
通过 AWS S3 在多个服务器之间共享数据
已发表: 2022-03-10在为处理用户上传的文件提供某些功能时,该文件必须在整个执行过程中对进程可用。 简单的上传和保存操作没有问题。 但是,如果在保存之前必须对文件进行操作,并且应用程序在负载平衡器后面的多个服务器上运行,那么我们需要确保每次运行该进程的任何服务器都可以使用该文件。
例如,多步骤“上传您的用户头像”功能可能需要用户在第 1 步上传头像,在第 2 步裁剪,最后在第 3 步保存。在第 3 步将文件上传到服务器后1,该文件必须可用于处理步骤 2 和 3 的请求的任何服务器,这可能与步骤 1 相同,也可能不同。
一种天真的方法是将步骤 1 中上传的文件复制到所有其他服务器,这样文件就可以在所有服务器上使用。 然而,这种方法不仅极其复杂而且不可行:例如,如果站点运行在来自多个区域的数百台服务器上,则无法实现。
一种可能的解决方案是在负载均衡器上启用“粘性会话”,它总是为给定会话分配相同的服务器。 然后,步骤 1、2 和 3 将由同一服务器处理,并且在步骤 1 上传到此服务器的文件对于步骤 2 和 3 仍然存在。但是,粘性会话并不完全可靠:如果在步骤 1 之间2 该服务器崩溃,然后负载均衡器将不得不分配不同的服务器,从而破坏功能和用户体验。 同样,在特殊情况下,总是为会话分配相同的服务器可能会导致负载过重的服务器的响应时间变慢。
更合适的解决方案是将文件的副本保存在所有服务器都可以访问的存储库中。 然后,在步骤 1 将文件上传到服务器后,该服务器会将其上传到存储库(或者,文件可以直接从客户端上传到存储库,绕过服务器); 服务器处理步骤 2 将从存储库下载文件,对其进行操作,然后再次上传; 最后,服务器处理步骤 3 将从存储库中下载并保存。
在本文中,我将描述后一种解决方案,它基于在 Amazon Web Services (AWS) Simple Storage Service (S3)(一种用于存储和检索数据的云对象存储解决方案)上存储文件的 WordPress 应用程序,通过 AWS 开发工具包进行操作。
注1:对于裁剪头像等简单功能,另一种解决方案是完全绕过服务器,通过Lambda函数直接在云端实现。 但由于本文是关于将服务器上运行的应用程序与 AWS S3 连接起来,因此我们不考虑这种解决方案。
注意 2:为了使用 AWS S3(或任何其他 AWS 服务),我们需要有一个用户帐户。 亚马逊在这里提供为期 1 年的免费套餐,这足以试验他们的服务。
注 3:有用于将文件从 WordPress 上传到 S3 的 3rd 方插件。 一个这样的插件是 WP Media Offload(精简版可在此处获得),它提供了一个很棒的功能:它将上传到媒体库的文件无缝传输到 S3 存储桶,这允许解耦站点的内容(例如在/wp-content/uploads) 来自应用程序代码。 通过解耦内容和代码,我们能够使用 Git 部署我们的 WordPress 应用程序(否则我们不能,因为用户上传的内容没有托管在 Git 存储库中),并将应用程序托管在多个服务器上(否则,每个服务器都需要保留所有用户上传内容的副本。)
创建存储桶
创建存储桶时,我们需要考虑存储桶名称:每个存储桶名称在 AWS 网络上必须是全局唯一的,因此即使我们想将存储桶称为“头像”之类的简单名称,该名称可能已经被使用,那么我们可以选择更独特的东西,比如“avatars-name-of-my-company”。
我们还需要选择存储桶所在的区域(该区域是数据中心所在的物理位置,位置遍布全球。)
该区域必须与我们的应用程序部署的区域相同,以便在流程执行期间访问 S3 快速。 否则,用户可能不得不等待额外的几秒钟来上传/下载图像到/从遥远的位置。
注意:只有当我们还使用 Amazon 的云上虚拟服务器服务 EC2 来运行应用程序时,才有意义使用 S3 作为云对象存储解决方案。 相反,如果我们依赖其他公司来托管应用程序,例如 Microsoft Azure 或 DigitalOcean,那么我们也应该使用他们的云对象存储服务。 否则,我们的站点将因数据在不同公司的网络之间传输而产生开销。
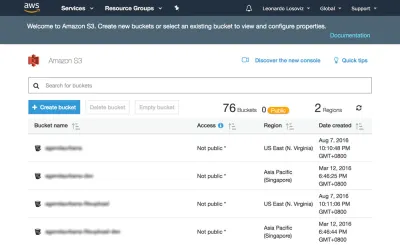
在下面的屏幕截图中,我们将看到如何创建用于上传用户头像以进行裁剪的存储桶。 我们首先前往 S3 仪表板并单击“创建存储桶”:
然后我们输入存储桶名称(在本例中为“avatars-smashing”)并选择区域(“EU (Frankfurt)”):
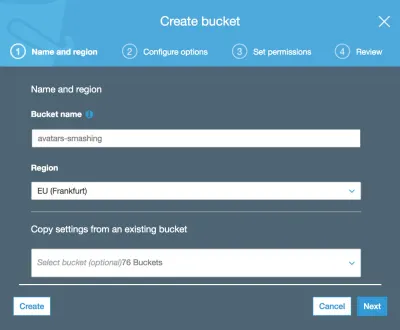
只有存储桶名称和区域是必需的。 对于以下步骤,我们可以保留默认选项,因此我们单击“下一步”,直到最后单击“创建存储桶”,这样,我们将创建存储桶。
设置用户权限
通过 SDK 连接到 AWS 时,我们将需要输入我们的用户凭证(一对访问密钥 ID 和秘密访问密钥),以验证我们是否可以访问请求的服务和对象。 用户权限可以是非常一般的(“管理员”角色可以做任何事情)或非常细化,只授予所需的特定操作的权限,没有别的。
作为一般规则,我们授予的权限越具体越好,以避免安全问题。 创建新用户时,我们需要创建一个策略,它是一个简单的 JSON 文档,列出了要授予用户的权限。 在我们的例子中,我们的用户权限将授予对 S3 的访问权限,用于存储桶“avatars-smashing”、“Put”(用于上传对象)、“Get”(用于下载对象)和“List”操作(用于列出存储桶中的所有对象),从而产生以下策略:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:Put*", "s3:Get*", "s3:List*" ], "Resource": [ "arn:aws:s3:::avatars-smashing", "arn:aws:s3:::avatars-smashing/*" ] } ] }在下面的屏幕截图中,我们可以看到如何添加用户权限。 我们必须转到身份和访问管理 (IAM) 仪表板:
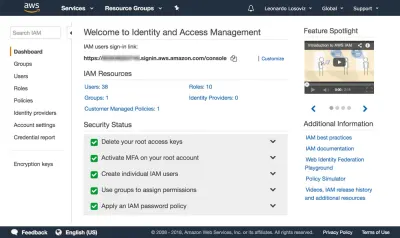
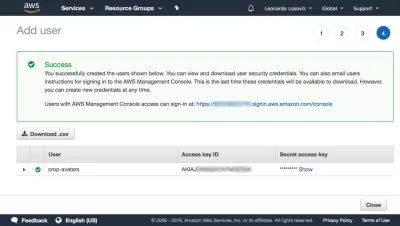
在仪表板中,我们单击“用户”,然后立即单击“添加用户”。 在添加用户页面中,我们选择一个用户名(“crop-avatars”),并勾选“程序访问”作为访问类型,它将提供访问密钥 ID 和秘密访问密钥,用于通过 SDK 进行连接:
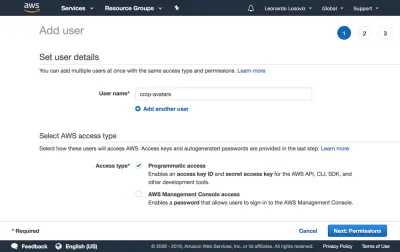
然后我们单击“下一步:权限”按钮,单击“直接附加现有策略”,然后单击“创建策略”。 这将在浏览器中打开一个新选项卡,其中包含“创建策略”页面。 我们单击 JSON 选项卡,然后输入上面定义的策略的 JSON 代码:
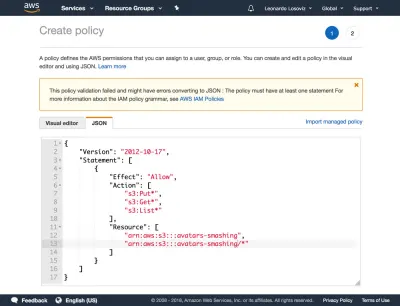
然后我们单击 Review policy,为其命名(“CropAvatars”),最后单击 Create policy。 创建策略后,我们切换回上一个选项卡,选择 CropAvatars 策略(我们可能需要刷新策略列表才能看到它),单击 Next: Review,最后单击 Create user。 完成此操作后,我们终于可以下载访问密钥 ID 和秘密访问密钥(请注意,这些凭据在这个独特的时刻可用;如果我们现在不复制或下载它们,我们将不得不创建一个新对):
通过 SDK 连接 AWS
SDK 可通过多种语言获得。 对于 WordPress 应用程序,我们需要 PHP 的 SDK,可以从这里下载,关于如何安装它的说明在这里。
一旦我们创建了存储桶、准备好用户凭证并安装了 SDK,我们就可以开始将文件上传到 S3。
上传和下载文件
为方便起见,我们将用户凭据和区域定义为 wp-config.php 文件中的常量:
define ('AWS_ACCESS_KEY_ID', '...'); // Your access key id define ('AWS_SECRET_ACCESS_KEY', '...'); // Your secret access key define ('AWS_REGION', 'eu-central-1'); // Region where the bucket is located. This is the region id for "EU (Frankfurt)" 在我们的例子中,我们正在实现裁剪头像功能,为此头像将存储在“头像粉碎”桶中。 但是,在我们的应用程序中,我们可能有几个其他功能的桶,需要执行相同的上传、下载和列出文件的操作。 因此,我们在抽象类AWS_S3上实现常用方法,并在实现子类中获取输入,例如通过函数get_bucket定义的存储桶名称。
// Load the SDK and import the AWS objects require 'vendor/autoload.php'; use Aws\S3\S3Client; use Aws\Exception\AwsException; // Definition of an abstract class abstract class AWS_S3 { protected function get_bucket() { // The bucket name will be implemented by the child class return ''; } } S3Client类公开了与 S3 交互的 API。 我们仅在需要时实例化它(通过延迟初始化),并在$this->s3Client下保存对它的引用以继续使用相同的实例:

abstract class AWS_S3 { // Continued from above... protected $s3Client; protected function get_s3_client() { // Lazy initialization if (!$this->s3Client) { // Create an S3Client. Provide the credentials and region as defined through constants in wp-config.php $this->s3Client = new S3Client([ 'version' => '2006-03-01', 'region' => AWS_REGION, 'credentials' => [ 'key' => AWS_ACCESS_KEY_ID, 'secret' => AWS_SECRET_ACCESS_KEY, ], ]); } return $this->s3Client; } } 当我们在应用程序中处理$file时,此变量包含磁盘中文件的绝对路径(例如/var/app/current/wp-content/uploads/users/654/leo.jpg ),但在上传时文件到 S3 我们不应该将对象存储在同一路径下。 特别是,出于安全原因,我们必须删除有关系统信息的初始位( /var/app/current ),并且我们可以选择删除/wp-content位(因为所有文件都存储在此文件夹下,这是冗余信息),只保留文件的相对路径 ( /uploads/users/654/leo.jpg )。 方便的是,这可以通过从绝对路径中删除WP_CONTENT_DIR之后的所有内容来实现。 下面的函数get_file和get_file_relative_path在绝对和相对文件路径之间切换:
abstract class AWS_S3 { // Continued from above... function get_file_relative_path($file) { return substr($file, strlen(WP_CONTENT_DIR)); } function get_file($file_relative_path) { return WP_CONTENT_DIR.$file_relative_path; } }将对象上传到 S3 时,我们可以通过访问控制列表 (ACL) 权限来确定授予谁访问该对象以及访问类型。 最常见的选项是保持文件私有(ACL => “private”)并使其可在 Internet 上阅读(ACL => “public-read”)。 因为我们需要直接从 S3 请求文件以将其显示给用户,所以我们需要 ACL => “public-read”:
abstract class AWS_S3 { // Continued from above... protected function get_acl() { return 'public-read'; } }最后,我们实现了将对象上传到 S3 存储桶以及从 S3 存储桶下载对象的方法:
abstract class AWS_S3 { // Continued from above... function upload($file) { $s3Client = $this->get_s3_client(); // Upload a file object to S3 $s3Client->putObject([ 'ACL' => $this->get_acl(), 'Bucket' => $this->get_bucket(), 'Key' => $this->get_file_relative_path($file), 'SourceFile' => $file, ]); } function download($file) { $s3Client = $this->get_s3_client(); // Download a file object from S3 $s3Client->getObject([ 'Bucket' => $this->get_bucket(), 'Key' => $this->get_file_relative_path($file), 'SaveAs' => $file, ]); } }然后,在实现子类中,我们定义存储桶的名称:
class AvatarCropper_AWS_S3 extends AWS_S3 { protected function get_bucket() { return 'avatars-smashing'; } } 最后,我们简单地实例化类以将头像上传到 S3 或从 S3 下载。 此外,当从第 1 步过渡到第 2 步和从第 2 步到第 3 步时,我们需要传达$file的值。 我们可以通过 POST 操作提交一个带有$file相对路径值的字段“file_relative_path”来做到这一点(出于安全原因,我们不传递绝对路径:不需要包含“/var/www/current ” 供外人查看的信息):
// Step 1: after the file was uploaded to the server, upload it to S3. Here, $file is known $avatarcropper = new AvatarCropper_AWS_S3(); $avatarcropper->upload($file); // Get the file path, and send it to the next step in the POST $file_relative_path = $avatarcropper->get_file_relative_path($file); // ... // -------------------------------------------------- // Step 2: get the $file from the request and download it, manipulate it, and upload it again $avatarcropper = new AvatarCropper_AWS_S3(); $file_relative_path = $_POST['file_relative_path']; $file = $avatarcropper->get_file($file_relative_path); $avatarcropper->download($file); // Do manipulation of the file // ... // Upload the file again to S3 $avatarcropper->upload($file); // -------------------------------------------------- // Step 3: get the $file from the request and download it, and then save it $avatarcropper = new AvatarCropper_AWS_S3(); $file_relative_path = $_REQUEST['file_relative_path']; $file = $avatarcropper->get_file($file_relative_path); $avatarcropper->download($file); // Save it, whatever that means // ...直接从 S3 显示文件
如果我们想在第2步操作后显示文件的中间状态(例如裁剪后的用户头像),那么我们必须直接从S3引用文件; URL 无法指向服务器上的文件,因为我们不知道哪个服务器将处理该请求。
下面,我们添加函数get_file_url($file) ,它在 S3 中获取该文件的 URL。 如果使用此功能,请确保上传文件的 ACL 为“public-read”,否则用户无法访问。
abstract class AWS_S3 { // Continue from above... protected function get_bucket_url() { $region = $this->get_region(); // North Virginia region is simply "s3", the others require the region explicitly $prefix = $region == 'us-east-1' ? 's3' : 's3-'.$region; // Use the same scheme as the current request $scheme = is_ssl() ? 'https' : 'http'; // Using the bucket name in path scheme return $scheme.'://'.$prefix.'.amazonaws.com/'.$this->get_bucket(); } function get_file_url($file) { return $this->get_bucket_url().$this->get_file_relative_path($file); } }然后,我们可以简单地获取 S3 上文件的 URL 并打印图像:
printf( "<img src='%s'>", $avatarcropper->get_file_url($file) );列出文件
如果在我们的应用程序中我们希望允许用户查看所有之前上传的头像,我们可以这样做。 为此,我们引入了get_file_urls函数,它列出了存储在某个路径下的所有文件的 URL(在 S3 术语中,它称为前缀):
abstract class AWS_S3 { // Continue from above... function get_file_urls($prefix) { $s3Client = $this->get_s3_client(); $result = $s3Client->listObjects(array( 'Bucket' => $this->get_bucket(), 'Prefix' => $prefix )); $file_urls = array(); if(isset($result['Contents']) && count($result['Contents']) > 0 ) { foreach ($result['Contents'] as $obj) { // Check that Key is a full file path and not just a "directory" if ($obj['Key'] != $prefix) { $file_urls[] = $this->get_bucket_url().$obj['Key']; } } } return $file_urls; } }然后,如果我们将每个头像存储在路径“/users/${user_id}/”下,通过传递此前缀,我们将获得所有文件的列表:
$user_id = get_current_user_id(); $prefix = "/users/${user_id}/"; foreach ($avatarcropper->get_file_urls($prefix) as $file_url) { printf( "<img src='%s'>", $file_url ); }结论
在本文中,我们探讨了如何使用云对象存储解决方案充当通用存储库,为部署在多个服务器上的应用程序存储文件。 对于解决方案,我们专注于 AWS S3,并继续展示需要集成到应用程序中的步骤:创建存储桶、设置用户权限以及下载和安装 SDK。 最后,我们解释了如何避免应用程序中的安全隐患,并通过代码示例演示了如何在 S3 上执行最基本的操作:上传、下载和列出文件,每个操作几乎不需要几行代码。 该解决方案的简单性表明,将云服务集成到应用程序中并不难,也可以由对云没有太多经验的开发人员来完成。