们的计划。
还要考虑人们可能会找到您的内容的方式。 例如,如果有机会突出显示用于语音搜索的副本片段,那就去做吧。 就是这样,或者让搜索引擎自己解决。 没有人比您更了解您的内容,因此请使用描述性标记来利用这种理解。
您无需猜测结构化数据将如何理解内容。 使用 Google 的 Rich Results Tester 之类的工具,您可以准确了解它如何提供可能被忽略的内容形式和含义。
资源和进一步阅读
- “使用微数据开始使用 Schema.org”,Schema.org
- “Schema.org 项目存储库”,GitHub 社区
- “结构化数据标记助手”,谷歌网站管理员
- “将结构化数据添加到您的网页”,Google Developers Codelabs
- “丰富的结果测试”,谷歌
优质内容值得优质标记
你会发现没有比我更支持伟大内容的人了。 每当谷歌推出重大搜索更新时,搜索引擎优化行业就会失去集体意识。 对歇斯底里的反应总是一样的:制作高质量的内容。 我补充说:正确标记它。
熟悉文档并清楚您的网站是关于什么的。 您标记的每条信息都使其更容易被索引并与合适的人共享。
无论您是 Google 的忠实拥护者还是 DuckDuckGo 的忠实拥护者,精神始终如一。 这不是关于排名,而是关于使网站尽可能好。 容纳结构化数据将使您网站的其他方面更好。
您无需相信技术就能了解您的内容是关于什么的——您可以告诉它。 从评论到食谱再到音频搜索,开发人员可以为其内容添加全新的复杂程度。
优化网站以进行搜索的核心和灵魂从未改变:制作出色的内容并尽可能清楚地说明它是什么以及为什么有用。 结构化数据是用于此目的的另一种工具,因此请使用它。