
结构化内容管理系统的无头项目策略
已发表: 2022-03-10这是我希望过去几年在使用无头内容管理系统 (CMS) 运行项目时拥有的指南。 我做过开发人员、用户体验和技术顾问、项目经理、信息架构师和作家。 不同的帽子让我意识到,即使我们现在拥有所谓的“无头”CMS 已有一段时间了,仍然有办法去思考如何最好地使用它们。
现在,我们中的许多人都依赖 JavaScript 框架进行前端工作,使用由组件和组合组成的设计系统,而不仅仅是实现平面页面布局。 在服务器和客户端上运行的 JAMstack 和同构/通用应用程序有很大的吸引力。 最后一个难题是我们如何管理所有内容。
传统的 CMS 正在添加 API 以通过网络请求和 JSON 格式提供内容。 此外,还出现了专门通过 API 提供内容的“无头”CMS。 不过,我在本文中的论点是,我们应该少花时间谈论“无头”,而多花时间谈论“结构化内容” 。 因为这是这些系统的基本品质。 这些系统隐含着对我们的工艺有很多影响,而且在找出我们应该如何处理这些技术的良好模式方面,我们还有很长的路要走。
从人文背景开始从事技术咨询,我学到了很多关于如何组织和处理采用以内容为中心的方法的 Web 项目的知识——无论是使用基于 API 的较新的还是传统的 CMS。 我开始欣赏如何尽早开始使用来自 CMS 的实际实时内容; 在跨学科环境中这样做不仅可以在早期阶段发现复杂性,还可以为所有相关人员提供代理权,并提供机会从最广泛的意义上反思技术和设计的挑战和可能性。
无头 WordPress
每个人都知道,如果一个网站速度慢,用户就会放弃它。 让我们仔细看看创建解耦 WordPress 的基础知识。 阅读相关文章 →
在本文中,我将建议一些总体策略,并提供一些关于如何考虑使用结构化内容的具体、真实的示例。 在撰写本文时,我刚刚开始在一家提供此类内容管理服务的 SaaS 公司工作,用于托管通过 API 交付的内容。 我会提到它,既是因为我过去在作为顾问参与的项目中使用它的经验,也是因为我认为它恰当地说明了我想要表达的观点。 所以认为这是一种免责声明。
话虽如此,几年来我一直在考虑写这篇文章,并且我努力使它适用于您选择使用的任何平台。 因此,事不宜迟,让我们回到二十年前,以便更多地了解我们今天所处的位置。
网络标准的第一步
在 2000 年代初期,Web 标准运动启发了一个领域来改变他们的工作方式。 从“布局优先”的方法来看,他们将我们的注意力引导到如何使用 HTML 对页面上的内容进行语义标记:网站的菜单不是<table> ,而是<nav> ; 标题不是<b> ,而是<h1> 。 这是思考网络内容所扮演的不同角色以帮助用户找到、识别和接受它的重要一步。
网络标准运动引入了语义标记提高了可访问性的论点,这也提高了它在谷歌搜索结果中的排名。 这也标志着我们对网络内容的看法发生了转变。 您的网站不再是展示您的内容的唯一场所。 您还必须考虑您的网页如何在其他视觉环境中呈现,例如在搜索结果或屏幕阅读器中。 后来,社交媒体和共享链接的嵌入式预览推动了这一点。 思维方式从内容的外观转变为内容的含义。 这也恰好是处理结构化内容的关键。
随着连接到互联网的袖珍设备的采用,网络突然成为应用程序的有力竞争者。 然而,竞争主要是为了最终用户的眼球。 许多组织仍然需要在他们的应用程序和不同的网络存在中分发有关其产品和服务的信息。 同时,Web 日趋成熟,JavaScript 和 AJAX 使得通过 API 连接不同的内容源变得更加容易。 今天,我们拥有 GraphQL 和工具,可以让内容获取和状态管理变得更简单。 因此,技术难题的各个部分开始到位。
“一次创建,到处发布”
尽管它主要被描述为“技术转变”,但在 JSON 有效负载中嵌入内容(通过 HTTP 管道传输)对我们如何看待数字内容和周围的工作流程产生了巨大的影响。 在某些方面,它已经有了。 大约十年前,美国国家公共广播电台 (NPR) 的 Daniel Jacobson 客座博客在programmedweb.com 上发表了关于他们的方法的博客,概括为首字母缩略词 COPE,代表“一次创建,随处发布”。 在文章中,他介绍了一个内容管理系统,它通过 API 向多个数字界面提供内容,而不是通过 HTML 渲染机,就像当时(可以说是现在)大多数 CMS 所做的那样。
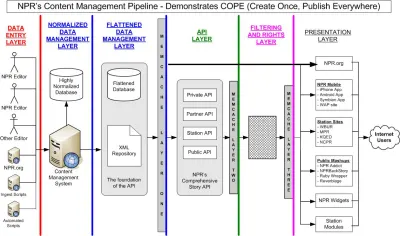
NPR 的 COPE“数据管理层”将成为“无头 CMS”的概念。 在 COPE 的早期,它是通过在 XML 中构建内容来实现的。 今天,JSON 已成为通过 API 传输数据的主要数据格式,包括物联网设备和网络之外的其他系统。 如果您想与聊天机器人、语音界面甚至可视化原型制作软件交换内容,您通常会使用 JSON 口音来谈论 HTTP。
“Uncoining” 术语“无头 CMS”
根据谷歌趋势,直到 2015 年,即 NPR 的 COPE 文章发表六年后,“无头 CMS”的搜索才开始流行。 “无头”一词(至少与数字技术相关,而不是 18 世纪晚期的法国贵族),已经被使用了很长一段时间来谈论没有图形用户界面运行的系统。
注意:有人可能会争辩说,命令行界面确实是“图形化的”,例如服务器上的软件或测试环境(但让我们将其留到另一篇文章中)。
我有两种想法,称这些新的 CMS 为“无头”。 我们也可以称它们为“多头的”——它有很多头。 它们是 CMS 的 Hydras 和 Cerbeuses。 “无头”也通过它们缺乏的能力(即,用于呈现网页的模板引擎)来定义这些系统,而不是通过它们的真正优势来定义它们:使得可以在没有网络约束的情况下构建内容。 话虽如此,截至今天,该类别中的许多解决方案也可以称为“几乎无头尼克”。 因为编辑界面仍然与系统紧密耦合。 他们的“无头”源于他们缺乏模板引擎,即从内容中产生标记的机器。
注意:不过,我几乎肯定会使用一个名为“Mimsy-Porpington”的 CMS(来自哈利波特世界)。
相反,它们通过 API 提供内容,从而为您提供更多灵活性,让您可以更灵活地选择要显示和使用该内容的方式、内容和位置。 这使它们成为流行的 JavaScript 前端框架(如 React、Angular 和 Vue)的完美伴侣。 尽管声称能够向“网站、应用程序和设备”提供内容,但其中大多数仍然受到网络内容工作方式的限制。 这在大多数处理富文本的方式中最为明显——将其存储为 HTML 或 Markdown。
除了模板渲染系统之外,传统的 CMS 也开始添加一些通用的 API,并将其称为“解耦”,以此作为与新竞争对手区分开来的一种方式。 “所有这些,还有 API!”* 是声明。 当涉及到内容建模时,其中一些 CMS 也非常不可知论。 例如,Craft CMS 在您首次安装时几乎不会对您的内容模型做出任何假设。 Wordpress 也在朝着使用 API 进行内容交付的方向发展。 我怀疑 CMS 领域的老玩家和新玩家之间的差距会随着我们的发展而缩小。
尽管如此,在一个组织的文本、图像、视频和媒体都被数字化并暴露给内部和外部用户和客户的时代,将内容管理置于 API(而不是 HTML 渲染器)之后是朝着更复杂的工作方式迈出的重要一步。 不过,是时候从定义他们缺乏的前端渲染能力转向他们真正能为我们做的事情了:给我们一种处理结构化内容的方法。 那么,我们应该称它们为“结构化内容管理系统”吗? 如,“不,鲍勃,这不是你常用的 CMS。 这是一个 SCMS,相信我,它会成为一件事。”
这不是关于头脑,而是关于结构化内容
结构化内容管理系统 (SCMS) 带来的最根本的变化是从根据页面层次结构安排内容转变为您可以自由地为任何您认为合适的目的构建内容。 避免重复内容是一个明显的优势,因为它提高了可靠性并减少了管理负担(您不必处理跨多个渠道的重复内容)。 换句话说:创建一次,到处发布。 如果您只需要在一个系统中更新您的产品描述一次,并且它会在您的产品暴露给用户的任何地方进行更新,那么这显然是一个优势。
尽管 SCMS 供应商经常使用“您的网站和应用程序”来证明对页面结构的不同思考是合理的,但您不必过河才能从结构化的内容结构中获益。 随着 JavaScript 框架的流行,将网站构建为单个组件的组合变得越来越普遍,这些组件可以根据状态和上下文“填充”不同的内容。 您的产品卡片可能会出现在整个 Web 应用程序的许多不同上下文中。 我们看到现代 Web 开发从设置文档和页面转向根据用户输入、算法和自定义的混合组合组件。
这些关于如何制作设计系统的趋势,以及如何鼓励我们通过测试、学习和迭代过程在团队中工作,使得内容管理领域已经成熟,可以采用一些新的思维方式。 一些模式已经出现,但我们还有很多路要走。 因此,根据我在将内容放在首位的团队和项目中工作的经验,以及现在作为为其构建服务的团队的一员(我敦促您注意这里的任何偏见),我想提出一些我认为会有所帮助的策略,并为进一步讨论创造要点。
1. 多学科团队中的方法内容
我相信,平面设计师可以将陈旧的、像素完美的页面交给负责“实施”设计的前端开发人员,这已成为过去。 我们现在制作由更小的组件组成的设计系统,这些组件的布局具有开箱即用的多种可能状态。 通常,这些组件必须对用户生成的输入具有弹性,这意味着您越早将实时内容引入流程越好。 前端开发人员的责任不是重现平面设计师的愿景; 它涉及浏览器如何呈现 HTML、CSS 和 JavaScript 的复杂领域,确保用户界面具有响应性、可访问性和高性能。
在 Netlife(一家专注于用户体验的咨询公司)担任技术顾问时,我看到开发人员、设计师和用户研究人员之间的协作正在取得重大进展。 尽管我们的内容编辑从一开始就一直参与到项目中,但他们的贡献并没有进入设计工作流程,主要是因为技术摩擦。
瓶颈通常是我们无法触及的遗留 CMS,或者构建内容结构需要时间,因为它依赖于设计布局。 这通常导致工作加倍:我们制作了一个 HTML 原型,通常基于从 Markdown 文件中解析的内容,当用户测试完成时,必须在 CMS 堆栈中重新实现,每个人都非常高兴. 这通常是一个昂贵的过程,因为 CMS 中的限制是在过程后期发现的。 它还会对所有部分产生压力,要求“一次就做好”,并为您在设计项目中想要进行的那种实验留下更少的空间。
多学科工作需要灵活的系统
迁移到 SCMS 需要几分钟的时间来编写内容模型(其中字段和 API 立即准备就绪)使我们的流程发生了翻天覆地的变化——而且变得更好。 我记得在项目开始的第一天,我和新 u4.no 的内容编辑器坐在一起。 谈论他们是如何工作的,并希望使用他们的内容。 很快,我们将结论转换为简单的 JavaScript 对象,这些对象立即转换为浏览器中的编辑环境。 找出有用的标题和标题描述。 我们讨论了他们如何希望可以在不同的页面和上下文中重复使用的文本片段,他们在内部将其称为“块”,然后我们在那里创建了它。
在项目开发的早期允许进行这种探索——在我们面前制作界面时,内容编辑器和开发人员一起交谈——感觉很强大。 知道我们可以在她和她的同事开始处理内容的同时继续在 React 中设计前端。 而且不用担心把自己画到一个角落里,就像我们经常对 CMS 所做的那样,其中的结构与您必须如何编写前端部分的代码紧密相关。
内容系统应该允许实验和迭代
除了创意重新设计项目,结构化内容系统还应该允许您继续改进、测试和迭代您的内容,作为整个设计系统的一部分。 UX 设计师应该能够使用 Sketch 或 Framer X 等工具快速制作具有真实内容的原型。您应该能够通过定量测量来增强内容管理,无论是可读性尺度还是内容在使用时的执行方式。
注意:我在上面使用了“用户体验设计师”这个词,尽管我们认为我们都应该——以某种方式——与创造良好用户体验的过程相关联。 我们都是不同设计领域的用户体验设计师。
如果您习惯于直接在网页布局上使用所见即所得的内容,那么使用结构化内容需要稍微适应一下。 然而,它有助于进行更符合数字设计领域发展趋势的对话。 结构化内容让设计人员、开发人员、内容编辑人员、用户研究人员和项目经理组成的团队共同思考系统应如何工作以支持用户的需求和战略目标。 这也需要您以不同的方式思考内容的结构,这将我们带到下一个策略。
2. 你可能不需要啄食顺序
对许多人来说最显着的变化之一是结构化内容系统面向文档的集合和列表,而不是反映网站导航结构的类似文件夹的层次结构。 一旦某些内容要在其他环境中使用——无论是聊天机器人、印刷媒体还是其他网站,这些结构就不再有意义。 传统的 CMS 试图通过允许可重用的内容块来缓解这种情况,但它们仍然需要放置在页面布局上,并且通过 API 进行推理很麻烦。
每一页都有自己的
正如核心模型中所述,当您的主要引荐来源之一是 Google 或社交媒体上的分享时,您应该将每个页面视为登录页面。 如果您查看页面浏览量的分布,您会注意到您的某些页面比其他页面更受欢迎。 除非您是新闻网站,否则那些往往不是新闻,而是那些让用户实现他们希望在您的网站上实现的目标的新闻。 它们是实际发生业务的地方。
您的数字内容应该服务于您自己的战略目标和用户的个人目标的交叉点。 当数字代理 Bengler(sanity.io 的前身)为 oma.eu 制作新网站时,他们并没有按照精心设计的页面层次结构来构建内容。 他们制作了反映组织日常现实的内容类型,即在项目、人员和出版物之后。 事实上,OMA 网站在内容层次结构方面几乎是完全平坦的,首页是由算法和编辑规则混合生成的。
那么,该怎么做呢? 我相信将您的内容考虑为您的组织的心理模型的反映以及它需要什么才能对您的用户需要的任何内容有用。
这是一个基本示例:在构建员工页面时,您可能应该从名为person的内容类型开始。 一个人可以有姓名、联系信息、图像、不同的组织角色和简短的传记。 个人文档可以在联系人列表、文章作者署名、聊天支持界面和构建访问徽章中重复使用。 也许您已经拥有一个知道这些人是谁并且带有 API 的内部系统? 太好了,然后与之同步。
不要迷失在本体兔子洞中
回到谷歌索引网页的方式以及他们如何尝试索引世界信息是很有用的。 这就是他们在链接数据(RDFa、微格式、JSON-LD)上花费时间和精力的原因。 如果您使用 JSON-LD 元素注释您的网页,您将在搜索结果中更显眼。 当您的信息应该由语音助手说出并显示在助手 UI 中时,它也很重要。 如果您的内容已经结构化并且可以在 API 中轻松使用,那么您可以相对容易地以这些微格式实现它。
不过,我不确定我是否会建议全神贯注于 schema.org 的本体和各种链接数据资源,至少不是出于编辑目的。 你很快就会迷失在一个试图制作完美的柏拉图式结构的兔子洞中。
新闻快讯:它永远不会,因为世界是一个混乱的地方,因为人们对事物的看法不同。
更重要的是在一个系统中构建您的内容,该系统具有直观意义,并且可以随着需求的变化而适应。 这就是为什么在设计和开发过程的早期就开始内容建模很重要——您需要了解如何使用它。
摘自现实,而非 CMS 约定
遵循 CMS 附带的任何约定可能很诱人。 还记得 Wordpress 是如何为您提供“帖子”和“页面”的,突然间,所有东西都需要放入这些框中吗? 所见即所得的富文本字段很灵活,因为它允许您输入任何内容,但内容不会结构化且易于调整——它只能灵活一次。 但是您需要一些地方来开始您的内容模型映射。 我的建议是从与人交谈开始,即与作者和读者交谈。
人们如何在内部谈论内容? 人们怎么称呼不同的东西? 你可以进行自由列表练习,这是民族志学家用来绘制民间分类法的一种方法。 例如,您可以问:
“说出我们组织中不同类型的内容。”
或者,在更具体的层面上:
“你能说出我们在这个组织中拥有的不同类型的报告吗?”
这项调查的重点是梳理出人们所携带的内在分类法,而不是他们对事物的看法或感受(这往往会破坏设计过程)。 在获得一份非常详尽的清单之前,您不必问特别多的问题。 您可能会发现列表的某些部分来自您当前 CMS 中的约定(如果您要进行一些改造,这很好知道)。 现在您应该与您的编辑交谈并尝试确定他们需要内容做什么。
您可以提出的一些问题可能如下:
- 您是否需要在多个地方使用此内容? 在哪里?
- 内容类型之间有什么不同的关系?
- 我们今天和明天需要在哪里显示内容?
- 我们需要以哪些方式对内容进行排序? 排序可以由用户通过算法完成,还是必须手动完成?
- 其他系统中是否有我们可以同步的系统或数据库以防止重复?
- 我们希望规范内容放在哪里? SCMS 应该是它的来源,还是只是增加现有内容,例如产品管理系统中产品的营销副本?
这并不意味着您必须用现在不温不火的洗澡水来抛弃传统的信息架构。 如果文章是您组织的内容现实的一部分,那么将文章作为内容类型仍然是有意义的。 但也许您并不真正需要categories的抽象约定,因为这些文章如何引用其中的服务或产品的类型。 这种关系允许在有意义的情况下查询这些文章,而不需要某人将“文章类别管理”作为其工作描述的一部分。

这篇文章也是让内容与表示层完全分离变得困难的原因。 我们习惯于考虑文章的布局和样式,但是在一个期望您将自己的内容托管在自己的域上,然后将其联合到诸如 medium.com 之类的平台上的时代,您已经放弃了控制视觉呈现。 这将我们带到下一个策略。
3. 表示上下文也是内容类型
准备好重新设计
您还希望能够适应并快速更改网站的导航结构,而无需重建整个内容架构或与严格的文件夹式界面作斗争。 您还希望能够拥有一些内容层次结构,因为它有时是有意义的,有时它比两个层次更深,API 优先 CMS 部门中的大多数接口都无法提供太多帮助。
有趣的是,聊天机器人的内容管理系统倾向于使用类似的层次结构来安排意图树和对话流。 这就是说内容层次结构在不同的渠道中扮演不同的角色,但它们通常提供浏览内容的方式。 解决此问题的一种方法是创建导航类型,您可以在其中通过引用排列内容,并为网页、菜单或会话界面的路径构建路径。
关系建议
引用(或关系)是使结构化内容系统成为可能的原因,它确实是我们在处理网络内容时所处理的一切的核心(这就是它首先被比喻称为网络的原因)。 能够在内容位之间进行引用是一件非常强大的事情,但就后端如何写入和检索此类数据而言,它也可能代价高昂。 因此,如果您有大量文档,您可能不得不换一种方式思考,因为规模很少是免费提供的。
还值得考虑的是,您并不总是需要显式引用来连接数据; 大多数情况下,它可以通过与内容有关的标准来完成,例如“给我这个地理位置内的所有人和所有建筑物”。 建筑物和人员不需要相互显式引用,只要它隐含在两种内容类型的位置字段中即可。
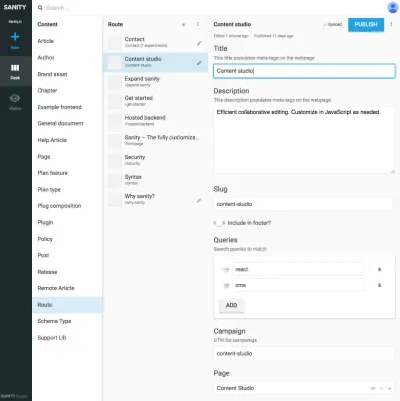
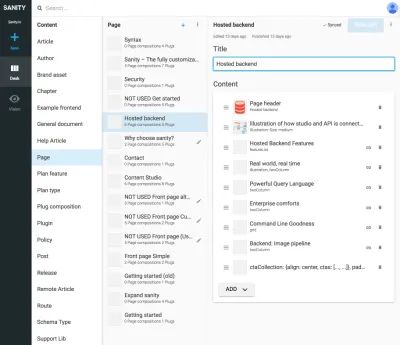
当您不能将其留给表示层中的算法来连接数据时,表示类型和其他内容类型之间的引用很有用。 明确地绘制这些表示类型并组合引用的内容可能看起来有点麻烦,但它可以解决您在 SCMS 中经常遇到的问题:很难知道内容在哪里被使用。 通过包含导航类型,您将明确地将内容与演示相关联,而不仅仅是一个。 这使得可以独立于它们所引导的内容来推理使用导航结构。
例如,在屏幕截图中,我们将 Google Experiments 与路由类型相关联,允许添加由内容引用组成的多个页面,这意味着我们可以运行 A/B 测试而几乎没有内容重复。 由于如果我们尝试删除其他文档引用的内容也会收到警告,因此这种结构化方式将阻止我们删除不应该删除的内容。
跨内容类型的关系是一把双刃剑。 它提高了可持续性,是避免重复的关键。 另一方面,您可以轻松地削减自己,因为您在内容之间建立了依赖关系,这(如果不透明)可能会导致显示数据的渠道发生意外更改。 例如,如果我们可以在没有警告的情况下删除“路由”使用的“页面”,那将会很糟糕。
这将我们引向下一个策略,该策略(当然!)在今天部分超出了普通用户的能力,因为它与不同系统的架构方式有关。 不过,还是值得思考的。
4. 不要把富文本放在角落里
富文本不仅仅是 HTML
我可以理解为什么 HTML 在数字内容中如此流行,但我知道它也来自某些东西; 它是 SGML 的子集,是一种构造机器可读文档的通用方法。 正如 Claire L. Evans 在精彩的著作《宽带:创造互联网的女性的不为人知的故事》(2018 年)中指出的那样,当引入 HTML 时,已经有一个充满活力的社区在思考链接文档。 Tim Berners-Lee 的提议比当时的许多其他系统要简单得多,但这可能就是它流行起来并使得——截至目前——开放、免费的网络成为可能的原因。
当您使用万维网上的浏览器时,HTML 非常棒。 如果您是一位想要发布以简单 HTML 结尾的内容的作家,那么 Markdown 非常棒。 如果您希望将富文本内容轻松集成到非浏览器或流行的 JavaScript 框架中,该框架允许您在复杂组件中使用 JavaScript 增强 HTML(是的,我们正在谈论 React 和 Vue.js) ,在您的 API 响应中包含 HTML 开始有点麻烦——尤其是当您需要解析它时。
几乎每个人都这样做,即使是街区里的新孩子:我浏览了 headlesscms.org 上的所有供应商并浏览了文档,还为那些没有提到它的人注册了。 除了两个例外,它们都将富文本存储为 HTML 或 Markdown。 如果您所做的只是使用 Jekyll 来渲染网站,或者如果您喜欢在 React 中使用 dangerouslySetInnerHTML,那很好。 但是,如果您想在不在网络上的界面中重用您的内容怎么办? 或者,如果您想在富文本编辑器中获得更多控制和功能? 或者只是希望在流行的前端框架之一中更轻松地呈现富文本,并让您的组件处理富文本内容的不同部分? 好吧,您要么必须找到一种聪明的方法来将 Markdown 或 HTML 解析为您需要的内容,或者更方便的是,首先将其存储得更合理。
例如,如果您想将富文本输出到语音界面怎么办? 我们知道语音助手越来越受欢迎。 这些助手最流行的平台能够通过 API 获取语音内容的文本。 然后你想利用诸如语音合成标记语言之类的东西。 可移植文本系统对富文本采取了一种更加不可知论的方法,它允许您为不同类型的界面调整相同的内容。
推荐阅读:使用 SpeechSynthesis 接口进行实验
可移植文本作为不可知的富文本模型
当您主要为网络制作内容时,可移植文本也很有用。 如果您希望能够使用数据结构(例如富文本脚注或内联编辑注释)嵌套和扩充您的文本,该怎么办? 或者 A/B 测试案例的替代短语或措辞? Markdown 和 HTML 很快就达不到要求,您将不得不依赖添加特殊短代码标签之类的东西,就像 Wordpress 解决了它一样。 使用可移植文本,您可以对内容结构进行不可知论的表示,而无需结合特定的实现。 Your content ends up being more sustainable and flexible for new redesigns and implementations.
There are also other advantages to portable text, especially if you want to be able to edit content collaboratively and in real time (as you do in Google Docs); you need to store rich text in another structure than HTML. If you do, you'll also be able to take advantage of microservices and bots, such as spaCy, in order to annotate and augment your content without locking the document.
As for now, portable text isn't widely adopted, but we're seeing movements towards it. The specification isn't very complex and can be explored at portabletext.org.
5. Make Sure Your SCMS Is In Service For Your Editors, And Not The Other Way Around
Digital content isn't just used for your organization's online web page leaflets anymore. For most of us, it encapsulates and defines how your organization is understood by the world, both from those within it and those outside: From product copy, micro texts to blog posts, chatbot responses, and strategy documents. We are millions of people that have to log into some CMS every day and navigate interfaces that were imagined twenty years ago with the assumptions of people who have never made much effort to user test or challenge their interfaces. Countless hours have been wasted away trying to fit a modern frontend experience into a page layout machine. Fortunately, this is soon a thing of the past.
As a technology consultant, I had to read through pages of technical specification whenever someone thought it was time to acquire a new CMS for themselves. There were demands from which server architecture it should run on (Windows servers, of course) to their ability to render “carousels” and “being able to edit web pages in place”, despite also requesting a “modular redesign”. When editors had been allowed to contribute to these specifications, they were also often dated to the what the editors had begotten used to. They seemed not aware that they could demand better user experiences, because enterprise software has to be big, lumpy and boring.
This is partly the fault of us making these systems. We tend to communicate technology features and specifications, and less what the everyday situation working with these systems look like. Sure, for a frontend designer, something supporting GraphQL is shorthand for how conveniently she is able to work against the backend, but on a higher level, it's about the systems ability to accommodate for emerging workflows, where a content model could survive visual redesigns and design systems should be resilient to changes of its content.
Questions To Ask Of Your (S)CMS
If we are to embrace design processes, we can't know prior to solving the problem whether the user tasks are best solved by making carousels ( newsflash: most probably not ), or whether A/B-testing makes sense for your case, even though it sounds cool.
Instead, ask questions like this:
- Is it possible, and how exactly will multi-disciplinary teams work with this system?
- How easy is it to change and migrate the content model?
- How does it deal with file and image assets?
- Has the editorial interface been user tested?
- To what extent can the system be configured and customized to special workflows and needs of the editorial team?
- How easy is it to export the content in a moveable format?
- How does the system accommodate for collaboration?
- Can content models be version controlled?
- How easy is it to integrate the system with a larger ecosystem of flowing information?
The goal of these questions is to explore to what degree a content management system allows for a cross-disciplinary team to work effortlessly together, without too many bottle-necks or long deployment cycles. They also push the focus to be more about the content should be doing, and less about how things should look in a given context. Leave that for the design processes, where user testing probably will challenge assumptions one may have when looking into getting a new content system.
There are, of course, many factors in addition to this that probably have to be taken into consideration. The easiest thing to assess is the fiscal cost of software licenses and API-related costs if you are on a hosted service. The invisible cost (in time and attention spent by the team working with the system), is harder to estimate. From my experience, many of the SCMSs in combination with one of the popular frontend frameworks can significantly cut development time and allow for an agile ( there's my coin for the swear jar ) design process. With the caveat that your team is prepared to solve some of the problems that come out of the box with traditional CMSs.
Towards Structured Content
The ways we work with digital content has changed dramatically since the World Wide Web made working with interconnected documents mainstream. Organizations, businesses, and corporations have amassed gigabytes of this content, which now is stuck in rigid page hierarchies, HTML markup, and clunky user interfaces.
Using a Structured Content Management System can be a great way to free your content from a paradigm that begins to feel its age. But it isn't a trivial exercise, and success comes from being able to work multi-disciplinary and put your content model to the test. You need to get rid of some conventions you have grown used to by dealing with CMSs designed to output hierarchical websites. That means that you need to think differently about ordering content, make presentations types in order to make it easier to orchestrate content across multiple channels and to consider how you structure rich text so that it can be used outside of HTML contexts.
This article deals with some of the high-level concerns working with SCMSs. There are, of course, loads of exciting challenges when you start working with this in your team. You have to rethink stuff we've taken for granted for many years, but that's probably a good thing. Because we are forced to evaluate our content, not only from its place on a digital page but from its role in a larger system that works for whatever goals your organization and your users may have.
I believe that we can achieve content models that are more meaningful and easier to sustain in the long run, and that means saving time and expenses. It means more flexibility in terms of inventing new outputs and services, and less tie in with software vendors. Because a well-made Structured Content Management System will make it easy for you to take your content and go elsewhere. And that makes for some interesting competition. Hopefully, all in favor of the users.