
使用机器学习进行股市预测 [分步实施]
已发表: 2021-02-26目录
介绍
股票市场的预测和分析是一些最复杂的任务。 造成这种情况的原因有很多,例如市场波动以及决定市场上特定股票价值的许多其他独立和独立因素。 这些因素使得任何股票市场分析师都很难准确地预测涨跌。
然而,随着机器学习及其强大算法的出现,最新的市场分析和股市预测发展已经开始将这些技术用于理解股市数据。
简而言之,机器学习算法被许多组织广泛用于分析和预测股票价值。 本文将通过使用 Python 中的几种机器学习算法来分析和预测一个流行的全球在线零售店的股票价值的简单实现。
问题陈述
在我们开始执行程序以预测股票市场价值之前,让我们可视化我们将要处理的数据。 在这里,我们将分析来自全国证券交易商自动报价协会 (NASDAQ) 的微软公司 (MSFT) 的股票价值。 股票价值数据将以逗号分隔文件 (.csv) 的形式呈现,可以使用 Excel 或电子表格打开和查看。
MSFT 的股票在纳斯达克注册,并在股票市场的每个工作日更新其价值。 请注意,市场不允许在周六和周日进行交易; 因此,两个日期之间存在间隔。 对于每个日期,记录股票的开盘价、该股票在同一天的最高价和最低价,以及当天结束时的收盘价。
调整后的收盘价显示了股息发布后的股票价值(技术性太强!)。 此外,还给出了市场中股票的总成交量,有了这些数据,机器学习/数据科学家的工作就可以研究数据并实施可以从微软公司股票历史中提取模式的几种算法数据。

长短期记忆
为了开发机器学习模型来预测微软公司的股票价格,我们将使用长短期记忆(LSTM)技术。 它们用于通过乘法和加法对信息进行小的修改。 根据定义,长期记忆 (LSTM) 是一种用于深度学习的人工循环神经网络 (RNN) 架构。
与标准的前馈神经网络不同,LSTM 具有反馈连接。 它可以处理单个数据点(如图像)和整个数据序列(如语音或视频)。 为了理解 LSTM 背后的概念,让我们举一个手机在线客户评论的简单例子。
假设我们要购买手机,我们通常会参考认证用户的网络评论。 根据他们的想法和投入,我们决定手机的好坏,然后购买。 当我们继续阅读评论时,我们会寻找诸如“惊人”、“好相机”、“最佳电池备份”等关键字,以及与手机相关的许多其他术语。
我们往往会忽略英语中常见的“it”、“gave”、“this”等词。因此,当我们决定是否购买手机时,我们只记得上面定义的这些关键词。 很可能,我们忘记了其他词。
这与长短期记忆算法的工作方式相同。 它只记住相关信息并使用它来进行预测,而忽略不相关的数据。 通过这种方式,我们必须建立一个 LSTM 模型,该模型基本上只识别有关该股票的基本数据并排除其异常值。
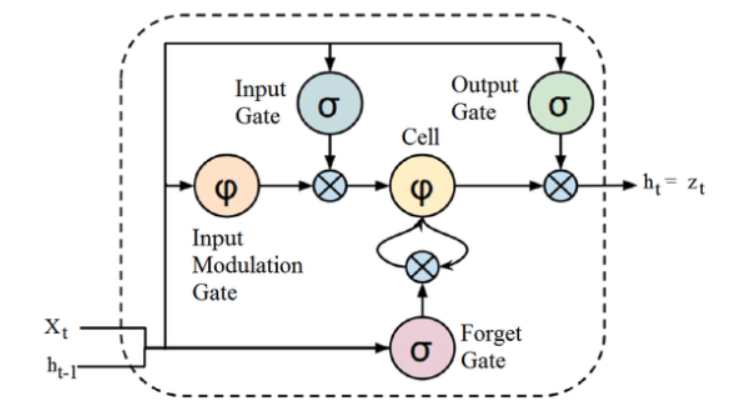
资源
虽然上面给出的 LSTM 架构的结构起初看起来很有趣,但记住 LSTM 是循环神经网络的高级版本就足够了,它保留了内存来处理数据序列。 它可以删除或添加信息到细胞状态,由称为门的结构仔细调节。
LSTM 单元包括一个单元、一个输入门、一个输出门和一个遗忘门。 细胞在任意时间间隔内记住值,三个门调节信息流入和流出细胞。
计划实施
我们将继续使用 LSTM 在 Python 中使用机器学习预测股票价值的部分。
第 1 步 - 导入库
众所周知,第一步是导入预处理微软公司股票数据所需的库以及构建和可视化 LSTM 模型输出所需的其他库。 为此,我们将使用 TensorFlow 框架下的 Keras 库。 所需的模块是从 Keras 库中单独导入的。
#导入库
将熊猫作为 PD 导入
将 NumPy 导入为 np
%matplotlib 内联
导入matplotlib。 pyplot 作为 plt
导入 matplotlib
来自sklearn。 预处理导入 MinMaxScaler
来自喀拉斯。 层导入 LSTM,密集,辍学
从 sklearn.model_selection 导入 TimeSeriesSplit
从 sklearn.metrics 导入 mean_squared_error, r2_score
导入matplotlib。 日期作为任务
来自sklearn。 预处理导入 MinMaxScaler
从 sklearn 导入线性模型
来自喀拉斯。 模型导入顺序
来自喀拉斯。 图层导入密集
导入 Keras。 后端为 K
来自喀拉斯。 回调导入 EarlyStopping
来自喀拉斯。 优化器导入 Adam
来自喀拉斯。 模型导入 load_model
来自喀拉斯。 图层导入 LSTM
来自喀拉斯。 utils.vis_utils 导入 plot_model
第 2 步 – 可视化数据
使用 Pandas Data 阅读器库,我们将本地系统的股票数据作为逗号分隔值 (.csv) 文件上传,并将其存储到 pandas DataFrame。 最后,我们还要查看数据。
#获取数据集
df = pd.read_csv(“MicrosoftStockData.csv”,na_values=['null'],index_col='Date',parse_dates=True,infer_datetime_format=True)
df.head()
从世界顶级大学在线获得AI 认证- 硕士、行政研究生课程和 ML 和 AI 高级证书课程,以加快您的职业生涯。
第 3 步 – 打印 DataFrame 形状并检查 Null 值。
在这又一个关键步骤中,我们首先打印数据集的形状。 为了确保数据框中没有空值,我们检查它们。 数据集中存在的空值往往会在训练期间引起问题,因为它们充当异常值,导致训练过程中出现很大差异。
#打印数据框形状并检查空值
打印(“数据框形状:”,df.shape)
打印(“空值存在:”,df.IsNull().values.any())
>> 数据框形状:(7334, 6)
>>存在空值:False
| 日期 | 打开 | 高的 | 低的 | 关闭 | 调整关闭 | 体积 |
| 1990-01-02 | 0.605903 | 0.616319 | 0.598090 | 0.616319 | 0.447268 | 53033600 |
| 1990-01-03 | 0.621528 | 0.626736 | 0.614583 | 0.619792 | 0.449788 | 113772800 |
| 1990-01-04 | 0.619792 | 0.638889 | 0.616319 | 0.638021 | 0.463017 | 125740800 |
| 1990-01-05 | 0.635417 | 0.638889 | 0.621528 | 0.622396 | 0.451678 | 69564800 |
| 1990-01-08 | 0.621528 | 0.631944 | 0.614583 | 0.631944 | 0.458607 | 58982400 |
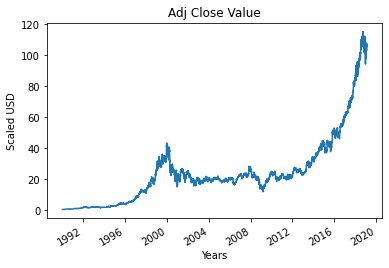
第 4 步 – 绘制真实调整后的收盘价
使用机器学习模型预测的最终输出值是调整后的收盘值。 该值代表股票在该特定股票市场交易日的收盘价。
#绘制真正的调整关闭值
df['Adj Close'].plot()
第 5 步 – 设置目标变量并选择特征
在下一步中,我们将输出列分配给目标变量。 在这种情况下,它是微软股票的调整后相对价值。 此外,我们还选择了作为目标变量(因变量)的自变量的特征。 考虑到培训目的,我们选择了四个特征,它们是:
- 打开
- 高的
- 低的
- 体积
#设置目标变量
output_var = PD.DataFrame(df['Adj Close'])
#选择特征
features = ['Open', 'High', 'Low', 'Volume']
第 6 步 - 缩放
为了减少表中数据的计算成本,我们将股票值缩小到 0 到 1 之间的值。这样,所有的大数据都被减少了,从而减少了内存使用。 此外,我们可以通过缩小规模来获得更高的准确性,因为数据不会以巨大的价值分散。 这是由 sci-kit-learn 库的 MinMaxScaler 类执行的。

#缩放
缩放器 = MinMaxScaler()
feature_transform = scaler.fit_transform(df[features])
feature_transform= pd.DataFrame(columns=features, data=feature_transform, index=df.index)
feature_transform.head()
| 日期 | 打开 | 高的 | 低的 | 体积 |
| 1990-01-02 | 0.000129 | 0.000105 | 0.000129 | 0.064837 |
| 1990-01-03 | 0.000265 | 0.000195 | 0.000273 | 0.144673 |
| 1990-01-04 | 0.000249 | 0.000300 | 0.000288 | 0.160404 |
| 1990-01-05 | 0.000386 | 0.000300 | 0.000334 | 0.086566 |
| 1990-01-08 | 0.000265 | 0.000240 | 0.000273 | 0.072656 |
如上所述,我们看到与上面给出的真实值相比,特征变量的值被缩小到更小的值。
第 7 步 - 拆分为训练集和测试集。
在将数据输入训练模型之前,我们需要将整个数据集拆分为训练集和测试集。 机器学习 LSTM 模型将根据训练集中存在的数据进行训练,并在测试集上测试其准确性和反向传播。
为此,我们将使用 sci-kit-learn 库的 TimeSeriesSplit 类。 我们将分割数设置为 10,表示将 10% 的数据用作测试集,90% 的数据将用于训练 LSTM 模型。 使用这种时间序列拆分的优势在于,拆分的时间序列数据样本以固定的时间间隔进行观察。
#拆分为训练集和测试集
timesplit= TimeSeriesSplit(n_splits=10)
对于 train_index,timesplit.split(feature_transform) 中的 test_index:
X_train, X_test = feature_transform[:len(train_index)], feature_transform[len(train_index): (len(train_index)+len(test_index))]
y_train, y_test = output_var[:len(train_index)].values.ravel(), output_var[len(train_index): (len(train_index)+len(test_index))].values.ravel()
第 8 步 - 为 LSTM 处理数据
一旦训练集和测试集准备就绪,我们就可以在构建 LSTM 模型后将其输入。 在此之前,我们需要将训练集和测试集数据转换为 LSTM 模型能够接受的数据类型。 我们首先将训练数据和测试数据转换为 NumPy 数组,然后将它们重塑为格式(样本数,1,特征数),因为 LSTM 要求数据以 3D 形式提供。 我们知道,训练集中的样本数是7334的90%,也就是6667,特征数是4,训练集reshape为(6667, 1, 4)。 同样,测试集也被重塑。
#处理LSTM的数据
trainX =np.array(X_train)
testX =np.array(X_test)
X_train = trainX.reshape(X_train.shape[0], 1, X_train.shape[1])
X_test = testX.reshape(X_test.shape[0], 1, X_test.shape[1])
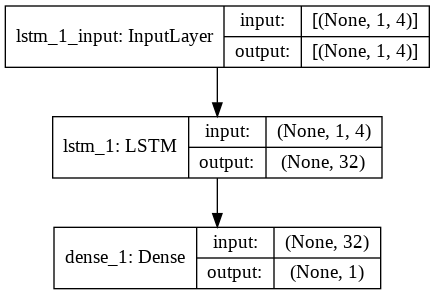
第 9 步 - 构建 LSTM 模型
最后,我们来到了构建 LSTM 模型的阶段。 在这里,我们创建了一个带有一个 LSTM 层的 Sequential Keras 模型。 LSTM 层有 32 个单元,紧随其后的是 1 个神经元的密集层。
我们使用 Adam Optimizer 和均方误差作为编译模型的损失函数。 这两者是 LSTM 模型最优选的组合。 此外,还绘制了模型并显示在下方。
#构建 LSTM 模型
lstm = 顺序()
lstm.add(LSTM(32, input_shape=(1, trainX.shape[1]), activation='relu', return_sequences=False))
lstm.add(密集(1))
lstm.compile(损失='mean_squared_error',优化器='adam')
plot_model(lstm, show_shapes=True, show_layer_names=True)
第 10 步 - 训练模型
最后,我们使用 fit 函数在 100 个 epoch 的训练数据上训练上面设计的 LSTM 模型,批量大小为 8。
#模型训练
历史= lstm.fit(X_train,y_train,epochs=100,batch_size=8,verbose=1,shuffle=False)
纪元 1/100
834/834 [===============================] – 3s 2ms/step – 损失:67.1211
纪元 2/100
834/834 [===============================] – 1s 2ms/步 – 损失:70.4911
纪元 3/100
834/834 [===============================] – 1s 2ms/步 – 损失:48.8155
纪元 4/100
834/834 [===============================] – 1s 2ms/步 – 损失:21.5447
纪元 5/100
834/834 [===============================] – 1s 2ms/步 – 损失:6.1709
时代 6/100
834/834 [===============================] – 1s 2ms/步 – 损失:1.8726
纪元 7/100
834/834 [===============================] – 1s 2ms/步 – 损失:0.9380
纪元 8/100
834/834 [===============================] – 2s 2ms/步 – 损失:0.6566
纪元 9/100
834/834 [===============================] – 1s 2ms/步 – 损失:0.5369
纪元 10/100
834/834 [===============================] – 2s 2ms/步 – 损失:0.4761
.
.
.
.
纪元 95/100
834/834 [===============================] – 1s 2ms/步 – 损失:0.4542
纪元 96/100
834/834 [===============================] – 2s 2ms/步 – 损失:0.4553
纪元 97/100
834/834 [===============================] – 1s 2ms/步 – 损失:0.4565
纪元 98/100
834/834 [===============================] – 1s 2ms/步 – 损失:0.4576
99/100 纪元
834/834 [===============================] – 1s 2ms/步 – 损失:0.4588
纪元 100/100
834/834 [===============================] – 1s 2ms/步 – 损失:0.4599
最后,我们看到损失值在 100 个 epoch 的训练过程中随时间呈指数下降,达到了 0.4599
第 11 步 – LSTM 预测
准备好我们的模型后,就可以在测试集上使用使用 LSTM 网络训练的模型并预测 Microsoft 股票的相邻收盘价了。 这是通过在构建的 lstm 模型上使用简单的预测功能来执行的。
#LSTM 预测
y_pred= lstm.predict(X_test)
第 12 步 – 真实与预测的 Adj 收盘值 – LSTM
最后,由于我们已经预测了测试集的值,我们可以绘制图表来比较 Adj Close 的真实值和 Adj Close 的 LSTM 机器学习模型的预测值。
#True 与预测的 Adj 收盘价 – LSTM
plt.plot(y_test, label='真值')
plt.plot(y_pred, label='LSTM 值')
plt.title(“LSTM 预测”)
plt.xlabel('时间刻度')
plt.ylabel('按比例缩放美元')
plt.legend()
plt.show()
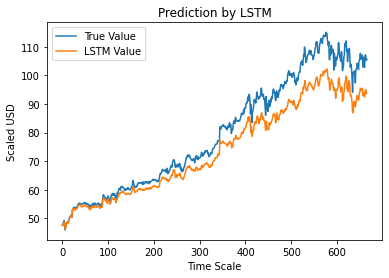
上图显示,上面构建的非常基本的单个 LSTM 网络模型检测到了一些模式。 通过微调几个参数并在模型中添加更多 LSTM 层,我们可以更准确地表示任何给定公司的股票价值。
结论
如果您有兴趣了解有关人工智能示例、机器学习的更多信息,请查看 IIIT-B 和 upGrad 的机器学习和 AI 执行 PG 计划,该计划专为工作专业人士设计,提供 450 多个小时的严格培训、30 多个案例研究和分配,IIIT-B 校友身份,5 个以上实用的实践顶点项目和顶级公司的工作协助。
你能用机器学习预测股市吗?
今天,我们有许多指标来帮助预测市场趋势。 然而,我们只需要一台高性能计算机就能找到最准确的股市指标。 股票市场是一个开放的系统,可以看作是一个复杂的网络。 该网络由股票、公司、投资者和交易量之间的关系组成。 通过使用像支持向量机这样的数据挖掘算法,您可以应用数学公式来提取这些变量之间的关系。 股市现在超出了人类的预测。
哪种算法最适合股市预测?
为获得最佳结果,您应该使用线性回归。 线性回归是一种统计方法,用于确定两个不同变量之间的关系。 在这个例子中,变量是价格和时间。 在股市预测中,价格是自变量,时间是因变量。 如果可以确定这两个变量之间的线性关系,那么就有可能准确预测未来任何时候股票的价值。
股市预测是分类问题还是回归问题?
在我们回答之前,我们需要了解股市预测的含义。 是二分类问题还是回归问题? 假设我们想预测一只股票的未来,未来意味着下一天、下周、下个月或下一年。 如果股票在某个时间点的过去表现是输入,未来是输出,那么这是一个回归问题。 如果一只股票的过去表现和一只股票的未来是独立的,那么它就是一个分类问题。