
如何制作语音合成编辑器
已发表: 2022-03-10当史蒂夫乔布斯在 1984 年推出 Macintosh 时,它在舞台上对我们说“你好”。 即使在那个时候,语音合成也不是真正的新技术:早在 30 年代末,贝尔实验室就开发了语音合成器,当斯坦利·库布里克(Stanley Kubrick)让语音合成器成为2001 年的 HAL9000:太空漫游(1968 年)。
直到 2015 年代中期 Apple 的 Siri、Amazon Echo 和 Google Assistant 推出之前,语音界面才真正进入更广泛公众的家中、手腕和口袋。 我们仍处于采用阶段,但这些语音助手似乎将继续存在。
换句话说,网络不再只是屏幕上的被动文本。 网络编辑和用户体验设计师必须习惯于制作应该大声说出来的内容和服务。
我们已经在快速转向使用内容管理系统,这些系统让我们可以无头地通过 API 处理我们的内容。 最后一点是制作编辑界面,以便更轻松地为语音定制内容。 所以让我们这样做吧!
什么是 SSML
虽然 Web 浏览器使用 W3C 的超文本标记语言 (HTML) 规范来直观地呈现文档,但大多数语音助手在生成语音时使用语音合成标记语言 (SSML)。
使用根元素<speak>以及段落 ( <p> ) 和句子 ( <s> ) 标记的最小示例:
<speak> <p> <s>This is the first sentence of the paragraph.</s> <s>Here's another sentence.</s> </p> </speak> 当我们为<emphasis>和<prosody> (pitch) 引入标签时,SSML 就存在了:
<speak> <p> <s>Put some <emphasis strength="strong">extra weight on these words</emphasis></s> <s>And say <prosody pitch="high" rate="fast">this a bit higher and faster</prosody>!</s> </p> </speak>SSML 有更多的功能,但这足以让您了解基础知识。 现在,让我们仔细看看我们将用来制作语音合成编辑界面的编辑器。
便携式文本编辑器
为了制作这个编辑器,我们将使用 Sanity.io 中的 Portable Text 编辑器。 Portable Text 是一种用于富文本编辑的 JSON 规范,可以序列化为任何标记语言,例如 SSML。 这意味着您可以使用不同的标记语言在多个地方轻松使用相同的文本片段。

安装理智
Sanity.io 是一个结构化内容平台,带有一个使用 React.js 构建的开源编辑环境。 启动并运行它需要两分钟。
在终端中输入npm i -g @sanity/cli && sanity init ,然后按照说明进行操作。 当系统提示您输入项目模板时,选择“空”。
如果您不想按照本教程从头开始制作此编辑器,您也可以克隆本教程的代码并按照README.md中的说明进行操作。
下载编辑器后,您可以在项目文件夹中运行sanity start来启动它。 它将启动一个开发服务器,该服务器使用热模块重新加载来在您编辑其文件时更新更改。
如何在 Sanity Studio 中配置模式
创建编辑器文件
我们将首先在/schemas文件夹中创建一个名为ssml-editor的文件夹。 在该文件夹中,我们将放置一些空文件:
/ssml-tutorial/schemas/ssml-editor ├── alias.js ├── emphasis.js ├── annotations.js ├── preview.js ├── prosody.js ├── sayAs.js ├── blocksToSSML.js ├── speech.js ├── SSMLeditor.css └── SSMLeditor.js 现在我们可以在这些文件中添加内容模式。 内容模式定义了富文本的数据结构,以及 Sanity Studio 用来生成编辑界面的内容。 它们是简单的 JavaScript 对象,大多只需要一个name和一个type 。
我们还可以添加title和description ,以使编辑更友好。 例如,这是title的简单文本字段的架构:
export default { name: 'title', type: 'string', title: 'Title', description: 'Titles should be short and descriptive' } 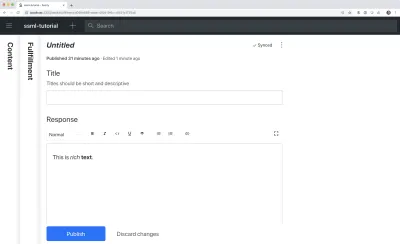
Portable Text 建立在将富文本作为数据的理念之上。 这很强大,因为它可以让您查询富文本,并将其转换为几乎任何您想要的标记。
它是一个称为“块”的对象数组,您可以将其视为“段落”。 在一个块中,有一组子跨度。 每个块都可以有一个样式和一组标记定义,这些定义描述了分布在子 span 上的数据结构。
Sanity.io 带有一个可以读取和写入便携式文本的编辑器,并通过将block类型放在array字段中来激活,如下所示:
// speech.js export default { name: 'speech', type: 'array', title: 'SSML Editor', of: [ { type: 'block' } ] }一个数组可以有多种类型。 对于 SSML 编辑器,这些可能是音频文件的块,但这超出了本教程的范围。
我们要做的最后一件事是添加可以使用此编辑器的内容类型。 大多数助手使用“意图”和“实现”的简单内容模型:
- 意图
通常是 AI 模型用来描述用户想要完成的内容的字符串列表。 - 履行情况
当确定“意图”时,就会发生这种情况。 一种满足通常——或者至少——伴随着某种回应。
因此,让我们使用语音合成编辑器创建一个名为fulfillment的简单内容类型。 创建一个名为fulfillment.js的新文件并将其保存在/schema文件夹中:
// fulfillment.js export default { name: 'fulfillment', type: 'document', title: 'Fulfillment', of: [ { name: 'title', type: 'string', title: 'Title', description: 'Titles should be short and descriptive' }, { name: 'response', type: 'speech' } ] }保存文件,然后打开schema.js 。 像这样将它添加到您的工作室:
// schema.js import createSchema from 'part:@sanity/base/schema-creator' import schemaTypes from 'all:part:@sanity/base/schema-type' import fullfillment from './fullfillment' import speech from './speech' export default createSchema({ name: 'default', types: schemaTypes.concat([ fullfillment, speech, ]) }) 如果您现在在项目根文件夹中的命令行界面中运行sanity start ,则工作室将在本地启动,您将能够添加条目以完成任务。 您可以在我们继续进行时保持工作室运行,因为当您保存文件时,它将自动重新加载新的更改。
将 SSML 添加到编辑器
默认情况下, block类型将为您提供一个标准编辑器,用于具有标题样式、强调和强的装饰器样式、链接注释和列表的视觉导向富文本。 现在我们想用 SSML 中的听觉概念覆盖那些。
我们首先定义不同的内容结构,并为编辑器提供有用的描述,我们将把它们添加到SSMLeditorSchema.js的block中作为annotations的配置。 这些是“强调”、“别名”、“韵律”和“说成”。
重点
我们从“强调”开始,它控制标记文本的权重。 我们将其定义为一个字符串,其中包含用户可以选择的预定义值列表:
// emphasis.js export default { name: 'emphasis', type: 'object', title: 'Emphasis', description: 'The strength of the emphasis put on the contained text', fields: [ { name: 'level', type: 'string', options: { list: [ { value: 'strong', title: 'Strong' }, { value: 'moderate', title: 'Moderate' }, { value: 'none', title: 'None' }, { value: 'reduced', title: 'Reduced' } ] } } ] }别名
有时书面和口头术语不同。 例如,您想在书面文本中使用短语的缩写,但要大声朗读整个短语。 例如:
<s>This is a <sub alias="Speech Synthesis Markup Language">SSML</sub> tutorial</s>别名的输入字段是一个简单的字符串:
// alias.js export default { name: 'alias', type: 'object', title: 'Alias (sub)', description: 'Replaces the contained text for pronunciation. This allows a document to contain both a spoken and written form.', fields: [ { name: 'text', type: 'string', title: 'Replacement text', } ] }韵律
通过韵律属性,我们可以控制文本应该如何朗读的不同方面,例如音高、速率和音量。 标记可能如下所示:
<s>Say this with an <prosody pitch="x-low">extra low pitch</prosody>, and this <prosody rate="fast" volume="loud">loudly with a fast rate</prosody></s>此输入将包含三个带有预定义字符串选项的字段:
// prosody.js export default { name: 'prosody', type: 'object', title: 'Prosody', description: 'Control of the pitch, speaking rate, and volume', fields: [ { name: 'pitch', type: 'string', title: 'Pitch', description: 'The baseline pitch for the contained text', options: { list: [ { value: 'x-low', title: 'Extra low' }, { value: 'low', title: 'Low' }, { value: 'medium', title: 'Medium' }, { value: 'high', title: 'High' }, { value: 'x-high', title: 'Extra high' }, { value: 'default', title: 'Default' } ] } }, { name: 'rate', type: 'string', title: 'Rate', description: 'A change in the speaking rate for the contained text', options: { list: [ { value: 'x-slow', title: 'Extra slow' }, { value: 'slow', title: 'Slow' }, { value: 'medium', title: 'Medium' }, { value: 'fast', title: 'Fast' }, { value: 'x-fast', title: 'Extra fast' }, { value: 'default', title: 'Default' } ] } }, { name: 'volume', type: 'string', title: 'Volume', description: 'The volume for the contained text.', options: { list: [ { value: 'silent', title: 'Silent' }, { value: 'x-soft', title: 'Extra soft' }, { value: 'medium', title: 'Medium' }, { value: 'loud', title: 'Loud' }, { value: 'x-loud', title: 'Extra loud' }, { value: 'default', title: 'Default' } ] } } ] }说为
我们要包含的最后一个是<say-as> 。 这个标签让我们可以更好地控制某些信息的发音方式。 如果您需要在语音界面中编辑某些内容,我们甚至可以使用它来发出声音。 那是@!%& 有用!
<s>Do I have to <say-as interpret-as="expletive">frakking</say-as> <say-as interpret-as="verbatim">spell</say-as> it out for you!?</s> // sayAs.js export default { name: 'sayAs', type: 'object', title: 'Say as...', description: 'Lets you indicate information about the type of text construct that is contained within the element. It also helps specify the level of detail for rendering the contained text.', fields: [ { name: 'interpretAs', type: 'string', title: 'Interpret as...', options: { list: [ { value: 'cardinal', title: 'Cardinal numbers' }, { value: 'ordinal', title: 'Ordinal numbers (1st, 2nd, 3th...)' }, { value: 'characters', title: 'Spell out characters' }, { value: 'fraction', title: 'Say numbers as fractions' }, { value: 'expletive', title: 'Blip out this word' }, { value: 'unit', title: 'Adapt unit to singular or plural' }, { value: 'verbatim', title: 'Spell out letter by letter (verbatim)' }, { value: 'date', title: 'Say as a date' }, { value: 'telephone', title: 'Say as a telephone number' } ] } }, { name: 'date', type: 'object', title: 'Date', fields: [ { name: 'format', type: 'string', description: 'The format attribute is a sequence of date field character codes. Supported field character codes in format are {y, m, d} for year, month, and day (of the month) respectively. If the field code appears once for year, month, or day then the number of digits expected are 4, 2, and 2 respectively. If the field code is repeated then the number of expected digits is the number of times the code is repeated. Fields in the date text may be separated by punctuation and/or spaces.' }, { name: 'detail', type: 'number', validation: Rule => Rule.required() .min(0) .max(2), description: 'The detail attribute controls the spoken form of the date. For detail='1' only the day fields and one of month or year fields are required, although both may be supplied' } ] } ] }现在我们可以在annotations.js文件中导入它们,这让事情变得更整洁了。

// annotations.js export {default as alias} from './alias' export {default as emphasis} from './emphasis' export {default as prosody} from './prosody' export {default as sayAs} from './sayAs'现在我们可以将这些注释类型导入到我们的主模式中:
// schema.js import createSchema from "part:@sanity/base/schema-creator" import schemaTypes from "all:part:@sanity/base/schema-type" import fulfillment from './fulfillment' import speech from './ssml-editor/speech' import { alias, emphasis, prosody, sayAs } from './annotations' export default createSchema({ name: "default", types: schemaTypes.concat([ fulfillment, speech, alias, emphasis, prosody, sayAs ]) })最后,我们现在可以像这样将这些添加到编辑器中:
// speech.js export default { name: 'speech', type: 'array', title: 'SSML Editor', of: [ { type: 'block', styles: [], lists: [], marks: { decorators: [], annotations: [ {type: 'alias'}, {type: 'emphasis'}, {type: 'prosody'}, {type: 'sayAs'} ] } } ] } 请注意,我们还向styles和decorators添加了空数组。 这会禁用默认样式和装饰器(如粗体和强调),因为它们在这种特定情况下没有多大意义。
自定义外观
现在我们有了功能,但由于我们没有指定任何图标,每个注释都将使用默认图标,这使得编辑器很难实际用于作者。 所以让我们解决这个问题!
使用 Portable Text 的编辑器,可以为图标和标记文本的呈现方式注入 React 组件。 在这里,我们将让一些表情符号为我们完成工作,但您显然可以走得更远,使它们变得动态等等。 对于prosody ,我们甚至会根据所选音量更改图标。 请注意,为简洁起见,我省略了这些片段中的字段,您不应在本地文件中删除它们。
// alias.js import React from 'react' export default { name: 'alias', type: 'object', title: 'Alias (sub)', description: 'Replaces the contained text for pronunciation. This allows a document to contain both a spoken and written form.', fields: [ /* all the fields */ ], blockEditor: { icon: () => '', render: ({ children }) => <span>{children} </span>, }, }; // emphasis.js import React from 'react' export default { name: 'emphasis', type: 'object', title: 'Emphasis', description: 'The strength of the emphasis put on the contained text', fields: [ /* all the fields */ ], blockEditor: { icon: () => '', render: ({ children }) => <span>{children} </span>, }, }; // prosody.js import React from 'react' export default { name: 'prosody', type: 'object', title: 'Prosody', description: 'Control of the pitch, speaking rate, and volume', fields: [ /* all the fields */ ], blockEditor: { icon: () => '', render: ({ children, volume }) => ( <span> {children} {['x-loud', 'loud'].includes(volume) ? '' : ''} </span> ), }, }; // sayAs.js import React from 'react' export default { name: 'sayAs', type: 'object', title: 'Say as...', description: 'Lets you indicate information about the type of text construct that is contained within the element. It also helps specify the level of detail for rendering the contained text.', fields: [ /* all the fields */ ], blockEditor: { icon: () => '', render: props => <span>{props.children} </span>, }, }; 
现在您有了一个编辑器,用于编辑语音助手可以使用的文本。 但是,如果编辑器也可以预览文本的实际听起来如何,那不是很有用吗?
使用 Google 的文字转语音添加预览按钮
原生语音合成支持实际上正在为浏览器提供支持。 但在本教程中,我们将使用支持 SSML 的 Google 文本转语音 API。 构建此预览功能还将演示如何在您想要使用它的任何服务中将可移植文本序列化为 SSML。
将编辑器包装在 React 组件中
我们首先打开SSMLeditor.js文件并添加以下代码:
// SSMLeditor.js import React, { Fragment } from 'react'; import { BlockEditor } from 'part:@sanity/form-builder'; export default function SSMLeditor(props) { return ( <Fragment> <BlockEditor {...props} /> </Fragment> ); } 我们现在已经将编辑器包装在我们自己的 React 组件中。 它需要的所有道具,包括它包含的数据,都是实时传递的。 要实际使用此组件,您必须将其导入到您的speech.js文件中:
// speech.js import React from 'react' import SSMLeditor from './SSMLeditor.js' export default { name: 'speech', type: 'array', title: 'SSML Editor', inputComponent: SSMLeditor, of: [ { type: 'block', styles: [], lists: [], marks: { decorators: [], annotations: [ { type: 'alias' }, { type: 'emphasis' }, { type: 'prosody' }, { type: 'sayAs' }, ], }, }, ], }当你保存这个并且工作室重新加载时,它应该看起来几乎完全一样,但那是因为我们还没有开始调整编辑器。
将便携式文本转换为 SSML
编辑器会将内容保存为可移植文本,这是 JSON 中的对象数组,可以轻松地将富文本转换为您需要的任何格式。 当您将 Portable Text 转换为另一种语法或格式时,我们称之为“序列化”。 因此,“序列化程序”是如何转换富文本的秘诀。 在本节中,我们将添加用于语音合成的序列化程序。
您已经制作了blocksToSSML.js文件。 现在我们需要添加我们的第一个依赖项。 首先在ssml-editor文件夹中运行终端命令npm init -y 。 这将添加一个package.json ,其中将列出编辑器的依赖项。
完成后,您可以运行npm install @sanity/block-content-to-html来获取一个库,以便更轻松地序列化可移植文本。 我们使用 HTML 库是因为 SSML 具有与标签和属性相同的 XML 语法。
这是一堆代码,所以请随意复制粘贴。 我将在代码段下方解释该模式:
// blocksToSSML.js import blocksToHTML, { h } from '@sanity/block-content-to-html' const serializers = { marks: { prosody: ({ children, mark: { rate, pitch, volume } }) => h('prosody', { attrs: { rate, pitch, volume } }, children), alias: ({ children, mark: { text } }) => h('sub', { attrs: { alias: text } }, children), sayAs: ({ children, mark: { interpretAs } }) => h('say-as', { attrs: { 'interpret-as': interpretAs } }, children), break: ({ children, mark: { time, strength } }) => h('break', { attrs: { time: '${time}ms', strength } }, children), emphasis: ({ children, mark: { level } }) => h('emphasis', { attrs: { level } }, children) } } export const blocksToSSML = blocks => blocksToHTML({ blocks, serializers }) 此代码将导出一个函数,该函数采用块数组并循环它们。 每当一个块包含一个mark时,它都会为该类型寻找一个序列化器。 如果您已将某些文本标记为emphasis ,则它来自序列化程序对象的此函数:
emphasis: ({ children, mark: { level } }) => h('emphasis', { attrs: { level } }, children) 也许你认出了我们定义模式的参数? h()函数让我们定义了一个 HTML 元素,也就是说,我们在这里“作弊”并让它返回一个名为<emphasis>的 SSML 元素。 如果定义了属性level ,我们还会为其提供属性级别,并将children元素放置在其中 - 在大多数情况下,这将是您标记为emphasis的文本。
{ "_type": "block", "_key": "f2c4cf1ab4e0", "style": "normal", "markDefs": [ { "_type": "emphasis", "_key": "99b28ed3fa58", "level": "strong" } ], "children": [ { "_type": "span", "_key": "f2c4cf1ab4e01", "text": "Say this strongly!", "marks": [ "99b28ed3fa58" ] } ] }这就是 Portable Text 中的上述结构如何序列化为此 SSML:
<emphasis level="strong">Say this strongly</emphasis> 如果您想要支持更多 SSML 标签,您可以在模式中添加更多注释,并将注释类型添加到序列化程序中的marks部分。
现在我们有一个函数可以从我们标记的富文本中返回 SSML 标记。 最后一部分是制作一个按钮,让我们可以将此标记发送到文本转语音服务。
添加一个与您对话的预览按钮
理想情况下,我们应该在 Web API 中使用浏览器的语音合成功能。 这样,我们就可以减少代码和依赖项。
然而,截至 2019 年初,对语音合成的原生浏览器支持仍处于早期阶段。 看起来对 SSML 的支持正在进行中,并且有客户端 JavaScript 实现的概念证明。
无论如何,您很有可能会将此内容与语音助手一起使用。 Google Assistant 和 Amazon Echo (Alexa) 都支持 SSML 作为履行中的响应。 在本教程中,我们将使用 Google 的 text-to-speech API,它听起来也不错,并且支持多种语言。
首先通过注册 Google Cloud Platform 获取 API 密钥(您处理的前 100 万个字符将免费)。 注册后,您可以在此页面上创建新的 API 密钥。
现在您可以打开PreviewButton.js文件,并将以下代码添加到其中:
// PreviewButton.js import React from 'react' import Button from 'part:@sanity/components/buttons/default' import { blocksToSSML } from './blocksToSSML' // You should be careful with sharing this key // I put it here to keep the code simple const API_KEY = '<yourAPIkey>' const GOOGLE_TEXT_TO_SPEECH_URL = 'https://texttospeech.googleapis.com/v1beta1/text:synthesize?key=' + API_KEY const speak = async blocks => { // Serialize blocks to SSML const ssml = blocksToSSML(blocks) // Prepare the Google Text-to-Speech configuration const body = JSON.stringify({ input: { ssml }, // Select the language code and voice name (AF) voice: { languageCode: 'en-US', name: 'en-US-Wavenet-A' }, // Use MP3 in order to play in browser audioConfig: { audioEncoding: 'MP3' } }) // Send the SSML string to the API const res = await fetch(GOOGLE_TEXT_TO_SPEECH_URL, { method: 'POST', body }).then(res => res.json()) // Play the returned audio with the Browser's Audo API const audio = new Audio('data:audio/wav;base64,' + res.audioContent) audio.play() } export default function PreviewButton (props) { return <Button style={{ marginTop: '1em' }} onClick={() => speak(props.blocks)}>Speak text</Button> }我已将此预览按钮代码保持在最低限度,以便更轻松地遵循本教程。 当然,您可以通过添加状态来构建它以显示预览是否正在处理,或者可以使用 Google API 支持的不同声音进行预览。
将按钮添加到SSMLeditor.js :
// SSMLeditor.js import React, { Fragment } from 'react'; import { BlockEditor } from 'part:@sanity/form-builder'; import PreviewButton from './PreviewButton'; export default function SSMLeditor(props) { return ( <Fragment> <BlockEditor {...props} /> <PreviewButton blocks={props.value} /> </Fragment> ); }现在您应该能够使用不同的注释标记您的文本,并在按下“朗读文本”时听到结果。 酷,不是吗?
你已经创建了一个语音合成编辑器,现在呢?
如果您遵循本教程,您已经了解了如何使用 Sanity Studio 中的可移植文本编辑器进行自定义注释和自定义编辑器。 您可以将这些技能用于各种事情,而不仅仅是制作语音合成编辑器。 您还了解了如何将 Portable Text 序列化为您需要的语法。 显然,如果您在 React 或 Vue 中构建前端,这也很方便。 您甚至可以使用这些技能从 Portable Text 生成 Markdown。
我们还没有介绍您如何将它与语音助手一起实际使用。 如果您想尝试,您可以使用与无服务器函数中的预览按钮相同的逻辑,并将其设置为使用 webhook 实现的 API 端点,例如使用 Dialogflow。
如果您希望我写一篇关于如何将语音合成编辑器与语音助手一起使用的教程,请随时在 Twitter 上给我提示或在下面的评论部分分享。
关于 SmashingMag 的进一步阅读:
- 尝试语音合成
- 使用 Web Speech API 增强用户体验
- 可访问性 API:Web 可访问性的关键
- 使用 Web Speech API 和 Node.js 构建一个简单的 AI 聊天机器人